上一篇文章:《Eiten 一个构建美股投资组合的好帮手》中,我们讲解了Eiten这一个开源工具包,以及如何使用它来构建美股的投资组合。
所谓的投资组合优化,就是决定你的股票池的权重分配比例,这一步是在选股完毕之后进行的。关于选股,你可以阅读我们之前的文章:量化投资单因子回测神器 — Alphalens。
本篇文章我们将介绍如何使用Eiten做A股的投资组合优化,文中的股票都是随机选取的,请勿参考。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
git clone https://github.com/tradytics/eiten.git cd eiten pip install -r requirements.txt pip install yfinance --upgrade --no-cache-dir
如你无法下载github上的内容,请到 https://pythondict.com/下载/eiten-源代码/ 上下载。
目录结构如下:
| 路径 | 描述 |
|---|---|
| eiten | 主目录 |
| └ figures | 仓库用到的图表(无需关注) |
| └ stocks | 你的用于创建投资组合的股票列表 |
| └ strategies | python编写的策略代码 |
| backtester.py | 回测模块 |
| data_loader.py | 数据加载工具 |
| portfolio_manager.py | 生成投资组合的代码 |
| simulator.py | 使用历史回报生成投资组合的模拟器 |
| strategy_manager.py | 策略管理器 |
2.使用方法—A股
把你想要构建投资组合的候选股票列表写入 stocks/stocks.txt 中。A股的股票代码形式如下:
上海市场,股票代码后缀加 .SS, 如: 600519.SS 及 688111.SS
深圳市场,股票代码后缀加 .SZ 如: 000858.SZ 及 300498.SZ
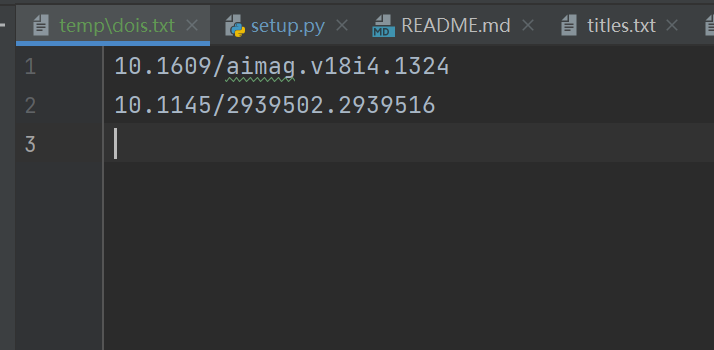
比如我在 stocks/stocks.txt 中放入以下10只股票进行投资组合优化:
600519.SS 601318.SS 600036.SS 000858.SZ 601012.SS 000333.SZ 600276.SS 002415.SZ 601166.SS 601888.SS
在终端输入以下命令运行,试试效果:
python portfolio_manager.py --is_test 1 --future_bars 20 --data_granularity_minutes 3600 --history_to_use 250 --apply_noise_filtering 1 --only_long 1 --eigen_portfolio_number 3 --stocks_file_path stocks/stocks.txt
参数说明:
is_test: 该值决定了程序是否要保留一些数据用于未来的测试。当这个值为True时,future_bars的值应该大于5。
future_bars: 构建投资组合时将排除的最近n条K线。这也被称为样本外的数据。
data_granularity_minutes: 你想什么频率的数据来建立你的投资组合。对于长期投资组合,你应该使用每日数据,但对于短期策略,你可以使用分钟的数据(60、30、15、5、1)。3600代表每天。
history_to_use: 是使用特定数量的数据还是使用我们从雅虎财经下载的所有数据。对于分钟级别的数据,我们只下载了一个月的历史数据。对于日线,我们下载了5年的历史数据。如果你想使用所有可用的数据,该值应该是 all,但如果你想使用较小的数据量,你可以将其设置为一个整数,例如100,这将只使用最后100条k线来建立投资组合。在本文例子中,我们只用250条K线,因为雅虎财经上沪深300指数只保存了1年半。
apply_noise_filtering: 它使用随机矩阵理论来过滤掉随机性的协方差矩阵,从而产生更好的投资组合。值为1将启用它。
market_index: 你想用哪个指数来作为你的投资组合的基准值, 这里我使用了沪深300指数(000300.SS)。
only_long: 是否只做多。
eigen_portfolio_number: 针对Eigen策略,数字越小,风险和回报都会降低。可阅读这篇文章了解更多: eigen-portfolios.
stocks_file_path: 你想用来建立投资组合的股票列表。
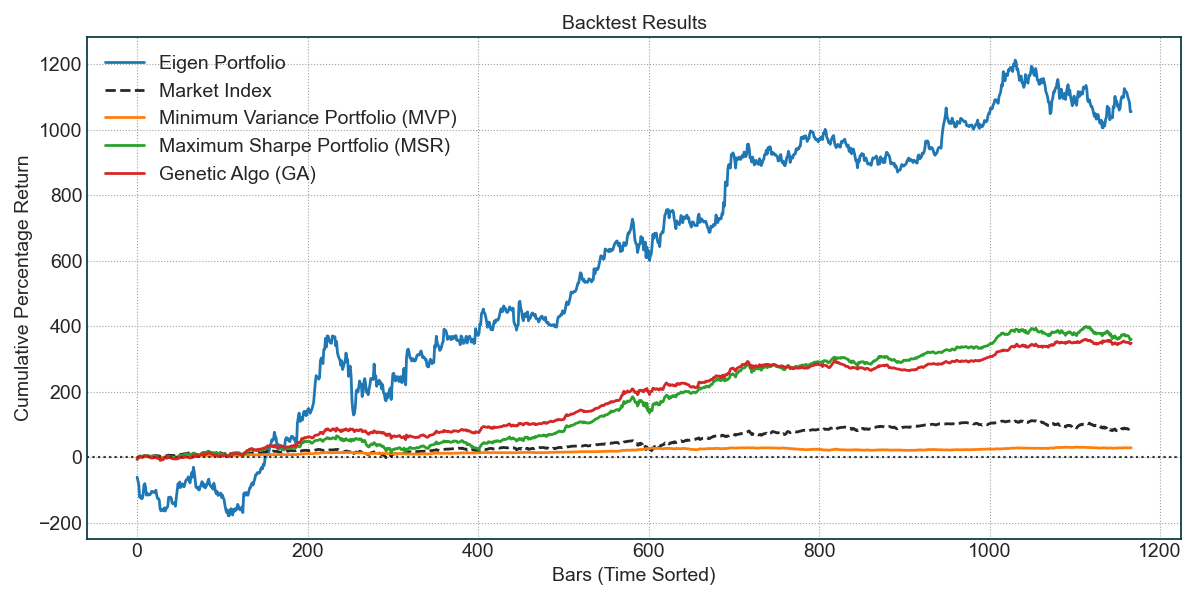
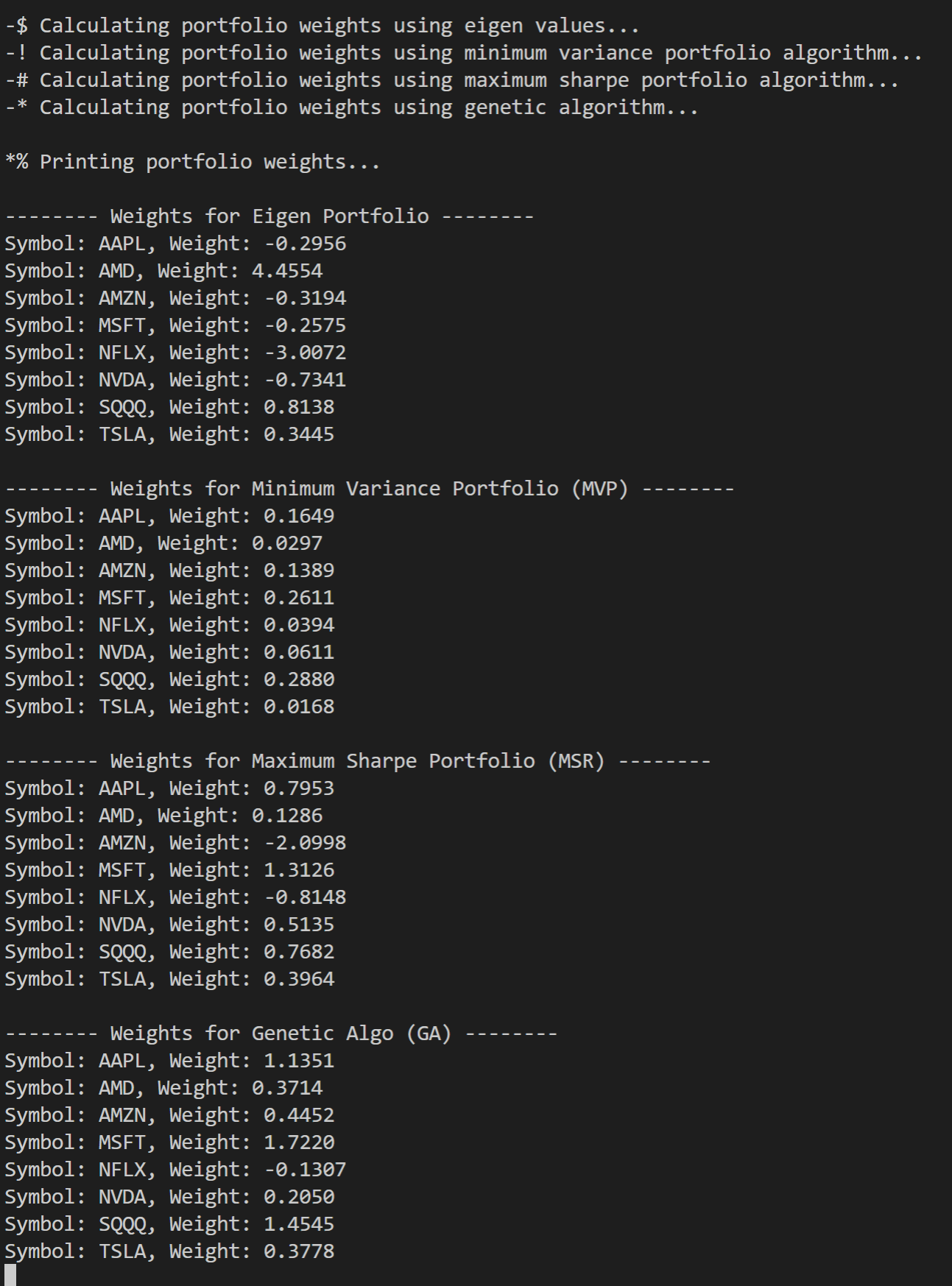
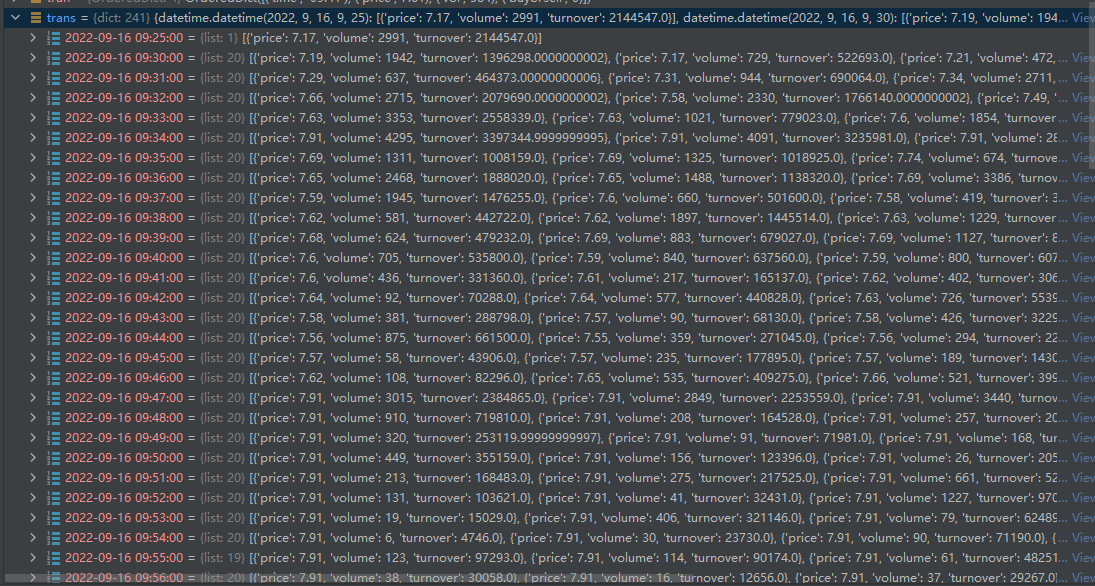
首先你会在终端中看到输出的所有策略给每只股票分配的权重:
*% Printing portfolio weights... -------- Weights for Eigen Portfolio -------- Symbol: 000333.SZ, Weight: 0.3399 Symbol: 000858.SZ, Weight: 0.0496 Symbol: 002415.SZ, Weight: -0.0787 Symbol: 600036.SS, Weight: 0.3179 Symbol: 600276.SS, Weight: 0.1612 Symbol: 600519.SS, Weight: 0.0292 Symbol: 601012.SS, Weight: 0.7539 Symbol: 601166.SS, Weight: 0.3149 Symbol: 601318.SS, Weight: 0.2433 Symbol: 601888.SS, Weight: -1.1312 -------- Weights for Minimum Variance Portfolio (MVP) -------- Symbol: 000333.SZ, Weight: -0.0335 Symbol: 000858.SZ, Weight: -0.0812 Symbol: 002415.SZ, Weight: 0.1281 Symbol: 600036.SS, Weight: -0.2021 Symbol: 600276.SS, Weight: 0.0767 Symbol: 600519.SS, Weight: 0.2759 Symbol: 601012.SS, Weight: 0.1913 Symbol: 601166.SS, Weight: 0.3773 Symbol: 601318.SS, Weight: 0.3735 Symbol: 601888.SS, Weight: -0.1058 -------- Weights for Maximum Sharpe Portfolio (MSR) -------- Symbol: 000333.SZ, Weight: 1.6382 Symbol: 000858.SZ, Weight: 0.1264 Symbol: 002415.SZ, Weight: 1.0846 Symbol: 600036.SS, Weight: -0.5394 Symbol: 600276.SS, Weight: 0.2878 Symbol: 600519.SS, Weight: -1.3160 Symbol: 601012.SS, Weight: 0.4310 Symbol: 601166.SS, Weight: 0.7743 Symbol: 601318.SS, Weight: -1.2865 Symbol: 601888.SS, Weight: -0.2004 -------- Weights for Genetic Algo (GA) -------- Symbol: 000333.SZ, Weight: -0.1276 Symbol: 000858.SZ, Weight: -0.8724 Symbol: 002415.SZ, Weight: -1.0129 Symbol: 600036.SS, Weight: -1.5845 Symbol: 600276.SS, Weight: -0.3169 Symbol: 600519.SS, Weight: 1.7996 Symbol: 601012.SS, Weight: 0.0641 Symbol: 601166.SS, Weight: 0.9515 Symbol: 601318.SS, Weight: 0.4069 Symbol: 601888.SS, Weight: 0.2969

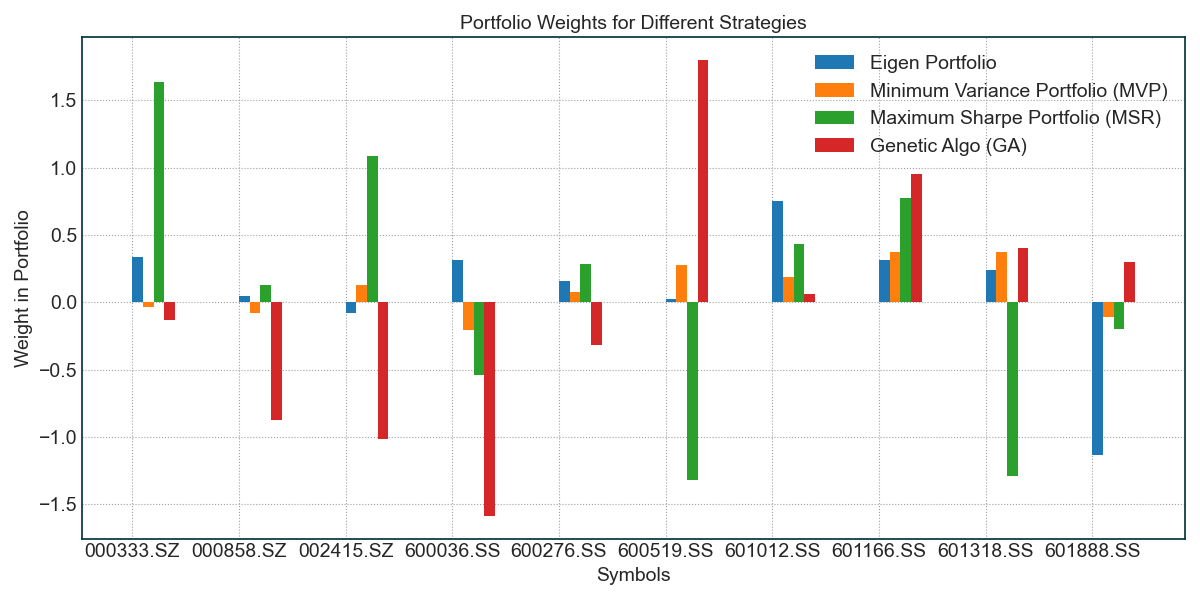
第二张图,你能看到每个策略的回测效果,可以看到,这10只股票的组合,使用GA策略的效果会比沪深300好一点:
@公众号: 二七阿尔量化
第三张图,我们设定了最后20个交易日用于测试,这是测试结果,由于近期市场处于下跌趋势,这10只股票也产生了剧烈波动,效果一般。

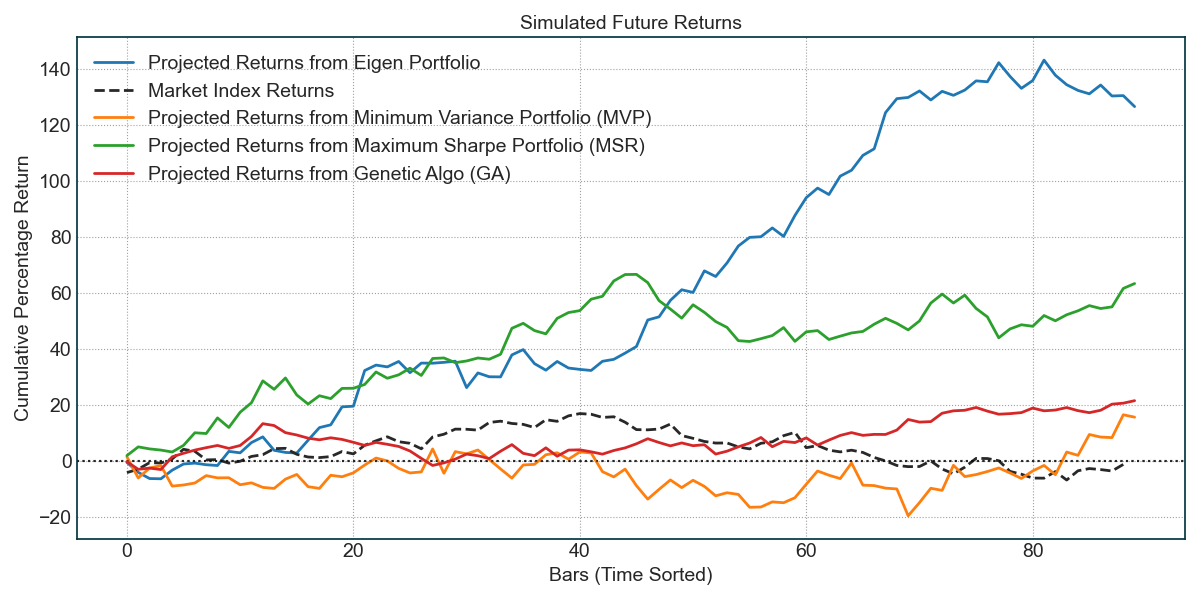
第四张图是对未来的一个预估,没有太大参考性。

3.四种策略的原理
可以看到输出的报告中包含了4种策略:
Eigen Portfolios 特征投资组合 (蓝色)
这些投资组合通常与市场相关性较低,会产生相对的高回报和阿尔法。然而,由于它们与市场相关性不高,它们也可能带来很大的风险。数字越小,风险和回报都会降低。
Minimum Variance Portfolio (MVP) 最小方差投资组合 (橙色)
MVP 试图最小化投资组合的收益方差。这些投资组合的风险和回报最低。
Maximum Sharpe Ratio Portfolio (MSR) 最大夏普比率投资组合 (绿色)
MSR 试图最大化投资组合的夏普比率。它在优化过程中使用过去的回报,这意味着如果过去的回报与未来的回报不同,那么未来的结果可能会有所不同。
Genetic Algorithm (GA) based Portfolio 基于遗传算法 (GA) 的投资组合 (红色)
这是 Eiten 模块内实现的基于 GA 的投资组合。通常能提供比其他策略更强大的投资组合。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典