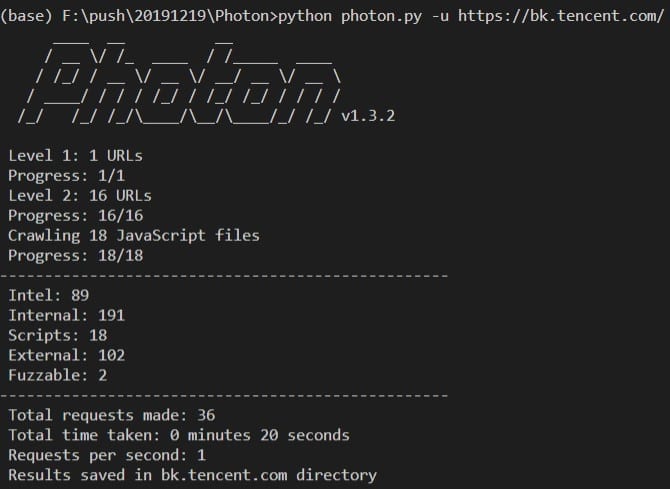
还记得我们上次做的一个高潮提取器吗:Python制作音乐高潮提取器 。今天我们来把这个高潮提取器做成一个网站,让许多不懂技术的人也可以很方便地提取歌曲里的高潮/副歌部分。
其实这是一个非常简单的单页面网站,不需要数据库 、不需要celery、不需要各种高深的后端技术。不过,如果适当地利用一些Python的Web开发框架,我们能更快地完成这个网站的开发,也能够顺便带大家入门一下Web开发框架。
因此我们将用Django 来完成这个网站。不过由于我不想让文章篇幅变得冗长,我们将分为两部分来讲解,第一部分是建造一个简单的支持文件上传的网站,第二部分将基于第一部分完善文件上传功能,建造一个音乐高潮提取网。
1.准备
在开始之前,你需要先安装好Python,如果还没有安装Python,请看这篇文章:超详细安装Python指南 。
打开CMD(windows)/Terminal(macos),下文统一称这两者为终端,输入安装Django 的命令:
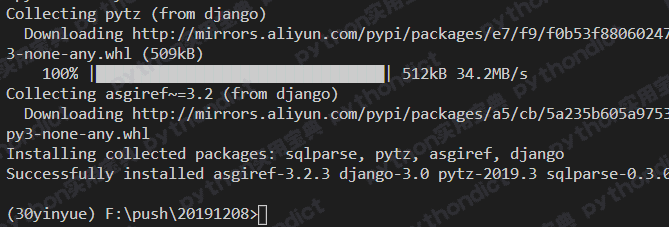
pip install Django 看到终端结果显示类似如下则说明安装成功。
安装高潮提取器需要用到的项目:
pip install pychorus
在你希望放置项目文件的目录下打开终端,输入以下命令:
django-admin startproject yinyue30 如果遇到 未找到命令 Django -admin 这样的错误,则说明你需要配置Django 的环境变量,详细可以看这篇文章的windows Django 安装:
https://www.runoob.com/django/django-install.html
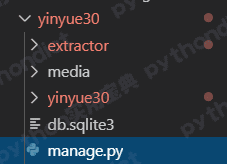
这个命令会新建一个Django 项目,目录结构如下:
新建了Django 项目后,我们就可以开始应用开发了。使用终端在生成的yinyue30文件夹中,输入以下命令新建“extractor(提取器)”应用:
python manage.py startapp extractor 到这里,应用初始化就算正式完成了。让我们看一下现在的文件结构:
看起来有点复杂,但是不要紧,我们只需要管其中几个文件即可。在我们开始正式编写代码前,我想先解释一下Django 的设计模式。
3.1 Django 设计模式简析( 你可以跳过这一部分)
传统的网站设计 模型是MVC模型,即:
M 代表模型(Model): 负责对象和数据库 的关系(ORM)。V 代表视图 (View): 负责如何把页面展示给用户(html)。C 代表控制器(Controller) :负责转发请求,处理请求等。
实质上Django 也是类似的模型,不过有些许不同。Django 更像是一个MVT模型,其中Controller的功能,被分担到了View和url转发器中。
在今天的教程中,我们重点关注的对象是View和Url转发器。
3.3 模型设计—编写models.py
尽管我们这个单页面应用可以不用到模型,但是使用模型能够帮助我们简化不少流程。而且代码非常简单:
文件将会被上传到“media/当前日期/ ” 的文件夹下,而且是和manage.py同级。如图所示:
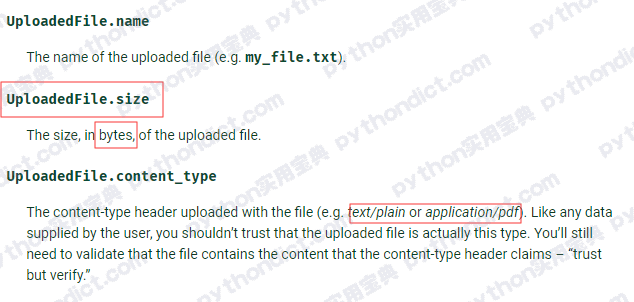
之所以用Django 自带的文件模型,不仅仅是因为这点方便,它还支持文件同名处理,当两个用户上传了相同文件名的文件时,第二个文件会被加一串md5作为区别。
除此之外,它还能限定文件上传的大小,具备用API作为代理访问基础文件等诸多方便的功能,如果你想了解更多的细节,可以阅读官方文档: https://docs.djangoproject.com/zh-hans/3.0/ref/models/fields/
3.4 视图设计—编写views.py
在views.py我们主要做以下几个事情:
1.渲染前端页面,允许用户提交文件。
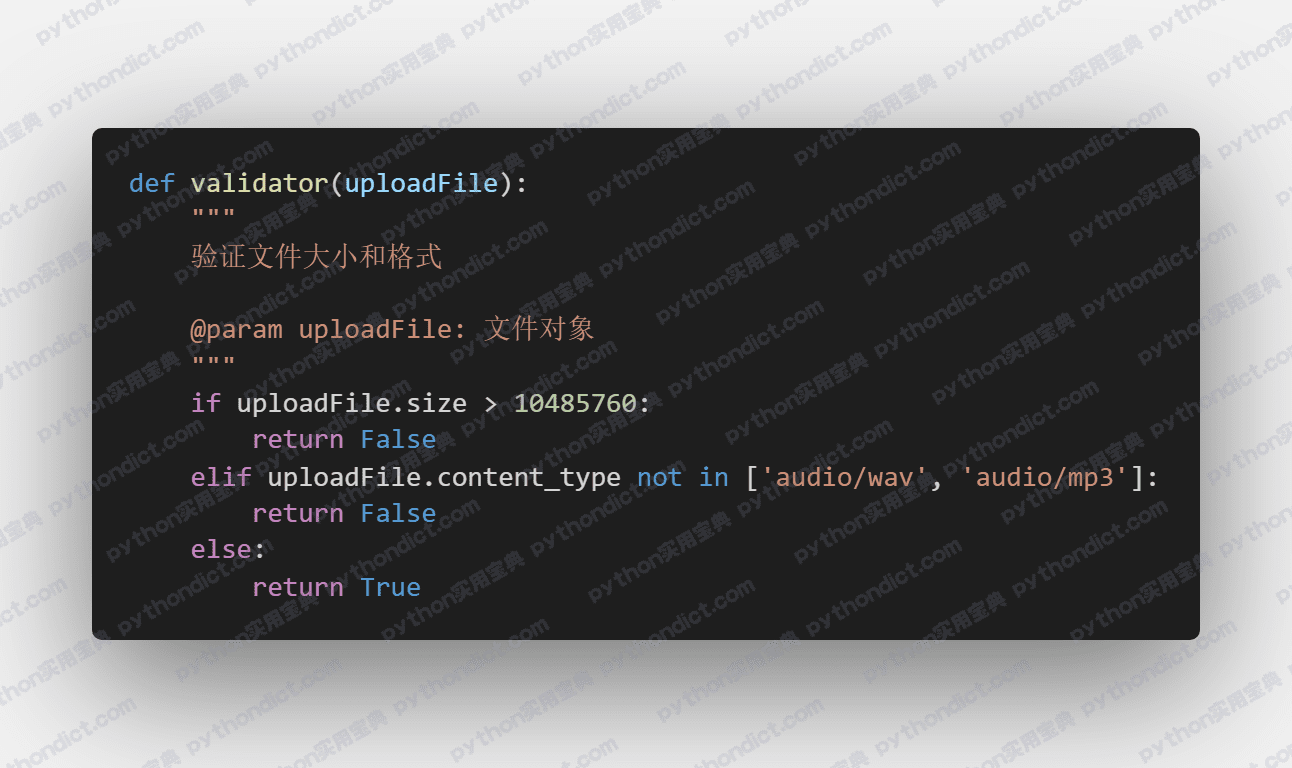
其中,后端要校验文件大小(前端校验的话容易被绕过),然后提取音乐高潮的时候前端应该有“处理中 ” 的提示,等待提取完成返回结果后,前端直接显示下载按钮。
我们先来制作允许用户提交文件这一部分。
3.4.1 编写forms表单
Django 有个我特别喜欢的特性:通过Form类能生成HTML代码,如果是做简单的页面开发,不需要用到前后端分离的情况下, 这点实在非常方便:
在extractor文件夹下新建一个forms.py的文件,写入以下代码:
接下来,在在extractor文件夹下新建templates文件夹,并在里面新建一个index.html 编写前端代码,将表单引入进来:
可以注意到,我们直接将表单以 {{ form.docfile }} 的形式引入进来生成前端表单,与此同时, {{ form.docfile.label_tag }} 可以直接将我们在类中定义的属性引入进前端。还有一点需要注意的是 {% csrf_token %},这是在Django 表单中必带的,它会在请求中注入一段token,以防止跨站攻击。
3.4.2 编写views主逻辑
接下来,我们就来编写views的主逻辑,让它接受文件上传的POST请求并渲染前端页面:
它主要做这么几件事:
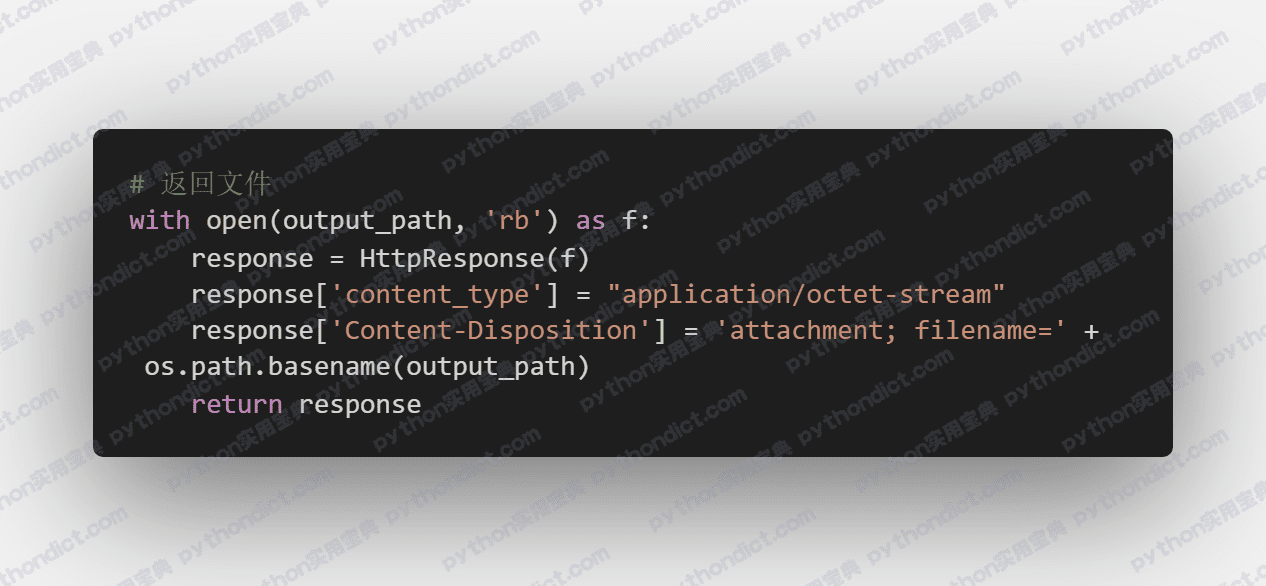
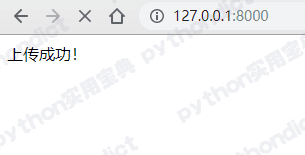
一是判断这个请求是否为POST请求,若是POST请求则进入文件上传保存的逻辑,判断用户上传的表单是否符合要求,若符合要求则保存文档,并返回HTTP回应:“上传成功!”。
二、如果不是POST请求,则说明是普通的访问,那么将生成一个空表单,渲染这个表单页面到前端,供用户提交文档。
3.5 配置路由
准备就绪了,接下来只要让我们把路由接上、再做一点简单的配置就能成功启动应用:
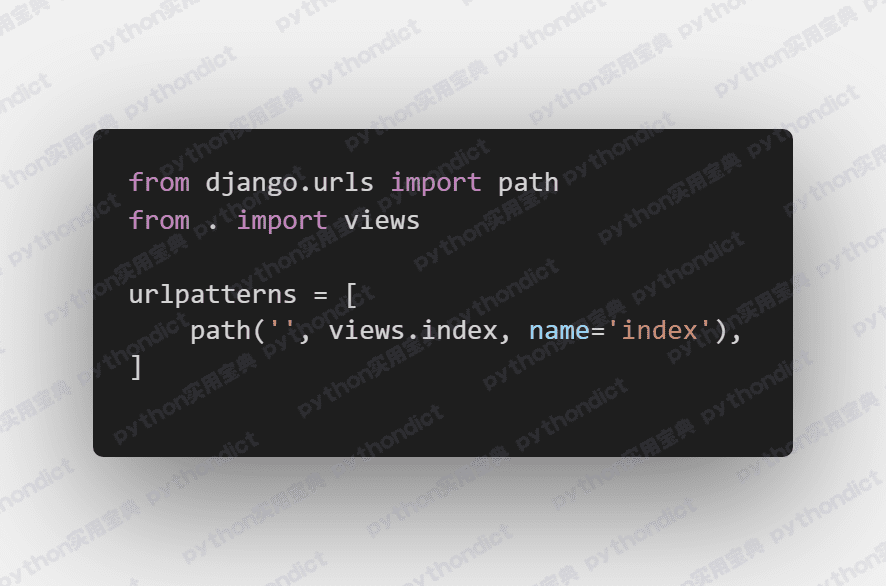
在extractor下新建一个urls.py文件,它将存放extractor即我们的提取器应用的所有路由(尽管我们就一个页面),配置如下:
它将能将直接访问域名的请求转发到views中的index函数,也就是我们刚在views.py中编写的主逻辑。不过这个是应用的路由,我们还需要修改Django 项目的主路由:
将yinyue30文件夹下的 urls.py 修改如下:
这里需要在Django 中引入include函数,然后在urlpatterns中,将所有直接指向域名的请求转发给我们刚刚编写的extractor的路由(extractor/urls.py),这样就大功告成了!
3.6 配置和迁移
我们刚刚编写了一个简单的extractor应用,由于Django 对APP是有着即插即用的特点,因此我们需要将这个应用“插入”到Django 中。
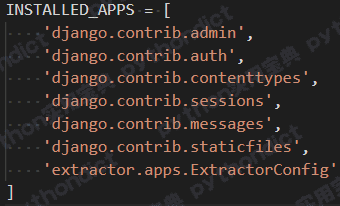
插入的方法也很简单,打开yinyue30文件夹下的settings.py, 在 INSTALLED_APPS 数组中加入 ‘extractor.apps.ExtractorConfig’ 。
最后一步,Django 中有许多自带功能需要用到数据库 和表,还有我们刚刚新建的文件模型也需要用到数据库 ,因此得新建我们所需要的东西,所幸,Django 本身自带了迁移功能,而且默认使用的是sqlite,这方便了我们这个简单应用的开发,因为我们甚至不需要去配置mysql,直接迁移。
在根目录(与manage.py同级)运行以下命令即可迁移完成:python manage.py makemigrations
第一句是生成迁移表,其实就是一些sql语句组成的文件。第二句是执行sql操作,即完成迁移功能。
4. 运行项目
接下来我们就能让项目跑起来了, 在根目录(与manage.py同级)运行以下命令运行程序:
python manage.py runserver
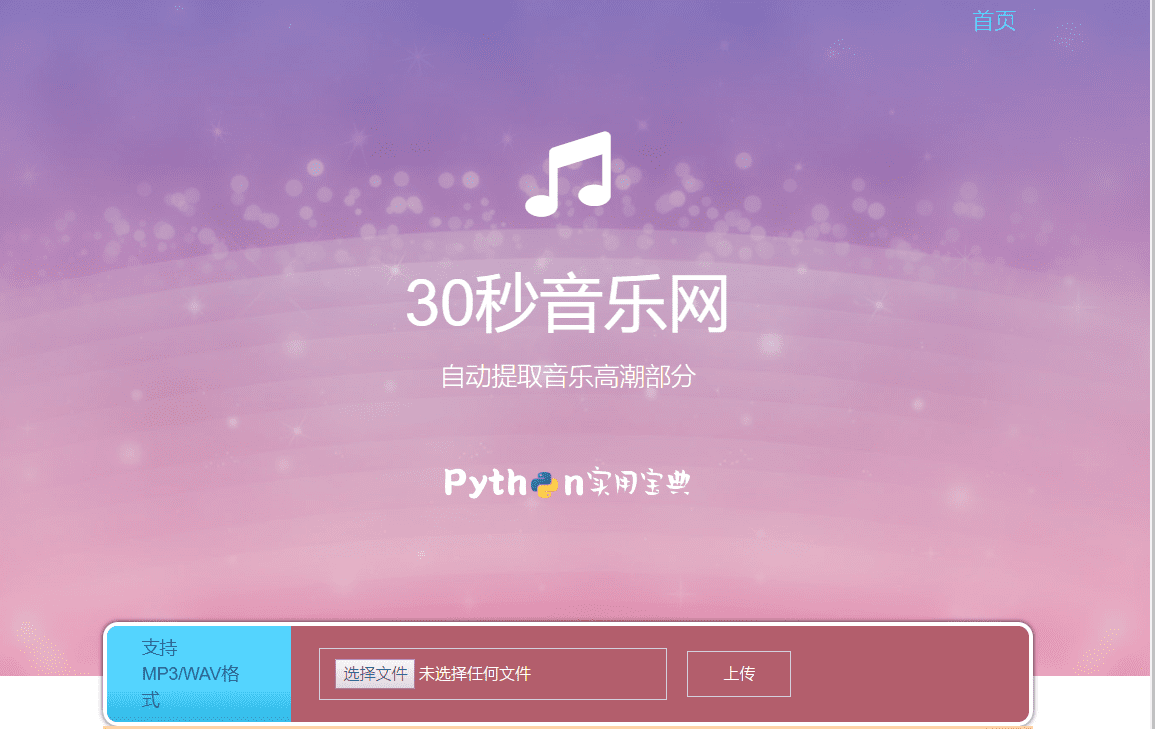
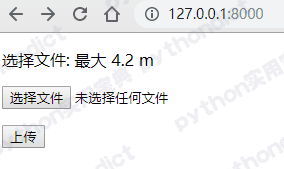
运行后访问http://127.0.0.1:8000效果如下:
尝试上传, 上传成功 :
顺便检查下是否真的传入,发现有文件在media下,放心了:
那么我们第一部分的任务就算顺利完成了!下一部分,我们将正式将音乐高潮提取器的部分加上去。 敬请期待! 关注下方公众号,后台回复 音乐高潮提取网 获得项目第一部分源代码!
我们的文章到此就结束啦,如果你希望我们今天的Python 教程 ,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦
音乐相关教程:
Python 批量下载网易云音乐歌单
Python 制作音乐高潮副歌提取器
Python Django快速开发音乐高潮提取网(1)
Python Django快速开发音乐高潮提取网(2)
Python Django快速开发音乐高潮提取网(3)
Python 超方便超快速剪辑音乐
Python 提取音乐频谱并可视化
Python实用宝典 (pythondict.com )