
本文通过两个案例,三个部分介绍了如何在 pandas 结构化数据中进行高效的范围查找。
1.简单案例讲解
Pandas案例需求
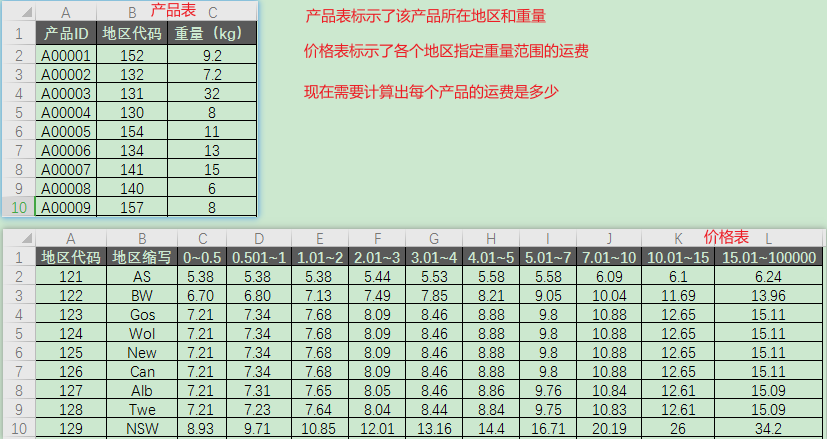
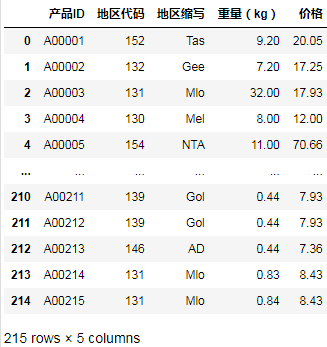
有两张表,A表记录了很多款产品的三个基础字段,分别是产品ID,地区代码和重量: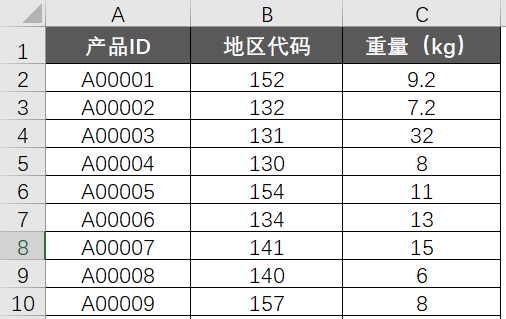
B表是运费明细表,这个表结构很“业务”。每行对应着单个地区,不同档位重量,所对应的运费:


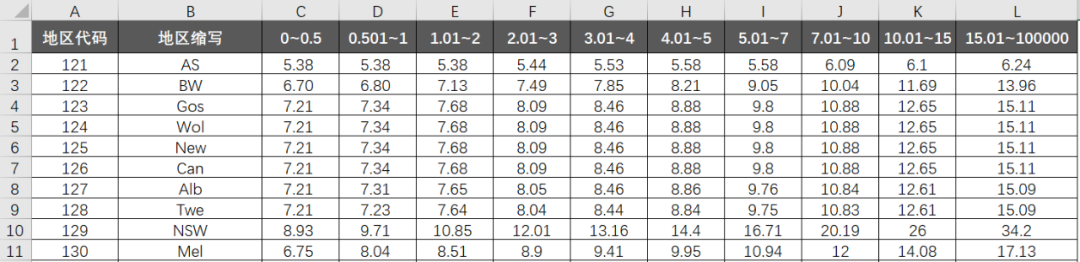
比如121地区,0-0.5kg的产品,运费是5.38元;2.01(实际应该是大于1)-3kg,运费则是5.44元。
现在,我们想要结合A表和B表,统计出A表每个产品付多少运费,应该怎么实现?
可以先自己思考一分钟!
解题思路
人海战术
任何数据需求,在人海战术面前都是弟弟。
A表一共215行,我们只需要找215个人,每个人只需要记好自己要统计那款产品的地区代码和重量字段,然后在B表中根据地区代码,找到所在地区运费标准,然后一眼扫过去,就能得到最终运费了。
两个“只需要”,问题就这样easy的解决了。
问题变成了,我还差214个人。
解构战术
通过人海战术,我们其实已经明确了解题的朴素思路:根据地区代码和重量,和B表匹配,返回运费结果。
难点在于,B表是偏透视表结构的,运费是横向分布,用Pandas就算用地区代码匹配,还是不能找到合适的运费区间。
怎么办呢?
如果我们把B表解构,变成“源数据”格式,问题就全部解决了:

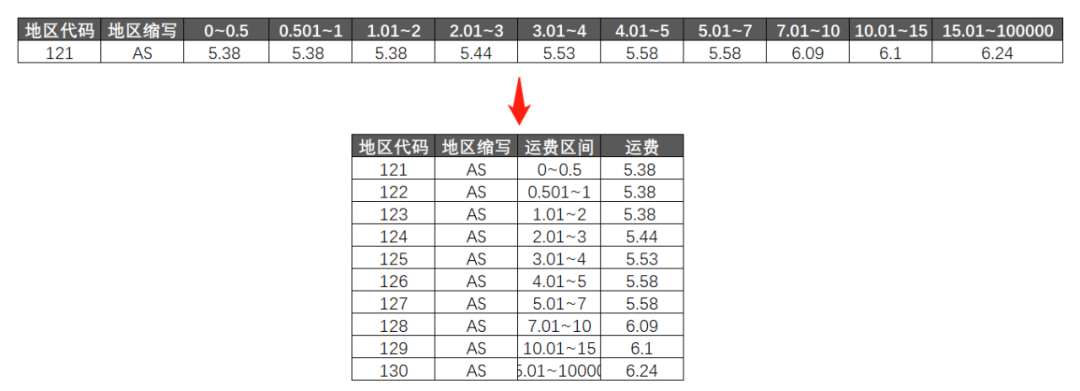
转换完成后,和A表根据地区代码做一个匹配筛选,答案就自己跑出来了。
下面是动手时刻。
具体实现
先导入数据,A表(product):


B表(cost):

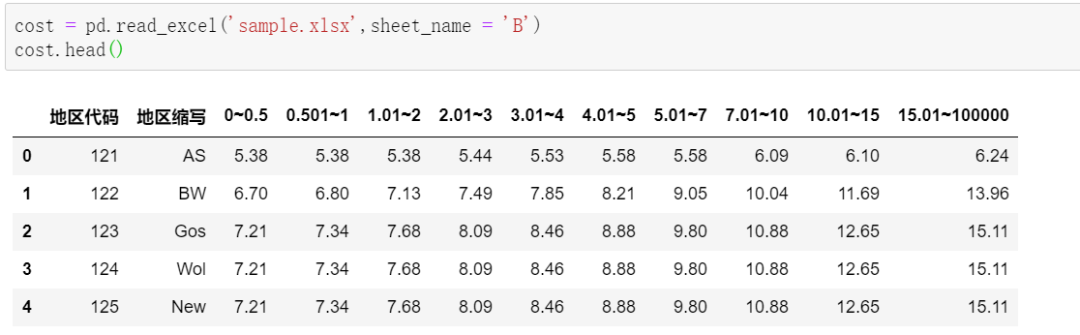
要想把B表变成“源数据”的格式,关键在于理解stack()堆叠操作,结合示例图比较容易搞懂:

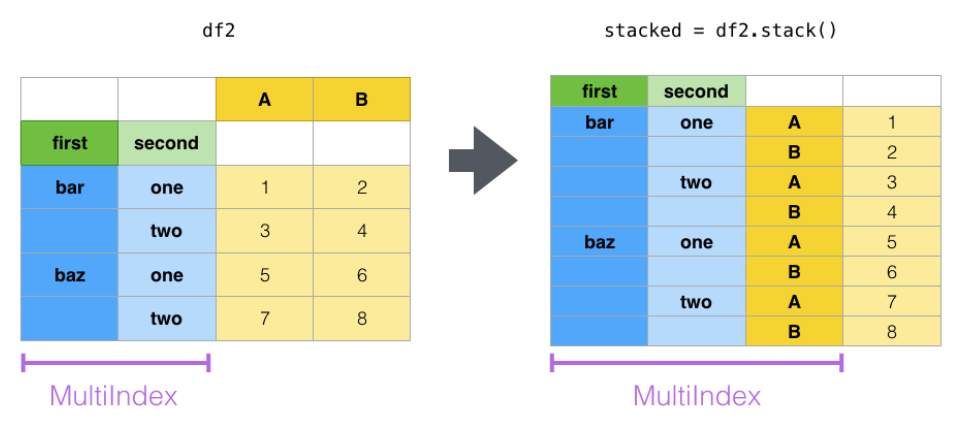
通过stack操作,把多列变为单列多行,原本的2列数据堆成了1列,从而方便了一些场景下的匹配。要变回来也很简单,unstack即可:

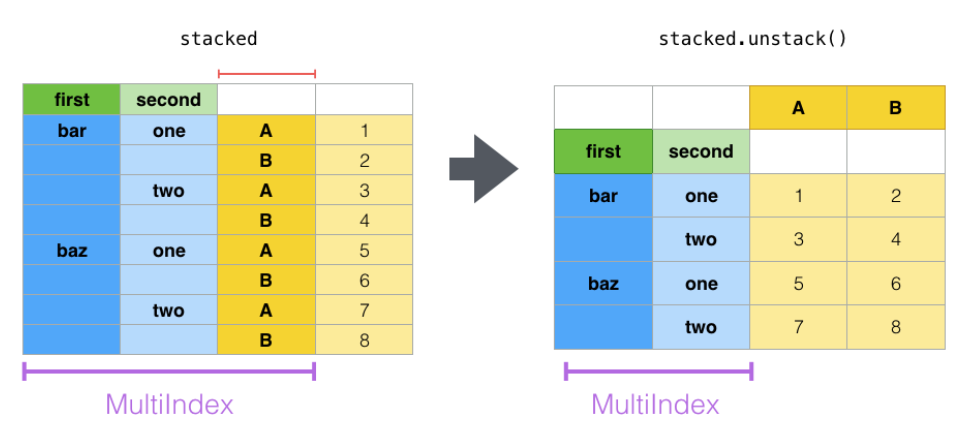
在我们的具体场景中,先指定好不变的索引列,然后直接上stack:

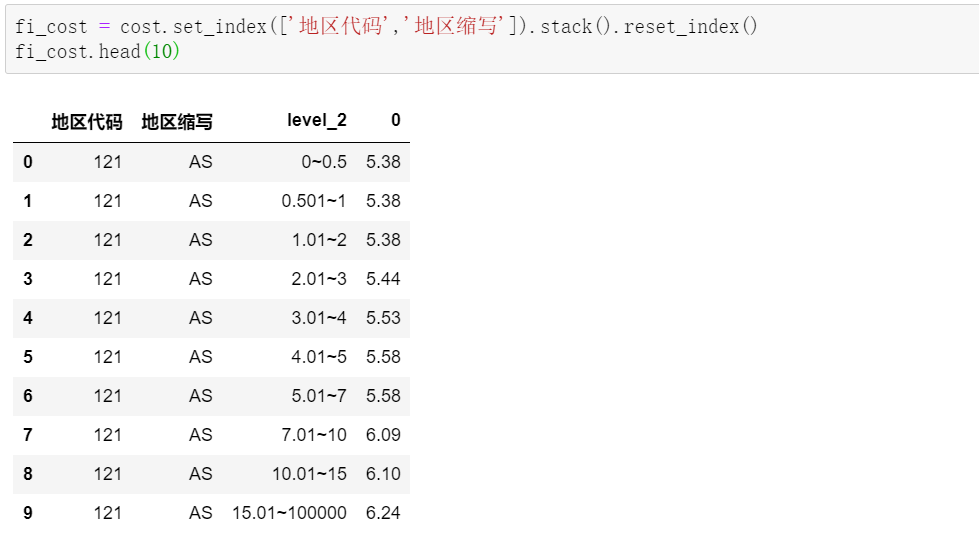
这样,就得到了我们目标的源数据。接着,A表和B表做匹配:

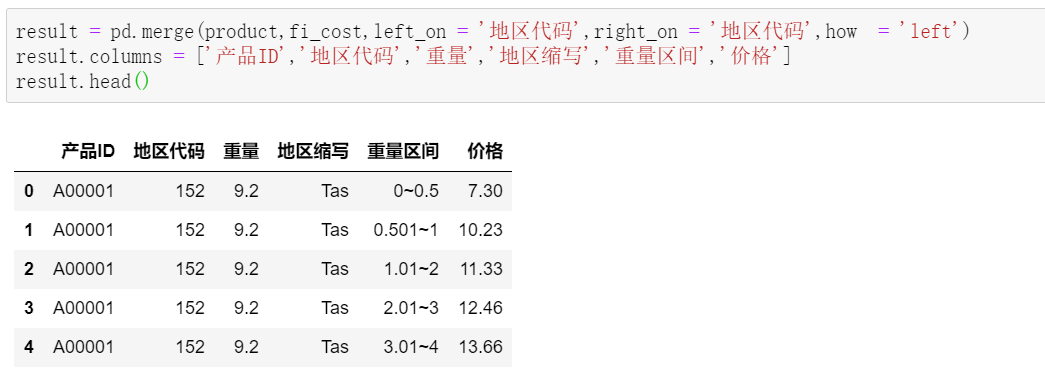
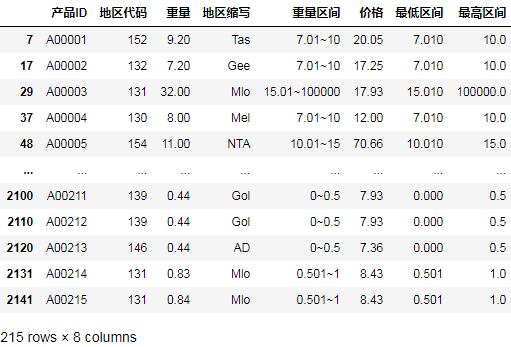
值得注意的是,因为我们根据每个地方的重量区间做了堆叠,这里的匹配结果,每个产品保留了对应地区,所有重量区间的价格,离最终结果还有一步之遥。
需要把重量区间做拆分,从而和产品重量对比,找到对应的重量区间:

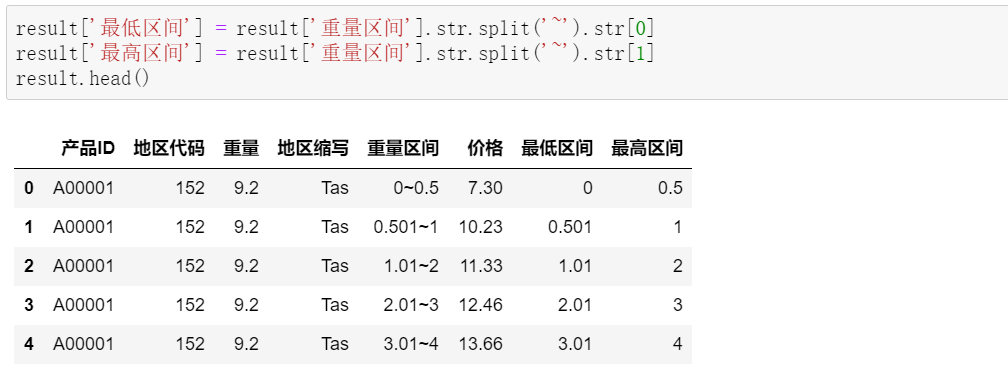
接着,根据重量的最低、最高区间,判断每一行的重量是否符合区间:

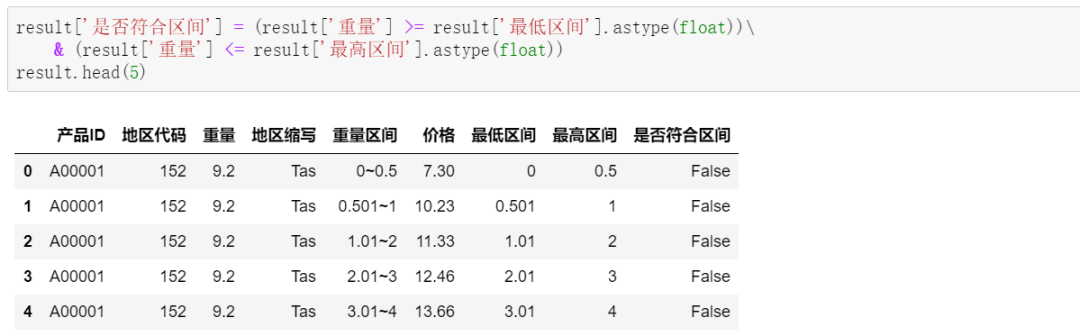
最后,筛选出符合区间的产品,及对应的价格等字段:

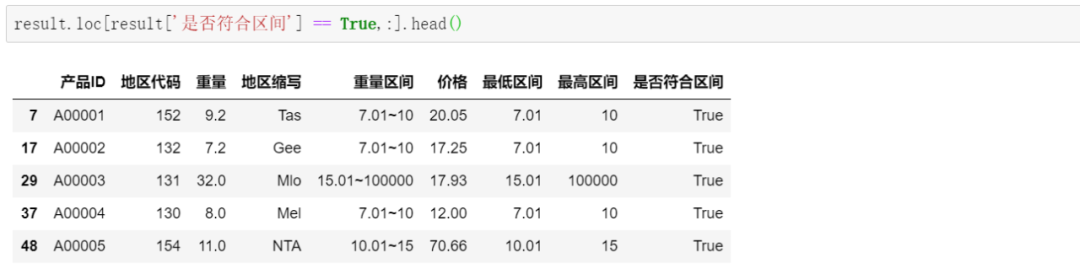
大功告成!
2.复杂一点的情况
Pandas案例需求
需求如下:

该问题最核心的解题思路是按照地区代码先将两张表关联起来,然后按照重量是否在指定的区间筛选出符合条件的记录。不同的解法实际区别也是,如何进行表关联,如何进行关联后的过滤。
上文的简化写法
简化后:
import pandas as pd
product = pd.read_excel('sample.xlsx', sheet_name='A')
cost = pd.read_excel('sample.xlsx', sheet_name='B')
fi_cost = cost.set_index(['地区代码','地区缩写']).stack().reset_index()
result = pd.merge(product, fi_cost, on='地区代码', how='left')
result.columns = ['产品ID', '地区代码', '重量', '地区缩写', '重量区间', '价格']
result[['最低区间', '最高区间']] = result['重量区间'].str.split('~', expand=True).astype(float)
result.query("最低区间<=`重量`<=最高区间")

顺序查找匹配
考虑到直接merge会产生笛卡尔积,多消耗N倍的内存,所以下面采用筛选连接法,执行耗时比merge连接稍微长点,但减少了内存消耗。
首先读取数据:
import pandas as pd
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
product = pd.read_excel('sample.xlsx', sheet_name='A')
cost = pd.read_excel('sample.xlsx', sheet_name='B')
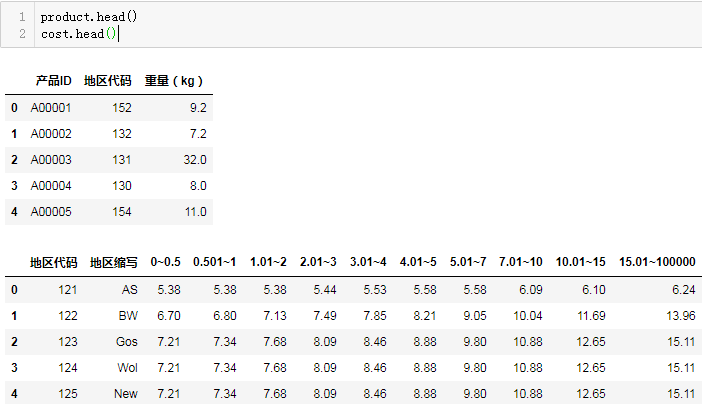
预览数据:
product.head()
cost.head()

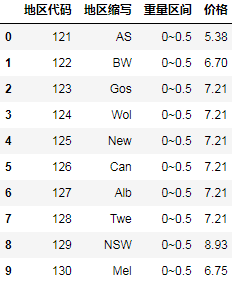
下面我们将价格表由”宽格式”旋转为”长格式”方便匹配:
fi_cost = cost.melt(id_vars=["地区代码", "地区缩写"], var_name="重量区间", value_name='价格')
fi_cost

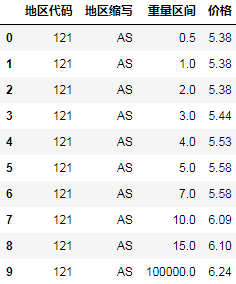
观察价格区间0~0.5, 0.501~1, 1.01~2, 2.01~3, 3.01~4, 4.01~5, 5.01~7, 7.01~10, 10.01~15, 15.01~100000我们完全可以只取前面的数字或只取后面的数字,理解为一个前闭后开或前开后闭的区间,我取重量区间的最大值来表示区间:
fi_cost.重量区间 = fi_cost.重量区间.str.split("~").str[1].astype("float")
fi_cost.sort_values(["地区代码", "重量区间"], inplace=True, ignore_index=True)
fi_cost.head(10)

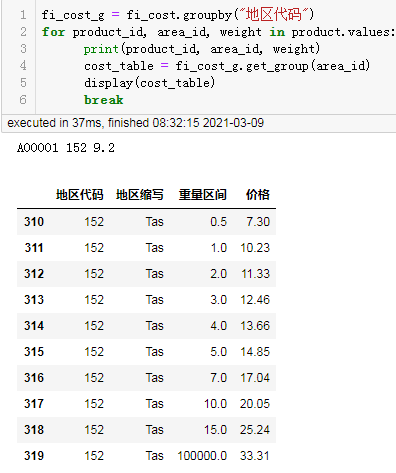
测试对第一个产品,取出对应的地区价格表:
fi_cost_g = fi_cost.groupby("地区代码")
for product_id, area_id, weight in product.values:
print(product_id, area_id, weight)
cost_table = fi_cost_g.get_group(area_id)
display(cost_table)
break

下面我们继续测试根据重量筛选出对应的价格:
fi_cost_g = fi_cost.groupby("地区代码")[["地区缩写", "重量区间", "价格"]]
for product_id, area_id, weight in product.values:
print(product_id, area_id, weight)
cost_table = fi_cost_g.get_group(area_id)
display(cost_table)
for area, weight_cost, price in cost_table.values:
if weight <= weight_cost:
print(area, price)
break
break

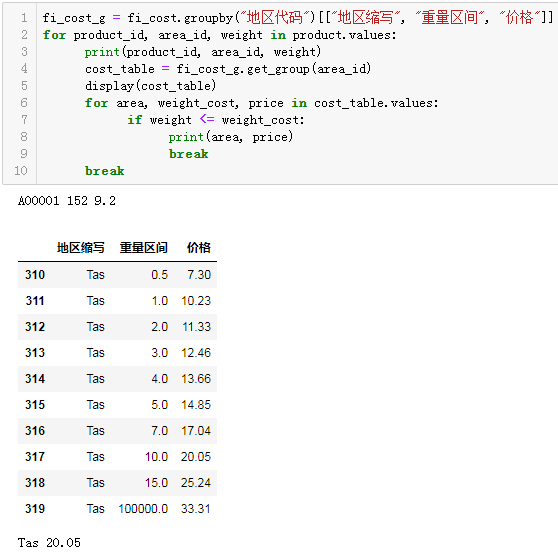
可以看到已经顺利的匹配出对应的价格是20.05。
于是完善最终代码为:
result = []
fi_cost_g = fi_cost.groupby("地区代码")[["地区缩写", "重量区间", "价格"]]
for product_id, area_id, weight in product.values:
cost_table = fi_cost_g.get_group(area_id)
for area, weight_cost, price in cost_table.values:
if weight <= weight_cost:
break
result.append((product_id, area_id, area, weight, price))
result = pd.DataFrame(result, columns=["产品ID", "地区代码", "地区缩写", "重量(kg)", "价格"])
result

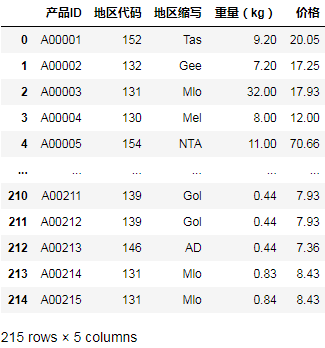
成功匹配出每个产品对应的地区简写和价格。
顺序查找匹配的完整代码为:
import pandas as pd
product = pd.read_excel('sample.xlsx', sheet_name='A')
cost = pd.read_excel('sample.xlsx', sheet_name='B')
fi_cost = cost.melt(id_vars=["地区代码", "地区缩写"], var_name="重量区间", value_name='价格')
fi_cost.重量区间 = fi_cost.重量区间.str.split("~").str[1].astype("float")
fi_cost.sort_values(["地区代码", "重量区间"], inplace=True, ignore_index=True)
result = []
fi_cost_g = fi_cost.groupby("地区代码")[["地区缩写", "重量区间", "价格"]]
for product_id, area_id, weight in product.values:
cost_table = fi_cost_g.get_group(area_id)
for area, weight_cost, price in cost_table.values:
if weight <= weight_cost:
break
result.append((product_id, area_id, area, weight, price))
result = pd.DataFrame(result, columns=["产品ID", "地区代码", "地区缩写", "重量(kg)", "价格"])
result3.优化方案
前面两部分内容就已经解决了问题,考虑到上述区间查找其实是一个顺序查找的问题,所以我们可以使用二分查找进一步优化减少查找次数。
当然二分查找对于这种2位数级别的区间个数查找优化不明显,但是当区间增加到万级别,几十万的级别时,那个查找效率一下子就体现出来了,大概就是几万次查找和几次查找的区别。
字典查找+二分查找高效匹配
本次优化,主要通过字典查询大幅度加快了查询的效率,几乎实现了将非等值连接转换为等值连接。
首先读取数据:
import pandas as pd
product = pd.read_excel('sample.xlsx', sheet_name='A')
cost = pd.read_excel('sample.xlsx', sheet_name='B')
cost.head()

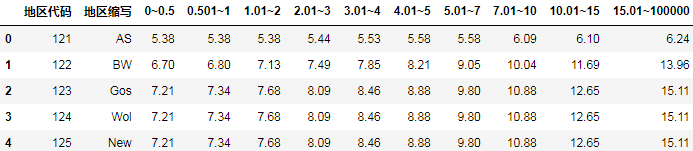
下面计划将价格表直接转换为能根据地区代码和索引快速查找价格的字典。
先取出区间范围列表,用于索引位置查找:
price_range = cost.columns[2:].str.split("~").str[1].astype("float").tolist()
price_range
结果:
[0.5, 1.0, 2.0, 3.0, 4.0, 5.0, 7.0, 10.0, 15.0, 100000.0]
下面将测试二分查找的效果:
import bisect
import numpy as np
for a in np.linspace(0.5, 5, 10):
idx = bisect.bisect_left(price_range, a)
print(a, idx)
结果:
0.5 0
1.0 1
1.5 2
2.0 2
2.5 3
3.0 3
3.5 4
4.0 4
4.5 5
5.0 5
可以打印索引列表方便对比:
print(*enumerate(price_range))
结果:
(0, 0.5) (1, 1.0) (2, 2.0) (3, 3.0) (4, 4.0) (5, 5.0) (6, 7.0) (7, 10.0) (8, 15.0) (9, 100000.0)
经过对比可以看到,二分查找可以正确的找到一个指定的重量在重量区间的索引位置。
于是我们可以构建地区代码和索引位置作联合主键快速查找价格的字典:
cost_dict = {}
for area_id, area, *prices in cost.values:
for idx, price in enumerate(prices):
cost_dict[(area_id, idx)] = area, price
然后就可以批量查找对应的运费了:
result = []
for product_id, area_id, weight in product.values:
idx = bisect.bisect_left(price_range, weight)
area, price = cost_dict[(area_id, idx)]
result.append((product_id, area_id, area, weight, price))
result = pd.DataFrame(result, columns=["产品ID", "地区代码", "地区缩写", "重量(kg)", "价格"])
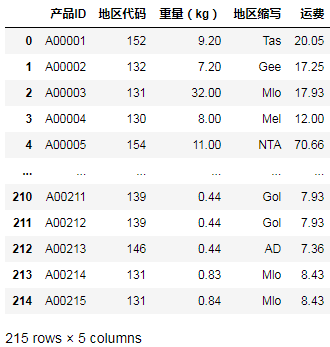
result

字典查找+二分查找高效匹配的完整代码:
import pandas as pd
import bisect
product = pd.read_excel('sample.xlsx', sheet_name='A')
cost = pd.read_excel('sample.xlsx', sheet_name='B')
price_range = cost.columns[2:].str.split("~").str[1].astype("float").tolist()
cost_dict = {}
for area_id, area, *prices in cost.values:
for idx, price in enumerate(prices):
cost_dict[(area_id, idx)] = area, price
result = []
for product_id, area_id, weight in product.values:
idx = bisect.bisect_left(price_range, weight)
area, price = cost_dict[(area_id, idx)]
result.append((product_id, area_id, area, weight, price))
result = pd.DataFrame(result, columns=["产品ID", "地区代码", "地区缩写", "重量(kg)", "价格"])
result
两种算法的性能对比

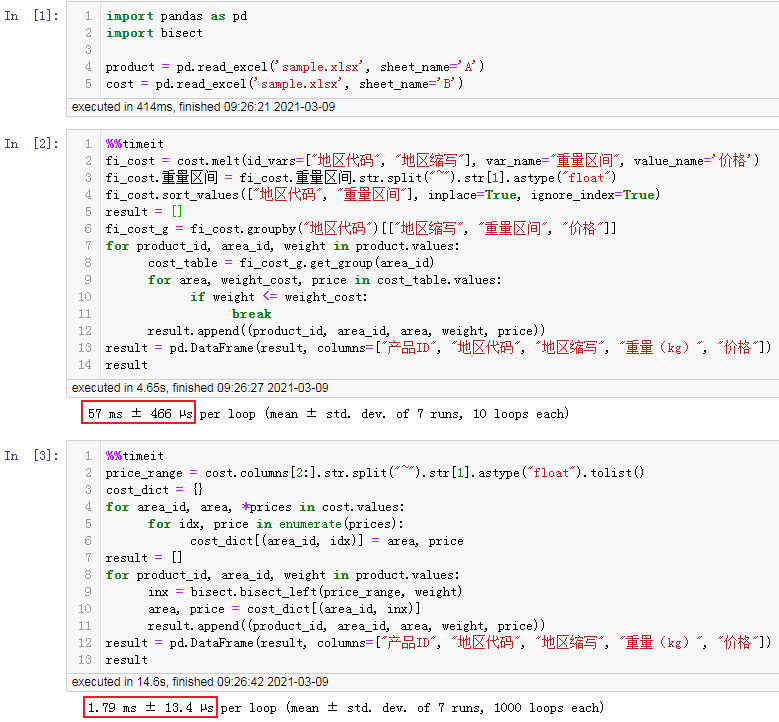
可以看到即使如此小的数据量下依然存在几十倍的性能差异,将来更大的数量量时,性能差异会更大。
将非等值连接转换为等值连接
基于以上测试,我们可以将非等值连接转换为等值连接直接连接出结果,完整代码如下:
import pandas as pd
import bisect
product = pd.read_excel('sample.xlsx', sheet_name='A')
cost = pd.read_excel('sample.xlsx', sheet_name='B')
price_range = cost.columns[2:].str.split("~").str[1].astype("float").tolist()
cost.columns = ["地区代码", "地区缩写"]+list(range(cost.shape[1]-2))
cost = cost.melt(id_vars=["地区代码", "地区缩写"],
var_name='idx', value_name='运费')
product["idx"] = product["重量(kg)"].apply(
lambda weight: bisect.bisect_left(price_range, weight))
result = pd.merge(product, cost, on=['地区代码', 'idx'], how='left')
result.drop(columns=["idx"], inplace=True)
result

该方法的平均耗时为6ms:


我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

