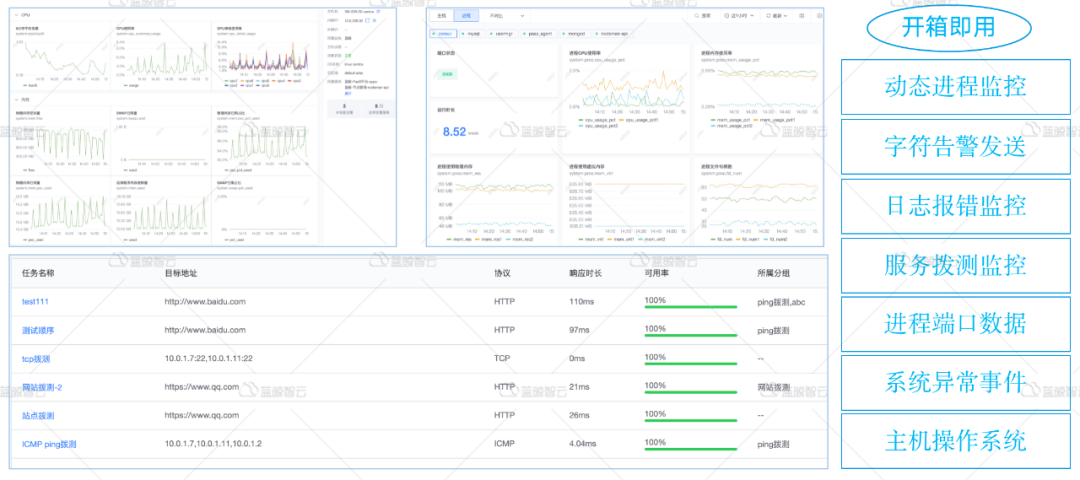
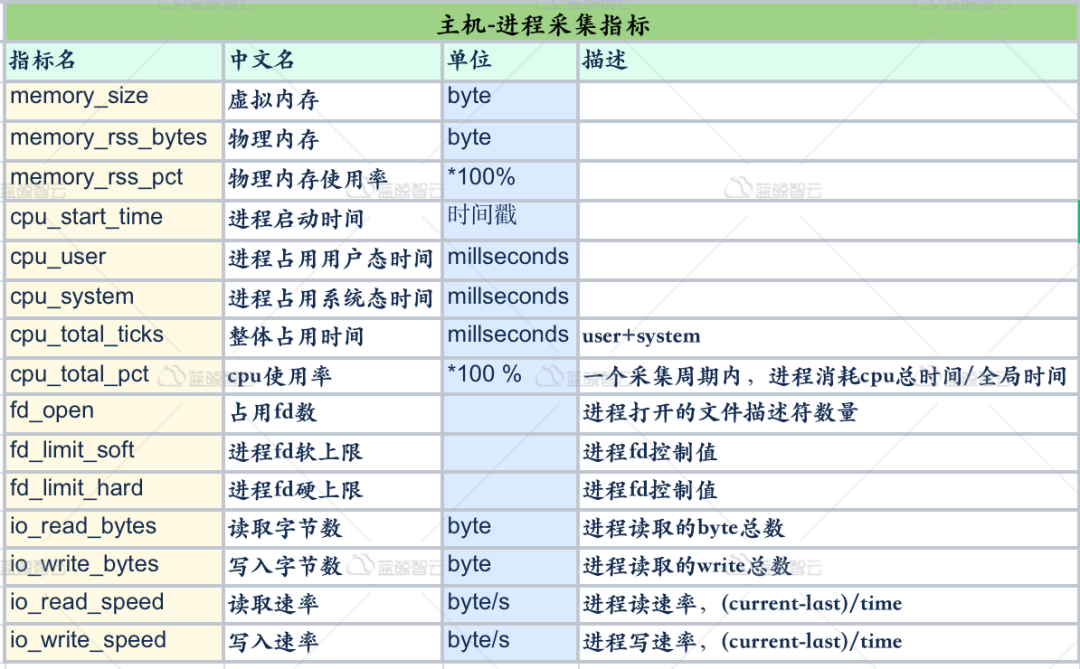
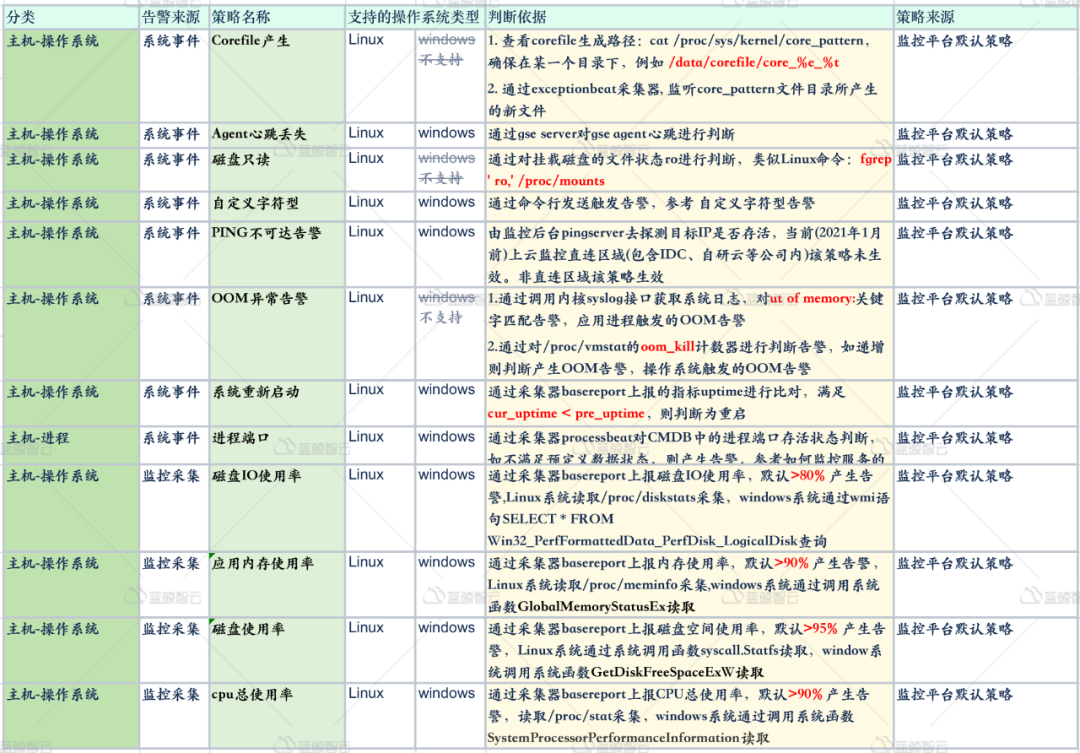
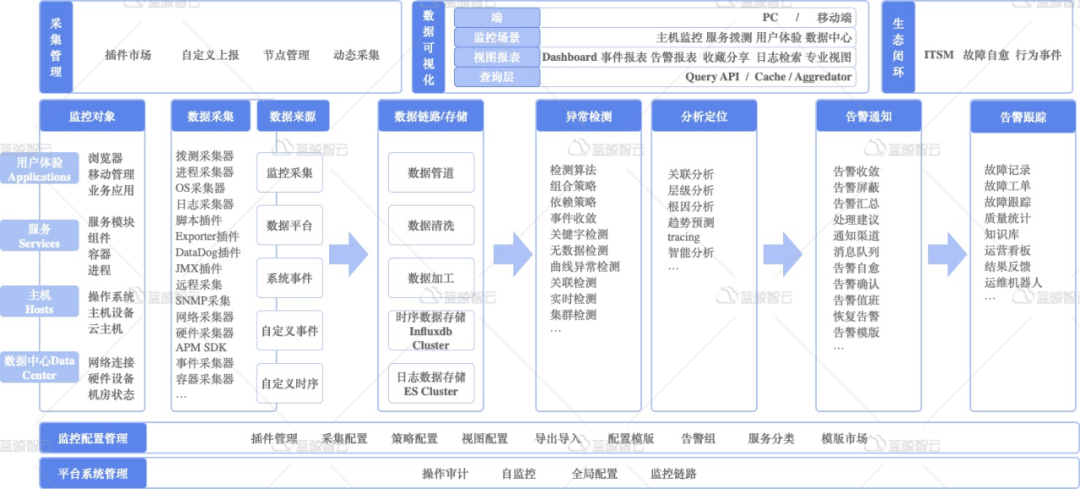
# HELP mysql_slave_status_slave_sql_running Generic metric from SHOW SLAVE STATUS. # TYPE mysql_slave_status_slave_sql_running untyped mysql_slave_status_slave_sql_running{channel_name="",connection_name="",master_host="172.16.1.1",master_uuid=""} 1
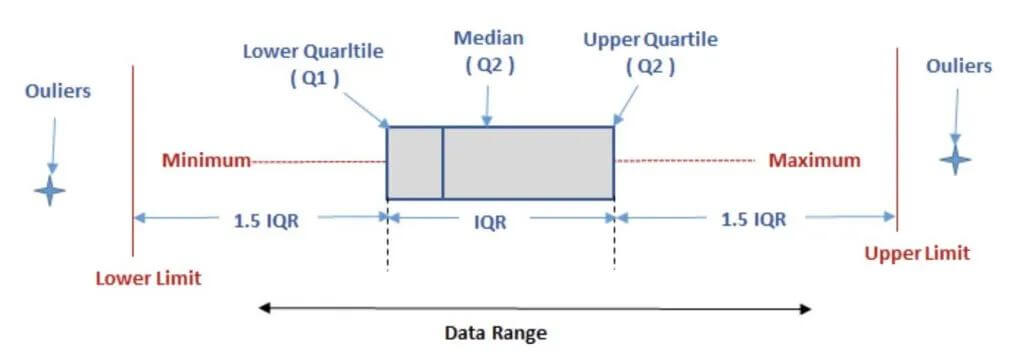
2、主从复制落后时间:
在使用show slave status 里面还有一个关键的参数Seconds_Behind_Master。Seconds_Behind_Master表示slave上SQL thread与IO thread之间的延迟,我们都知道在MySQL的复制环境中,slave先从master上将binlog拉取到本地(通过IO thread),然后通过SQL thread将binlog重放,而Seconds_Behind_Master表示本地relaylog中未被执行完的那部分的差值。所以如果slave拉取到本地的relaylog(实际上就是binlog,只是在slave上习惯称呼relaylog而已)都执行完,此时通过show slave status看到的会是0
# HELP mysql_slave_status_seconds_behind_master Generic metric from SHOW SLAVE STATUS. # TYPE mysql_slave_status_seconds_behind_master untyped mysql_slave_status_seconds_behind_master{channel_name="",connection_name="",master_host="172.16.1.1",master_uuid=""} 0
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Questions"; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | Questions | 15071 | +---------------+-------+
# HELP mysql_global_status_questions Generic metric from SHOW GLOBAL STATUS. # TYPE mysql_global_status_questions untyped mysql_global_status_questions13253
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Com_insert"; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | Com_insert | 10578 | +---------------+-------+
# HELP mysql_global_status_commands_total Total number of executed MySQL commands. # TYPE mysql_global_status_commands_total counter mysql_global_status_commands_total{command="create_trigger"} 0 mysql_global_status_commands_total{command="create_udf"} 0 mysql_global_status_commands_total{command="create_user"} 1 mysql_global_status_commands_total{command="create_view"} 0 mysql_global_status_commands_total{command="dealloc_sql"} 0 mysql_global_status_commands_total{command="delete"} 3369 mysql_global_status_commands_total{command="delete_multi"} 0
MariaDB [(none)]> SHOW VARIABLES LIKE 'long_query_time'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+ 1 row in set (0.00 sec)
当然我们也可以修改时间
MariaDB [(none)]> SET GLOBAL long_query_time = 5; Query OK, 0 rows affected (0.00 sec)
然后我们而已通过sql语言查询MySQL实例中Slow_queries的数量:
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Slow_queries"; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | Slow_queries | 0 | +---------------+-------+ 1 row in set (0.00 sec)
# HELP mysql_global_status_slow_queries Generic metric from SHOW GLOBAL STATUS. # TYPE mysql_global_status_slow_queries untyped mysql_global_status_slow_queries0
MariaDB [(none)]> SHOW VARIABLES LIKE 'max_connections'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_connections | 151 | +-----------------+-------+
当然我们可以修改配置文件的形式来增加这个数值。与之对应的就是当前连接数量,当我们当前连接出来超过系统设置的最大值之后常会出现我们看到的Too many connections(连接数过多),下面我查找一下当前连接数:
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Threads_connected"; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | Threads_connected | 41 | +-------------------+-------
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Threads_running"; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | Threads_running | 10 | +-----------------+-------+
# HELP mysql_global_variables_max_connections Generic gauge metric from SHOW GLOBAL VARIABLES. # TYPE mysql_global_variables_max_connections gauge mysql_global_variables_max_connections151
表示最大连接数
# HELP mysql_global_status_threads_connected Generic metric from SHOW GLOBAL STATUS. # TYPE mysql_global_status_threads_connected untyped mysql_global_status_threads_connected41
表示当前的连接数
# HELP mysql_global_status_threads_running Generic metric from SHOW GLOBAL STATUS. # TYPE mysql_global_status_threads_running untyped mysql_global_status_threads_running1
表示当前活跃的连接数
# HELP mysql_global_status_aborted_connects Generic metric from SHOW GLOBAL STATUS. # TYPE mysql_global_status_aborted_connects untyped mysql_global_status_aborted_connects31
累计所有的连接数
# HELP mysql_global_status_connection_errors_total Total number of MySQL connection errors. # TYPE mysql_global_status_connection_errors_total counter mysql_global_status_connection_errors_total{error="internal"} 0 #服务器内部引起的错误、如内存硬盘等 mysql_global_status_connection_errors_total{error="max_connections"} 0 #超出连接处引起的错误
MariaDB [(none)]> show global variables like 'innodb_buffer_pool_size'; +-------------------------+-----------+ | Variable_name | Value | +-------------------------+-----------+ | innodb_buffer_pool_size | 134217728 | +-------------------------+-----------+
# HELP mysql_global_variables_innodb_buffer_pool_size Generic gauge metric from SHOW GLOBAL VARIABLES. # TYPE mysql_global_variables_innodb_buffer_pool_size gauge mysql_global_variables_innodb_buffer_pool_size 1.34217728e+08
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Innodb_buffer_pool_read_requests"; +----------------------------------+-------------+ | Variable_name | Value | +----------------------------------+-------------+ | Innodb_buffer_pool_read_requests | 38465 | +----------------------------------+-------------+
# HELP mysql_global_status_innodb_buffer_pool_read_requests Generic metric from SHOW GLOBAL STATUS. # TYPE mysql_global_status_innodb_buffer_pool_read_requests untyped mysql_global_status_innodb_buffer_pool_read_requests2.7711547168e+10
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Innodb_buffer_pool_reads"; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | Innodb_buffer_pool_reads | 138 | +--------------------------+-------+ 1 row in set (0.00 sec)
# HELP mysql_global_status_innodb_buffer_pool_reads Generic metric from SHOW GLOBAL STATUS. # TYPE mysql_global_status_innodb_buffer_pool_reads untyped mysql_global_status_innodb_buffer_pool_reads138
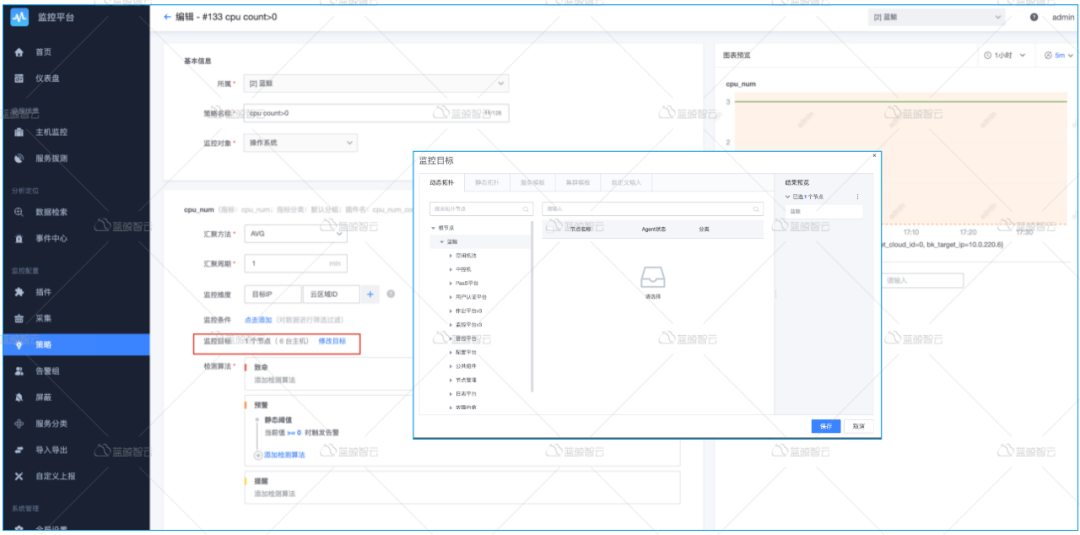
groups: - name: MySQL-rules rules: - alert: MySQL Status expr: up == 0 for: 5s labels: severity: warning annotations: summary: "{{$labels.instance}}: MySQL has stop !!!" description: "检测MySQL数据库运行状态"
- alert: MySQL Slave IO Thread Status expr: mysql_slave_status_slave_io_running == 0 for: 5s labels: severity: warning annotations: summary: "{{$labels.instance}}: MySQL Slave IO Thread has stop !!!" description: "检测MySQL主从IO线程运行状态"
- alert: MySQL Slave SQL Thread Status expr: mysql_slave_status_slave_sql_running == 0 for: 5s labels: severity: warning annotations: summary: "{{$labels.instance}}: MySQL Slave SQL Thread has stop !!!" description: "检测MySQL主从SQL线程运行状态"
- alert: MySQL Slave Delay Status expr: mysql_slave_status_sql_delay == 30 for: 5s labels: severity: warning annotations: summary: "{{$labels.instance}}: MySQL Slave Delay has more than 30s !!!" description: "检测MySQL主从延时状态"
- alert: Mysql_Too_Many_slow_queries expr: rate(mysql_global_status_slow_queries[5m]) > 3 for: 2m labels: severity: warning annotations: summary: "{{$labels.instance}}: 慢查询有点多,请检查处理" description: "{{$labels.instance}}: Mysql slow_queries is more than 3 per second ,(current value is: {{ $value }})"