def tex_coord(x, y, n=4):
""" Return the bounding vertices of the texture square.
"""
m = 1.0 / n
dx = x * m
dy = y * m
return dx, dy, dx + m, dy, dx + m, dy + m, dx, dy + m
def tex_coords(top, bottom, side):
""" Return a list of the texture squares for the top, bottom and side.
"""
top = tex_coord(*top)
bottom = tex_coord(*bottom)
side = tex_coord(*side)
result = []
result.extend(top)
result.extend(bottom)
result.extend(side * 4)
return result
TEXTURE_PATH = 'texture.png'
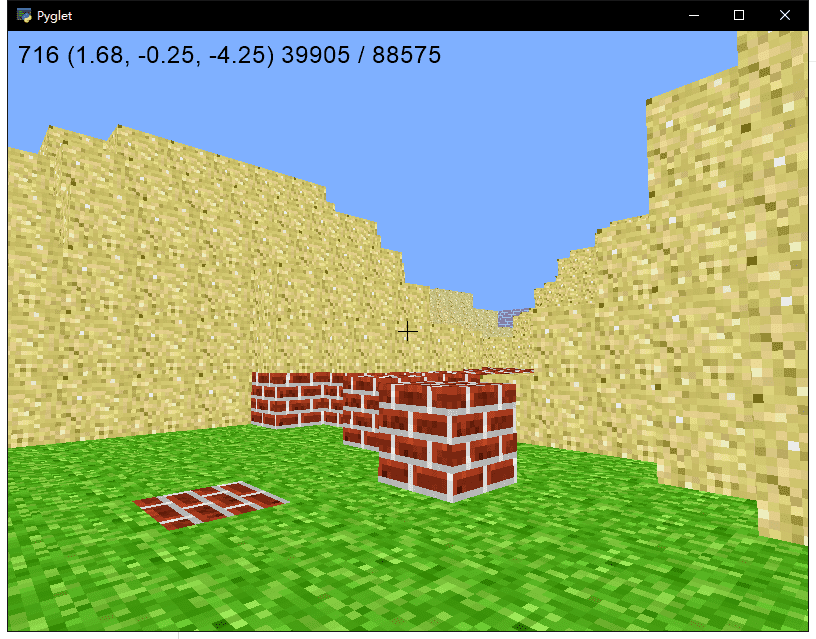
GRASS = tex_coords((1, 0), (0, 1), (0, 0))
SAND = tex_coords((1, 1), (1, 1), (1, 1))
BRICK = tex_coords((2, 0), (2, 0), (2, 0))
STONE = tex_coords((2, 1), (2, 1), (2, 1))
from diagrams import Cluster, Diagram
from diagrams.aws.compute import ECS
from diagrams.aws.database import RDS
from diagrams.aws.network import Route53
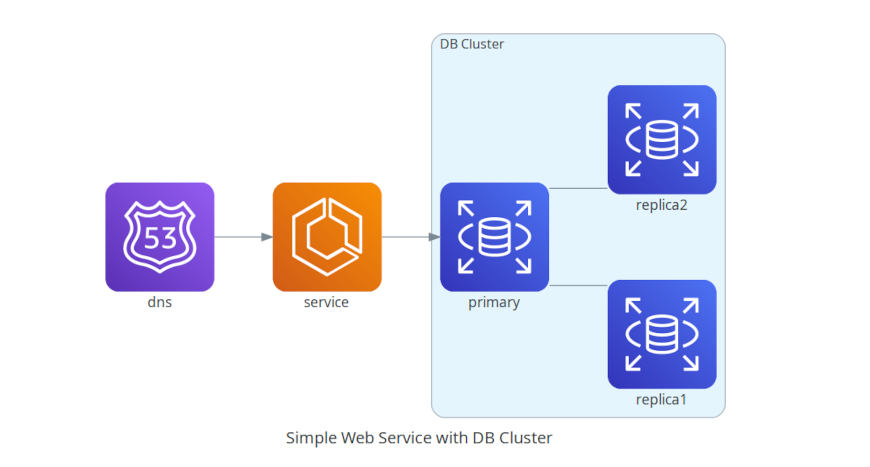
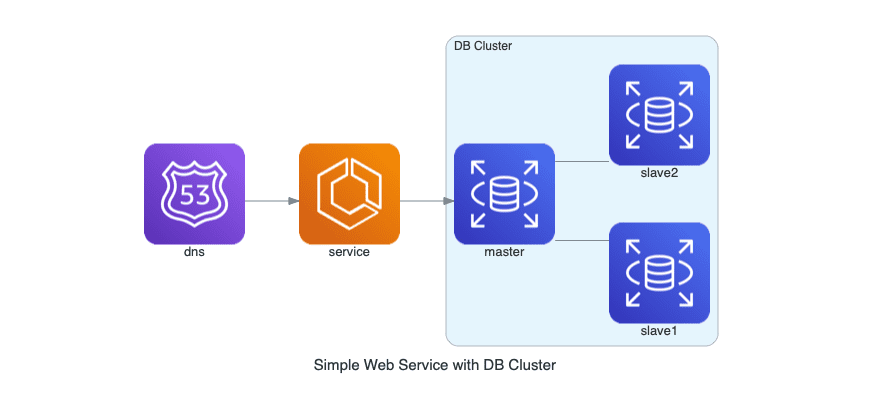
with Diagram("Simple Web Service with DB Cluster", show=False):
dns = Route53("dns")
web = ECS("service")
with Cluster("DB Cluster"):
db_master = RDS("master")
db_master - [RDS("slave1"),
RDS("slave2")]
dns >> web >> db_master
from diagrams import Diagram
from diagrams.aws.compute import EC2
from diagrams.aws.database import RDS
from diagrams.aws.network import ELB
from diagrams.aws.storage import S3
# show参数表示是否自动打开图像
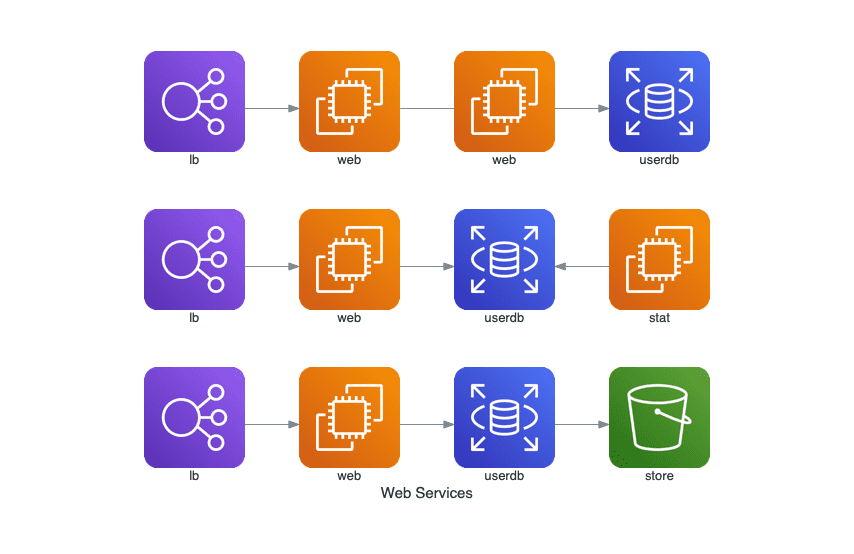
with Diagram("Web Services", show=False):
ELB("lb") >> EC2("web") >> RDS("userdb") >> S3("store")
ELB("lb") >> EC2("web") >> RDS("userdb") << EC2("stat")
(ELB("lb") >> EC2("web")) - EC2("web") >> RDS("userdb")
几个操作符:
>> 表示从左到右的数据流 << 表示从右到左的数据流 – 表示没有箭头的数据流
可以用变量赋值的形式简化代码:
from diagrams import Diagram
from diagrams.aws.compute import EC2
from diagrams.aws.database import RDS
from diagrams.aws.network import ELB
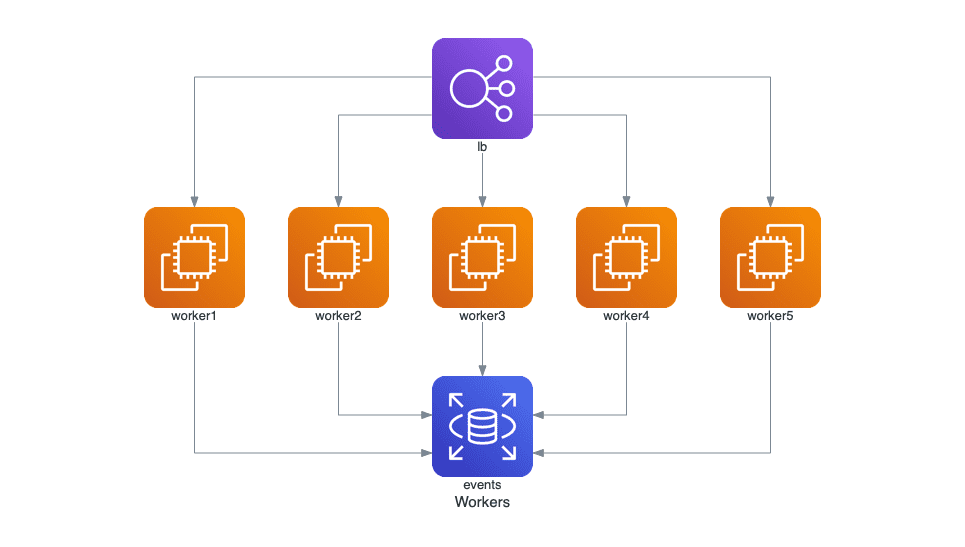
with Diagram("Workers", show=False, direction="TB"):
lb = ELB("lb")
db = RDS("events")
lb >> EC2("worker1") >> db
lb >> EC2("worker2") >> db
lb >> EC2("worker3") >> db
lb >> EC2("worker4") >> db
lb >> EC2("worker5") >> db
可以看到这里箭头的方向变了,这是因为Diagram加了direction参数,TB 表示数据流向 top to bottm, 即从上到下,可选的其他参数还有:LR(左至右)、BT(底至上)、RL(右至左)。
上面的代码还可以用数组的形式进一步简化:
from diagrams import Diagram
from diagrams.aws.compute import EC2
from diagrams.aws.database import RDS
from diagrams.aws.network import ELB
with Diagram("Grouped Workers", show=False, direction="TB"):
ELB("lb") >> [EC2("worker1"),
EC2("worker2"),
EC2("worker3"),
EC2("worker4"),
EC2("worker5")] >> RDS("events")
2.3 集群块
使用Cluster 类 并用with以上下文的形式,你可以非常方便地生成一个集群块:
from diagrams import Cluster, Diagram
from diagrams.aws.compute import ECS
from diagrams.aws.database import RDS
from diagrams.aws.network import Route53
with Diagram("Simple Web Service with DB Cluster", show=False):
dns = Route53("dns")
web = ECS("service")
with Cluster("DB Cluster"):
db_master = RDS("master")
db_master - [RDS("slave1"),
RDS("slave2")]
dns >> web >> db_master
而且还可以做得相当复杂:
这里代码很简单,但是比较长,不展示了,有兴趣的话可以点击最下方阅读原文进行查看。
from diagrams import Cluster, Diagram
from diagrams.aws.compute import ECS, EKS, Lambda
from diagrams.aws.database import Redshift
from diagrams.aws.integration import SQS
from diagrams.aws.storage import S3
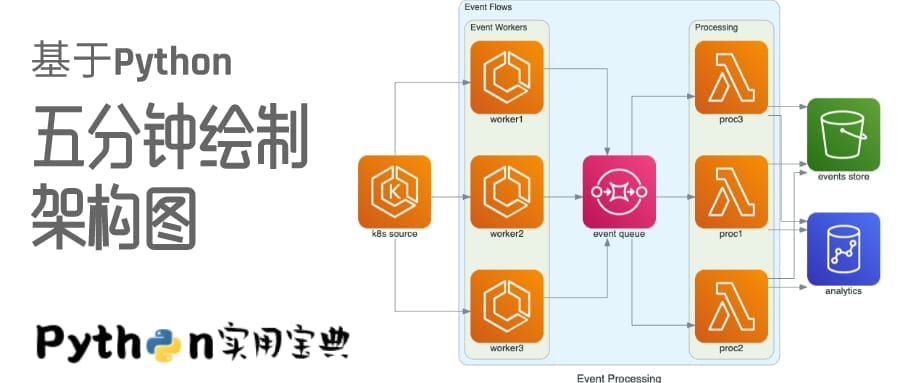
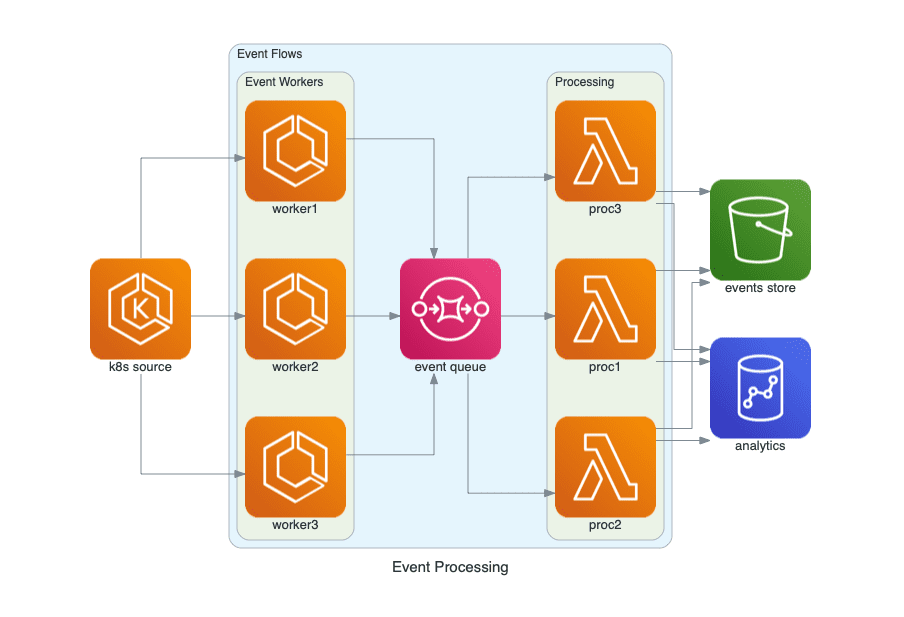
with Diagram("Event Processing", show=False):
source = EKS("k8s source")
with Cluster("Event Flows"):
with Cluster("Event Workers"):
workers = [ECS("worker1"),
ECS("worker2"),
ECS("worker3")]
queue = SQS("event queue")
with Cluster("Processing"):
handlers = [Lambda("proc1"),
Lambda("proc2"),
Lambda("proc3")]
store = S3("events store")
dw = Redshift("analytics")
source >> workers >> queue >> handlers
handlers >> store
handlers >> dw
>>> print(data['first_name'])
['John', 'George', 'Henry']
>>> print(data)
First Name|Last Name |age
----------|----------|---
John |Adams |90
George |Washington|67
Henry |Ford |83
>>> data.get_col(1)
['Adams', 'Washington', 'Ford']
删除记录
>>> del data[1]
>>> print(data)
First Name|Last Name|age
----------|---------|---
John |Adams |90
Henry |Ford |83
>>> data.yaml
'- {First Name: John, Last Name: Adams, age: 90}\n- {First Name: Henry, Last Name: Ford, age: 83}\n'
>>> print(data.yaml)
- {First Name: John, Last Name: Adams, age: 90}
- {First Name: Henry, Last Name: Ford, age: 83}
>> f = open('data.yaml', 'w', encoding='utf-8')
>> f.write(data.yaml)
>> f.close()
excel
>>> with open('people.xls', 'wb') as f:
... f.write(data.xls)
注意要以二进制形式打开文件
dbf
>>> with open('people.dbf', 'wb') as f:
... f.write(data.dbf)
高级使用
动态列
可以将一个函数指定给Dataset对象
import random
def random_grade(row):
"""Returns a random integer for entry."""
return (random.randint(60,100)/100.0)
data.append_col(random_grade, header='Grade')
>>> data.yaml
- {Age: 22, First Name: Kenneth, Grade: 0.6, Last Name: Reitz}
- {Age: 20, First Name: Bessie, Grade: 0.75, Last Name: Monke}
函数的参数row传入的是每一行记录,所以可以根据传入的记录进行更一步的计算:
def guess_gender(row):
"""Calculates gender of given student data row."""
m_names = ('Kenneth', 'Mike', 'Yuri')
f_names = ('Bessie', 'Samantha', 'Heather')
name = row[0]
if name in m_names:
return 'Male'
elif name in f_names:
return 'Female'
else:
return 'Unknown'
>>> data.yaml
- {Age: 22, First Name: Kenneth, Gender: Male, Last Name: Reitz}
- {Age: 20, First Name: Bessie, Gender: Female, Last Name: Monke}
import matplotlib.pyplot as plt
import librosa.display
import numpy as np
from pydub import AudioSegment
# 1秒=1000毫秒
SECOND = 1000
# 音乐文件
AUDIO_PATH = 'Fenn.mp3'
def split_music(begin, end, filepath):
# 导入音乐
song = AudioSegment.from_mp3(filepath)
# 取begin秒到end秒间的片段
song = song[begin*SECOND: end*SECOND]
# 存储为临时文件做备份
temp_path = 'backup/'+filepath
song.export(temp_path)
return temp_path
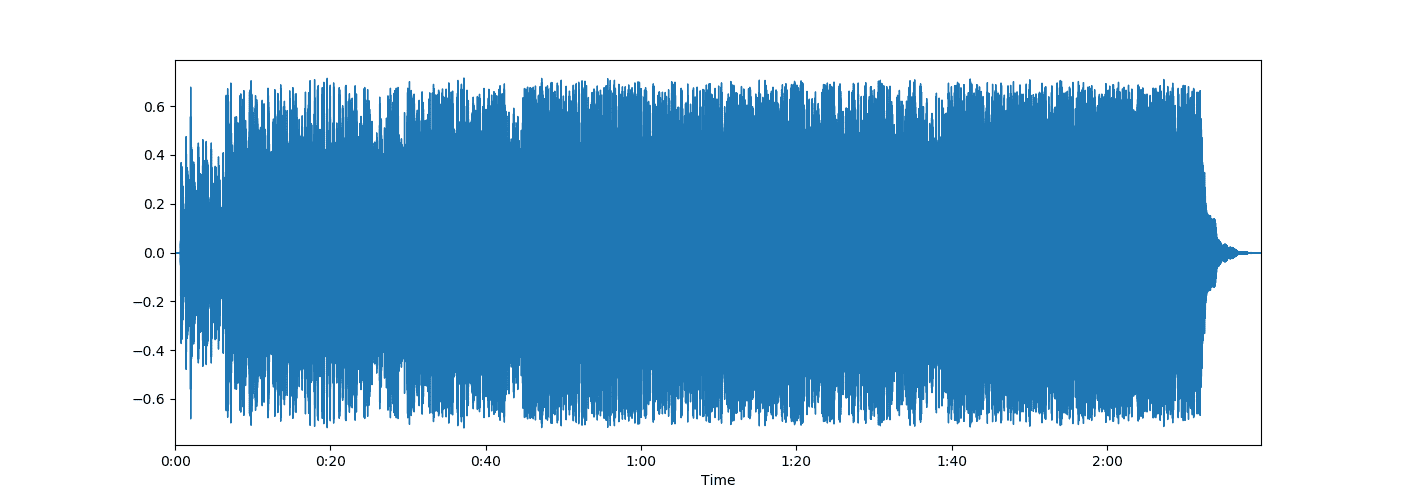
music, sr = librosa.load(split_music(0, 1, AUDIO_PATH))
# 宽高比为14:5的图
plt.figure(figsize=(14, 5))
librosa.display.waveplot(music, sr=sr)
plt.show()
这下细是细了,但是还是太复杂了,其实我们做频谱的展示,只需要正值即可:
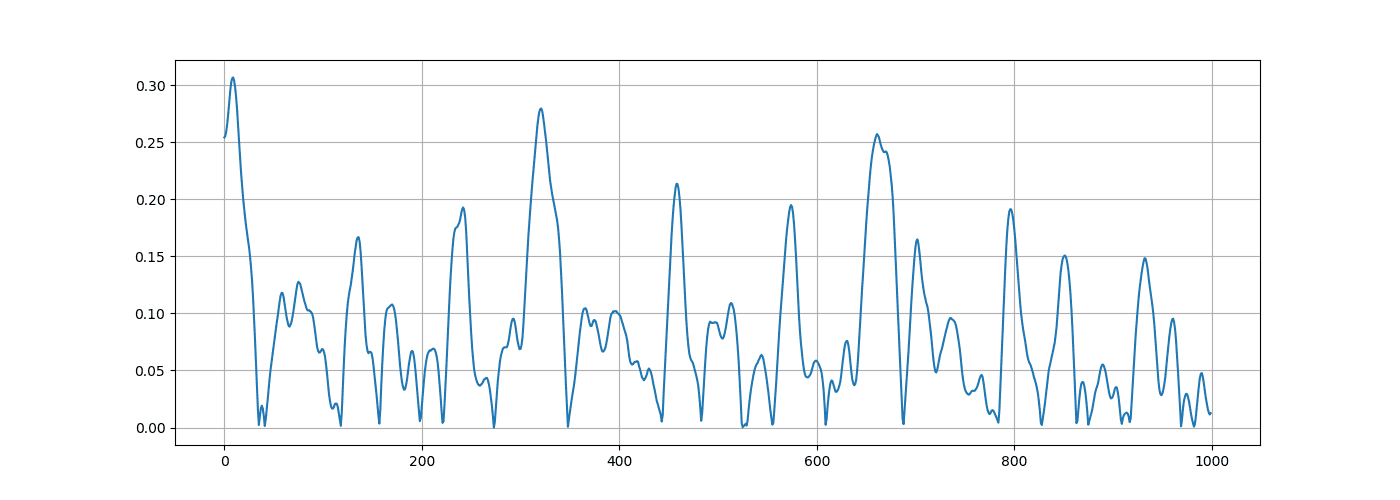
然后我们还可以进一步放大,比如说0.9秒到1秒之间的频谱:
# 放大
n0 = 9000
n1 = 10000
music = np.array([mic for mic in music if mic > 0])
plt.figure(figsize=(14, 5))
plt.plot(music[n0:n1])
plt.grid()
# 显示图
plt.show()