Python 自动整理文件是一个非常容易实现的工具。以前,我经常习惯性地把下载下来的东西放在桌面或者下载文件夹中,使用完后再也没管它,久而久之桌面便变得乱七八糟
不知道你是不是有过跟我一样糟糕的体验,不过,我们现在完全可以用Python做一个这样的工具 来根据后缀名整理文件
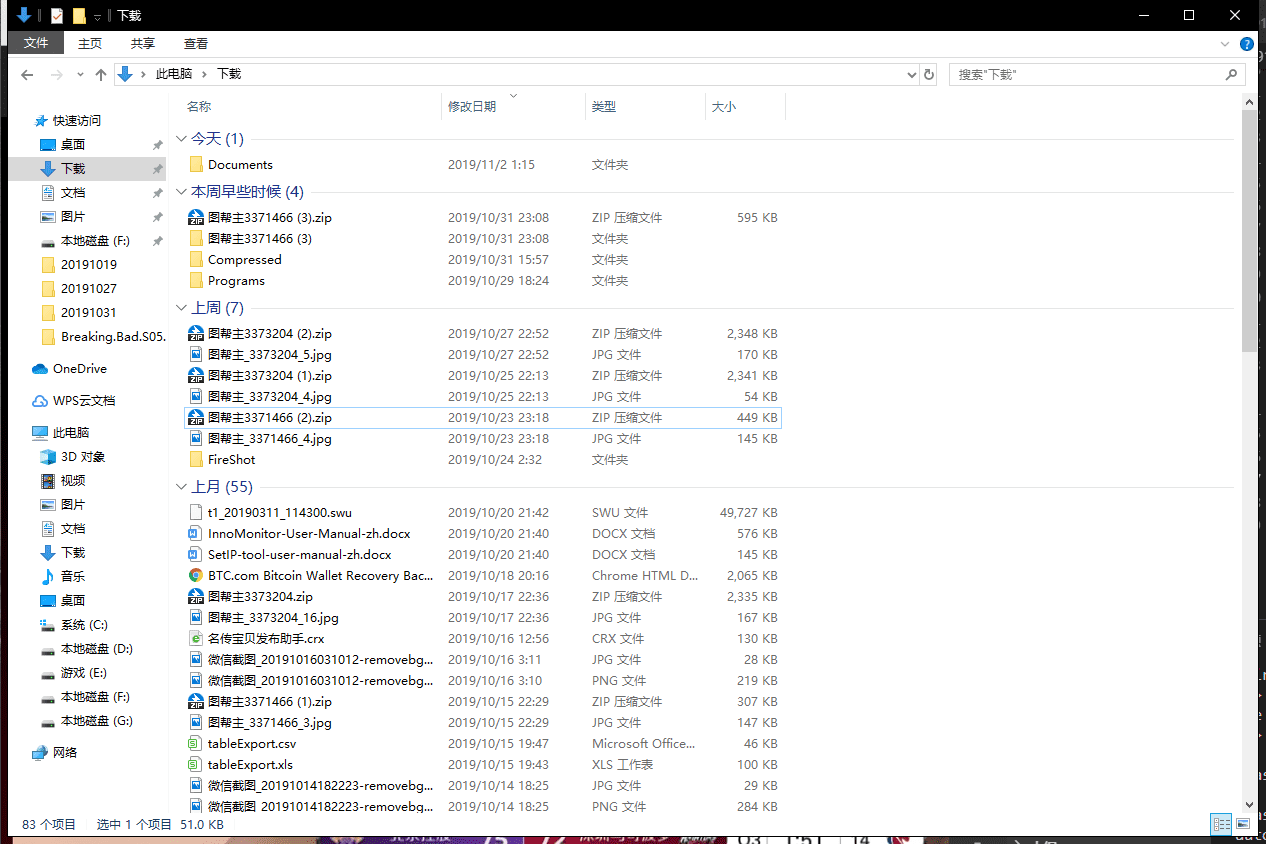
自动整理前:
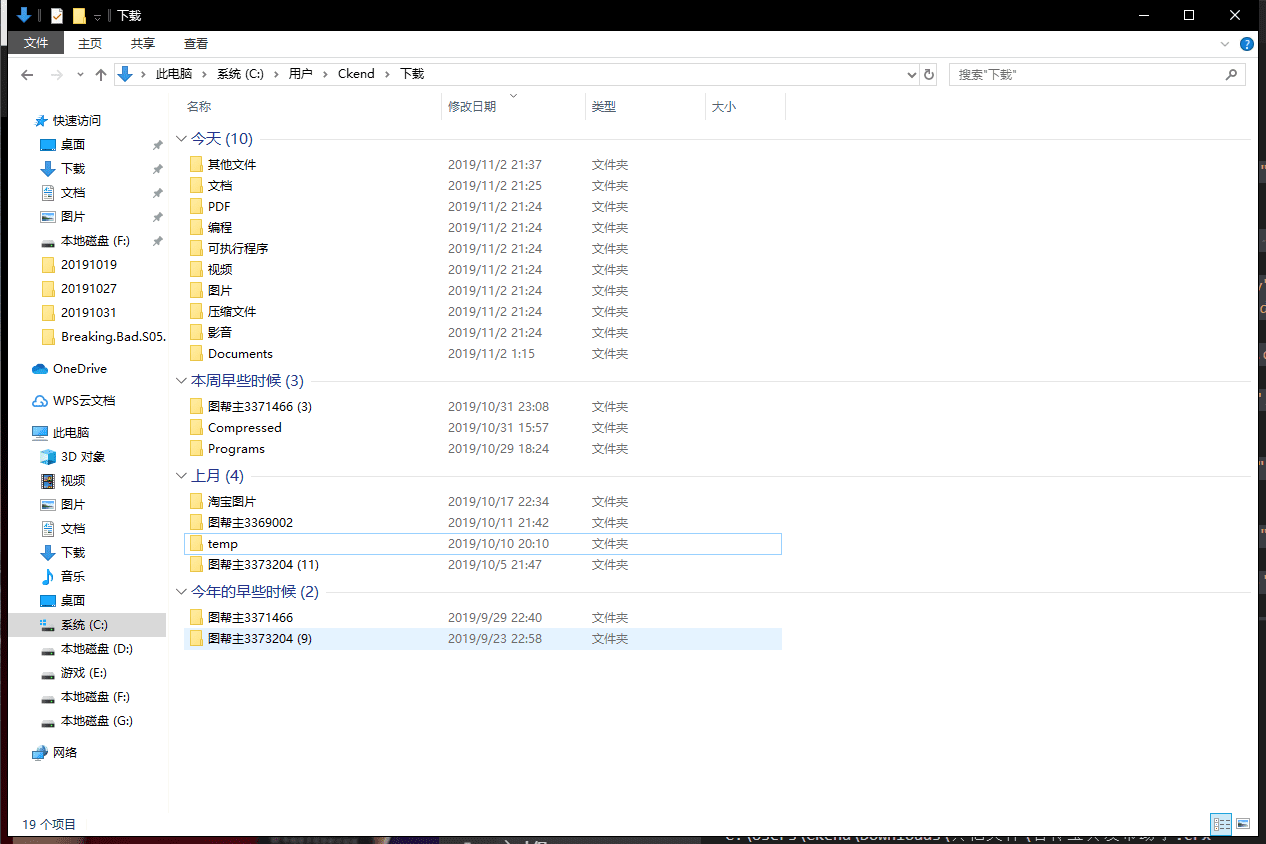
自动整理后:
效果非常好,舒服多了文件自动整理 获得源代码下载地址。
1.一键整理文件 开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析 ,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda ,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
你只需要修改源代码主程序中调用 auto_organize 函数的参数即可完成对对应文件的整理,比如我想整理 C:\Users\83493\Downloads 文件夹:
if __name__ == "__main__": auto_organize(r"C:\Users\83493\Downloads") 如上所示,修改代码第61行的文件夹地址即可。修改完成后运行该脚本:
就能瞬间完成对指定文件夹的整理,极其方便。
你只需要修改源代码主程序中调用 auto_organize函数的参数即可完成对对应文件的整理,比如我想整理 C:\Users\83493\Downloads
if __name__ == "__main__": auto_organize(r"C:\Users\83493\Downloads")
就能瞬间完成对指定文件夹的整理,极其方便:
2.整理文件原理
为了整理这些文件,我们要遍历当前指定的文件夹:如果是文件夹则跳过,如果是文件则检测后缀,分类到对应的文件夹中 。文件夹名字及其对应的文件后缀如下:
DIRECTORIES = {
"图片": [".jpeg", ".jpg", ".tiff", ".gif", ".bmp", ".png", ".bpg", "svg",
".heif", ".psd"],
"视频": [".avi", ".flv", ".wmv", ".mov", ".mp4", ".webm", ".vob", ".mng",
".qt", ".mpg", ".mpeg", ".3gp", ".mkv"],
"文档": [".oxps", ".epub", ".pages", ".docx", ".doc", ".fdf", ".ods",
".odt", ".pwi", ".xsn", ".xps", ".dotx", ".docm", ".dox",
".rvg", ".rtf", ".rtfd", ".wpd", ".xls", ".xlsx", ".ppt",
"pptx",".csv",",pdf"],
"压缩文件": [".a", ".ar", ".cpio", ".iso", ".tar", ".gz", ".rz", ".7z",
".dmg", ".rar", ".xar", ".zip"],
"影音": [".aac", ".aa", ".aac", ".dvf", ".m4a", ".m4b", ".m4p", ".mp3",
".msv", "ogg", "oga", ".raw", ".vox", ".wav", ".wma"],
"文本": [".txt", ".in", ".out"],
"编程": [".py",".html5", ".html", ".htm", ".xhtml",".c",".cpp",".java",".css"],
"可执行程序": [".exe"],
} 接下来是自动整理的部分代码,先遍历指定的文件夹,识别后缀并分类到对应的文件夹中。
for entry in os.scandir(dirval):
if entry.is_dir():
# 如果是文件夹则跳过
continue
file_path = Path(dirval + "\\" + entry.name)
file_format = file_path.suffix.lower()
# 避免后缀大小写判断问题,全转为小写
if file_format in FILE_FORMATS:
directory_path = Path(dirval + "\\" + FILE_FORMATS[file_format])
directory_path.mkdir(exist_ok=True)
file_path.rename(directory_path.joinpath(entry.name)) 还有出现不存在在我们字典里的后缀的情况,把它们分类到名为 其他文件 的文件夹中:
try:
os.mkdir(dirval + "\\" +"其他文件")
except:
pass
for dir in os.scandir(dirval):
try:
if dir.is_dir():
# 删除空文件夹
os.rmdir(dir)
else:
temp = str(Path(dir)).split('\\')
# 分割文件路径
path = '\\'.join(temp[:-1])
print(path + '\\其他文件\\' + str(temp[-1]))
os.rename(str(Path(dir)), path + '\\其他文件\\' + str(temp[-1]))
except:
pass 最后再把以上这些部分整理成函数即可。关注文章最下方的Python实用宝典公众号,后台回复 文件自动整理 获得源代码下载地址。
3.自定义整理
如果你并不想按照设定好的文件整理,希望能自定义地将某些特定后缀 的文件放到另一个文件夹,比如 .py 文件统一收纳到“Python脚本 ”文件夹中,你可以这么改 DIRECTORIES 变量:
改动前:
DIRECTORIES = {
# ......
"编程": [".py",".html5", ".html", ".htm", ".xhtml",".c",".cpp",".java",".css"],
# ......
} 改动后:
DIRECTORIES = {
# ......
"编程": [".html5", ".html", ".htm", ".xhtml",".c",".cpp",".java",".css"],
"Python脚本": [".py"],
# ......
} 你可以按照这个方法,自定义收纳那些你需要整理收纳的文件格式。
如果你只想对 DIRECTORIES 变量里那些后缀的文件进行整理,不属于这些后缀的文件则不进行整理,不需要放到“其他文件”目录下,此时要怎么做?
很简单,你只需要删除以下部分代码就可以完成这个功能:
# ......
try:
os.mkdir(dirval + "\\" +"其他文件")
except:
pass
for dir in os.scandir(dirval):
try:
if dir.is_dir():
# 删除空文件夹
os.rmdir(dir)
else:
temp = str(Path(dir)).split('\\')
# 分割文件路径
path = '\\'.join(temp[:-1])
print(path + '\\其他文件\\' + str(temp[-1]))
os.rename(str(Path(dir)), path + '\\其他文件\\' + str(temp[-1]))
except:
pass
# ...... 怎么样,是不是很方便?如果喜欢的话记得给我点个赞哦。
文章到此就结束啦,如果你喜欢今天的Python 教程 ,请持续关注Python实用宝典,如果对你有帮助,麻烦在下面点一个赞/在看哦
Python实用宝典 (pythondict.com )