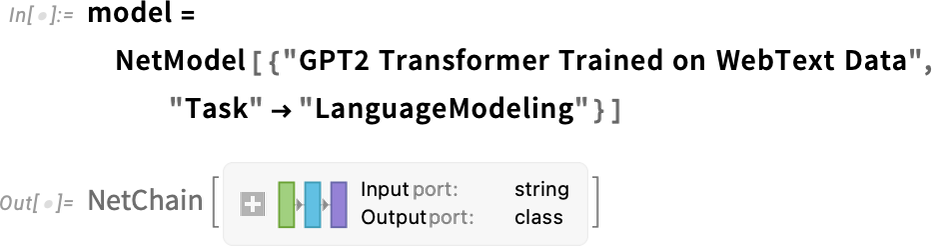
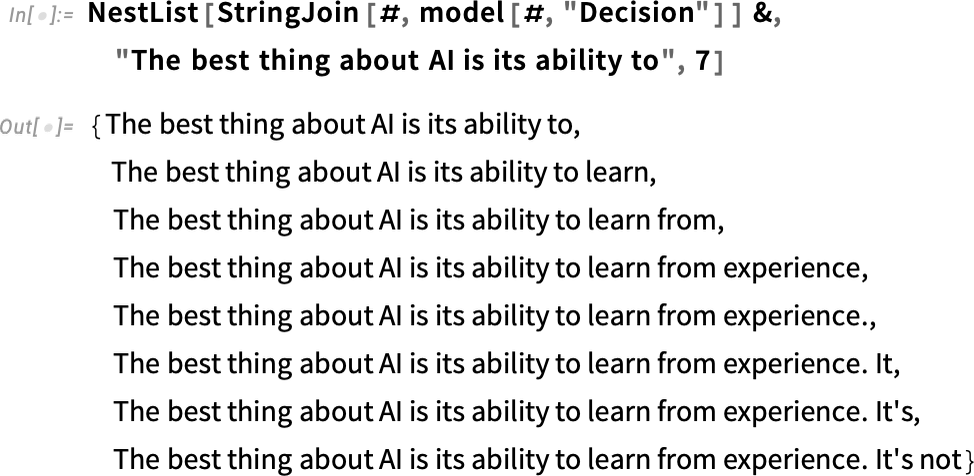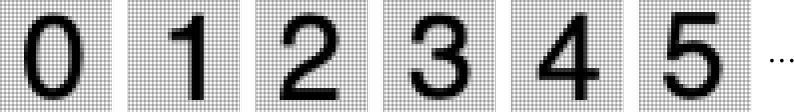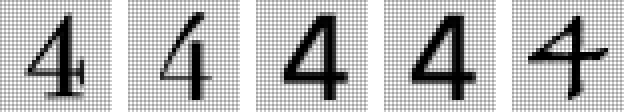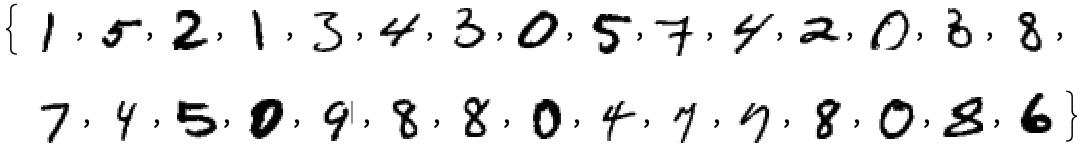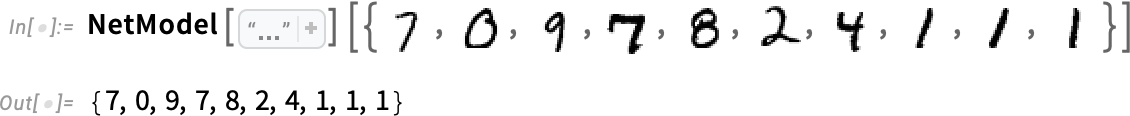from bert_serving.client import BertClient
bc = BertClient()
bc.encode(['First do it', 'then do it right', 'then do it better'])
作为 BERT 的一个特性,你可以通过将它们与 |||(前后有空格)连接来获得一对句子的编码,例如
bc.encode(['First do it ||| then do it right'])
远程使用 BERT 服务
你还可以在一台 (GPU) 机器上启动服务并从另一台 (CPU) 机器上调用它,如下所示:
# on another CPU machine
from bert_serving.client import BertClient
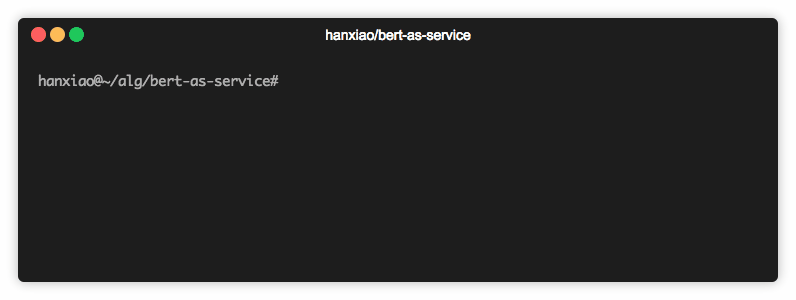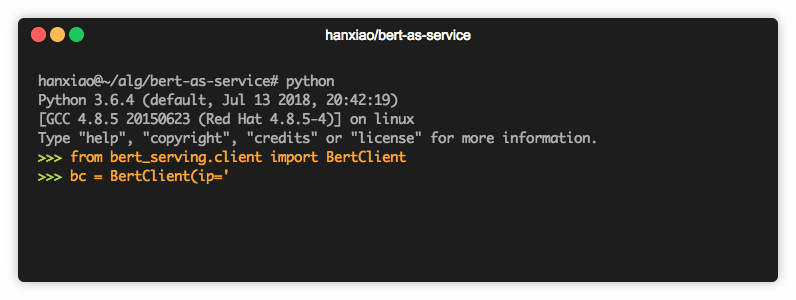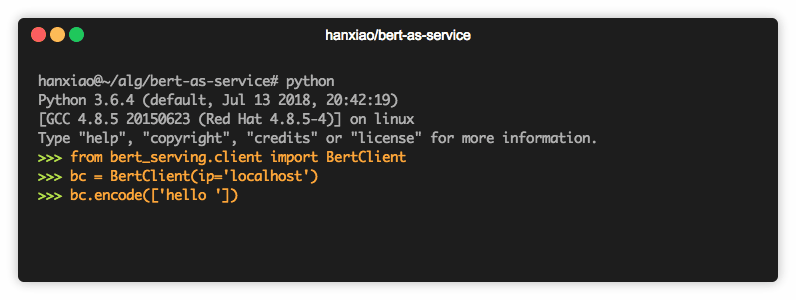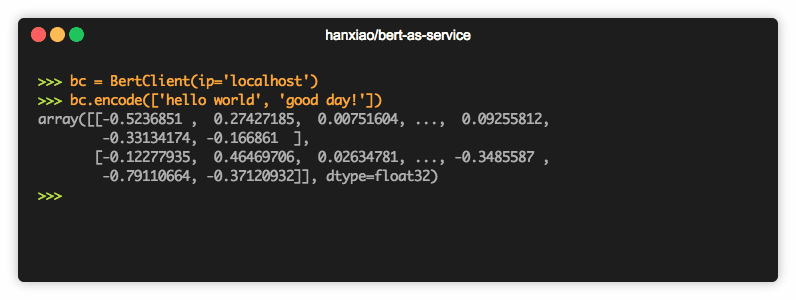
bc = BertClient(ip='xx.xx.xx.xx') # ip address of the GPU machine
bc.encode(['First do it', 'then do it right', 'then do it better'])
prefix_q = '##### **Q:** '
with open('README.md') as fp:
questions = [v.replace(prefix_q, '').strip() for v in fp if v.strip() and v.startswith(prefix_q)]
print('%d questions loaded, avg. len of %d' % (len(questions), np.mean([len(d.split()) for d in questions])))
# 33 questions loaded, avg. len of 9
while True:
query = input('your question: ')
query_vec = bc.encode([query])[0]
# compute normalized dot product as score
score = np.sum(query_vec * doc_vecs, axis=1) / np.linalg.norm(doc_vecs, axis=1)
topk_idx = np.argsort(score)[::-1][:topk]
for idx in topk_idx:
print('> %s\t%s' % (score[idx], questions[idx]))
完成!现在运行代码并输入你的查询,看看这个搜索引擎如何处理模糊匹配:
完整代码如下,一共23行代码(在后台回复关键词也能下载):
import numpy as np
from bert_serving.client import BertClient
from termcolor import colored
prefix_q = '##### **Q:** '
topk = 5
with open('README.md') as fp:
questions = [v.replace(prefix_q, '').strip() for v in fp if v.strip() and v.startswith(prefix_q)]
print('%d questions loaded, avg. len of %d' % (len(questions), np.mean([len(d.split()) for d in questions])))
with BertClient(port=4000, port_out=4001) as bc:
doc_vecs = bc.encode(questions)
while True:
query = input(colored('your question: ', 'green'))
query_vec = bc.encode([query])[0]
# compute normalized dot product as score
score = np.sum(query_vec * doc_vecs, axis=1) / np.linalg.norm(doc_vecs, axis=1)
topk_idx = np.argsort(score)[::-1][:topk]
print('top %d questions similar to "%s"' % (topk, colored(query, 'green')))
for idx in topk_idx:
print('> %s\t%s' % (colored('%.1f' % score[idx], 'cyan'), colored(questions[idx], 'yellow')))
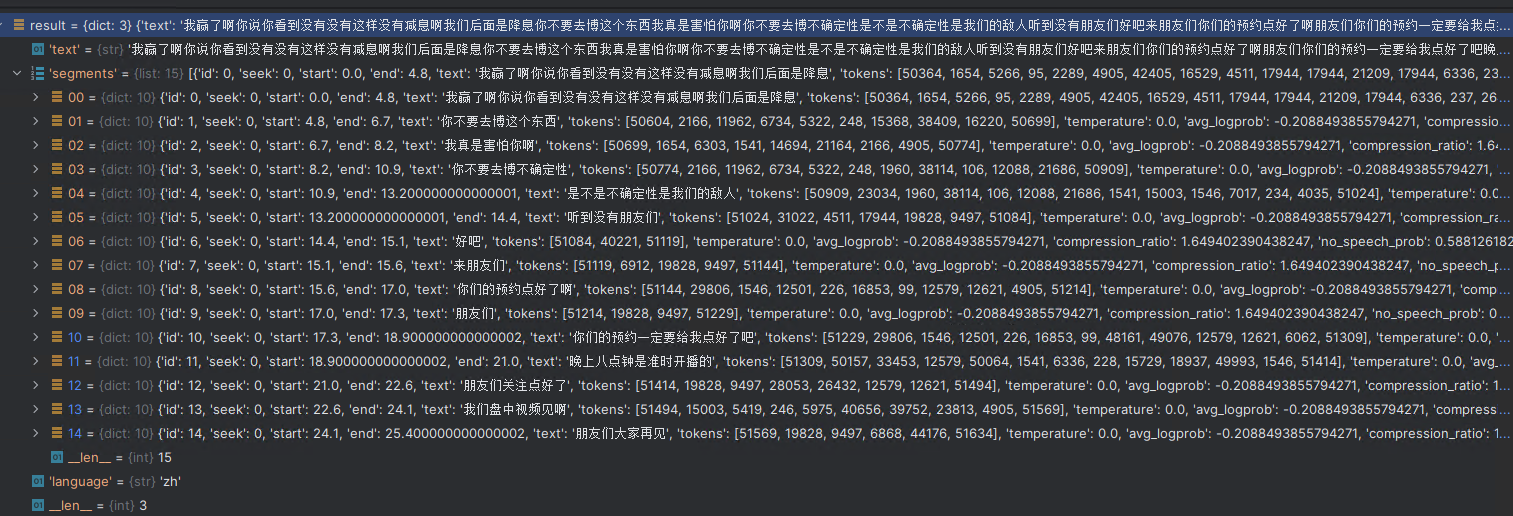
", ".join([i["text"] for i in result["segments"] if i is not None])
# Out[12]: '我赢了啊你说你看到没有没有这样没有减息啊我们后面是降息, 你不要去博这个东西, 我真是害怕你啊, 你不要去博不确定性, 是不是不确定性是我们的敌人, 听到没有朋友们, 好吧, 来朋友们, 你们的预约点好了啊, 朋友们, 你们的预约一定要给我点好了吧, 晚上八点钟是准时开播的, 朋友们关注点好了, 我们盘中视频见啊, 朋友们大家再见'
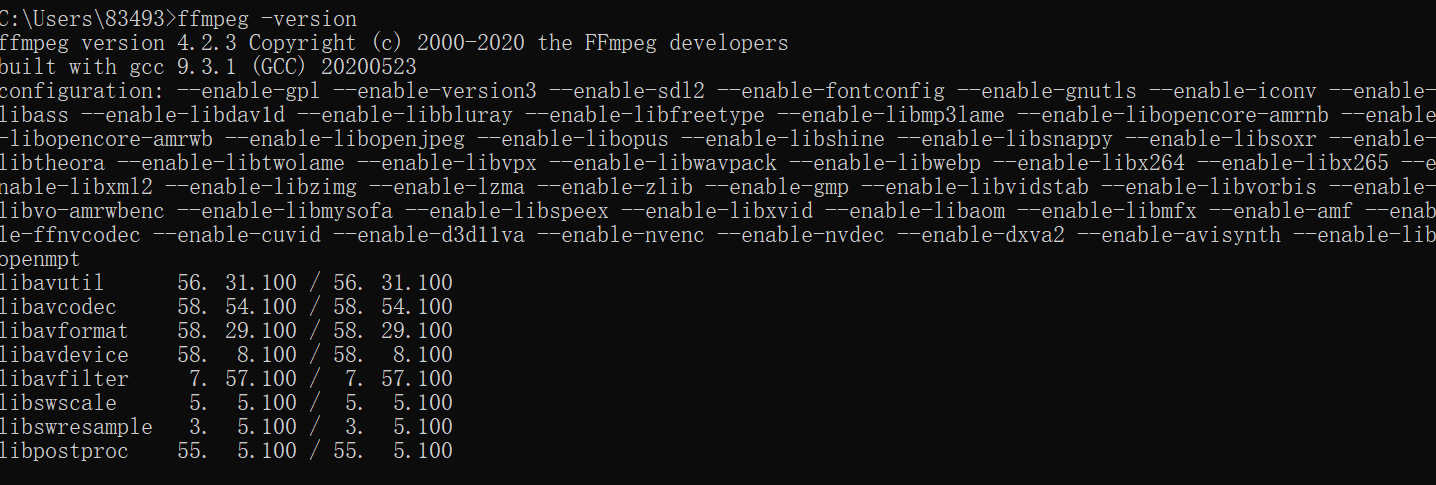
1. 进入 http://ffmpeg.org/download.html#build-windows,点击 windows 对应的图标,进入下载界面点击 download 下载按钮, 2. 解压下载好的zip文件到指定目录 3. 将解压后的文件目录中 bin 目录(包含 ffmpeg.exe )添加进 path 环境变量中 4. DOS 命令行输入 ffmpeg -version, 出现以下界面说明安装完成:
2.使用Whisper进行语音转文字
简单的使用例子:
import whisper
whisper_model = whisper.load_model("large")
result = whisper_model.transcribe(r"C:\Users\win10\Downloads\test.wav")
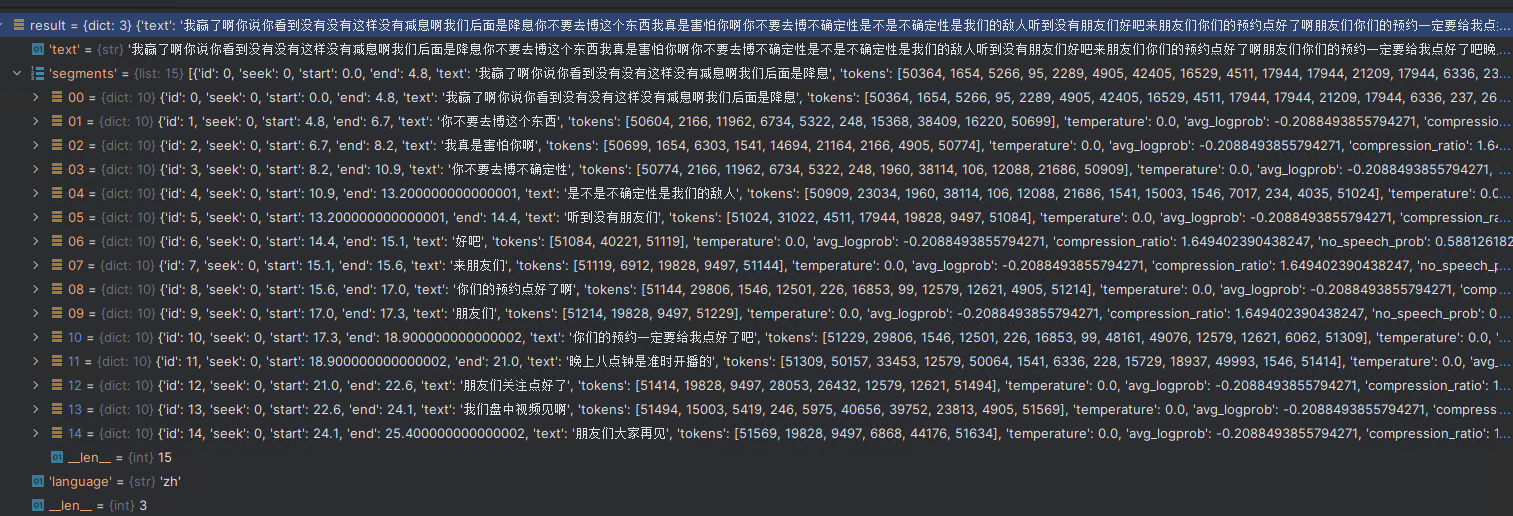
print(", ".join([i["text"] for i in result["segments"] if i is not None]))
import whisper
whisper_model = whisper.load_model("large")
result = whisper_model.transcribe(r"C:\Users\win10\Downloads\test.wav")
print(", ".join([i["text"] for i in result["segments"] if i is not None]))
# 我赢了啊你说你看到没有没有这样没有减息啊我们后面是降息, 你不要去博这个东西, 我真是害怕你啊, 你不要去博不确定性, 是不是不确定性是我们的敌人, 听到没有朋友们, 好吧, 来朋友们, 你们的预约点好了啊, 朋友们, 你们的预约一定要给我点好了吧, 晚上八点钟是准时开播的, 朋友们关注点好了, 我们盘中视频见啊, 朋友们大家再见
那么我们如何遵循同样的方法来找到单词的Embedding呢?关键是从一个关于单词的任务开始,我们可以很容易地进行训练。标准的这样的任务是“单词预测”。想象一下,我们得到了“the ___ cat”。基于大量的文本语料库(比如网页的文本内容),可能有哪些单词“填空”呢?或者,给定“___ black ___”,不同“侧翼单词”的概率是什么?
我们如何为单词创建嵌入呢?关键是从一个关于单词的任务开始,这个任务可以很容易地进行训练。标准的这种任务是“单词预测”。想象一下,我们被给出“the ___ cat”。根据大量的文本语料库(比如网络内容),哪些单词“填空”最有可能呢?或者换句话说,给定“___ black ___”,不同“flanking words”的概率是多少?
语法提供了一种对语言的限制,但显然还有其他的限制。像“nquisitive electrons eat blue theories for fish”(探究性电子吃蓝色理论以换取鱼) 这样的句子在语法上是正确的,但并不是我们通常会说的,如果ChatGPT生成了这样的句子,也不会被认为是成功的——因为,嗯,就是用其中的单词的正常含义而言,它基本上是没有意义的。
text_prompts:
- A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.
- yellow color scheme
init_image:
width_height: [ 1280, 768 ]
skip_steps: 0
steps: 250
init_scale: 1000
clip_guidance_scale: 5000
tv_scale: 0
range_scale: 150
sat_scale: 0
cutn_batches: 4
diffusion_model: 512x512_diffusion_uncond_finetune_008100
use_secondary_model: True
diffusion_sampling_mode: ddim
perlin_init: False
perlin_mode: mixed
seed:
eta: 0.8
clamp_grad: True
clamp_max: 0.05
randomize_class: True
clip_denoised: False
rand_mag: 0.05
cut_overview: "[12]*400+[4]*600"
cut_innercut: "[4]*400+[12]*600"
cut_icgray_p: "[0.2]*400+[0]*600"
cut_ic_pow: 1.
save_rate: 20
gif_fps: 20
gif_size_ratio: 0.5
n_batches: 4
batch_size: 1
batch_name:
clip_models:
- ViT-B-32::openai
- ViT-B-16::openai
- RN50::openai
clip_models_schedules:
use_vertical_symmetry: False
use_horizontal_symmetry: False
transformation_percent: [0.09]
on_misspelled_token: ignore
diffusion_model_config:
cut_schedules_group:
name_docarray:
skip_event:
stop_event:
text_clip_on_cpu: False
truncate_overlength_prompt: False
image_output: True
visualize_cuts: False
display_rate: 1
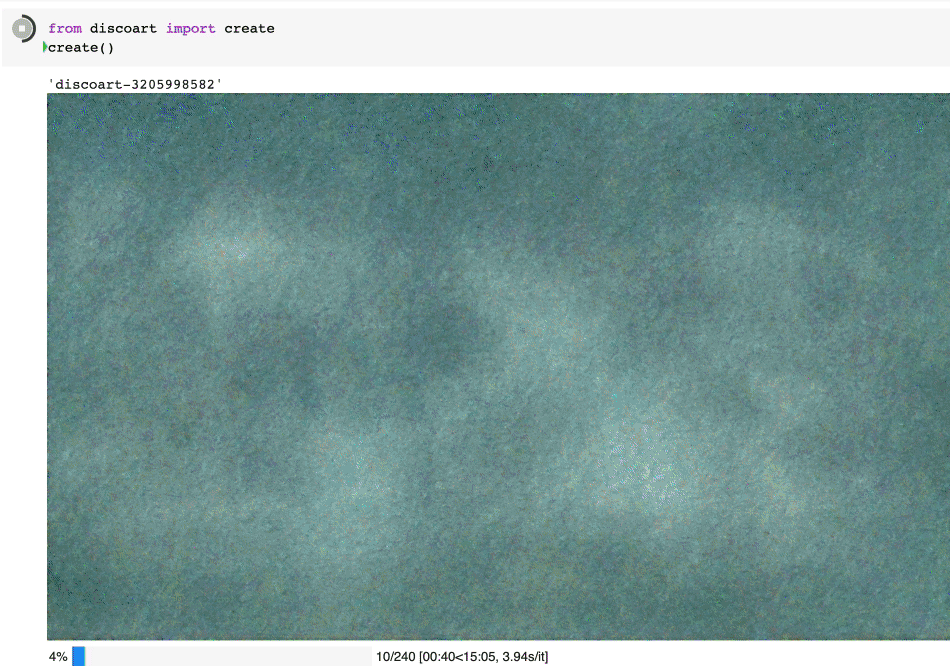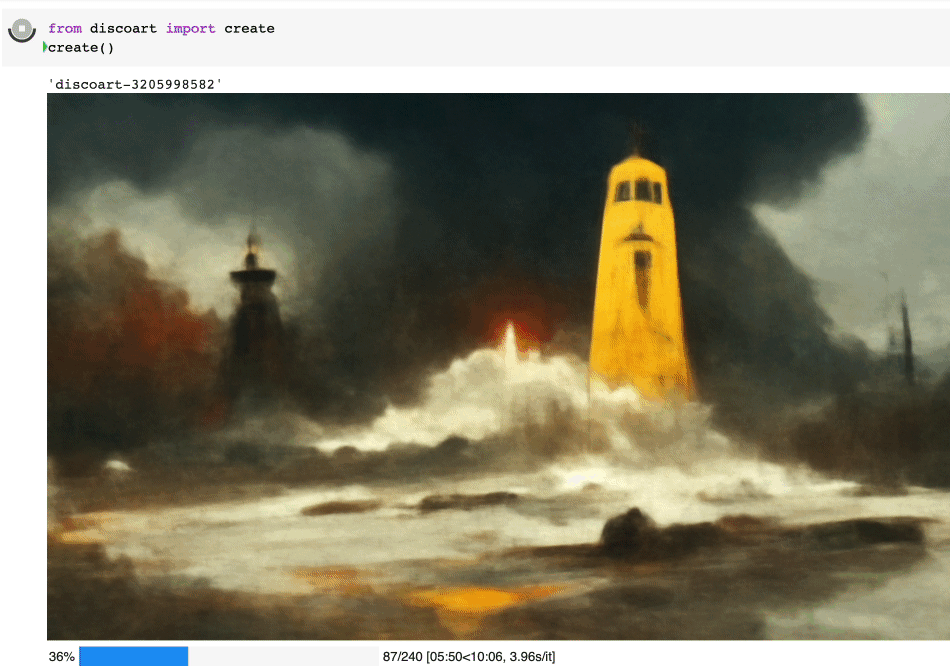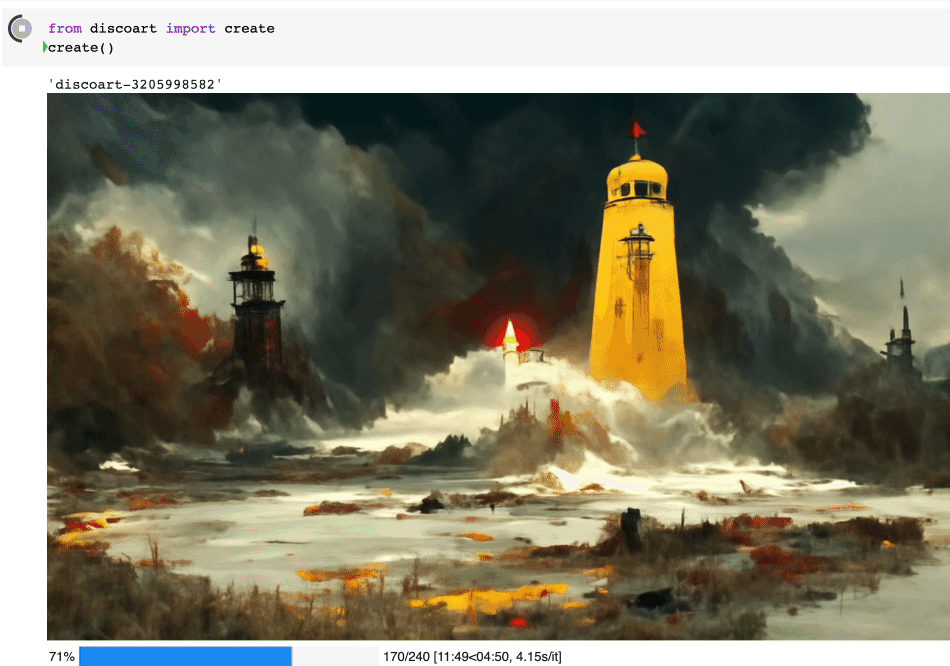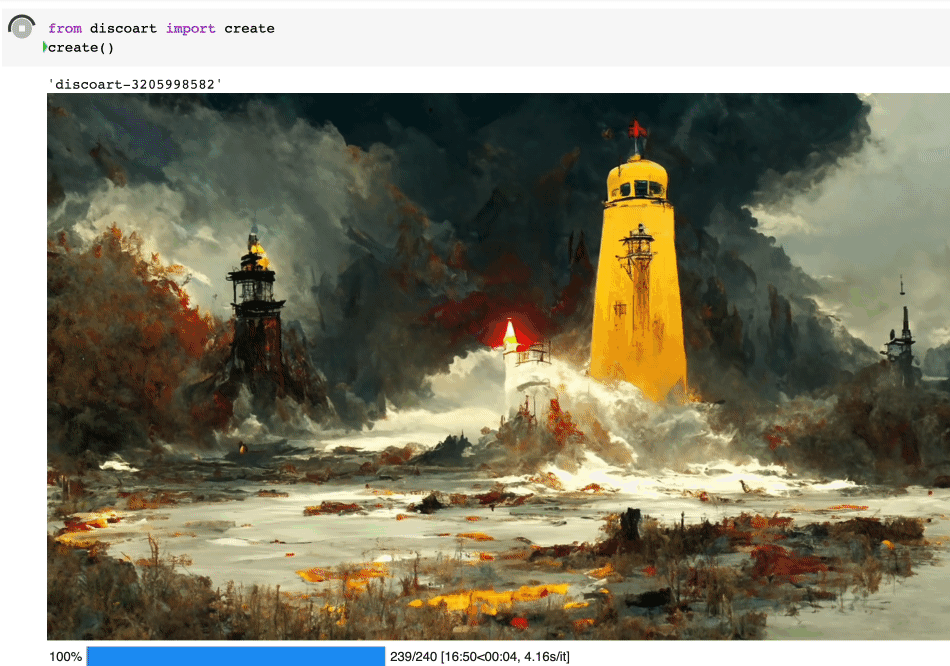
创建出来的就是这个图:
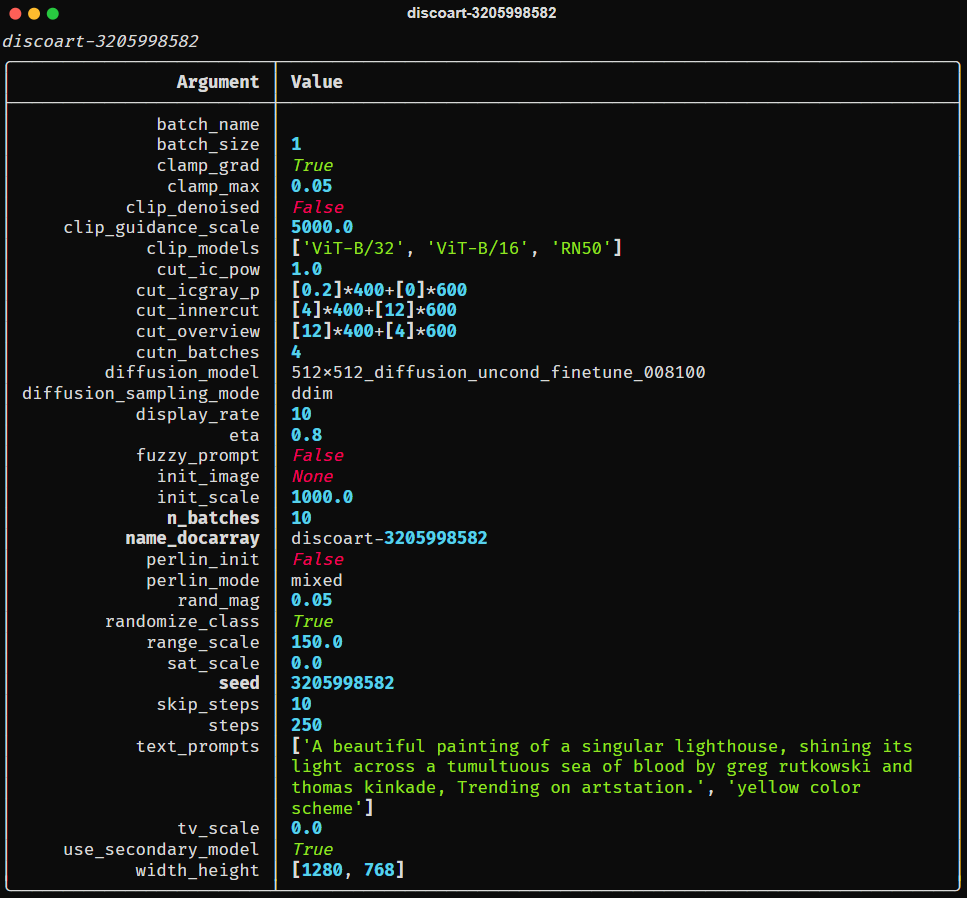
Create 支持的所有参数如下:
text_prompts:
- A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.
- yellow color scheme
init_image:
width_height: [ 1280, 768 ]
skip_steps: 0
steps: 250
init_scale: 1000
clip_guidance_scale: 5000
tv_scale: 0
range_scale: 150
sat_scale: 0
cutn_batches: 4
diffusion_model: 512x512_diffusion_uncond_finetune_008100
use_secondary_model: True
diffusion_sampling_mode: ddim
perlin_init: False
perlin_mode: mixed
seed:
eta: 0.8
clamp_grad: True
clamp_max: 0.05
randomize_class: True
clip_denoised: False
rand_mag: 0.05
cut_overview: "[12]*400+[4]*600"
cut_innercut: "[4]*400+[12]*600"
cut_icgray_p: "[0.2]*400+[0]*600"
cut_ic_pow: 1.
save_rate: 20
gif_fps: 20
gif_size_ratio: 0.5
n_batches: 4
batch_size: 1
batch_name:
clip_models:
- ViT-B-32::openai
- ViT-B-16::openai
- RN50::openai
clip_models_schedules:
use_vertical_symmetry: False
use_horizontal_symmetry: False
transformation_percent: [0.09]
on_misspelled_token: ignore
diffusion_model_config:
cut_schedules_group:
name_docarray:
skip_event:
stop_event:
text_clip_on_cpu: False
truncate_overlength_prompt: False
image_output: True
visualize_cuts: False
display_rate: 1
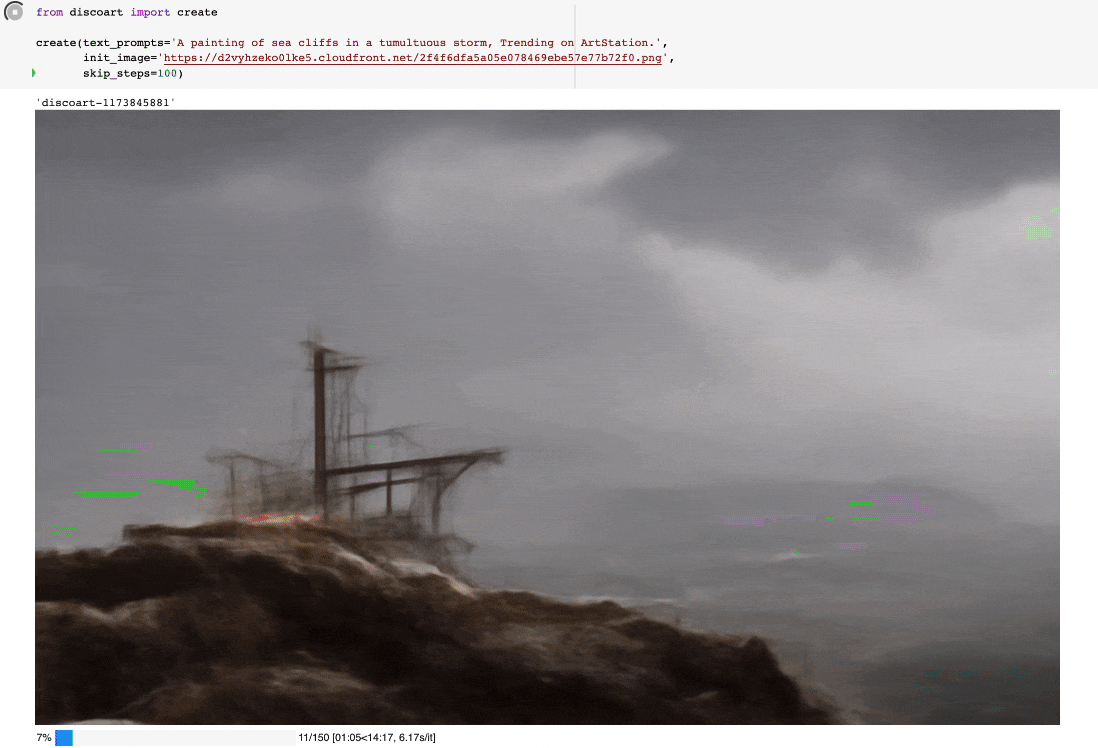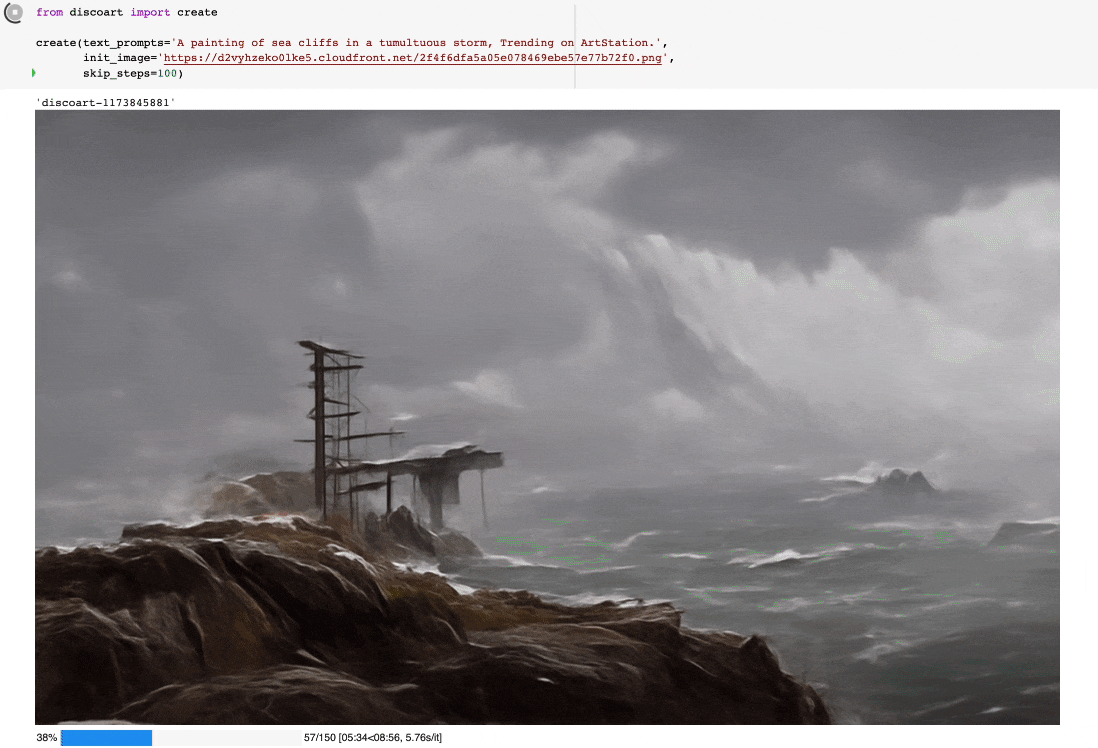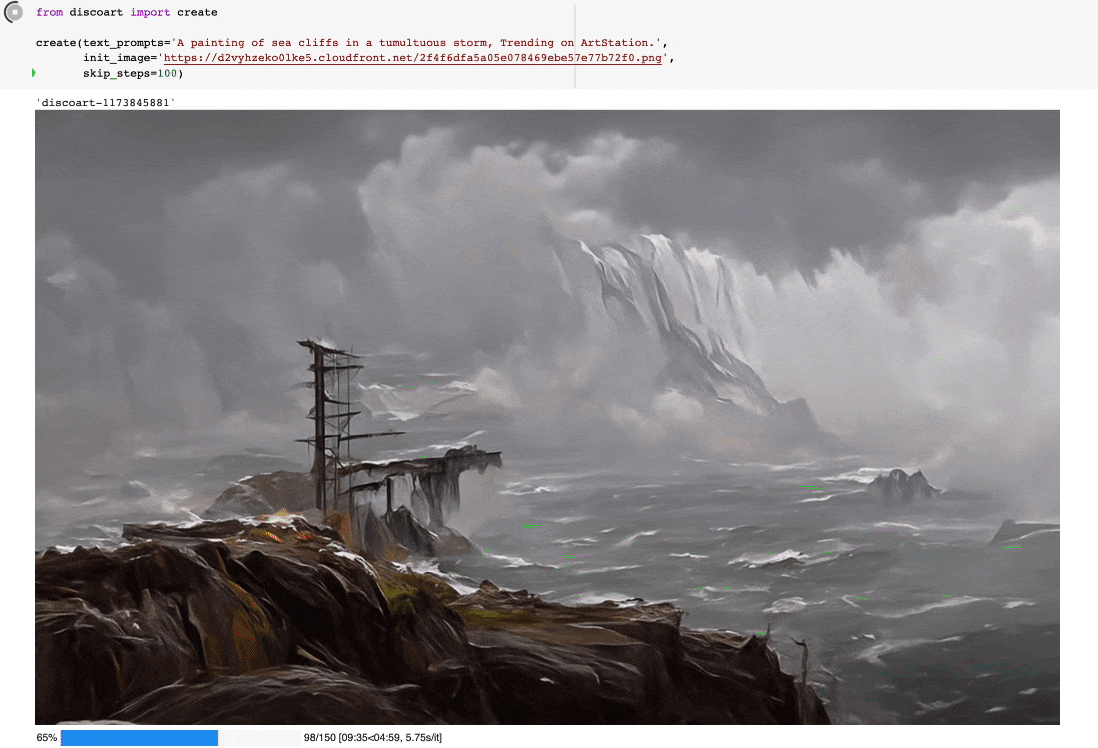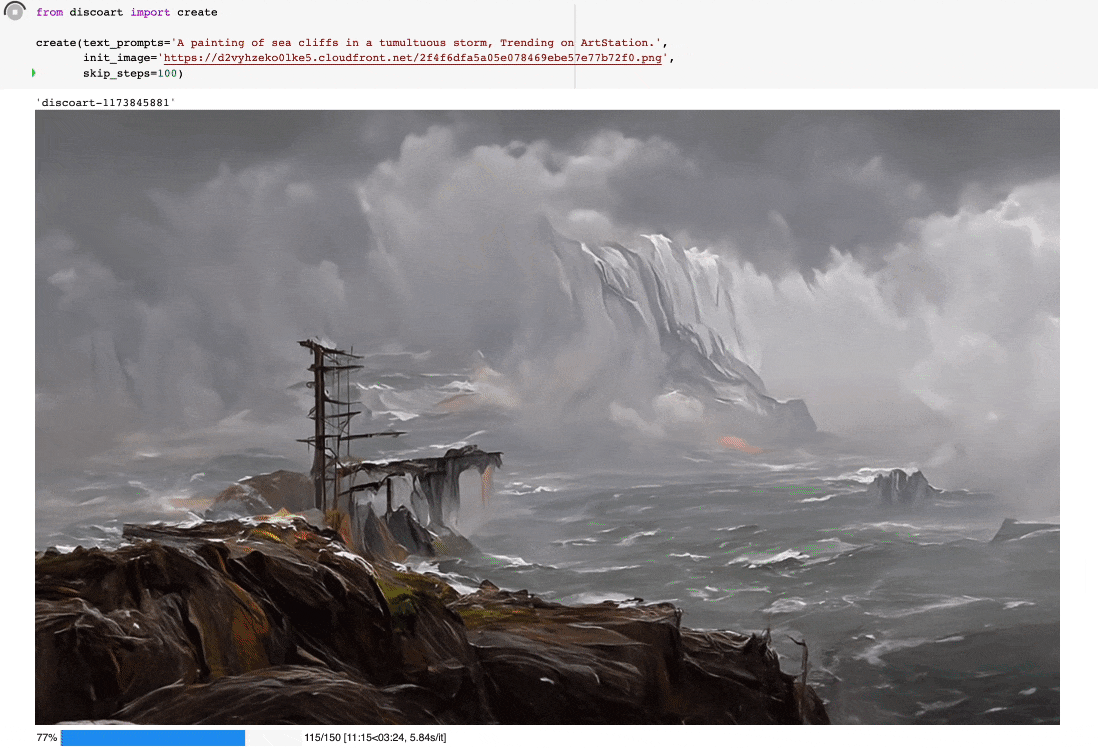
你可以这么使用:
from discoart import create
da = create(
text_prompts='A painting of sea cliffs in a tumultuous storm, Trending on ArtStation.',
init_image='https://d2vyhzeko0lke5.cloudfront.net/2f4f6dfa5a05e078469ebe57e77b72f0.png',
skip_steps=100,
)
from discoart import show_config
show_config(da) # show the config of the first run
show_config(da[3]) # show the config of the fourth run
show_config(
'discoart-06030a0198843332edc554ffebfbf288'
) # show the config of the run with a known DocArray ID
要保存 Document/DocumentArray 的配置:
from discoart import save_config
save_config(da, 'my.yml') # save the config of the first run
save_config(da[3], 'my.yml') # save the config of the fourth run
从配置中导入:
from discoart import create, load_config
config = load_config('my.yml')
create(**config)
此外,你还能直接把配置导出为图像的形式
from discoart.config import save_config_svg
save_config_svg(da)
# 公众号 Python实用宝典
import autograd.numpy as np
from autograd import grad
def oneline(x):
y = x/2
return y
grad_oneline = grad(oneline)
print(grad_oneline(3.0))
运行代码,传入任意X值,你就能得到在该X值下的斜率:
(base) G:\push\20220724>python 1.py
0.5
由于这是一条直线,因此无论你传什么值,都只会得到0.5的结果。
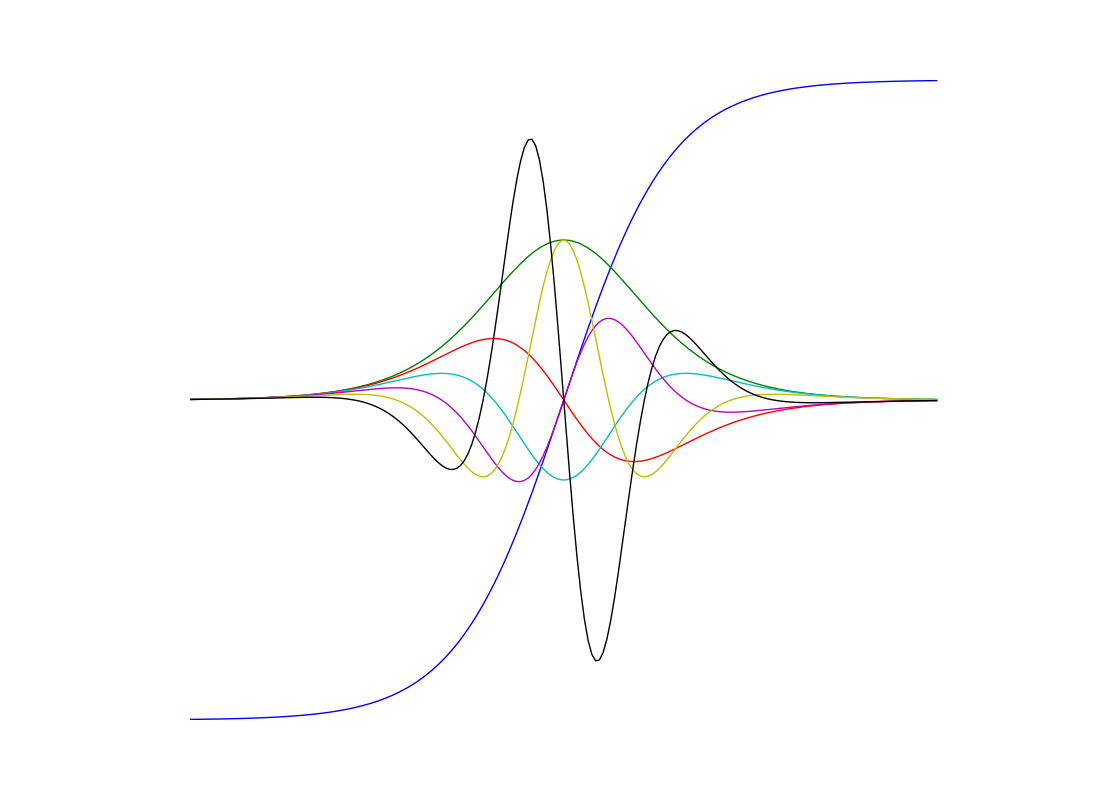
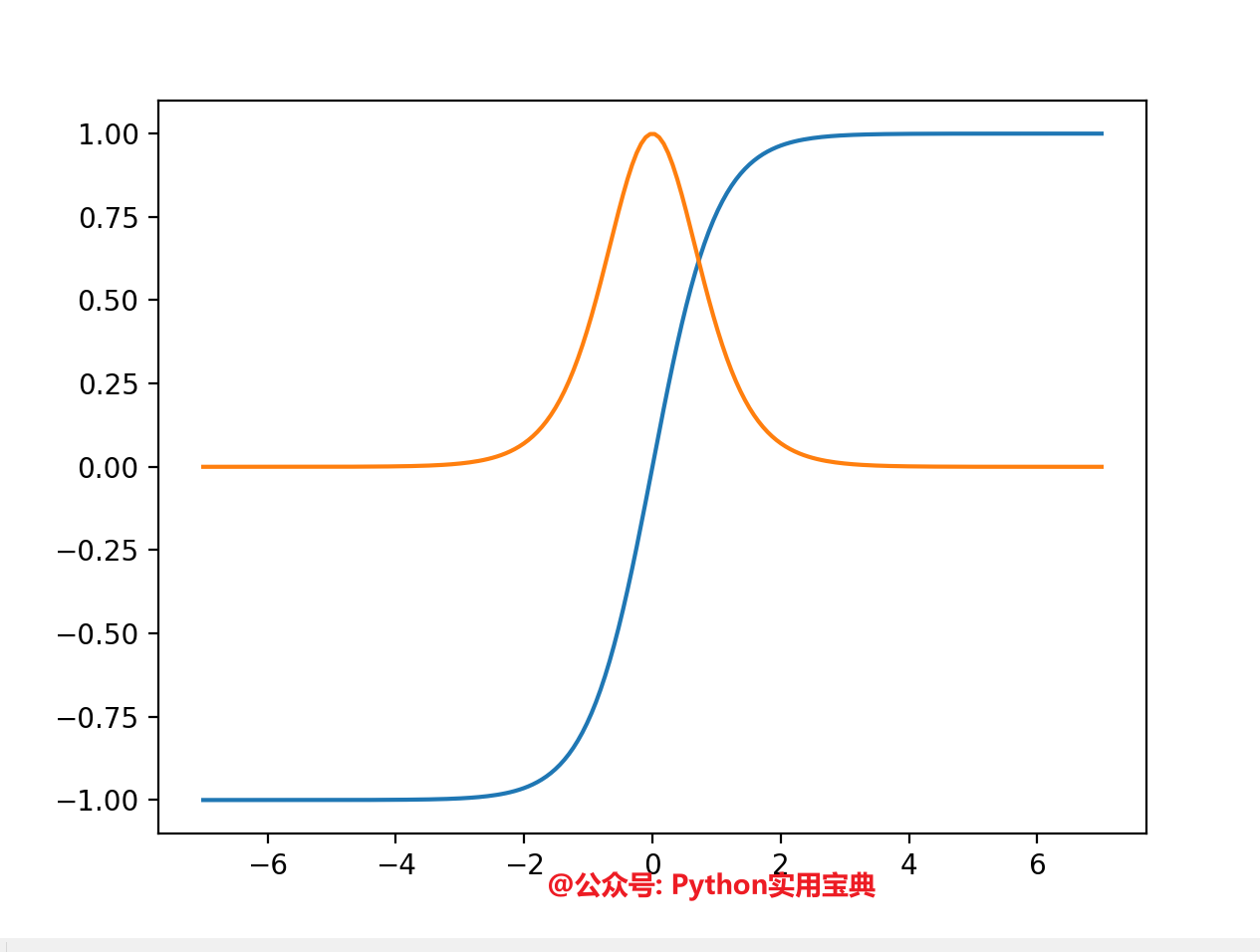
那么让我们再试试一个tanh函数:
# 公众号 Python实用宝典
import autograd.numpy as np
from autograd import grad
def tanh(x):
y = np.exp(-2.0 * x)
return (1.0 - y) / (1.0 + y)
grad_tanh = grad(tanh)
print(grad_tanh(1.0))
def training_loss(weights):
# Training loss is the negative log-likelihood of the training labels.
preds = logistic_predictions(weights, inputs)
label_probabilities = preds * targets + (1 - preds) * (1 - targets)
return -np.sum(np.log(label_probabilities))
# Define a function that returns gradients of training loss using Autograd.
training_gradient_fun = grad(training_loss)
# Optimize weights using gradient descent.
weights = np.array([0.0, 0.0, 0.0])
print("Initial loss:", training_loss(weights))
for i in range(100):
weights -= training_gradient_fun(weights) * 0.01
print("Trained loss:", training_loss(weights))
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader):
inputs, labels = data[0].to(model_engine.local_rank), data[1].to(
model_engine.local_rank)
outputs = model_engine(inputs)
loss = criterion(outputs, labels)
model_engine.backward(loss)
model_engine.step()
# print statistics
running_loss += loss.item()
if i % args.log_interval == (args.log_interval - 1):
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / args.log_interval))
running_loss = 0.0
2.5 测试逻辑
模型测试和模型训练的逻辑类似:
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images.to(model_engine.local_rank))
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels.to(
model_engine.local_rank)).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' %
(100 * correct / total))