
文献搜索对于广大学子来说真的是个麻烦事,如果你的学校购买的论文下载权限不够多,或者不在校园内,那就很头痛了。幸好,我们有Python制作的这个论文搜索工具,简化了我们学习的复杂性。
2020-05-28 补充:已用最新的scihub提取网,目前项目可用,感谢@lisenjor的分享。另外分享一个可用下载地址:https://sci-hub.shop/
2020-06-25 补充:增加关键词搜索批量下载论文功能。
2021-01-07 补充:增加异步下载方式,加快下载速度;加强下载稳定性,不再出现文件损坏的情况。
2021-04-08 补充:由于sciencedirect增加了机器人检验,现在搜索下载功能需要先在HEADERS中填入Cookie才可爬取。
2021-04-25 补充:搜索下载增加百度学术、publons渠道。
2021-08-10 补充:修复scihub页面结构变化导致无法下载的问题,增加DOI下载函数。
1.什么是Scihub?
首先给大家介绍一下sci-hub这个线上数据库,这个数据库提供了 81,600,000 篇科学学术论文和文章下载。起初由一名叫 亚历珊卓·艾尔巴金 的研究生建立,她过去在哈佛大学从事研究时发现支付所需要的数百篇论文的费用实在是太高了,因此就萌生了创建这个网站,让更多人获得知识的想法

后来,这个网站越来越出名,逐渐地在更多地国家如印度、印度尼西亚、中国、俄罗斯等国家盛行,并成功地和一些组织合作,共同维护和运营这个网站。到了2017年的时候,网站上已有81600000篇学术论文,占到了所有学术论文的69%,基本满足大部分论文的需求,而剩下的31%是研究者不想获取的论文。
2.为什么我们需要用Python工具下载
在起初,这个网站是所有人都能够访问的,但是随着其知名度的提升,越来越多的出版社盯上了他们,在2015年时被美国法院封禁后其在美国的服务器便无法被继续访问,因此从那个时候开始,他们就跟出版社们打起了游击战。
游击战的缺点就是导致scihub的地址需要经常更换,所以我们没办法准确地一直使用某一个地址访问这个数据库。当然也有一些别的方法可让我们长时间访问这个网站,比如说修改DNS,修改hosts文件,不过这些方法不仅麻烦,而且也不是长久之计,还是存在失效的可能的。
3.新姿势:用Python写好的API工具超方便下载论文
这是一个来自github的开源非官方API工具,下载地址为:
https://github.com/zaytoun/scihub.py
但由于作者长久不更新,原始的下载工具已经无法使用,Python实用宝典修改了作者的源代码,适配了中文环境的下载器,并添加了异步批量下载等方法:
https://github.com/Ckend/scihub-cn
欢迎给我一个Star,鼓励我继续维护这个仓库。如果你访问不了GitHub,请在 Python实用宝典 公众号后台回复 scihub,下载最新可用代码。
解压后使用CMD/Terminal进入这个文件夹,输入以下命令(默认你已经安装好了Python)安装依赖:
pip install -r requirements.txt
然后我们就可以准备开始使用啦!
这个工具使用起来非常简单,你可以先在 Google 学术(搜索到论文的网址即可)或ieee上找到你需要的论文,复制论文网址如:
http://img3.imgtn.bdimg.com/it/u=664814095,2334584570&fm=11&gp=0.jpg

然后在scihub-cn文件夹里新建一个文件叫download.py, 输入以下代码:
from scihub import SciHub
sh = SciHub()
# 第一个参数输入论文的网站地址
# path: 文件保存路径
result = sh.download('https://ieeexplore.ieee.org/document/26502', path='paper.pdf')进入该文件夹后在cmd/terminal中运行:
python download.py
你就会发现文件成功下载到你的当前目录啦,名字为paper.pdf,如果不行,多试几次就可以啦,还是不行的话,可以在下方留言区询问哦。
上述是第一种下载方式,第二种方式你可以通过在知网或者百度学术上搜索论文拿到DOI号进行下载,比如:
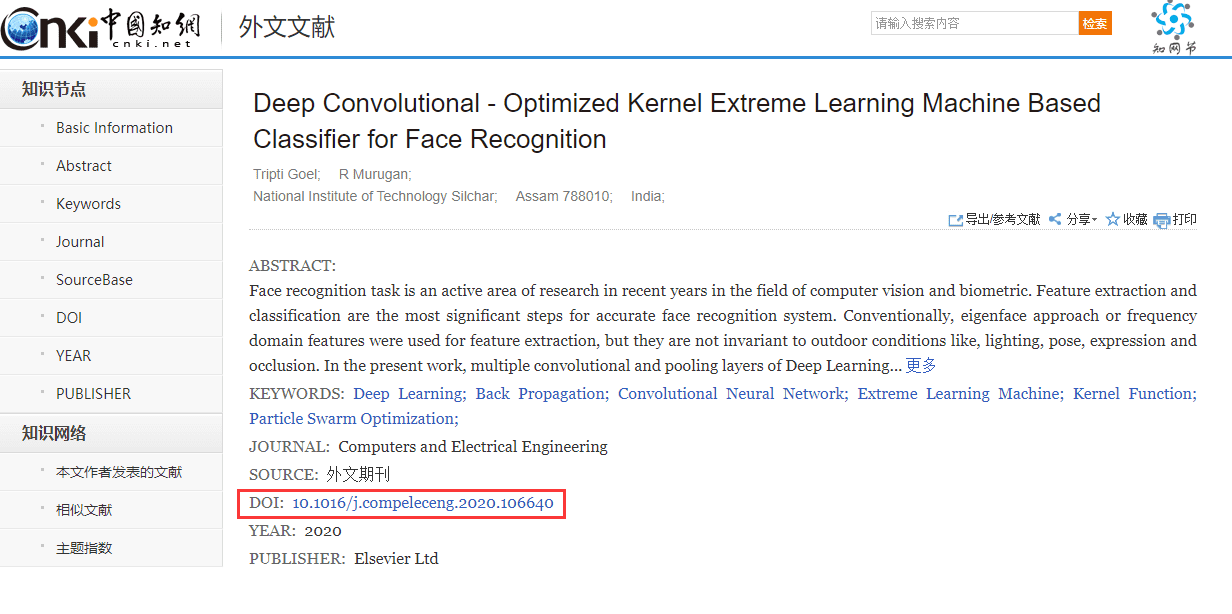
from scihub import SciHub
sh = SciHub()
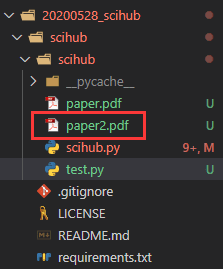
result = sh.download('10.1016/j.compeleceng.2020.106640', path='paper2.pdf')下载完成后就会在文件夹中出现该文献:
除了这种最简单的方式,我们还提供了 论文关键词搜索批量下载 及 论文关键词批量异步下载 两种高级的下载方法。
我们在下文将会详细地讲解这两种方法的使用,大家可以看项目内的 test.py 文件,你可以了解到论文搜索批量下载的方法。
进一步的高级方法在download.py 中可以找到,它可以实现论文搜索批量异步下载,大大加快下载速度。具体实现请看后文。
4.论文关键词批量下载
支持使用搜索的形式批量下载论文,比如说搜索关键词 量化投资(quant):
from scihub import SciHub
sh = SciHub()
# 搜索词
keywords = "quant"
# 搜索该关键词相关的论文,limit为篇数
result = sh.search(keywords, limit=10)
print(result)
for index, paper in enumerate(result.get("papers", [])):
# 批量下载这些论文
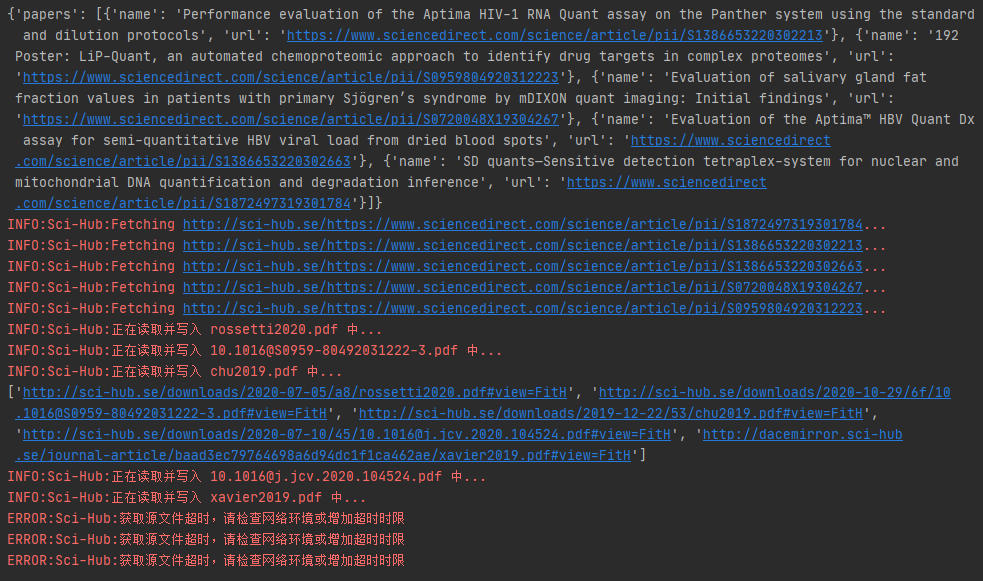
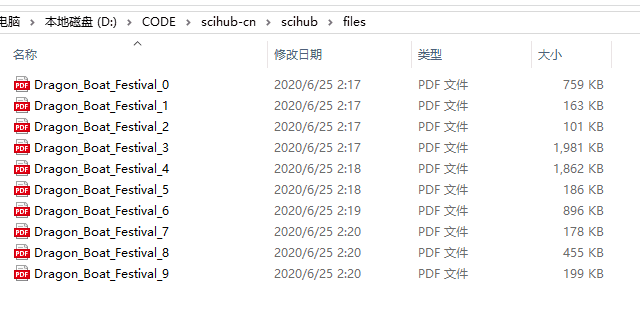
sh.download(paper["doi"], path=f"files/{keywords.replace(' ', '_')}_{index}.pdf")运行结果,下载成功:
2021-04-25 更新:
由于读者们觉得Sciencedirect的搜索实在太难用了,加上Sciencedirect现在必须要使用Cookie才能正常下载,因此我新增了百度学术和publons这2个检索渠道。
由于 Web of Science 有权限限制,很遗憾我们无法直接使用它来检索,不过百度学术作为一个替代方案也是非常不错的。
现在默认的 search 函数调用了百度学术的接口进行搜索,大家不需要配置任何东西,只需要拉一下最新的代码,使用上述例子中的代码就可以正常搜索下载论文。
其他两个渠道的使用方式如下:
sciencedirect渠道:
由于 sciencedirect 加强了他们的爬虫防护能力,增加了机器人校验机制,所以现在必须在HEADER中填入Cookie才能进行爬取。
操作如下:
1.获取Cookie
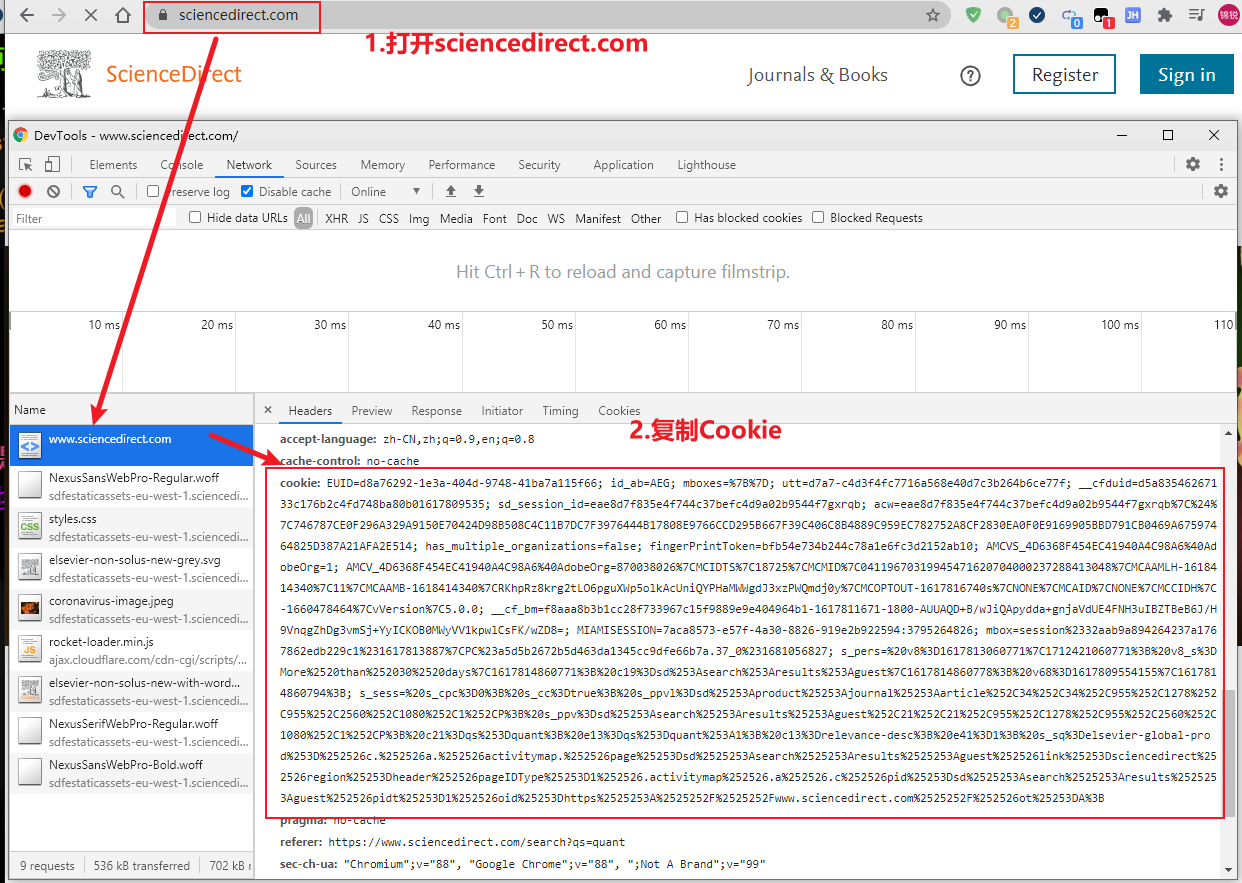
2.使用sciencedirect搜索时,需要用search_by_science_direct函数,并将cookie作为参数之一传入:
from scihub import SciHub
sh = SciHub()
# 搜索词
keywords = "quant"
# 搜索该关键词相关的论文,limit为篇数
result = sh.search_by_science_direct(keywords, cookie="你的cookie", limit=10)
print(result)
for index, paper in enumerate(result.get("papers", [])):
# 批量下载这些论文
sh.download(paper["doi"], path=f"files/{keywords.replace(' ', '_')}_{index}.pdf")这样就能顺利通过sciencedirect搜索论文并下载了。
publons渠道:
其实有了百度学术的默认渠道,大部分文献我们都能覆盖到了。但是考虑到publons的特殊性,这里还是给大家一个通过publons渠道搜索下载的选项。
使用publons渠道搜索下载其实很简单,你只需要更改搜索的函数名即可,不需要配置Cookie:
from scihub import SciHub
sh = SciHub()
# 搜索词
keywords = "quant"
# 搜索该关键词相关的论文,limit为篇数
result = sh.search_by_publons(keywords, limit=10)
print(result)
for index, paper in enumerate(result.get("papers", [])):
# 批量下载这些论文
sh.download(paper["doi"], path=f"files/{keywords.replace(' ', '_')}_{index}.pdf")5.异步批量下载优化,增加超时控制
这份代码已经运行了几个月,经常有同学反馈搜索论文后批量下载论文的速度过慢、下载的文件损坏的问题,这几天刚好有时间一起解决了。
下载速度过慢是因为之前的版本使用了串行的方式去获取数据和保存文件,事实上对于这种IO密集型的操作,最高效的方式是用 asyncio 异步的形式去进行文件的下载。
而下载的文件损坏则是因为下载时间过长,触发了超时限制,导致文件传输过程直接被腰斩了。
因此,我们将在原有代码的基础上添加两个方法:1.异步请求下载链接,2.异步保存文件。
此外增加一个错误提示:如果下载超时了,提示用户下载超时并不保存损坏的文件,用户可自行选择调高超时限制。
首先,新增异步获取scihub直链的方法,改为异步获取相关论文的scihub直链:
async def async_get_direct_url(self, identifier):
"""
异步获取scihub直链
"""
async with aiohttp.ClientSession() as sess:
async with sess.get(self.base_url + identifier) as res:
logger.info(f"获取 {self.base_url + identifier} 中...")
# await 等待任务完成
html = await res.text(encoding='utf-8')
s = self._get_soup(html)
frame = s.find('iframe') or s.find('embed')
if frame:
return frame.get('src') if not frame.get('src').startswith('//') \
else 'http:' + frame.get('src')
else:
logger.error("Error: 可能是 Scihub 上没有收录该文章, 请直接访问上述页面看是否正常。")
return html这样,在搜索论文后,调用该接口就能获取所有需要下载的scihub直链,速度很快:
def search(keywords: str, limit: int):
"""
搜索相关论文并下载
Args:
keywords (str): 关键词
limit (int): 篇数
"""
sh = SciHub()
result = sh.search(keywords, limit=limit)
print(result)
loop = asyncio.get_event_loop()
# 获取所有需要下载的scihub直链
tasks = [sh.async_get_direct_url(paper["doi"]) for paper in result.get("papers", [])]
all_direct_urls = loop.run_until_complete(asyncio.gather(*tasks))
print(all_direct_urls)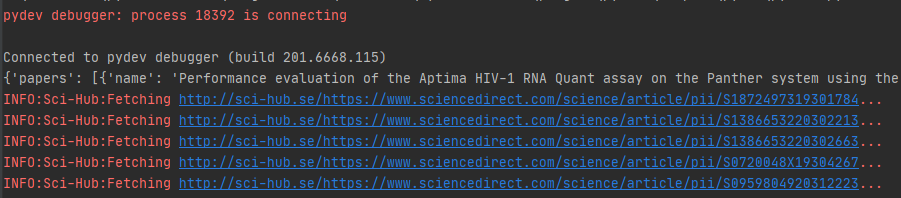
获取直链后,需要下载论文,同样也是IO密集型操作,增加2个异步函数:
async def job(self, session, url, destination='', path=None):
"""
异步下载文件
"""
if not url:
return
file_name = url.split("/")[-1].split("#")[0]
logger.info(f"正在读取并写入 {file_name} 中...")
# 异步读取内容
try:
url_handler = await session.get(url)
content = await url_handler.read()
except Exception as e:
logger.error(f"获取源文件出错: {e},大概率是下载超时,请检查")
return str(url)
with open(os.path.join(destination, path + file_name), 'wb') as f:
# 写入至文件
f.write(content)
return str(url)
async def async_download(self, loop, urls, destination='', path=None):
"""
触发异步下载任务
如果你要增加超时时间,请修改 total=300
"""
async with aiohttp.ClientSession(timeout=aiohttp.ClientTimeout(total=300)) as session:
# 建立会话session
tasks = [loop.create_task(self.job(session, url, destination, path)) for url in urls]
# 建立所有任务
finished, unfinished = await asyncio.wait(tasks)
# 触发await,等待任务完成
[r.result() for r in finished]这样,最后,在search函数中补充下载操作:
import asyncio
from scihub import SciHub
def search(keywords: str, limit: int):
"""
搜索相关论文并下载
Args:
keywords (str): 关键词
limit (int): 篇数
"""
sh = SciHub()
result = sh.search(keywords, limit=limit)
print(result)
loop = asyncio.get_event_loop()
# 获取所有需要下载的scihub直链
tasks = [sh.async_get_direct_url(paper["doi"]) for paper in result.get("papers", [])]
all_direct_urls = loop.run_until_complete(asyncio.gather(*tasks))
print(all_direct_urls)
# 下载所有论文
loop.run_until_complete(sh.async_download(loop, all_direct_urls, path=f"files/"))
loop.close()
if __name__ == '__main__':
search("quant", 10)
一个完整的下载过程就OK了:
比以前的方式舒服太多太多了… 如果你要增加超时时间,请修改async_download函数中的 total=300,把这个请求总时间调高即可。
最新代码前往GitHub上下载:
https://github.com/Ckend/scihub-cn
或者从Python实用宝典公众号后台回复 scihub 下载。
6.根据DOI号下载文献
最近有同学希望直接通过DOI号下载文献,因此补充了这部分内容。
import asyncio
from scihub import SciHub
def fetch_by_doi(dois: list, path: str):
"""
根据 doi 获取文档
Args:
dois: 文献DOI号列表
path: 存储文件夹
"""
sh = SciHub()
loop = asyncio.get_event_loop()
# 获取所有需要下载的scihub直链
tasks = [sh.async_get_direct_url(doi) for doi in dois]
all_direct_urls = loop.run_until_complete(asyncio.gather(*tasks))
print(all_direct_urls)
# 下载所有论文
loop.run_until_complete(sh.async_download(loop, all_direct_urls, path=path))
loop.close()
if __name__ == '__main__':
fetch_by_doi(["10.1088/1751-8113/42/50/504005"], f"files/")默认存储到files文件夹中,你也可以根据自己的需求对代码进行修改。
7.工作原理
这个API的源代码其实非常好读懂。
一、找到sci-hub目前可用的域名
首先它会在这个网址里找到sci-hub当前可用的域名,用于下载论文:
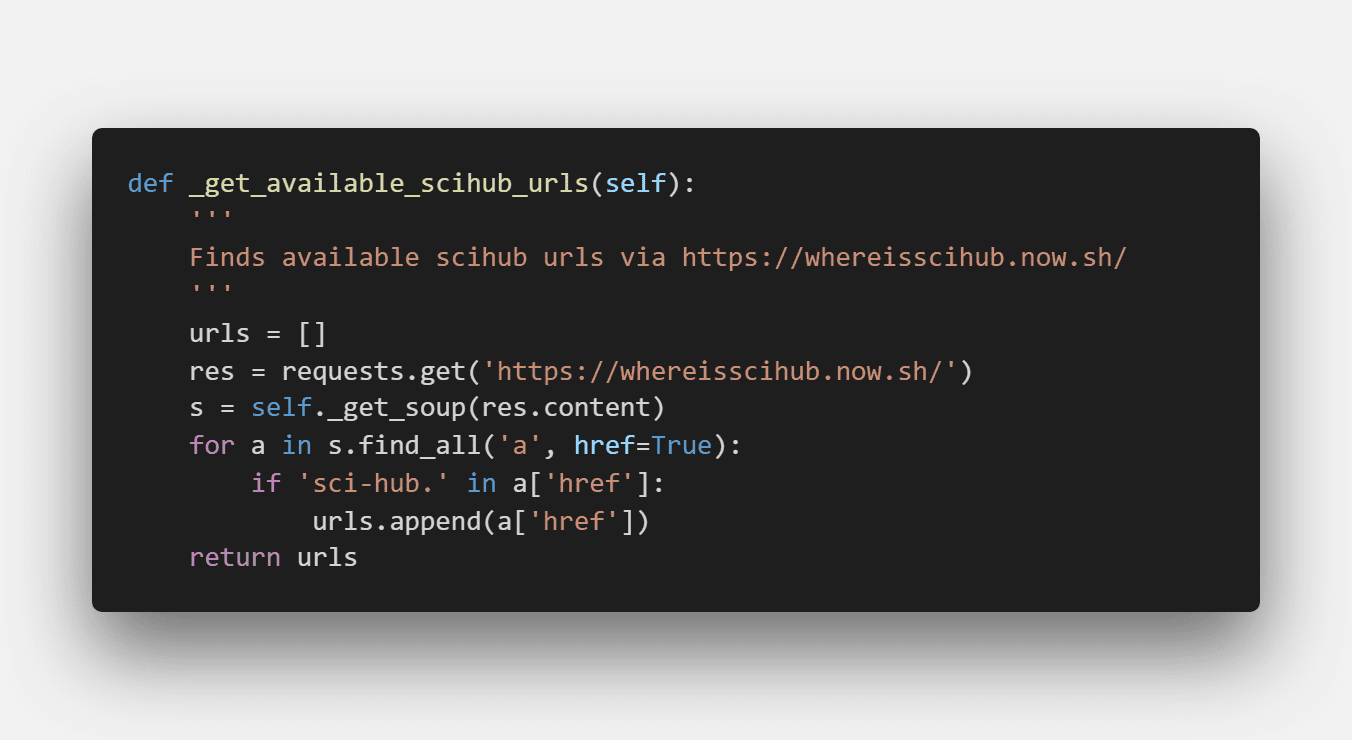
可惜的是,作者常年不维护,该地址已经失效了,我们就是在这里修改了该域名,使得项目得以重新正常运作:

二、对用户输入的论文地址进行解析,找到相应论文
1. 如果用户输入的链接不是直接能下载的,则使用sci-hub进行下载
2. 如果scihub的网址无法使用则切换另一个网址使用,除非所有网址都无法使用。

3.如果用户输入的是关键词,将调用sciencedirect的接口,拿到论文地址,再使用scihub进行论文的下载。
三、下载
1. 拿到论文后,它保存到data变量中
2. 然后将data变量存储为文件即可
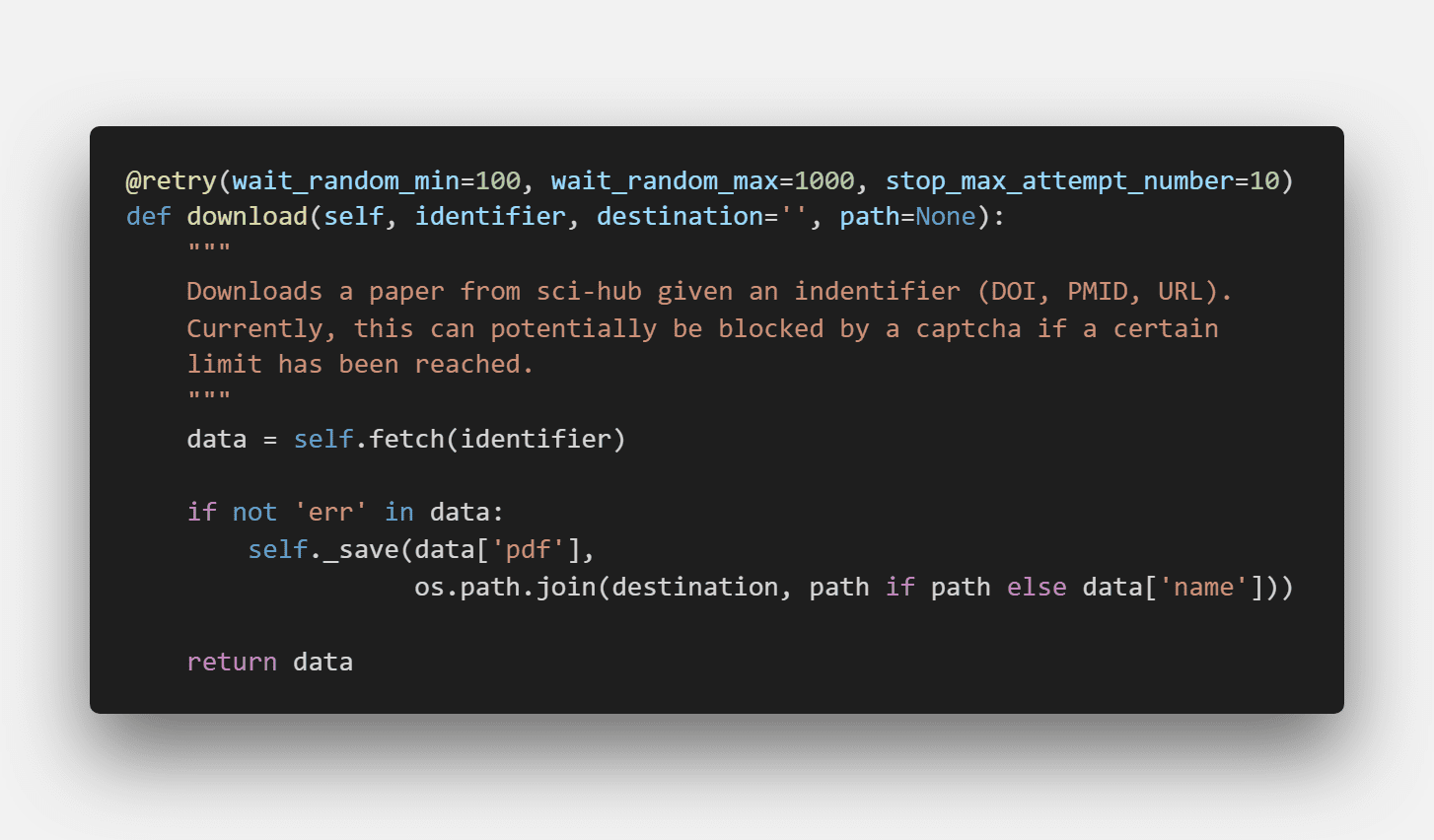
此外,代码用到了一个retry装饰器,这个装饰器可以用来进行错误重试,作者设定了重试次数为10次,每次重试最大等待时间不超过1秒。
我们的文章到此就结束啦,如果你希望我们今天的文章,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦,有任何问题都可以在下方留言区留言,我们都会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典

评论(79)
cannot import name ‘SciHub’
为什么我IMPROT 不了呀?
要下载下来,和scihub.py一个文件夹哦。
为啥批量下载没有反应呢?就是把download.py换成下面的没用啊
from scihub import SciHub
sh = SciHub()
# 获取在谷歌学术上 ‘bittorrent’ 关键词的5篇文章
results = sh.search(‘bittorrent’, 5)
# 下载论文,有需要的话会调用scihub
for paper in results[‘papers’]:
sh.download(paper[‘url’])
用CMD进入该文件夹中,然后输入 python download.py 命令,看看提示什么
输入pip install -r requirements.txt直接报错闪退了,这怎么解决
WIN+R,输入cmd进入cmd,然后cd到你的文件夹目录,输入这条命令,看看报什么错。
运行download.py后,显示scihub.py中第43行出现list index out of range问题,怎么解决?
说明此时没有可用的下载站了,过段时间我看看有没有别的下载站
2020-05-17补充:由于网络问题,这个模块有可能使用不了,如果无法使用,建议大家用 http://tool.yovisun.com/scihub/ 搜索目前可用的scihub进行论文的下载,感谢@lisenjor的分享。
太有用啦~
File “E:\python\scihub\scihub\scihub.py”, line 43, in __init__
self.base_url = self.available_base_url_list[0] + ‘/’
IndexError: list index out of range
报错了
说明没找到可用的url,这个服务最近可能无法使用了
2020-05-17补充:由于网络问题,这个模块有可能使用不了,如果无法使用,建议大家用 http://tool.yovisun.com/scihub/ 搜索目前可用的scihub进行论文的下载,感谢@lisenjor的分享。
http://tool.yovisun.com/scihub/
这个网站可用找到url
这个不错,我列上去
可是我尝试把源代码中的网址换成这个,甚至是直接把几个可用网址用列表列出来,不报错了,但是下载没反应
是的,源代码中包含了提取可用链接的部分,可能是提取出来的链接不正确,你可以在相关下载代码前DEBUG一下或者print下载链接,看看正不正确。
请问怎样把源代码中的sciencedirect换成NCBI呢
源代码里有一个链接可以替换
谢谢您,但是我将源代码中两条链接更换后运行脚本会报错
请问 为什么我运行的时候,显示can’t find download.py 呢?
和终端目前所在的文件夹有关,要在scihub文件夹下运行命令
安装依赖pip install -r requirements.txt 的时候报错,
ERROR:Could not find aversion that satisfies the requirement beautifulsoup 4(from -r requirement. txt (line 1)
是beautifulsoup4,不是beautifulsoup 4,后者多了一个空格
谢谢及时的回复,之前由于是在手机上输入,多打了一个空格,具体出现的错误如下,ERROR: Could not find a version that satisfies the requirement beautifulsoup4 (from -r requirements.txt (line 1)) (from versions: none)
ERROR: No matching distribution found for beautifulsoup4 (from -r requirements.txt (line 1))。这样该周末解决呢?
先试一下升级pip:
pip install –upgrade pip
再试试:
pip install beautifulsoup4
如果不行可以按照bs4:
pip install bs4
先试一下升级pip:
pip install –upgrade pip
再试试:
pip install beautifulsoup4
如果不行可以安装bs4:
pip install bs4
关键字下载的时候 可以换换除了 sciencedirect以外 的接口吗,
可以的,不过需要简单修改一下
怎么改呢 如果方便的话也可以出个 教程,TOT我改了几次都出错了orz
可以把你希望用的网站发给我,我来提供选项
请问Errno2咋办,其实我是有keywords-download.py的,是python要和这个文件夹在同一个大文件夹里吗?
有没有详细的错误信息
期待google scholar 或者pubmed的模式
我也想知道,怎么换接口了?不用sciencedirect,另外我下载限制为100篇,为什么只出来40篇左右了?
换接口需要改代码里的链接和相应的元素参数,可以把你希望用的网站发给我,我来提供选项
请问运行python出现下面信息提示,怎么办?请各位大神指教。
INFO: Sci-Hub: Failed to fetch pdf with identifier science/article/pii/S0308814620325504 (resolved url None) due to request exception.
应该是网络问题
一直都显示是:{‘papers’: [], ‘err’: ‘Failed to complete search with query klebsiella pneumoniae (connection error)’},
无论怎么更换keywords都是这个结果,但是我自己网络用起来是好的
搜索的网站属于外网,所以可能会出现无法访问的情况: https://www.sciencedirect.com/search 可以试试直接访问,如果访问不了,说明还是网络的问题,后期将找到一个可以替换sciencedirect的网站
我就一直搞不懂建立文件夹是在哪里建立呢 一直是 cannot import name ‘SciHub’
要在与scihub.py文件同级的文件夹下新建download.py. 如果你是下载的代码,会发现已经有这个文件了,直接运行即可。(https://github.com/Ckend/scihub-cn)
rror running ‘scihub’: Cannot run program “C:\Users\郭丰磊\PycharmProjects\pythonProject\venv\Scripts\python.exe” (in directory “C:\Users\xxx\PycharmProjects\pythonProject\scihub-cn-master\scihub”): CreateProcess error=2, 系统找不到指定的文件 一直显示这样的
代码下载是有固定的储存路径吗
运行python download.py 没反应也没任何提示呢
有相关截图吗
有两个问题:1。为什么我运行这串代码的时候总是提示说找不到scihub这个模块,我是按照代码进行的啊?
2.为什么我无法加群啊,加了微信,也没有任何反应啊?
1.终端要进入download.py的文件夹运行。
2.你的微信多少,我加一下,最近加的人比较多,没有按照要求的回答都没加。
您好,在cmd中输入pip那句时报错:
ERROR: Could not find a version that satisfies the requirement retrying (from -r requirements.txt (line 3)) (from versions: none)
ERROR: No matching distribution found for retrying (from -r requirements.txt (line 3))
噢,看错了,可能是源的问题,试试这样: pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
您好,刚才的问题换了台电脑已解决(感谢!),现在运行download.py后报错如下:
aiohttp.client_exceptions.ServerDisconnectedError: Server disconnected
您好!我在使用中遇到以下问题:
Traceback (most recent call last):
File “D:\LearningStuff\scihub-cn-master\scihub\scihub.py”, line 257, in job
file_name = url.split(“/”)[-1].split(“#”)[0]
AttributeError: ‘NoneType’ object has no attribute ‘split’
ERROR:asyncio:Task exception was never retrieved
future: <Task finished name='Task-566' coro= exception=AttributeError(“‘NoneType’ object has no attribute ‘split'”)>
请问如何解决?
获取直链的时候没有获取成功,检查一下该关键词是否真的能从sciencedirect上搜索到论文,然后试试手动上scihub上看看相关论文地址是否可以下载。
我使用cmd输入运行命令提示错误如下:
ModuleNotFoundError: No module named ‘aiohttp’
如果在Visual Studio Code终端运行提示如下错误:
python.exe: can’t open file ‘d:\PythonPractise\scihub-cn’: [Errno 2] No such file or directory
向大神求救!
没进入到 d:\PythonPractise\scihub-cn\scihub\ 去运行 python download.py
sh.fetch 命令可以正常运行,但sh.download和sh.search显示以下错误:
AttributeError: ‘SciHub’ object has no attribute ‘download’
请问如何解决
不太应该,是不是没和scihub.py在一个文件中
第一个运行”python download.py”时,会报错“Traceback (most recent call last):
ModuleNotFoundError: No module named ‘aiohttp’”
需要:pip install aiohttp
你好,我在使用中遇到如下问题:
Traceback (most recent call last):
File “download.py”, line 30, in
search(“quant”, 5)
File “download.py”, line 25, in search
loop.run_until_complete(sh.async_download(loop, all_direct_urls, path=f”files/”))
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/asyncio/base_events.py”, line 468, in run_until_complete
return future.result()
File “/Users/han/PycharmProjects/scihub-cn-master/scihub/scihub.py”, line 279, in async_download
finished, unfinished = await asyncio.wait(tasks)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/asyncio/tasks.py”, line 304, in wait
raise ValueError(‘Set of coroutines/Futures is empty.’)
ValueError: Set of coroutines/Futures is empty.
你用的是Python3的哪个版本?感觉和asyncio版本有关。
当然也有可能是网络问题,导致task没有成功创建。
大佬您好!我也想加一些接口,除了sciencedirect的,希望能有pubs.acs.org,onlinelibrary.wiley.com, pubmed.ncbi.nlm.nih.gov, 这些接口,麻烦大佬赐教,多谢!
可以阅读scihub.py的源代码,其实不难理解,可以自行学一下如何提取
INFO:Sci-Hub:Failed to fetch pdf with identifier 10.1016/j.compeleceng.2020.106640 (resolved url None) due to request exception.zh
这个如何解决?
这篇论文还没被scihub收录吧
输出{‘papers’: []},报错ValueError: Set of coroutines/Futures is empty.这是什么原因?
已修复,请看最新文章
昨晚下载成功了几十篇了,今早又不行了。
发生异常: FileNotFoundError
[Errno 2] No such file or directory: ‘files/10.1016@j.jcv.2020.104524.pdf’
这个报错像是没有files文件夹,检查一下
可以修改sciencedirect为web of science吗?
准备增加这个选项了
不能直接用web of science,就用数组迭代的方式通过DOI号批量下载文献:
from scihub import SciHub
sh = SciHub()
from doilist import DOIs
index = len(DOIs)
for doi in DOIs:
result = sh.download(doi, path= str(index) + “.pdf”)
index -= 1
但是经常出现下面问题:
发生异常: TypeError
argument of type ‘NoneType’ is not iterable
File “C:\Downloads\py\scihub\scihub.py”, line 125, in download
if not ‘err’ in data:
File “C:\Downloads\py\scihub\DOI_download.py”, line 9, in
result = sh.download(doi, path= str(index) + “.pdf”)
这种情况经常是因为scihub没有收录此DOI指向的文档导致的,建议try except跳过
大牛,两个问题
1、请问 是最多只能下载 80篇吗?
limit300完全 不管作用
2、请问大牛能更新一下吗?让只下载近10年的文献
已经改版了,现在可以通过命令行下载:https://github.com/Ckend/scihub-cn
测试的时候提示
Traceback (most recent call last):
File “E:\scihub-cn\scihub\my_test.py”, line 2, in
sh = SciHub()
TypeError: __init__() missing 1 required positional argument: ‘proxy’
应该怎么解决啊
已经发生了改版,请看最新文章
现在可以通过命令行下载:https://github.com/Ckend/scihub-cn
pip install scihub-cn
下载只需要输入命令
$scihub-cn -w machine_learning