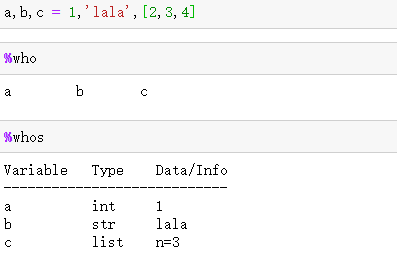
作者 | Erik-Jan van Baaren 译者 | 弯月,责编 | 屠敏 出品 | CSDN(ID:CSDNnews)
1. Python 版本
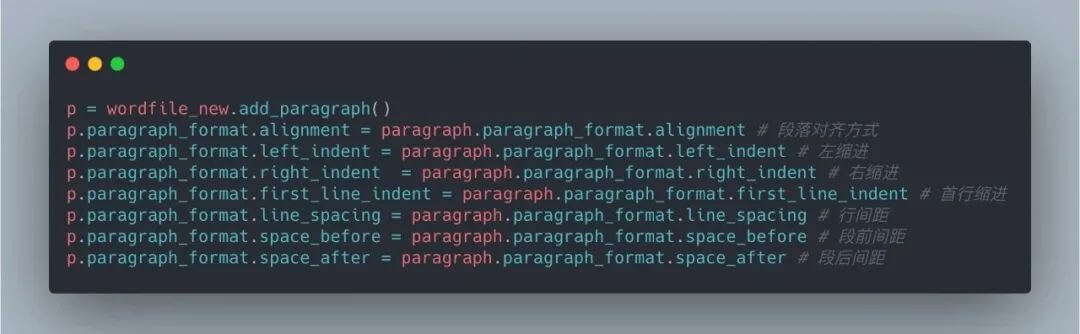
2. Python 编程技巧 – 检查 Python 的最低版本
# berate your user for running a 10 year
# python version
elif not sys.version_info >= (3, 5):
# Kindly tell your user (s)he needs to upgrade
# because you’re using 3.5 features
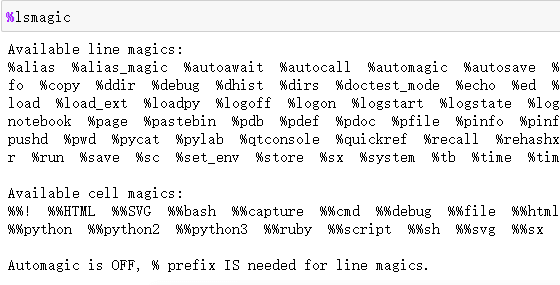
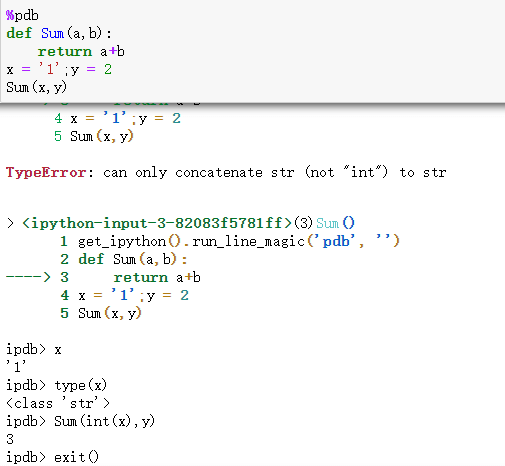
3.Python 编程技巧 – IPython

-
%cd:改变当前的工作目录
-
%edit:打开编辑器,并关闭编辑器后执行键入的代码
-
%env:显示当前环境变量
-
%pip install [pkgs]:无需离开交互式shell,就可以安装软件包
-
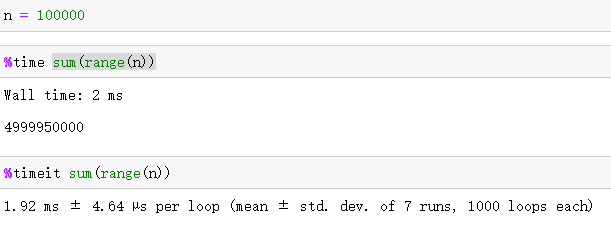
%time 和 %timeit:测量执行Python代码的时间
4.Python 编程技巧 – 列表推导式
print(mylist)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(squares)
# [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
return (a + 5) / 2
my_formula = [some_function(i) for i in range(10)]
print(my_formula)
# [2, 3, 3, 4, 4, 5, 5, 6, 6, 7]
print(filtered)
# [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
5. Python 编程技巧 -检查对象使用内存的状况
mylist = range(0, 10000)
print(sys.getsizeof(mylist))
# 48
myreallist = [x for x in range(0, 10000)]
print(sys.getsizeof(myreallist))
# 87632
6. Python 编程技巧 – 返回多个值
# fetch user from database
# ….
return name, birthdate
name, birthdate = get_user(4)
7. Python 编程技巧 – 使用数据类
-
数据类的代码量较少
-
你可以比较数据类,因为数据类提供了 __eq__ 方法
-
调试的时候,你可以轻松地输出数据类,因为数据类还提供了 __repr__ 方法
-
数据类需要类型提示,因此可以减少Bug的发生几率
@dataclass
class Card:
rank: str
suit: str
card = Card(“Q”, “hearts”)
print(card == card)
# True
print(card.rank)
# ‘Q’
print(card)
Card(rank=‘Q’, suit=‘hearts’)
8. Python 编程技巧 – 交换变量
b = 2
a, b = b, a
print (a)
# 2
print (b)
# 1
9. Python 编程技巧 – 合并字典(Python 3.5以上的版本)
dict2 = { ‘b’: 3, ‘c’: 4 }
merged = { **dict1, **dict2 }
print (merged)
# {‘a’: 1, ‘b’: 3, ‘c’: 4}
10. Python 编程技巧 – 字符串的首字母大写
print(mystring.title())
’10 Awesome Python Tricks’
11. Python 编程技巧 – 将字符串分割成列表
mylist = mystring.split(‘ ‘)
print(mylist)
# [‘The’, ‘quick’, ‘brown’, ‘fox’]
12. Python 编程技巧 – 根据字符串列表创建字符串
mystring = ” “.join(mylist)
print(mystring)
# ‘The quick brown fox’
13. Python 编程技巧 – 表情符


result = emoji.emojize(‘Python is :thumbs_up:’)
print(result)
# ‘Python is 👍’
# You can also reverse this:
result = emoji.demojize(‘Python is 👍’)
print(result)
# ‘Python is :thumbs_up:’
14. Python 编程技巧 – 列表切片
-
start:0
-
end:字符串的结尾
-
step:1
# the first two elements of a list:
first_two = [1, 2, 3, 4, 5][0:2]
print(first_two)
# [1, 2]
# And if we use a step value of 2,
# we can skip over every second number
# like this:
steps = [1, 2, 3, 4, 5][0:5:2]
print(steps)
# [1, 3, 5]
# This works on strings too. In Python,
# you can treat a string like a list of
# letters:
mystring = “abcdefdn nimt”[::2]
print(mystring)
# ‘aced it’
15. Python 编程技巧 – 反转字符串和列表
print(revstring)
# ‘gfedcba’
revarray = [1, 2, 3, 4, 5][::-1]
print(revarray)
# [5, 4, 3, 2, 1]
16. Python 编程技巧 – 显示猫猫


im = Image.open(“kittens.jpg”)
im.show()
print(im.format, im.size, im.mode)
# JPEG (1920, 1357) RGB
17. Python 编程技巧 – map()
return s.upper()
mylist = list(map(upper, [‘sentence’, ‘fragment’]))
print(mylist)
# [‘SENTENCE’, ‘FRAGMENT’]
# Convert a string representation of
# a number into a list of ints.
list_of_ints = list(map(int, “1234567”)))
print(list_of_ints)
# [1, 2, 3, 4, 5, 6, 7]
18. Python 编程技巧 – 获取列表或字符串中的唯一元素
print (set(mylist))
# {1, 2, 3, 4, 5, 6}
# And since a string can be treated like a
# list of letters, you can also get the
# unique letters from a string this way:
print (set(“aaabbbcccdddeeefff”))
# {‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’}
19. Python 编程技巧 – 查找出现频率最高的值
print(max(set(test), key = test.count))
# 4
-
max() 会返回列表的最大值。参数 key 会接受一个参数函数来自定义排序,在本例中为 test.count。该函数会应用于迭代对象的每一项。
-
test.count 是 list 的内置函数。它接受一个参数,而且还会计算该参数的出现次数。因此,test.count(1) 将返回2,而 test.count(4) 将返回4。
-
set(test) 将返回 test 中所有的唯一值,也就是 {1, 2, 3, 4}。
20. Python 编程技巧 – 创建一个进度条
bar = Bar(‘Processing’, max=20)
for i in range(20):
# Do some work
bar.next()
bar.finish()
21. Python 编程技巧 – 在交互式shell中使用_(下划线运算符)
Out[1]: 9In [2]: _ + 3
Out[2]: 12
22. Python 编程技巧 – 快速创建Web服务器
23. Python 编程技巧 – 多行字符串
between triple quotes. It’s not ideal
when formatting your code though”””
print (s1)
# Multi line strings can be put
# between triple quotes. It’s not ideal
# when formatting your code though
s2 = (“You can also concatenate multiple\n” +
“strings this way, but you’ll have to\n”
“explicitly put in the newlines”)
print(s2)
# You can also concatenate multiple
# strings this way, but you’ll have to
# explicitly put in the newlines
24. Python 编程技巧 – 条件赋值中的三元运算符
25. Python 编程技巧 – 统计元素的出现次数
mylist = [1, 1, 2, 3, 4, 5, 5, 5, 6, 6]
c = Counter(mylist)
print(c)
# Counter({1: 2, 2: 1, 3: 1, 4: 1, 5: 3, 6: 2})
# And it works on strings too:
print(Counter(“aaaaabbbbbccccc”))
# Counter({‘a’: 5, ‘b’: 5, ‘c’: 5})
26. Python 编程技巧 – 比较运算符的链接
# Instead of:
if x > 5 and x < 15:
print(“Yes”)
# yes
# You can also write:
if 5 < x < 15:
print(“Yes”)
# Yes
27. Python 编程技巧 – 添加颜色


print(Fore.RED + ‘some red text’)
print(Back.GREEN + ‘and with a green background’)
print(Style.DIM + ‘and in dim text’)
print(Style.RESET_ALL)
print(‘back to normal now’)
28. Python 编程技巧 – 日期的处理
logline = ‘INFO 2020-01-01T00:00:01 Happy new year, human.’
timestamp = parse(log_line, fuzzy=True)
print(timestamp)
# 2020-01-01 00:00:01
29.Python 编程技巧 – 整数除法


5 / 2 = 2
5 / 2.0 = 2.5
5 / 2 = 2.5
5 // 2 = 2
30. Python 编程技巧 – 通过chardet 来检测字符集
somefile.txt: ascii with confidence 1.0
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典