









△ 10×10 的《星空》

△ 25×25 的《星空》

△ 50×50 的《星空》
















Python tiler 实战教程


脑洞丰富的作者



我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典


我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
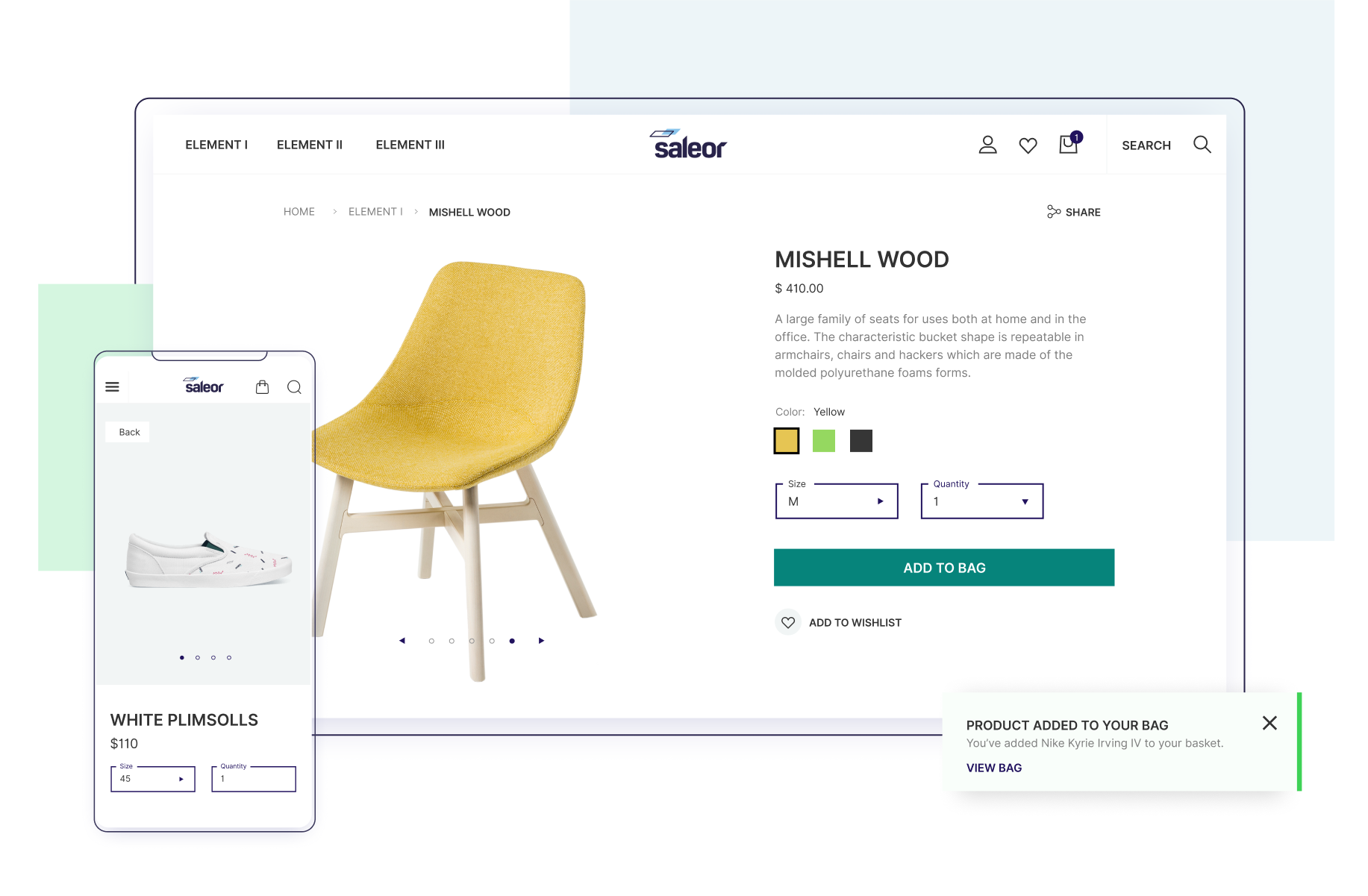
Saleor 是一个快速发展的开源电子商务平台,基于 Python 和 Django开发,且持续更新中,一点不用担心版本过旧的问题。
它的特点如下:
1.GraphQL API:基于GraphQL实现的前后端分离,属于最前沿的技术。
2.仪表板:管理员可以完全控制用户、流程和产品。
3.订单:订单、发货和退款的综合系统。
4.购物车:高级付款和税收选项,支持折扣和促销活动
5.支付:灵活的 API 架构允许集成任何支付方式。
6.地理自适应:自动支持多国家的结账体验。
7.支持云部署:支持Docker部署。
8.支持谷歌分析:集成了谷歌分析,可以很方便地分析流量去留。
Saleor 仓库地址:
https://github.com/mirumee/saleor
Saleor支持多种运行方式,你可以采用手动安装并运行的方式,也可以使用Docker进行运行,下面介绍全平台通用且最简单的Docker部署方案。
在按照以下说明操作之前,你需要安装Docker Desktop和Docker Compose。
Docker 部署 Saleor 非常方便,你只需要克隆存储库并构建镜像然后运行服务即可:
# Python 实用宝典 # 克隆存储库 git clone https://github.com/mirumee/saleor-platform.git --recursive --jobs 3 cd saleor-platform # 构建Docker镜像 docker-compose build
如果你无法成功克隆 Salor 源代码仓库,请在Python实用宝典公众号回复:Saleor 下载全部源代码。
Saleor 使用共享文件夹来启用实时代码重新加载。如果你使用的是Windows或MacOS,则需要:
1.将克隆的 saleor-platform 目录放置到 Docker 的共享目录配置 (Settings -> Shared Drives or Preferences -> Resources -> File sharing)。
2.确保在 Docker 首选项中你有至少 5 GB 的专用内存(设置 -> 高级 或 首选项->资源 -> 高级)
执行数据库migrations及打包前端资源:
docker-compose run --rm api python3 manage.py migrate docker-compose run --rm api python3 manage.py collectstatic --noinput
(可选)使用示例数据填充数据库:
docker-compose run --rm api python3 manage.py populatedb
最后,为自己创建一个管理员帐户:
docker-compose run --rm api python3 manage.py createsuperuser
运行服务:
使用以下命令运行Saleor:
docker-compose up

如果你要基于 Saleor 进行开发,那么你必须了解它的架构。
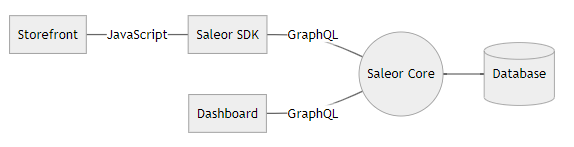
Saleor 由三个重要组件组成:
1.Saleor Core, 它是GraphQL API的后端服务器。基于Django开发,数据库采用了PostgreSQL并在Redis中储存了一些缓存信息。
2.Saleor Dashboard, 这是一个可以用来经营商店的仪表盘,它是一个静态网站,因此没有任何自己的后端代码,它是一个与Saleor Core核心服务器对话的React程序。
3.Saleor Storefront, 这是基于React实现的示例商店,你可以自定义这部分代码满足你自己的需求,也可以使用 Saleor SDK 构建自定义店面。
所有三个组件都使用 GraphQL 通过 HTTPS 进行通信。
虽然你可以直接基于Saleor源代码进行开发,但是官方建议不这么做,原因是一旦你的代码和Saleor官方源代码产生冲突,你就很难跟上官方的更新,最终会导致代码没人维护的尴尬局面。
因此Saleor提供了两种添加功能的方式:
1.插件功能:插件提供了一种在Saleor Core上运行附加代码的能力,而且有访问数据库的能力。
2.APPS:基于GraphQL API和Saleor Core开发APP,还可以使用WebHooks订阅事件。
下面我们介绍如何基于插件进行扩展开发。
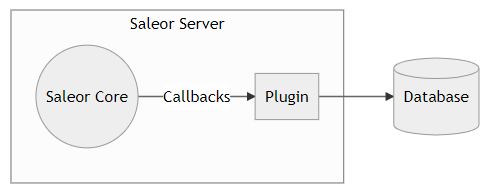
如上图所示,Saleor Core 提供了一种回调通知事件给插件,插件基于此事件进行相关操作,并与数据库进行交互。
开发插件,你必须继承 BasePlugin 基类,然后重写部分方法,比如下面这个例子重写了 postprocess_order_creation 方法,增加了订单创建时的一些操作:
# Python实用宝典
# custom/plugin.py
from django.conf import settings
from urllib.parse import urljoin
from ..base_plugin import BasePlugin
from .tasks import api_post_request_task
class CustomPlugin(BasePlugin):
def postprocess_order_creation(self, order: "Order", previous_value: Any):
# 订单创建时的操作
data = ...
transaction_url = urljoin(settings.CUSTOM_API_URL, "transactions/createoradjust")
api_post_request_task.delay(transaction_url, data)加载插件, 需要在 setup.py 进行配置来自动发现已安装的插件。要使插件可被发现,你需要设置 entry_points 的 saleor_plugins 字段, 并使用这个语法定义插件:package_name = package_name.path.to:PluginClass.
示例如下:
# setup.py
from setuptools import setup
setup(
...,
entry_points={
"saleor.plugins": [
"my_plugin = my_plugin.plugin:MyPlugin"
]
}
)如果你的插件是 Django 应用程序,包名(等号前的部分)将被添加到 Django 的 INSTALLED_APPS 中,以便你可以利用 Django 的功能,例如 ORM 集成和数据库迁移。
注意到我们前面订单创建时的操作使用了 .delay 的语法,这是 Celery 的异步任务。因为有些插件的操作就应该异步完成,Saleor 使用 Celery 并将发现 tasks.py 在插件目录中声明的所有异步任务:
# custom_plugin/tasks.py
import json
from celery import shared_task
from typing import Any, Dict
import requests
from requests.auth import HTTPBasicAuth
from django.conf import settings
@shared_task
def api_post_request(
url: str,
data: Dict[str, Any],
):
try:
username = "username"
password = "password"
auth = HTTPBasicAuth(username, password)
requests.post(url, auth=auth, data=json.dumps(data), timeout=settings.TIMEOUT)
except requests.exceptions.RequestException:
return上面这个 api_post_request 函数就是前面插件用到的异步任务,在插件调用delay方法后,这个任务将被塞到队列中异步执行。
好了,上面就是一个简单的插件开发例子,个人认为Saleor的开发模式还是很不错的。如果大家有需要,可以采用这个项目构建一个属于自己的商城。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

对于MySQL的监控平台,相信大家实现起来有很多了:基于天兔的监控,还有基于zabbix相关的二次开发。相信很多同行都应该已经开始玩起来了。我这边的选型是Prometheus + Granafa的实现方式。简而言之就是我现在的生产环境使用的是prometheus,还有就是granafa满足的我的日常工作需要。在入门的简介和安装,大家可以参考这里:
1、首先看下我们的监控效果、mysql主从

2、mysql状态:


3、缓冲池状态:

1、安装exporter
[root@controller2 opt]# https://github.com/prometheus/mysqld_exporter/releases/download/v0.10.0/mysqld_exporter-0.10.0.linux-amd64.tar.gz
[root@controller2 opt]# tar -xf mysqld_exporter-0.10.0.linux-amd64.tar.gz
2、添加mysql 账户:
GRANT SELECT, PROCESS, SUPER, REPLICATION CLIENT, RELOAD ON *.* TO 'exporter'@'%' IDENTIFIED BY 'localhost';
flush privileges;
3、编辑配置文件:
[root@controller2 mysqld_exporter-0.10.0.linux-amd64]# cat /opt/mysqld_exporter-0.10.0.linux-amd64/.my.cnf
[client]
user=exporter
password=123456
4、设置配置文件:
[root@controller2 mysqld_exporter-0.10.0.linux-amd64]# cat /etc/systemd/system/mysql_exporter.service
[Unit]
Description=mysql Monitoring System
Documentation=mysql Monitoring System
[Service]
ExecStart=/opt/mysqld_exporter-0.10.0.linux-amd64/mysqld_exporter \
-collect.info_schema.processlist \
-collect.info_schema.innodb_tablespaces \
-collect.info_schema.innodb_metrics \
-collect.perf_schema.tableiowaits \
-collect.perf_schema.indexiowaits \
-collect.perf_schema.tablelocks \
-collect.engine_innodb_status \
-collect.perf_schema.file_events \
-collect.info_schema.processlist \
-collect.binlog_size \
-collect.info_schema.clientstats \
-collect.perf_schema.eventswaits \
-config.my-cnf=/opt/mysqld_exporter-0.10.0.linux-amd64/.my.cnf
[Install]
WantedBy=multi-user.target
5、添加配置到prometheus server
- job_name: 'mysql'
static_configs:
- targets: ['192.168.1.11:9104','192.168.1.12:9104']
6、测试看有没有返回数值:
http://192.168.1.12:9104/metrics
正常我们通过mysql_up可以查询倒mysql监控是否已经生效,是否起起来
#HELP mysql_up Whether the MySQL server is up.
#TYPE mysql_up gauge
mysql_up 1
在做任何一个东西监控的时候,我们要时刻明白我们要监控的是什么,指标是啥才能更好的去监控我们的服务,在mysql里面我们通常可以通过一下指标去衡量mysql的运行情况:mysql主从运行情况、查询吞吐量、慢查询情况、连接数情况、缓冲池使用情况以及查询执行性能等。
1、主从复制线程监控:
大部分情况下,很多企业使用的都是主从复制的环境,监控两个线程是非常重要的,在mysql里面我们通常是通过命令:
MariaDB [(none)]> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.16.1.1
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000045
Read_Master_Log_Pos: 72904854
Relay_Log_File: mariadb-relay-bin.000127
Relay_Log_Pos: 72905142
Relay_Master_Log_File: mysql-bin.000045
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Slave_IO_Running、Slave_SQL_Running两个线程正常那么说明我们的复制集群是健康状态的。
MySQLD Exporter中返回的样本数据中通过mysql_slave_status_slave_sql_running来获取主从集群的健康状况。
# HELP mysql_slave_status_slave_sql_running Generic metric from SHOW SLAVE STATUS.
# TYPE mysql_slave_status_slave_sql_running untyped
mysql_slave_status_slave_sql_running{channel_name="",connection_name="",master_host="172.16.1.1",master_uuid=""} 1
2、主从复制落后时间:
在使用show slave status
里面还有一个关键的参数Seconds_Behind_Master。Seconds_Behind_Master表示slave上SQL thread与IO thread之间的延迟,我们都知道在MySQL的复制环境中,slave先从master上将binlog拉取到本地(通过IO thread),然后通过SQL
thread将binlog重放,而Seconds_Behind_Master表示本地relaylog中未被执行完的那部分的差值。所以如果slave拉取到本地的relaylog(实际上就是binlog,只是在slave上习惯称呼relaylog而已)都执行完,此时通过show slave status看到的会是0
Seconds_Behind_Master: 0
MySQLD Exporter中返回的样本数据中通过mysql_slave_status_seconds_behind_master 来获取相关状态。
# HELP mysql_slave_status_seconds_behind_master Generic metric from SHOW SLAVE STATUS.
# TYPE mysql_slave_status_seconds_behind_master untyped
mysql_slave_status_seconds_behind_master{channel_name="",connection_name="",master_host="172.16.1.1",master_uuid=""} 0
说到吞吐量,那么我们如何从那方面来衡量呢?
通常来说我们可以根据mysql 的插入、查询、删除、更新等操作来
为了获取吞吐量,MySQL 有一个名为 Questions 的内部计数器(根据 MySQL
用语,这是一个服务器状态变量),客户端每发送一个查询语句,其值就会加一。由 Questions 指标带来的以客户端为中心的视角常常比相关的Queries
计数器更容易解释。作为存储程序的一部分,后者也会计算已执行语句的数量,以及诸如PREPARE 和 DEALLOCATE PREPARE
指令运行的次数,作为服务器端预处理语句的一部分。可以通过命令来查询:
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Questions";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Questions | 15071 |
+---------------+-------+
MySQLD Exporter中返回的样本数据中通过mysql_global_status_questions反映当前Questions计数器的大小:
# HELP mysql_global_status_questions Generic metric from SHOW GLOBAL STATUS.
# TYPE mysql_global_status_questions untyped
mysql_global_status_questions 13253
当然由于prometheus
具有非常丰富的查询语言,我们可以通过这个累加的计数器来查询某一短时间内的查询增长率情况,可以做相关的阈值告警处理、例如一下查询2分钟时间内的查询情况:
rate(mysql_global_status_questions[2m])
当然上面是总量,我们可以分别从监控读、写指令的分解情况,从而更好地理解数据库的工作负载、找到可能的瓶颈。通常,通常,读取查询会由 Com_select
指标抓取,而写入查询则可能增加三个状态变量中某一个的值,这取决于具体的指令:
Writes = Com_insert + Com_update + Com_delete
下面我们通过命令获取插入的情况:
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Com_insert";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_insert | 10578 |
+---------------+-------+
从MySQLD
Exporter的/metrics返回的监控样本中,可以通过global_status_commands_total获取当前实例各类指令执行的次数:
# HELP mysql_global_status_commands_total Total number of executed MySQL commands.
# TYPE mysql_global_status_commands_total counter
mysql_global_status_commands_total{command="create_trigger"} 0
mysql_global_status_commands_total{command="create_udf"} 0
mysql_global_status_commands_total{command="create_user"} 1
mysql_global_status_commands_total{command="create_view"} 0
mysql_global_status_commands_total{command="dealloc_sql"} 0
mysql_global_status_commands_total{command="delete"} 3369
mysql_global_status_commands_total{command="delete_multi"} 0
查询性能方面,慢查询也是查询告警的一个重要的指标。MySQL还提供了一个Slow_queries的计数器,当查询的执行时间超过long_query_time的值后,计数器就会+1,其默认值为10秒,可以通过以下指令在MySQL中查询当前long_query_time的设置:
MariaDB [(none)]> SHOW VARIABLES LIKE 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
当然我们也可以修改时间
MariaDB [(none)]> SET GLOBAL long_query_time = 5;
Query OK, 0 rows affected (0.00 sec)
然后我们而已通过sql语言查询MySQL实例中Slow_queries的数量:
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Slow_queries";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Slow_queries | 0 |
+---------------+-------+
1 row in set (0.00 sec)
MySQLD
Exporter返回的样本数据中,通过mysql_global_status_slow_queries指标展示当前的Slow_queries的值:
# HELP mysql_global_status_slow_queries Generic metric from SHOW GLOBAL STATUS.
# TYPE mysql_global_status_slow_queries untyped
mysql_global_status_slow_queries 0
同样的,更具根据Prometheus 慢查询语句我们也可以查询倒他某段时间内的增长率:
rate(mysql_global_status_slow_queries[5m])
监控客户端连接情况相当重要,因为一旦可用连接耗尽,新的客户端连接就会遭到拒绝。MySQL 默认的连接数限制为 151。
MariaDB [(none)]> SHOW VARIABLES LIKE 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
当然我们可以修改配置文件的形式来增加这个数值。与之对应的就是当前连接数量,当我们当前连接出来超过系统设置的最大值之后常会出现我们看到的Too many
connections(连接数过多),下面我查找一下当前连接数:
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Threads_connected";
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_connected | 41 |
+-------------------+-------
当然mysql 还提供Threads_running 这个指标,帮助你分隔在任意时间正在积极处理查询的线程与那些虽然可用但是闲置的连接。
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Threads_running";
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| Threads_running | 10 |
+-----------------+-------+
如果服务器真的达到 max_connections
限制,它就会开始拒绝新的连接。在这种情况下,Connection_errors_max_connections
指标就会开始增加,同时,追踪所有失败连接尝试的Aborted_connects 指标也会开始增加。
MySQLD Exporter返回的样本数据中:
# HELP mysql_global_variables_max_connections Generic gauge metric from SHOW GLOBAL VARIABLES.
# TYPE mysql_global_variables_max_connections gauge
mysql_global_variables_max_connections 151
表示最大连接数
# HELP mysql_global_status_threads_connected Generic metric from SHOW GLOBAL STATUS.
# TYPE mysql_global_status_threads_connected untyped
mysql_global_status_threads_connected 41
表示当前的连接数
# HELP mysql_global_status_threads_running Generic metric from SHOW GLOBAL STATUS.
# TYPE mysql_global_status_threads_running untyped
mysql_global_status_threads_running 1
表示当前活跃的连接数
# HELP mysql_global_status_aborted_connects Generic metric from SHOW GLOBAL STATUS.
# TYPE mysql_global_status_aborted_connects untyped
mysql_global_status_aborted_connects 31
累计所有的连接数
# HELP mysql_global_status_connection_errors_total Total number of MySQL connection errors.
# TYPE mysql_global_status_connection_errors_total counter
mysql_global_status_connection_errors_total{error="internal"} 0
#服务器内部引起的错误、如内存硬盘等
mysql_global_status_connection_errors_total{error="max_connections"} 0
#超出连接处引起的错误
当然根据prom表达式,我们可以查询当前剩余可用的连接数:
mysql_global_variables_max_connections - mysql_global_status_threads_connected
查询mysq拒绝连接数
mysql_global_status_aborted_connects
MySQL 默认的存储引擎 InnoDB
使用了一片称为缓冲池的内存区域,用于缓存数据表与索引的数据。缓冲池指标属于资源指标,而非工作指标,前者更多地用于调查(而非检测)性能问题。如果数据库性能开始下滑,而磁盘
I/O 在不断攀升,扩大缓冲池往往能带来性能回升。
默认设置下,缓冲池的大小通常相对较小,为 128MiB。不过,MySQL 建议可将其扩大至专用数据库服务器物理内存的 80% 大小。我们可以查看一下:
MariaDB [(none)]> show global variables like 'innodb_buffer_pool_size';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+
MySQLD Exporter返回的样本数据中,使用mysql_global_variables_innodb_buffer_pool_size来表示。
# HELP mysql_global_variables_innodb_buffer_pool_size Generic gauge metric from SHOW GLOBAL VARIABLES.
# TYPE mysql_global_variables_innodb_buffer_pool_size gauge
mysql_global_variables_innodb_buffer_pool_size 1.34217728e+08
Innodb_buffer_pool_read_requests记录了正常从缓冲池读取数据的请求数量。可以通过以下指令查看
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Innodb_buffer_pool_read_requests";
+----------------------------------+-------------+
| Variable_name | Value |
+----------------------------------+-------------+
| Innodb_buffer_pool_read_requests | 38465 |
+----------------------------------+-------------+
MySQLD
Exporter返回的样本数据中,使用mysql_global_status_innodb_buffer_pool_read_requests来表示。
# HELP mysql_global_status_innodb_buffer_pool_read_requests Generic metric from SHOW GLOBAL STATUS.
# TYPE mysql_global_status_innodb_buffer_pool_read_requests untyped
mysql_global_status_innodb_buffer_pool_read_requests 2.7711547168e+10
当缓冲池无法满足时,MySQL只能从磁盘中读取数据。Innodb_buffer_pool_reads即记录了从磁盘读取数据的请求数量。通常来说从内存中读取数据的速度要比从磁盘中读取快很多,因此,如果Innodb_buffer_pool_reads的值开始增加,可能意味着数据库的性能有问题。
可以通过以下只能查看Innodb_buffer_pool_reads的数量
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE "Innodb_buffer_pool_reads";
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| Innodb_buffer_pool_reads | 138 |
+--------------------------+-------+
1 row in set (0.00 sec)
MySQLD
Exporter返回的样本数据中,使用mysql_global_status_innodb_buffer_pool_read_requests来表示。
# HELP mysql_global_status_innodb_buffer_pool_reads Generic metric from SHOW GLOBAL STATUS.
# TYPE mysql_global_status_innodb_buffer_pool_reads untyped
mysql_global_status_innodb_buffer_pool_reads 138
通过以上监控指标,以及实际监控的场景,我们可以利用PromQL快速建立多个监控项。可以查看两分钟内读取磁盘的增长率的增长率:
rate(mysql_global_status_innodb_buffer_pool_reads[2m])
上面是我们简单列举的一些指标,下面我们使用granafa给 MySQLD_Exporter添加监控图表:
主从主群监控(模板7371):
相关mysql 状态监控7362:
缓冲池状态7365:
简单的告警规则
除了相关模板之外,没有告警规则那么我们的监控就是不完美的,下面列一下我们的监控告警规则
groups:
- name: MySQL-rules
rules:
- alert: MySQL Status
expr: up == 0
for: 5s
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: MySQL has stop !!!"
description: "检测MySQL数据库运行状态"
- alert: MySQL Slave IO Thread Status
expr: mysql_slave_status_slave_io_running == 0
for: 5s
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: MySQL Slave IO Thread has stop !!!"
description: "检测MySQL主从IO线程运行状态"
- alert: MySQL Slave SQL Thread Status
expr: mysql_slave_status_slave_sql_running == 0
for: 5s
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: MySQL Slave SQL Thread has stop !!!"
description: "检测MySQL主从SQL线程运行状态"
- alert: MySQL Slave Delay Status
expr: mysql_slave_status_sql_delay == 30
for: 5s
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: MySQL Slave Delay has more than 30s !!!"
description: "检测MySQL主从延时状态"
- alert: Mysql_Too_Many_Connections
expr: rate(mysql_global_status_threads_connected[5m]) > 200
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 连接数过多"
description: "{{$labels.instance}}: 连接数过多,请处理 ,(current value is: {{ $value }})"
- alert: Mysql_Too_Many_slow_queries
expr: rate(mysql_global_status_slow_queries[5m]) > 3
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 慢查询有点多,请检查处理"
description: "{{$labels.instance}}: Mysql slow_queries is more than 3 per second ,(current value is: {{ $value }})"
2、添加规则到prometheus:
rule_files:
- "rules/*.yml"
3、打开web ui我们可以看到规则生效了:

到处监控mysql的相关状态已经完成,大家可以根据mysql更多的监控指标去完善自己的监控,当然这一套就是我用在线上环境的,可以参考参考。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
这是Python改变生活系列的第三篇,讲到了如何通过Python的pyzbar批量识别快递单号的条形码,以提高我们的生活工作效率,这是一篇实战教程。
了解我的小伙伴可能都知道,小五经常给大家送书。最近一年,不算联合抽奖送书,单独我自购+出版社赞助已送出1000本书籍。
如果是自购的话,还需要自己联系快递小哥寄出书籍。

寄出后快递小哥会给我截图来反馈,然而我想要单号的时候就遇到问题了。
每次寄完书,我都只能得到n个截图(内含快递信息)。

为了及时反馈大家物流信息,我需要尽快将快递单号提取出来。
每次大概都有十几到几十张截图,手动去识别真的太麻烦。
不如先看看每张截图大概是什么样子,再去想想批量处理的办法吧。

主要是为了批量获取图片中的快递单号,我想到了两个解决办法:
用python识别条形码来直接获得准确快递单号
用python调用ocr,识别截图中的快递单号文字
大家觉得哪个更简单更准确呢?

今天我先聊聊第一种方法的流程和踩坑经历。
首先,第一步需要先获取文件夹中的所有截图,再依次进行条形码识别。
具体操作可以参考注释
import os
def get_jpg():
jpgs = []
path = os.getcwd()
for i in os.listdir(path): #获取文件列表
if i.split(".")[-1] == "jpg": #筛选jpg文件(截图)
oldname=os.path.join(path,i) #旧文件名
i = i.replace('微信图片_','')
newname=os.path.join(path,i) #新文件名
os.rename(oldname,newname) #改名
jpgs.append(i)
return jpgs
上面的代码中除了遍历筛选图片,还涉及了改名的操作。
这是因为我在后面使用 opencv 时,打开的路径只要含有中文就会一直报错,于是我就干脆把截图名称里的中文去除。
执行构建的get_jpg()函数,得到
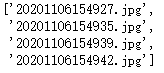
这些就是演示文件中的四个截图文件,下面开始对他们进行识别。
python的第三方模块 pyzbar 可以很方便地处理二维码的识别。我们这次用它来识别一维条形码的话,用法也大致一样。不过还要搭配 cv2 使用,主要是为了利用cv2.imread()来读取图片文件。
注意:对于cv2模块,安装时需要输入
pip3 install opencv-python,但在导入的时候采用import cv2。
识别条形码的具体语句如下所示:
import pyzbar.pyzbar as pyzbar
import cv2
def get_barcode(img):
image = cv2.imread(img)
barcodes = pyzbar.decode(image)
barcode = barcodes[0]
barcode_data = barcode.data.decode("utf-8")
return barcode_data
上面构建的get_barcode()函数可以实现识别条形码,并返回结果数据。
我们可以用for循环遍历前文获取的所有图片,再依次使用get_barcode()函数来识别条形码。
data_m =[]
for i in jpgs:
data = get_barcode(i)
data_m.append(data)
data_m
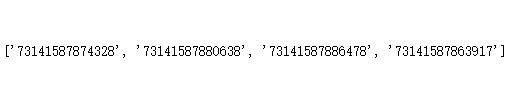
可以发现,成功识别了四张截图里的条形码,并获取了对应的快递单号。

回顾今天的问题案例,我先通过思考想出了两种解决办法。第一种的优点是识别条形码比OCR更准确,但是其只获取了快递单号。后续在给获得赠书的同学反馈时,我还需要手动将名字和单号对应,不够偷懒。后续将给大家介绍第二种方法的流程和优缺点。
如果想看更多python改变生活的真实问题案例,给本文右下角点个赞吧👍
如果你也有一直想用python解决的问题,欢迎在评论区告诉我🚀
本文转自快学Python。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典


在人工智能领域中,有一项非常关键的技术,那就是图像分割。
图像分割是指将图像中具有特殊意义的不同区域划分开来, 这些区域互不相交,每个区域满足灰度、纹理、彩色等特征的某种相似性准则。
比如上图识别视盘。视盘是视网膜中的关键解剖学结构,其形状、面积和深度等参数是衡量眼底健康状况的重要指标,准确定位和分割视盘区域是眼底图像分析和处理的关键步骤。
在人工智能的辅助下,只需要数秒,即可初步判断被检者是否存在眼底疾病,这将有助缓解专业眼科医生不足的瓶颈,开启眼底疾病的基层筛查新模式。而图像分割就是实现这项功能的基础,可见其重要性。
下面就给大家讲讲如何基于 PaddlePaddle 平台,训练并测试一个视盘图像分割的基本模型。
为了实现这个实验,Python 是必不可少的,如果你还没有安装 Python,建议阅读我们的这篇文章:超详细Python安装指南。
在安装前,确认自己需要的 PaddlePaddle 版本,比如 GPU版 或 CPU版,GPU 在计算上具有绝对优势,但是如果你没有一块强力的显卡,建议选择CPU版本。
(GPU版) 如果你想使用GPU版,请确认本机安装了 CUDA 计算平台及 cuDNN,它们的下载地址分别是:
https://developer.nvidia.com/cuda-downloads
https://developer.nvidia.com/cudnn-download-survey
具体 CUDA 和 cuDNN 对应的版本要求如下:
CUDA安装流程很简单,下载exe程序,一路往下走。cuDNN安装流程复杂一些,你需要转移压缩包解压后的部分文件到CUDA中,具体可见这篇cuDNN的官方安装指引:
https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html
(CPU版)CPU版安装过程比较简单,直接按照下面 PaddlePaddle 的安装指引输入命令即可。
(通用)选择完你想要安装的版本,并做好基础工作后,接下来就是安装 PaddlePaddle 的具体步骤,打开安装指引流程页面:
https://www.paddlepaddle.org.cn/install/quick
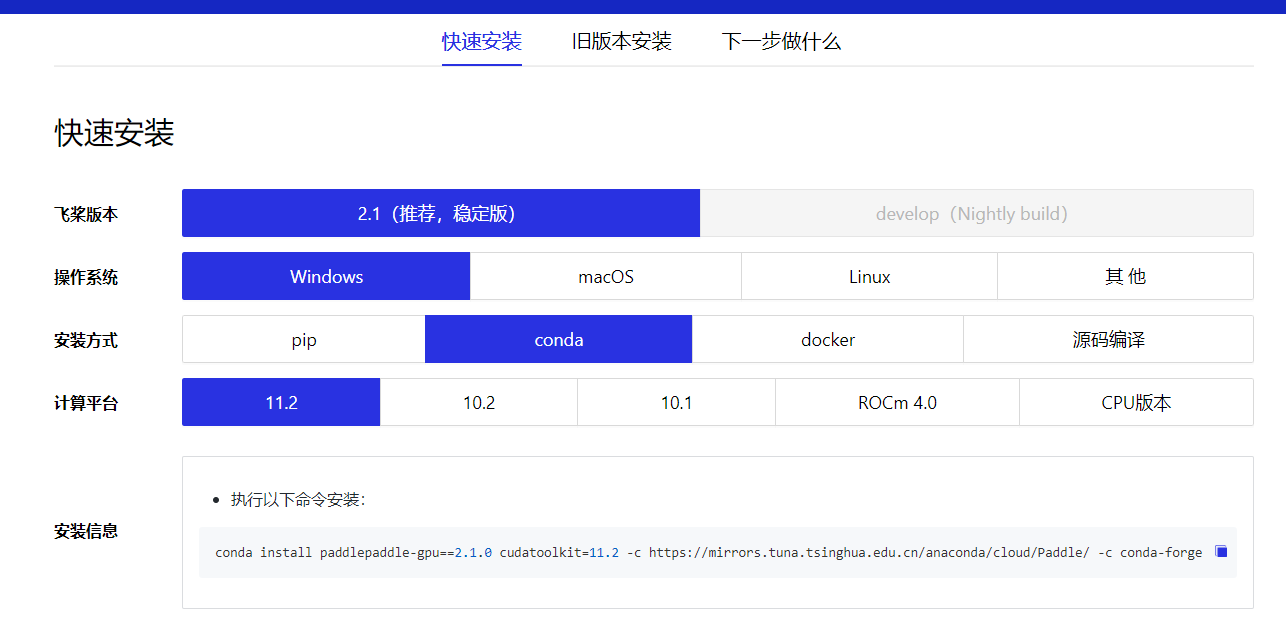
根据你自己的情况选择这些选项,最后一个选项计算平台指的是 GPU 加速工具包或CPU,如果你不想用GPU,请选CPU版;想用GPU版的同学请按刚刚下载的CUDA版本进行选择。
选择完毕后下方会出现安装信息,输入安装信息里的命令即可安装成功,不得不说,PaddlePaddle 这些方面做的还是比较贴心的。
在页面下方还有具体的从头到尾的安装步骤,对 Python 基本的虚拟环境安装流程不了解的同学可以看着这些步骤进行安装。
安装完 paddle 后,为了能够实现图像分割功能,我们还需要安装 paddleseg:
pip install paddleseg
并克隆 paddleseg的代码库(如果克隆不了,请在Python实用宝典公众号后台回复:图像分割 下载):
git clone https://github.com/PaddlePaddle/PaddleSeg.git
克隆完成,进入代码库文件夹:
cd PaddleSeg
执行下面命令,并在 PaddleSeg/output 文件夹中出现预测结果,则证明安装成功。
python predict.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path https://bj.bcebos.com/paddleseg/dygraph/optic_disc/bisenet_optic_disc_512x512_1k/model.pdparams\
--image_path docs/images/optic_test_image.jpg \
--save_dir output/result预测结果如下:
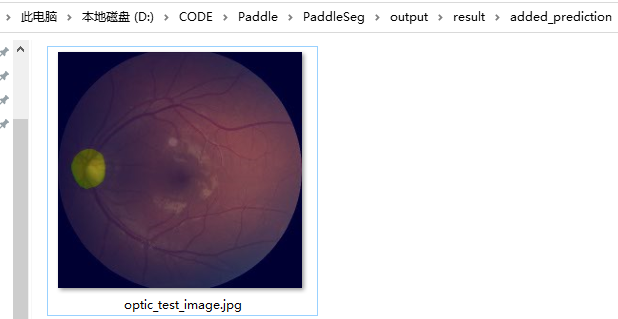
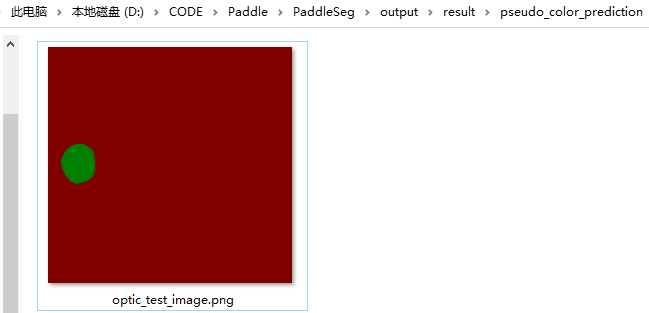
前面只是利用了 PaddlePaddle 提前训练好的数据进行预测,下面我们要尝试自己训练一个模型。
为了训练模型,我们需要获得眼底训练集。事实上,在前面 初尝 Paddleseg 中,我们便获得了一份眼底训练集,其路径是 PaddleSeg\data\optic_disc_seg.
如果你没有进行 初尝 Paddleseg 这一节,也想要获取训练集数据的话,在Python实用宝典公众号后台回复:图像分割 下载。下载后解压数据集,得到一个optic_disc_seg文件夹,将其放到 PaddleSeg 代码库的 data 文件夹下。
PaddleSeg 提供了配置化驱动进行模型训练。他们在配置文件中详细列出了每一个可以优化的选项,用户只要修改这个配置文件就可以对模型进行定制。
所有的配置文件在PaddleSeg/configs文件夹下面:
每一个文件夹代表一个模型,里面包含这个模型的所有配置文件。
在PaddleSeg的配置文件给出的学习率中,除了”bisenet_optic_disc_512x512_1k.yml”中为单卡学习率外,其余配置文件中均为4卡的学习率,因此如果你是单卡训练,则学习率设置应变成原来的1/4。
为了简化学习难度,我们继续以”bisenet_optic_disc_512x512_1k.yml”文件为例,修改部分参数进行训练,下面是这个配置的全部说明:
batch_size: 4 #设定batch_size的值即为迭代一次送入网络的图片数量,一般显卡显存越大,batch_size的值可以越大
iters: 1000 #模型迭代的次数
train_dataset: #训练数据设置
type: OpticDiscSeg #选择数据集格式
dataset_root: data/optic_disc_seg #选择数据集路径
num_classes: 2 #指定目标的类别个数(背景也算为一类)
transforms: #数据预处理/增强的方式
- type: Resize #送入网络之前需要进行resize
target_size: [512, 512] #将原图resize成512*512在送入网络
- type: RandomHorizontalFlip #采用水平反转的方式进行数据增强
- type: Normalize #图像进行归一化
mode: train
val_dataset: #验证数据设置
type: OpticDiscSeg #选择数据集格式
dataset_root: data/optic_disc_seg #选择数据集路径
num_classes: 2 #指定目标的类别个数(背景也算为一类)
transforms: #数据预处理/增强的方式
- type: Resize #将原图resize成512*512在送入网络
target_size: [512, 512] #将原图resize成512*512在送入网络
- type: Normalize #图像进行归一化
mode: val
optimizer: #设定优化器的类型
type: sgd #采用SGD(Stochastic Gradient Descent)随机梯度下降方法为优化器
momentum: 0.9 #动量
weight_decay: 4.0e-5 #权值衰减,使用的目的是防止过拟合
learning_rate: #设定学习率
value: 0.01 #初始学习率
decay:
type: poly #采用poly作为学习率衰减方式。
power: 0.9 #衰减率
end_lr: 0 #最终学习率
loss: #设定损失函数的类型
types:
- type: CrossEntropyLoss #损失函数类型
coef: [1, 1, 1, 1, 1]
#BiseNetV2有4个辅助loss,加上主loss共五个,1表示权重 all_loss = coef_1 * loss_1 + .... + coef_n * loss_n
model: #模型说明
type: BiSeNetV2 #设定模型类别
pretrained: Null #设定模型的预训练模型你可以尝试调整部分参数进行训练,看看你自己训练的模型效果和官方给出的模型的效果的差别。
(GPU版)在正式开启训练前,我们需要将CUDA设置为目前有1张可用的显卡:
set CUDA_VISIBLE_DEVICES=0 # windows # export CUDA_VISIBLE_DEVICES=0 # linux
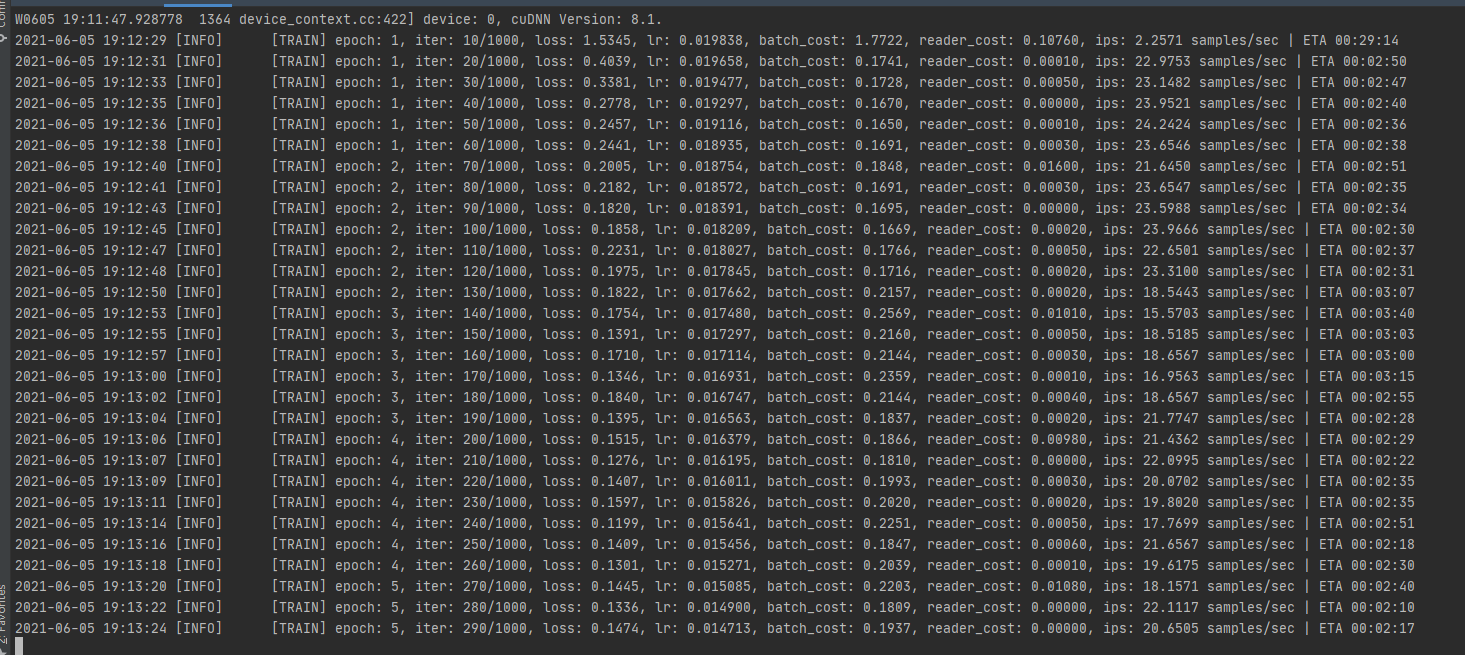
输入训练命令开始训练:
python train.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output| 参数名 | 用途 | 是否必选项 | 默认值 |
|---|---|---|---|
| iters | 训练迭代次数 | 否 | 配置文件中指定值 |
| batch_size | 单卡batch size | 否 | 配置文件中指定值 |
| learning_rate | 初始学习率 | 否 | 配置文件中指定值 |
| config | 配置文件 | 是 | – |
| save_dir | 模型和visualdl日志文件的保存根路径 | 否 | output |
| num_workers | 用于异步读取数据的进程数量, 大于等于1时开启子进程读取数据 | 否 | 0 |
| use_vdl | 是否开启visualdl记录训练数据 | 否 | 否 |
| save_interval_iters | 模型保存的间隔步数 | 否 | 1000 |
| do_eval | 是否在保存模型时启动评估, 启动时将会根据mIoU保存最佳模型至best_model | 否 | 否 |
| log_iters | 打印日志的间隔步数 | 否 | 10 |
| resume_model | 恢复训练模型路径,如:output/iter_1000 | 否 | None |
| keep_checkpoint_max | 最新模型保存个数 | 否 | 5 |
见到如下的界面,说明你已经开始训练了:
PaddlePaddle 还提供了可视化分析工具:VisualDL,让我们的网络训练过程更加直观。
当打开use_vdl开关后,PaddleSeg会将训练过程中的数据写入VisualDL文件,可实时查看训练过程中的日志。记录的数据包括:
使用如下命令启动VisualDL查看日志
# 下述命令会在127.0.0.1上启动一个服务,支持通过前端web页面查看,可以通过--host这个参数指定实际ip地址 visualdl --logdir output/
在浏览器输入提示的网址,效果如下:

如图所示,打开 http://127.0.0.1:8040/ 页面,效果如下:
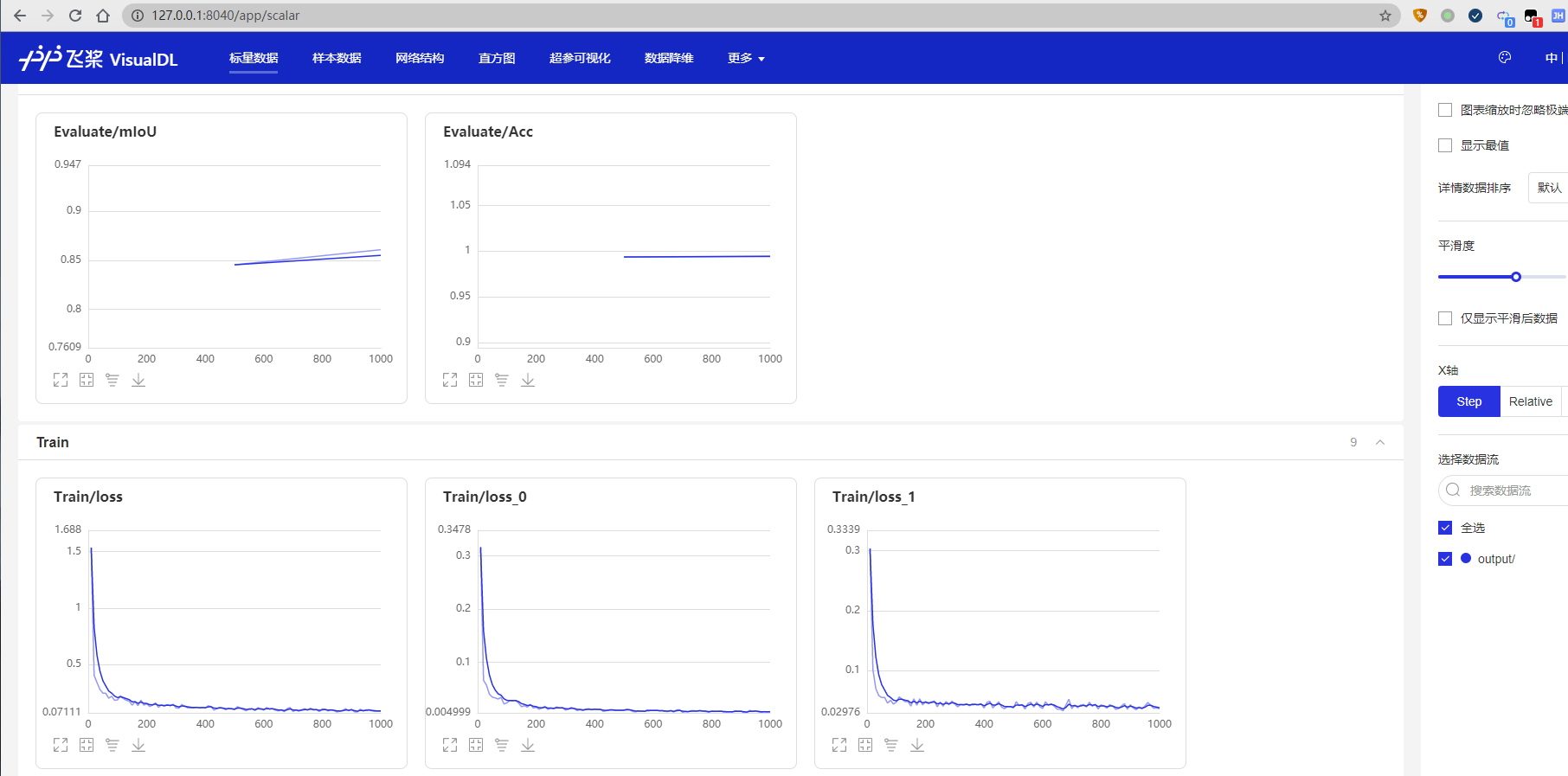
训练完成后,用户可以使用评估脚本val.py来评估模型效果。
假设训练过程中迭代次数(iters)为1000,保存模型的间隔为500,即每迭代1000次数据集保存2次训练模型。
因此一共会产生2个定期保存的模型,加上保存的最佳模型best_model,一共有3个模型,可以通过model_path指定期望评估的模型文件。
python val.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path output/iter_1000/model.pdparams在图像分割领域中,评估模型质量主要是通过三个指标进行判断,准确率(acc)、平均交并比(Mean Intersection over Union,简称mIoU)、Kappa系数。
随着评估脚本的运行,最终打印的评估日志如下。
76/76 [==============================] - 6s 84ms/step - batch_cost: 0.0835 - reader cost: 0.0029 2021-06-05 19:38:53 [INFO] [EVAL] #Images: 76 mIoU: 0.8609 Acc: 0.9945 Kappa: 0.8393 2021-06-05 19:38:53 [INFO] [EVAL] Class IoU: [0.9945 0.7273] 2021-06-05 19:38:53 [INFO] [EVAL] Class Acc: [0.9961 0.8975]
可以看到,我改了参数后的训练效果还是不错的。
除了分析模型的IOU、ACC和Kappa指标之外,我们还可以查阅一些具体样本的切割样本效果,从Bad Case启发进一步优化的思路。
predict.py脚本是专门用来可视化预测案例的,命令格式如下所示
python predict.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path output/iter_1000/model.pdparams \
--image_path data/optic_disc_seg/JPEGImages/H0003.jpg \
--save_dir output/result运行完成后,打开 output/result 文件夹。我们选择1张图片进行查看,效果如下。
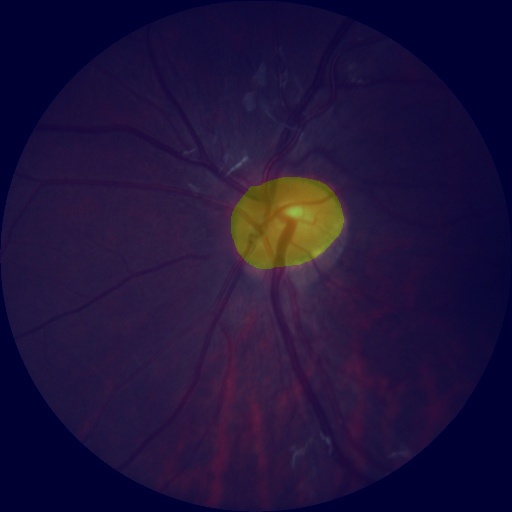
我们可以直观的看到模型的切割效果和原始标记之间的差别,从而产生一些优化的思路,比如是否切割的边界可以做规则化的处理等。
大家也可以尝试自己标注一个数据集进行图像分割,你只要按照 PaddleSeg\data\optic_disc_seg 里面那样组织图片结构,就可以复用这些训练、评估的过程。
本文部分内容摘自: PaddleSeg官方文档
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

JsonPath是一种简单的方法来提取给定JSON文档的部分内容。 JsonPath有许多编程语言,如Javascript,Python和PHP,Java。JsonPath提供的json解析非常强大,它提供了类似正则表达式的语法,基本上可以满足所有你想要获得的json内容。
本文介绍了Json相关的基础知识,引入XML和Jsonpath的对比,说明Jsonpath出现的必要性,并在文末附上了 Jsonpath 实战教程。
JSON是一个标记符序列。这套标记符包括:构造字符、字符串、数字和三个字面值。
JSON包括六个构造字符,分别是:左方括号、右方括号、左大括号、右大括号、冒号与逗号。
JSON值可以是对象、数组、数字、字符串或者三个字面值(false、true、null),并且字面值必须是小写英文字母。
对象是由花括号括起来,逗号分割的成员构成,成员是字符串键和上面所说的JSON值构成,例如:
{"name":"jack","age":18,"address":{"country"}}
数组是由方括号括起来的一组数值构成,例如:
[1,2,32,3,6,5,5]
字符串与数字想必就不用我过多叙述吧。
下面我就举例一些合法的JSON格式的数据:
{"a":1,"b":[1.2.3]}
[1,2,"3",{"a":4}]
3.14
"json_data"
JSON是一种轻量级的数据交互格式,它使得人们很容易的进行阅读和编写。同时也方便机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
把JSON格式字符串解码转成Python对象,从JSON到Python类型转换表如下:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number(int) | int |
| number(real) | float |
| true | True |
| false | False |
| null | None |
import json
strList = "[1,2,3,3,4]"
print(json.loads(strList))
print(type(json.loads(strList)))
试着运行上面的代码,你会发现已经成功的将strList转换为列表对象。
import json
strDict = '{"city":"上海","name":"jack","age":18}'
print(json.loads(strDict))
print(type(json.loads(strDict)))
试着运行上面的代码,你会发现已经成功的将object转换为dict类型的数据。
其实这个方法也很好理解,就是将Python类型的对象转换为json字符串。从Python类型向JSON类型转换的对照表如下:
| python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| False | false |
| None | null |
import json
list_str = [1,2,3,6,5]
print(json.dumps(list_str))
print(type(json.dumps(list_str)))
试着运行上面的代码,你会发现成功的将列表类型转换成了字符串类型。
import json
tuple_str = (1,2,3,6,5)
print(json.dumps(tuple_str))
print(type(json.dumps(tuple_str)))
试着运行上面的代码,你会发现成功的将元组类型的数据转换成了字符串。
import json
dict_str = {"name": "小明", "age":18, "city": "中国深圳"}
print(json.dumps(dict_str))
print(type(json.dumps(dict_str)))
输出结果:
{"name": "\u5c0f\u660e", "age": 18, "city": "\u4e2d\u56fd\u6df1\u5733"}
<class 'str'>
看到上面的输出结果也许你会有点疑惑,其实不需要疑惑,这是ASCII编码方式造成的,因为**json.dumps()**做序列化操作时默认使用的就是ASCII编码,因此我们可以这样写:
import json
dict_str = {"name": "小明", "age":18, "city": "中国深圳"}
print(json.dumps(dict_str, ensure_ascii=False))
print(type(json.dumps(dict_str)))
输出结果:
{"name": "小明", "age": 18, "city": "中国深圳"}
<class 'str'>
因为ensure_ascii的默认值是True,因此我们可以添加参数ensure_ascii将它的默认值改成False,这样编码方式就会更改为utf-8了。
该方法的主要作用是将文件中JSON形式的字符串转换为Python类型。
具体代码示例如下:
import json
str_list = json.load(open('position.json', encoding='utf-8'))
print(str_dict)
print(type(str_dict))
运行上面的代码,你会发现成功的将字符串类型的JSON数据转换为了dict类型。
代码中的文件position.json我也会分享给大家。
将Python内置类型序列化为JSON对象后写入文件。具体代码示例如下所示:
import json
list_str = [{'city':'深圳'}, {'name': '小明'},{'age':18}]
dict_str = {'city':'深圳','name':'小明','age':18}
json.dump(list_str, open('listStr.json', 'w'), ensure_ascii=False)
json.dump(list_str, open('dictStr.json', 'w'), ensure_ascii=False)
XML的优点是提供了大量的工具来分析、转换和有选择地从XML文档中提取数据。Xpath是这些功能强大的工具之一。
对于JSON数据来说,也出现了jsonpath这样的工具来解决这些问题:
jsonpath表达式始终引用JSON结构的方式与Xpath表达式与XML文档使用的方式相同。
pip install jsonpath
下面表格是jsonpath语法与Xpath的完整概述和比较。
| Xpath | jsonpath | 概述 |
|---|---|---|
| / | $ | 根节点 |
| . | @ | 当前节点 |
| / | .or[] | 取子节点 |
| * | * | 匹配所有节点 |
| [] | [] | 迭代器标识(如数组下标,根据内容选值) |
| // | … | 不管在任何位置,选取符合条件的节点 |
| n/a | [,] | 支持迭代器中多选 |
| n/a | ?() | 支持过滤操作 |
| n/a | () | 支持表达式计算 |
下面我们就通过几个示例来学习jsonxpath的使用方法。
我们先来看下面这段json数据
{ "store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
假如我需要获取到作者的名称该怎么样写呢?
如果通过Python的字典方法来获取是非常麻烦的,所以在这里我们可以选择使用jsonpath.。
具体代码示例如下所示:
import jsonpath
author = jsonpath.jsonpath(data_json, '$.store.book[*].author')
print(author)
运行上面的代码你会发现,成功的获取到了所有的作者名称,并保存在列表中。
或者还可以这样写:
import jsonpath
author = jsonpath.jsonpath(data_json, '$..author')
print(author)
还是使用上面的json数据,假如我现在需要获取第三本书的价格。
third_book_price = jsonpath.jsonpath(data_json, '$.store.book[2].price')
print(third_book_price)
运行上面的代码,你会发现成功的获取到了第三本书的价格。
isbn_book = jsonpath.jsonpath(data_json, '$..book[?(@.isbn)]')
print(isbn_book)
print(type(isbn_book))
通过运行上面的代码,你会发现,成功的将含有isbn编号的书籍过滤出来了。
同样的道理,根据上面的例子,我们也可以将价格小于10元的书过滤出来。
book = jsonpath.jsonpath(data_json, '$..book[?(@.price<10)]')
print(book)
print(type(book))
通过运行上面的代码,你会发现这里已经成功的将价格小于10元的书提取出来了。
jsonpath其实是非常适合用来获取json格式的数据的一款工具,最重要的是这款工具轻量简单容使用。关于jsonpath的介绍到这里就结束了,下面我们就进入实战演练吧!
每年的6月份都是高校学生的毕业季,作为计算机专业的你来说,如果刚刚毕业就可以进入大厂,想必是一个非常不错的选择。因此,今天我带来的项目就是爬取腾讯招聘的网站,获取职位名称、职位类别、工作地点、工作国家、职位的更新时间、职位描述。
爬取内容一共有329页,在前329页的职位都是在这个月发布的,还是比较新,对大家来说更有参考的价值。
网页链接:https://careers.tencent.com/search.html
工欲善其事,必现利其器。首先我们要准备好几个库:pandas、requests、jsonpath
如果没有安装,请参考下面的安装过程:
pip install requests
pip install pandas
pip install jsonpath
对网页进行分析的时候,我发现想从网页上直接获取信息是是做不到的,该网页的响应信息如下所示:
<!DOCTYPE html><html><head><meta charset=utf-8><meta http-equiv=X-UA-Compatible content="IE=edge"><meta name=viewport content="initial-scale=1,maximum-scale=1,user-scalable=no"><meta name=keywords content=""><meta name=description content=""><meta name=apple-mobile-web-app-capable content=no><meta name=format-detection content="telephone=no"><title>搜索 | 腾讯招聘</title><link rel=stylesheet href=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/css/main.css><link rel=stylesheet href=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/css/jquery-ui.min.css></head><body><div id=app></div><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/careersmlr/HeadFoot_zh-cn.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/careersmlr/HostMsg_zh-cn.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/careersmlr/Search_zh-cn.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/config.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/jquery.min.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/jquery.ellipsis.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/report.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/qrcode.min.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/manifest.build.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor.build.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/p_zh-cn_search.build.js></script></body><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/common.js></script></html>
因此我判断,这个是动态Ajax加载的数据,因此就要去网页控制器上查找职位数据是否存在。
经过一番查找,果然发现是动态加载的数据,信息如下所示:
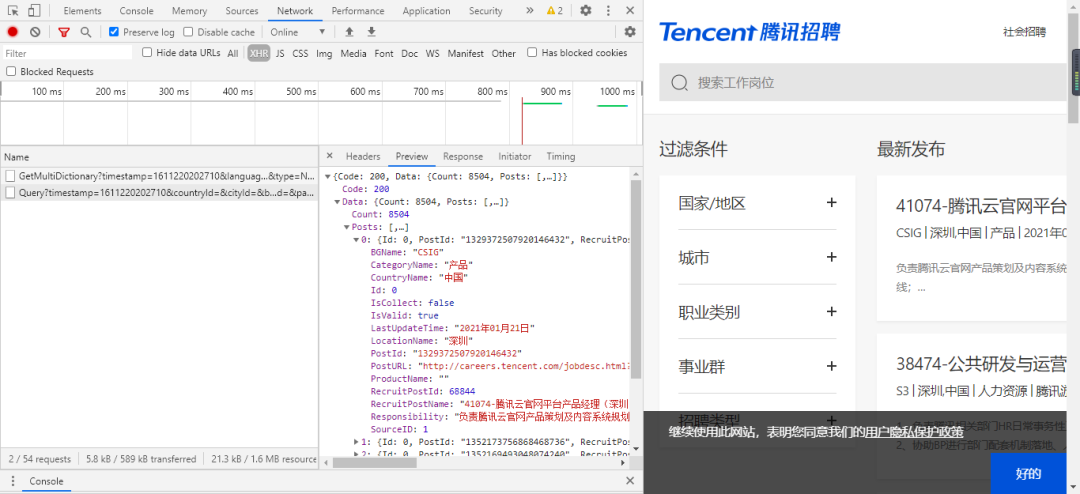
格式化之后的数据如下所示:
{
"Code":200,
"Data":{
"Count":8500,
"Posts":[
{
"Id":0,
"PostId":"1346716678288842752",
"RecruitPostId":71330,
"RecruitPostName":"41071-腾讯会议项目经理(西安)(CSIG全资子公司)",
"CountryName":"中国",
"LocationName":"西安",
"BGName":"CSIG",
"ProductName":"腾讯云",
"CategoryName":"产品",
"Responsibility":"1、负责研发项目及研发效能的计划制定、进度驱动和跟踪、风险识别以及应对,确保项目按计划完成;
2、负责组织项目各项评审会议及项目例会,制定并推广项目流程规范,确保项目有序进行;
3、负责与项目外部合作伙伴进行沟通,制定流程规范双方合作,并推动合作事宜;
4、及时发现并跟踪解决项目问题,有效管理项目风险。
",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1346716678288842752",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1346716729744564224",
"RecruitPostId":71331,
"RecruitPostName":"41071-腾讯会议产品策划(平台方向)(CSIG全资子公司)",
"CountryName":"中国",
"LocationName":"西安",
"BGName":"CSIG",
"ProductName":"腾讯云",
"CategoryName":"产品",
"Responsibility":"1、负责腾讯会议企业管理平台的产品策划工作,包括企业运营平台、运维、会控平台和工具的产品设计和迭代优化;
2、协调和推动研发团队完成产品开发、需求落地,并能在需求上线后进行持续数据分析和反馈跟进,不断提升产品竞争力;
3、根据行业场景抽象用户需求,沉淀面向不同类型客户的云端管控平台解决方案;
",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1346716729744564224",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1346062593894129664",
"RecruitPostId":71199,
"RecruitPostName":"41071-腾讯会议产品策划(CSIG全资子公司)",
"CountryName":"中国",
"LocationName":"西安",
"BGName":"CSIG",
"ProductName":"腾讯云",
"CategoryName":"产品",
"Responsibility":"负责腾讯会议的产品策划工作:
1、研究海外用户办公习惯及SaaS市场动态,调研海外相关SaaS产品并输出产品调研结论,综合市场情况和用户需求输出高质量的产品需求或解决方案;
2、负责腾讯会议各产品线的英文版的功能同步和产品设计工作,把关产品功能同步和国际版需求改造等;
3、协调和推动研发团队完成产品开发、需求落地,并能在需求上线后进行持续数据分析和反馈跟进,不断提升产品竞争力; ",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1346062593894129664",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1352161575309418496",
"RecruitPostId":72134,
"RecruitPostName":"CSIG16-推荐算法高级工程师",
"CountryName":"中国",
"LocationName":"北京",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"技术",
"Responsibility":"1. 参与地图场景下推荐算法优化,持续提升转化效果和用户体验;
2. 负责地图场景下推荐引擎架构设计和开发工作;
3. 跟进业界推荐领域最新进展,并推动其在地图场景下落地。",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=0",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1352158432852975616",
"RecruitPostId":72133,
"RecruitPostName":"41071-腾讯云SDK 终端研发工程师(CSIG全资子公司)",
"CountryName":"中国",
"LocationName":"西安",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"技术",
"Responsibility":"1. 负责腾讯云 GME SDK(游戏多媒体引擎)的开发和优化工作,并配套开发相应的场景解决方案业务流程,以满足不同场景和不同行业的客户需求;
2. 全流程参与客户需求咨询、需求评估、方案设计、方案编码实施及交付工作;
3. 负责优化腾讯云GME产品易用性,并跟踪客户的接入成本、完善服务体系,解决客户使用产品服务和解决方案过程中的技术问题,不断完善问题处理机制和流程。",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=0",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1352155053116366848",
"RecruitPostId":72131,
"RecruitPostName":"40931-智慧交通数据平台前端开发工程师(北京)",
"CountryName":"中国",
"LocationName":"北京",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"技术",
"Responsibility":"负责腾讯智慧交通领域的平台前端开发工作;
负责规划与制定前端整体发展计划与基础建设;
负责完成前端基础架构设计与组件抽象。",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=0",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1306860769169645568",
"RecruitPostId":66367,
"RecruitPostName":"35566-HRBP(腾讯全资子公司)",
"CountryName":"中国",
"LocationName":"武汉",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"人力资源",
"Responsibility":"负责区域研发公司的HR政策、制度、体系与重点项目在部门内部的落地与推动执行;
深入了解所负责领域业务与人员发展状况,评估并明确组织与人才发展对HR的需求;
驱动平台资源提供HR解决方案,并整合内部资源推动执行;提升管理干部的人力资源管理能力,关注关键人才融入与培养,确保持续的沟通与反馈;
协助管理层进行人才管理、团队发展、组织氛围建设等,确保公司文化在所属业务领域的落地;
负责所对接部门的人才招聘工作;
",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1306860769169645568",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1351353005709991936",
"RecruitPostId":71981,
"RecruitPostName":"35566-招聘经理(腾讯云全资子公司)",
"CountryName":"中国",
"LocationName":"武汉",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"人力资源",
"Responsibility":"1、负责CSIG区域研发公司相关部门的社会招聘及校园招聘工作,制定有效的招聘策略并推动落地执行,保障人才开源、甄选和吸引;
2、负责相关部门人力资源市场分析,有效管理并优化招聘渠道;
3、参与招聘体系化建设,甄选相关优化项目,有效管理及优化招聘渠道。",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1351353005709991936",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1351838518279675904",
"RecruitPostId":72081,
"RecruitPostName":"35566-雇主品牌经理(腾讯云全资子公司)",
"CountryName":"中国",
"LocationName":"武汉",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"人力资源",
"Responsibility":"1、负责腾讯云区域研发公司雇主品牌的规划和建设工作,结合业务招聘需求,制定有效的品牌方案;
2、负责讯云区域研发公司的公众号、媒体账号的内容策划、撰写,协调相关资源完成高质量内容输出;
3、负责招聘创意项目的策划和项目统筹,借助各种平台渠道,完成创意内容的传播触达,提升人选对腾讯云区域研发公司的认知和意向度;",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1351838518279675904",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1199244591342030848",
"RecruitPostId":55432,
"RecruitPostName":"22989-数据库解决方案架构师(北京/上海/深圳)",
"CountryName":"中国",
"LocationName":"上海",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"产品",
"Responsibility":"支持客户的应用架构设计,了解客户的业务逻辑和应用架构,给出合理的产品方案建议;
支持客户的数据库方案设计,从运维、成本、流程等角度主导云数据库产品落地;
梳理客户的核心诉求,提炼为普适性的产品能力,推动研发团队提升产品体验;
根据客户的行业属性,定制行业场景的解决方案,提升云数据库的影响力;",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1199244591342030848",
"SourceID":1,
"IsCollect":false,
"IsValid":true
}
]
}
}
经过对比发现上面的json数据与网页信息是完全相同的。
看到json数据你有没有一丝的惊喜,终于到了可以大显身手的时候了。
你会发现,上面每一个节点的参数都是独立的,不会存在重复,那我们可以这样写:
def get_info(data):
recruit_post_name = jsonpath.jsonpath(data, '$..RecruitPostName')
category_name = jsonpath.jsonpath(data, '$..CategoryName')
country_name= jsonpath.jsonpath(data, '$..CountryName')
location_name = jsonpath.jsonpath(data, '$.Data.Posts..LocationName')
responsibility = jsonpath.jsonpath(data, '$..Responsibility')
responsibility = [i.replace('\n', '').replace('\r', '') for i in responsibility]
last_update_time = jsonpath.jsonpath(data, '$..LastUpdateTime')
运行上面的代码,你会发现成功的获取到了每一组数据。
打开网页之后你会发现腾讯的职位信息一共有850页,但是前面的json数据仅仅只有第一页的数据怎么办呢?
不用担心,直接点击第二页看看网络数据有什么变化。
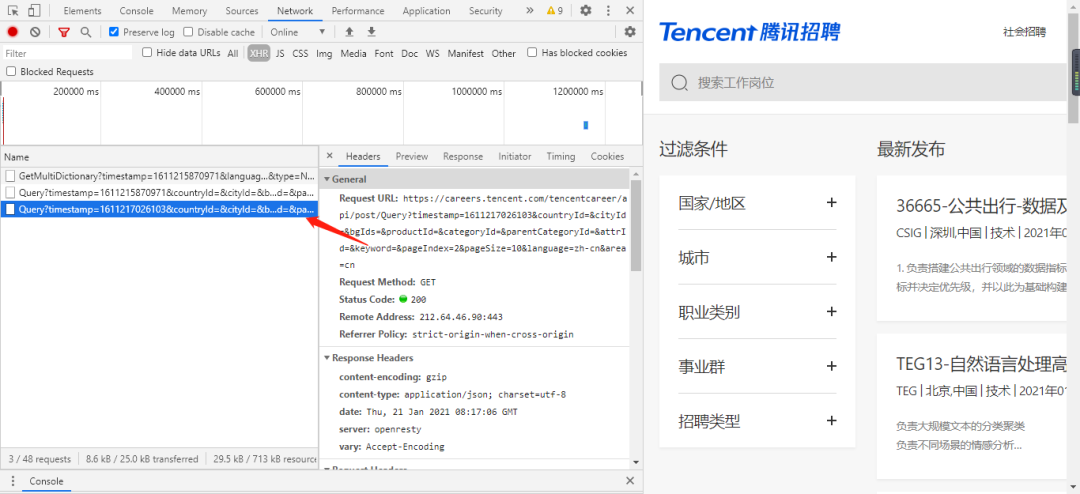
如上图所示,当点击第二页的时候,又加载出来了一个数据,点击进去之后你就会发现,这个数据刚好就是第二页的职位信息。
那接下来就是发现规律的时候了,第一页与第二页保存JSON数据的URL如下所示:
# 第一页
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1611215870971&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn
# 第二页
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1611217026103&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=2&pageSize=10&language=zh-cn&area=cn
经过测试发现,可以将URL地址进行简化,简化后的URL如下所示:
# 第一页
https://careers.tencent.com/tencentcareer/api/post/Query?pageIndex=1&pageSize=10
# 第二页
https://careers.tencent.com/tencentcareer/api/post/Query?pageIndex=1&pageSize=10
将爬取下来的数据保存至csv文件,核心代码如下所示:
df = pd.DataFrame({
'country_name': country_name,
'location_name': location_name,
'recruit_post_name':recruit_post_name,
'category_name': category_name,
'responsibility':responsibility,
'last_update_time':last_update_time
})
if __name__ == '__main__':
tengxun = TengXun()
df = pd.DataFrame(columns=['country_name', 'location_name', 'category_name','recruit_post_name', 'responsibility', 'last_update_time'])
for page in range(1, 330):
print(f'正在获取第{page}页')
url = tengxun.get_url(page)
data = tengxun.get_json(url)
time.sleep(0.03)
df1 = get_info(data)
df = pd.concat([df, df1])
df = df.reset_index(drop=True)
# pprint.pprint(data)
df.to_csv('../data/腾讯招聘.csv', encoding='utf-8-sig')

我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典

众所周知,Django对于网站快速开发非常友好,这得益于框架为我们做了很多事情,让我们只需要做一些简单的配置和逻辑即可把网站的功能开发出来。
但是,在使用Django的过程中,有一个地方一直是比较难受的,那就是使用Django自带的模版,这种通常需要自己利用HTML+CSS+Jquery的方式总感觉是上一个时代的做法,前后端分离无论对于开发效率、多端支持等等都是很有好处的。
所以,本文希望通过一个简单的demo,讲一讲基于Django+Vue的前后端分离开发,将Django作为一个纯后端的服务,为前端Vue页面提供数据支持。
本文采用的django版本号2.2.5,Vue版本2.9.6。
如果看不完可以先收藏关注哈~
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,可以访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器,它有许多的优点:Python 编程的最好搭档—VSCode 详细指南。
请选择以下任一种方式输入命令安装依赖:
1. Windows 环境 打开 Cmd (开始-运行-CMD)。
2. MacOS 环境 打开 Terminal (command+空格输入Terminal)。
3. 如果你用的是 VSCode编辑器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install djangovue的安装可见:
https://www.runoob.com/vue2/vue-install.html
创建前后端项目:创建一个文件夹,然后命令行创建项目即可,如下图:
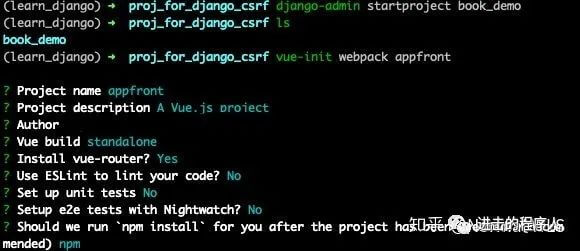
命令行进入后端文件夹 book_demo,输入下面命令,浏览器登陆 127.0.0.1:8000 看见欢迎页即成功。
python manage.py runserver再进入前端文件夹 appfront ,输入下面命令,浏览器登陆 127.0.0.1:8080 看见欢迎页即成功。
npm run dev上面两个命令也是对应前后端项目的启动命令,后面就直接将过程说成启动前/后端项目。
为了方便后端的实现,作为django做后端api服务的一种常用插件,django-rest-framework(DRF)提供了许多好用的特性,所以本文demo中也应用一下,命令行输入命令安装:
pip install django-rest-framework进入book_demo目录,创建一个新的名为books的应用,并在新应用中添加urls.py文件,方便后面的路由配置,命令行输入:
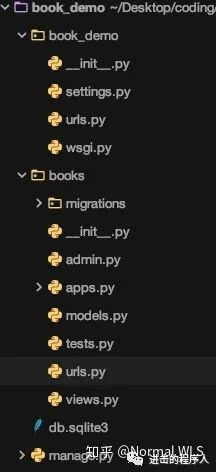
python manage.py startapp books cd books touch urls.py
现在的目录结构如下:
下面开始做一些简单的配置:
将DRF和books配置到django项目中,打开项目中的 settings.py 文件,添加:
# book_demo/settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
# demo add
'rest_framework',
'books',
]对整个项目的路由进行配置,让访问 api/ 路径时候转到books应用中的urls.py文件配置进行处理。
# book_demo/settings.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('api/', include('books.urls')), # demo add
]下面在books应用中写简单的逻辑,demo只最简单涉及对书本的增删改查。因为这一部分不是本文重点,所以这里只介绍写代码流程和贴代码,对代码不做详细解释:
在models.py文件中写简单数据类Books:
# books/models.py
from django.db import models
class Books(models.Model):
name = models.CharField(max_length=30)
author = models.CharField(max_length=30, blank=True, null=True)在books文件夹中创建serializer.py文件,并写对应序列化器BooksSerializer:
# books/serializer.py
from rest_framework import serializers
from books.models import Books
class BooksSerializer(serializers.ModelSerializer):
class Meta:
model = Books
fields = '__all__'在views.py文件中写对应的视图集BooksViewSet来处理请求:
# books/views.py
from rest_framework import viewsets
from books.models import Books
from books.serializer import BooksSerializer
class BooksViewSet(viewsets.ModelViewSet):
queryset = Books.objects.all()
serializer_class = BooksSerializer在urls.py文件中写对应的路由映射:
# books/urls.py
from django.urls import path, include
from rest_framework.routers import DefaultRouter
from books import views
router = DefaultRouter()
router.register('books', views.BooksViewSet)
urlpatterns = [
path('', include(router.urls)),
]对于books应用中的内容,如果对DRF和Django流程熟悉的同学肯定知道都干了些什么,篇幅关系这里只能简单解释,DRF通过视图集ViewSet的方式让我们对某一个数据类Model可以进行增删改查,而且不同的操作对应于不同的请求方式,比如查看所有books用get方法,添加一本book用post方法等,让整个后端服务是restful的。
如果实在看不懂代码含义,只需知道这样做之后就可以通过不同的网络请求对后端数据库的Books数据进行操作即可,后续可以结合Django和DRF官方文档对代码进行学习,或关注本人未来分享的内容。
到这里,可以运行一下后端项目看看效果,命令行运行:
python manage.py makemigrations python manage.py migrate python manage.py runserver
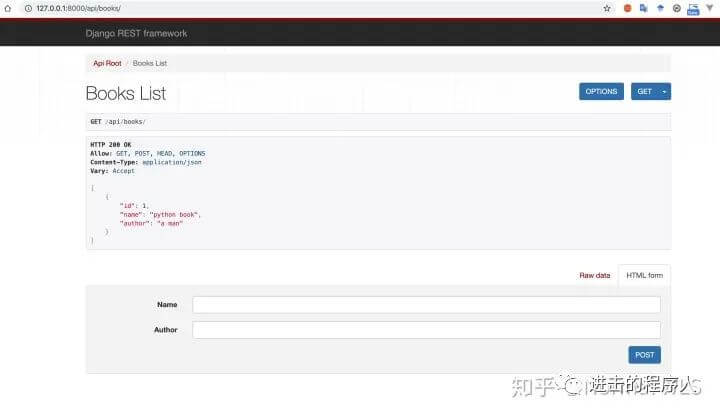
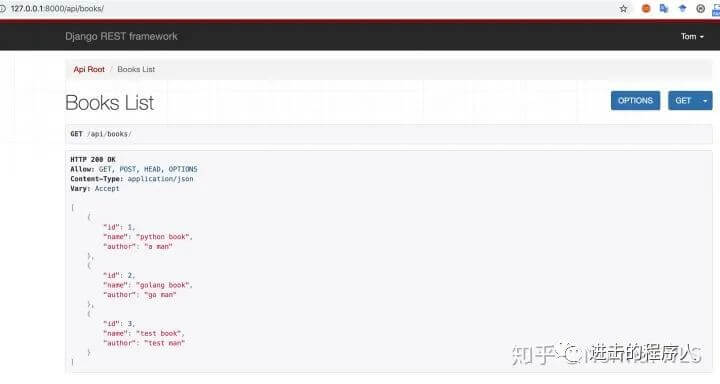
得益于DRF提供的api可视化界面,浏览器访问 127.0.0.1:8000/api/books/ ,如果出现了以下界面并添加数据正常,则说明后端的基本逻辑已经ok了~下图为添加了一条数据之后的效果。
接下来的工作以appfront项目目录为根目录进行,开始写一点前端的展示和表单,希望达到两个目标,一是能从后端请求到所有的books列表,二是能往后端添加一条book数据。说白了就是希望把上面的页面用Vue简单实现一下,然后能达到相同的功能。
对于Vue项目中各个文件的功能这里也不多解释,可以参考其文档系统学习。这里只需要知道欢迎页面中的样式是写在App.vue和components/HelloWorld.vue中即可。
这里直接用HelloWorld.vue进行修改,只求功能不追求页面了~
// appfront/src/components/HelloWorld.vue
<template>
<div class="hello">
<h1>{{ msg }}</h1>
<!-- show books list -->
<ul>
<li v-for="(book, index) in books" :key="index" style="display:block">
{{index}}-{{book.name}}-{{book.author}}
</li>
</ul>
<!-- form to add a book -->
<form action="">
输入书名:<input type="text" placeholder="book name" v-model="inputBook.name"><br>
输入作者:<input type="text" placeholder="book author" v-model="inputBook.author"><br>
</form>
<button type="submit" @click="bookSubmit()">submit</button>
</div>
</template>
<script>
export default {
name: 'HelloWorld',
data () {
return {
msg: 'Welcome to Your Vue.js App',
// books list data
books: [
{name: 'test', author: 't'},
{name: 'test2', author: 't2'}
],
// book data in the form
inputBook: {
"name": "",
"author": "",
}
}
},
methods: {
loadBooks () {...}, // load books list when visit the page
bookSubmit () {...} // add a book to backend when click the button
},
created: function () {
this.loadBooks()
}
}
</script>
...
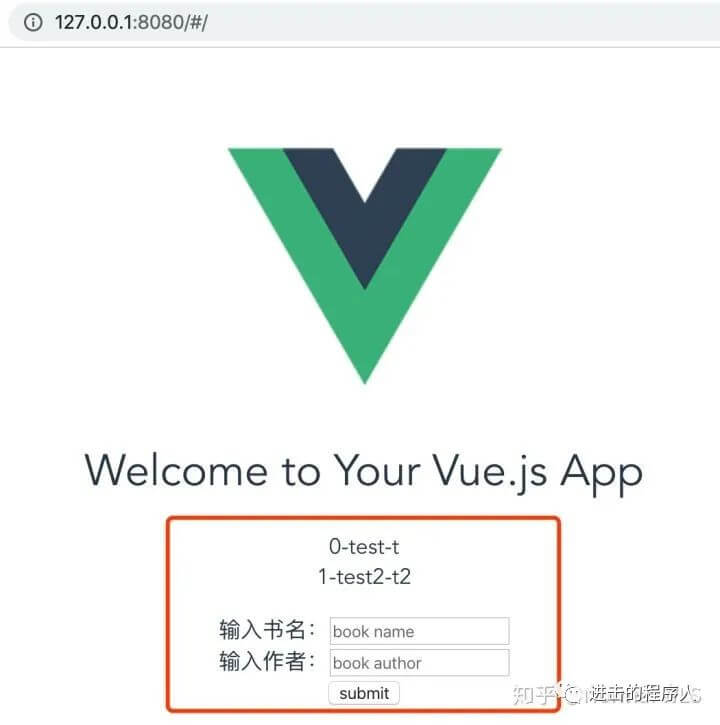
启动前端项目,浏览器访问127.0.0.1:8080,可以看到刚写的页面已经更新上去了,丑是丑了点,意思到了就行~如下图:
敲黑板,重点来了!!上面的页面中数据其实是写死在前端页面的模拟数据,这一节希望通过从后端拿数据并展示在前端页面的方式来完成前后端联调。前后端联调,涉及最多的就是跨域的问题,为了保证安全,通常需要遵循同源策略,即“协议、域名、端口”三者都相同,具体可以看看相关的博客,这里只需知道上述三者相同才算同源即可。
后端部分,对于django的跨域问题,网上比较常用的做法就是利用django-cors-headers模块来解决,这里也不能免俗,操作如下。
先在命令行中进行对应模块的安装:
pip install django-cors-headers然后在项目中添加该模块:
# books_demo/settings.py
INSTALLED_APPS = [
...
# demo
'corsheaders',
...
]
MIDDLEWARE = [
'corsheaders.middleware.CorsMiddleware', # 需注意与其他中间件顺序,这里放在最前面即可
...
]
# 支持跨域配置开始
CORS_ORIGIN_ALLOW_ALL = True
CORS_ALLOW_CREDENTIALS = True后端部分告于段落,接下来需要补充一下前端的逻辑,Vue框架现在一般都用axios模块进行网络请求,这里沿用这种方式,下面是在前端项目中操作:
首先命令行安装axios模块,如果没有安装cnpm就还是用npm安装:
cnpm install axios为了方便管理api请求的各种逻辑,在前端项目的src目录下创建api目录,然后创建api.js和index.js文件。index.js文件是对axios做配置:
// appfront/src/api/index.js
import Vue from 'vue'
import Axios from 'axios'
const axiosInstance = Axios.create({
withCredentials: true
})
// 通过拦截器处理csrf问题,这里的正则和匹配下标可能需要根据实际情况小改动
axiosInstance.interceptors.request.use((config) => {
config.headers['X-Requested-With'] = 'XMLHttpRequest'
const regex = /.*csrftoken=([^;.]*).*$/
config.headers['X-CSRFToken'] = document.cookie.match(regex) === null ? null : document.cookie.match(regex)[1]
return config
})
axiosInstance.interceptors.response.use(
response => {
return response
},
error => {
return Promise.reject(error)
}
)
Vue.prototype.axios = axiosInstance
export default axiosInstanceapi.js文件是对后端进行请求,可以看到,获取books列表和添加一本book各对应于一个请求:
// appfront/src/api/api.js
import axiosInstance from './index'
const axios = axiosInstance
export const getBooks = () => {return axios.get(`http://localhost:8000/api/books/`)}
export const postBook = (bookName, bookAuthor) => {return axios.post(`http://localhost:8000/api/books/`, {'name': bookName, 'author': bookAuthor})}然后更新HelloWorld.vue中的处理逻辑:
// appfront/src/components/HelloWorld.vue
<script>
import {getBooks, postBook} from '../api/api.js'
export default {
...
methods: {
loadBooks () {
getBooks().then(response => {
this.books = response.data
})
}, // load books list when visit the page
bookSubmit () {
postBook(this.inputBook.name, this.inputBook.author).then(response => {
console.log(response)
this.loadBooks()
})
} // add a book to backend when click the button
},
...
}
</script>至此,一个极其简陋的查询和添加书籍的功能算是完成了~如下图:
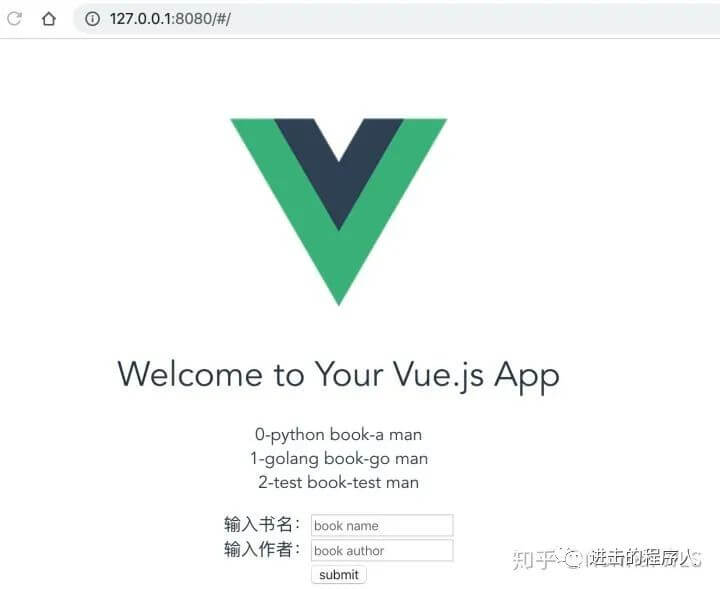
可以看到,列表里面的数据是从后端读取到的,同时前端的提交数据库也能有对应的操作,所以前后端至此是打通了。
现阶段是前后端分开开发,但是当最后要用的时候,还需要把代码合在一起。
首先对前端项目进行打包,这里用Vue的自动打包:
npm run build可以看到前端项目中多出了一个dist文件夹,这个就是前端文件的打包结果。需要把dist文件夹复制到books_demo项目文件夹中。
然后对settings.py文件进行相应的修改,其实就是帮django指定模版文件和静态文件的搜索地址:
# books_demo/books_demo/settings.py
...
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'dist')], # demo add
...
},
]
...
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'dist/static'),
]
..最后在根urls.py文件中配置一下入口html文件的对应路由:
# books_demo/books_demo/urls.py
...
from django.views.generic.base import TemplateView
urlpatterns = [
...
path('', TemplateView.as_view(template_name='index.html'))
]重新启动项目,这次用浏览器访问 127.0.0.1:8000 ,即django服务的对应端口即可。
可以看到,项目的交互是正常的,符合我们的预期。
本文以一个非常简单的demo为例,介绍了利用django+drf+vue的前后端分离开发模式,基本可以算是手把手入门。有了这个小demo之后,不管是前端页面还是后端功能,都可以做相应的扩展,从而开发出更加复杂使用的网站。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典


本文是一个较为完整的 mitmproxy教程,侧重于介绍如何开发拦截脚本,帮助读者能够快速得到一个自定义的代理工具。玩爬虫的小伙伴都知道,抓包工具除了MitmProxy 外,还有 Fiddler、Charles以及浏览器 netwrok 等
既然都有这么多抓包工具了,为什么还要会用 MitmProxy 呢??主要有以下几点:
本文假设读者有基本的 python 知识,且已经安装好了一个 python 3 开发环境。如果你对 nodejs 的熟悉程度大于对 python,可移步到 anyproxy,anyproxy 的功能与 mitmproxy 基本一致,但使用 js 编写定制脚本。除此之外我就不知道有什么其他类似的工具了,如果你知道,欢迎评论告诉我。
本文基于 mitmproxy v5,当前版本号为 v5.0.1。
顾名思义,mitmproxy 就是用于 MITM 的 proxy,MITM 即中间人攻击(Man-in-the-middle attack)。用于中间人攻击的代理首先会向正常的代理一样转发请求,保障服务端与客户端的通信,其次,会适时的查、记录其截获的数据,或篡改数据,引发服务端或客户端特定的行为。
不同于 fiddler 或 wireshark 等抓包工具,mitmproxy 不仅可以截获请求帮助开发者查看、分析,更可以通过自定义脚本进行二次开发。举例来说,利用 fiddler 可以过滤出浏览器对某个特定 url 的请求,并查看、分析其数据,但实现不了高度定制化的需求,类似于:“截获对浏览器对该 url 的请求,将返回内容置空,并将真实的返回内容存到某个数据库,出现异常时发出邮件通知”。而对于 mitmproxy,这样的需求可以通过载入自定义 python 脚本轻松实现。
但 mitmproxy 并不会真的对无辜的人发起中间人攻击,由于 mitmproxy 工作在 HTTP 层,而当前 HTTPS 的普及让客户端拥有了检测并规避中间人攻击的能力,所以要让 mitmproxy 能够正常工作,必须要让客户端(APP 或浏览器)主动信任 mitmproxy 的 SSL 证书,或忽略证书异常,这也就意味着 APP 或浏览器是属于开发者本人的——显而易见,这不是在做黑产,而是在做开发或测试。
事实上,以上说的仅是 mitmproxy 以正向代理模式工作的情况,通过调整配置,mitmproxy 还可以作为透明代理、反向代理、上游代理、SOCKS 代理等,但这些工作模式针对 mitmproxy 来说似乎不大常用,故本文仅讨论正向代理模式。
MitmProxy可以说是客户端,也可以说是一个 python 库
https://mitmproxy.org/downloads/在这个地址下可以下载对应的客户端安装即可
pip install mitmproxy通过这个 pip 命令可以下载好 MitmProxy,下面将会以 Python 库的使用方式给大家讲解如何使用(推荐方式二)
2.启动 MitmProxy
MitmProxy 启动有三个命令(三种模式)
mitmproxy,提供命令行界面
mitmdump,提供一个简单的终端输出(还可以配合Python抓包改包)
mitmweb,提供在线浏览器抓包界面
mitmdump -w d://lyc.txt
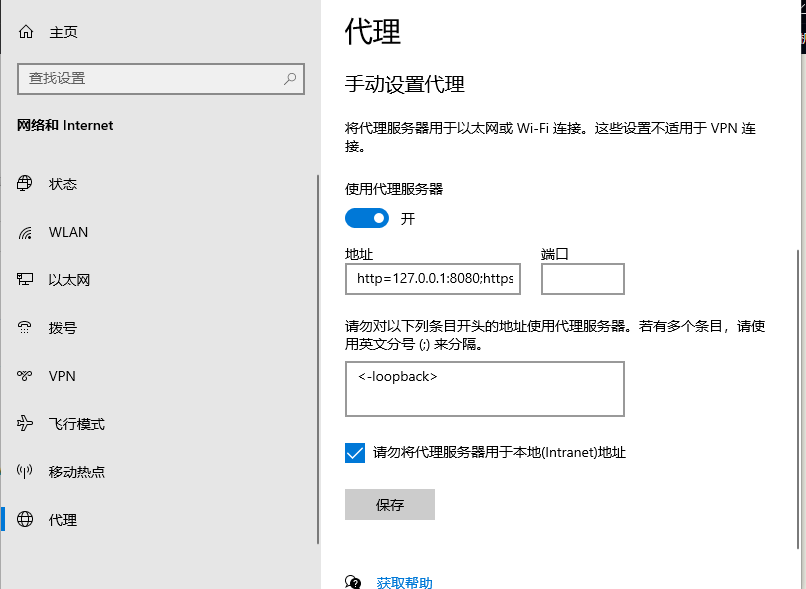
这样就启动mitmdump,接着在本地设置代理Ip是本机IP,端口8080
访问下面这个链接
http://mitm.it/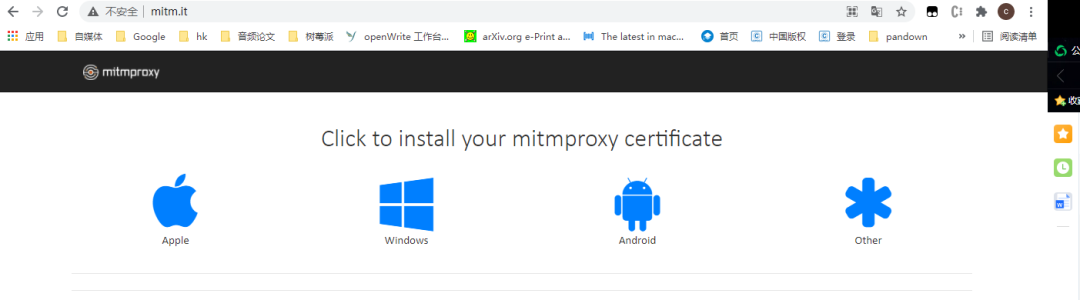
可以选择自己的设备(window,或者Android、Apple设备去)安装证书。
然后随便打开一个网页,比如百度
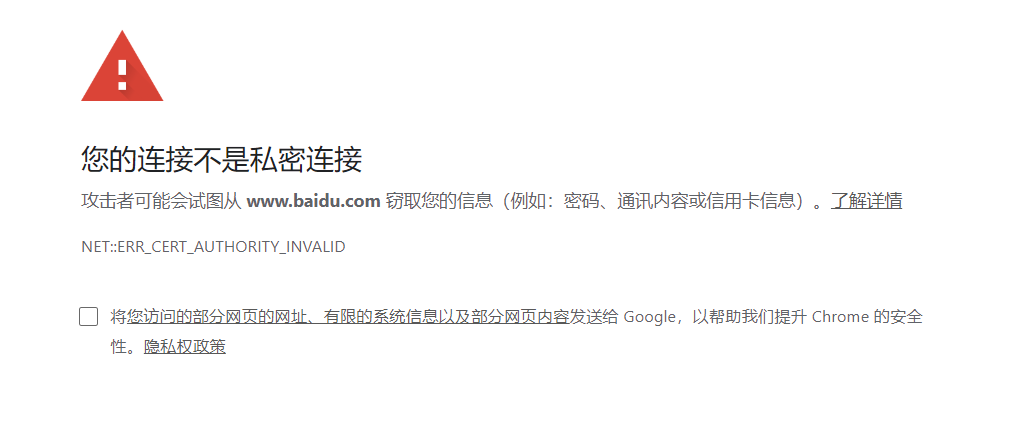
这里是因为证书问题,提示访问百度提示https证书不安全,那么下面开始解决这个问题,因此就引出了下面的这种启动方式
哪一个浏览器都可以,下面以Chrome浏览器为例(其他浏览器操作一样)
先找到chrome浏览器位置,我的chrome浏览器位置如下图
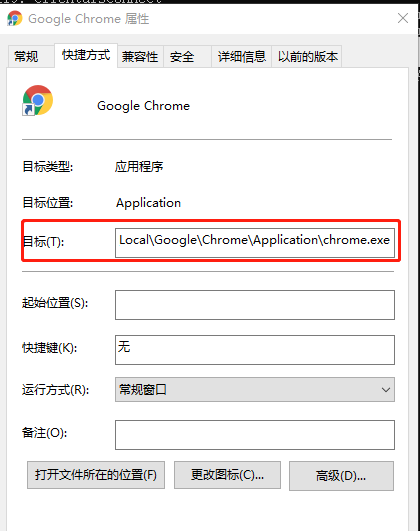
通过下面命令启动
"C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors—proxy-server是设置代理和端口
–ignore-certificate-errors是忽略证书
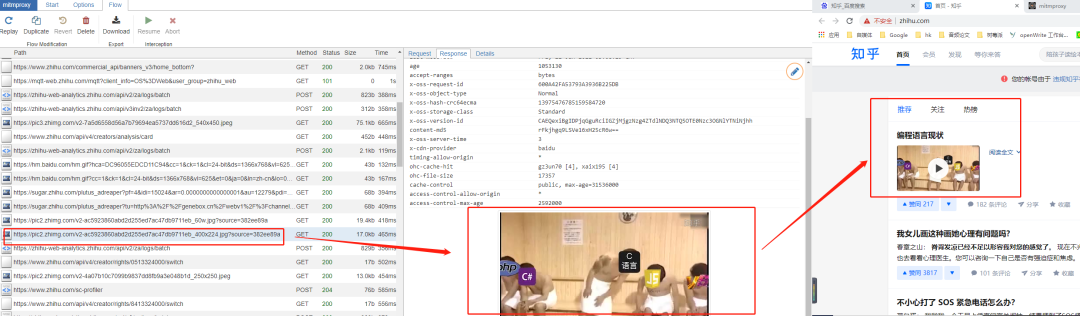
然后会弹出来Chrome浏览器,接着我们搜索知乎
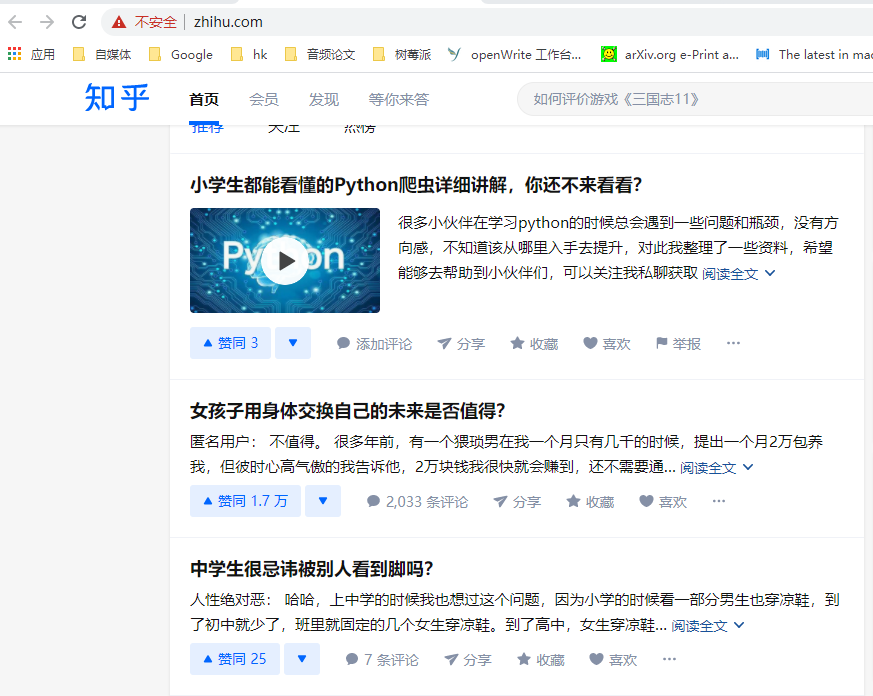
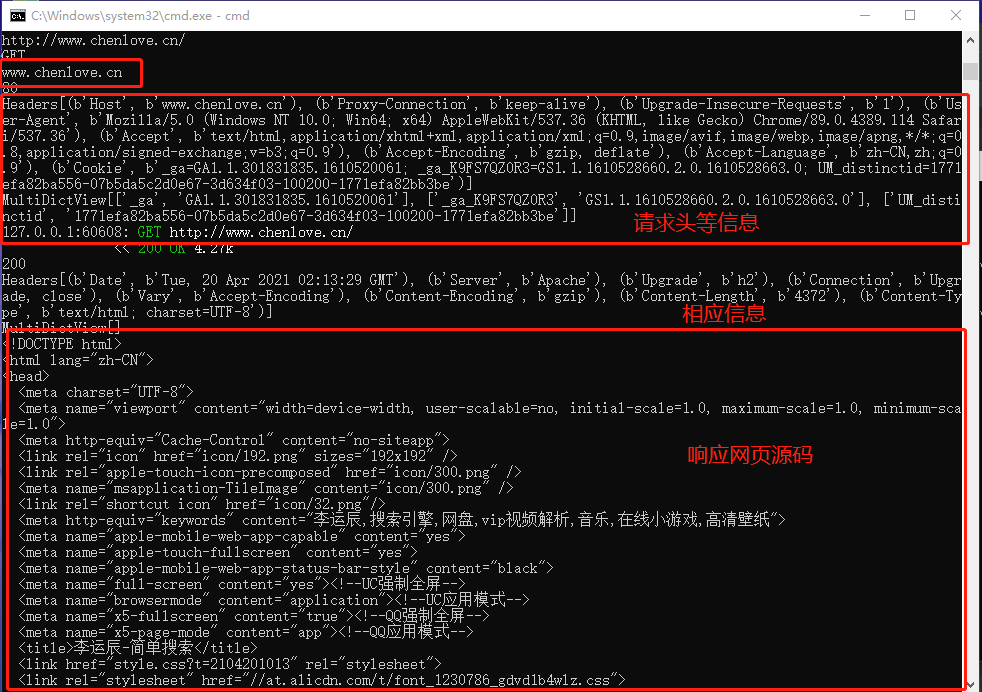
在cmd中就可以看到数据包
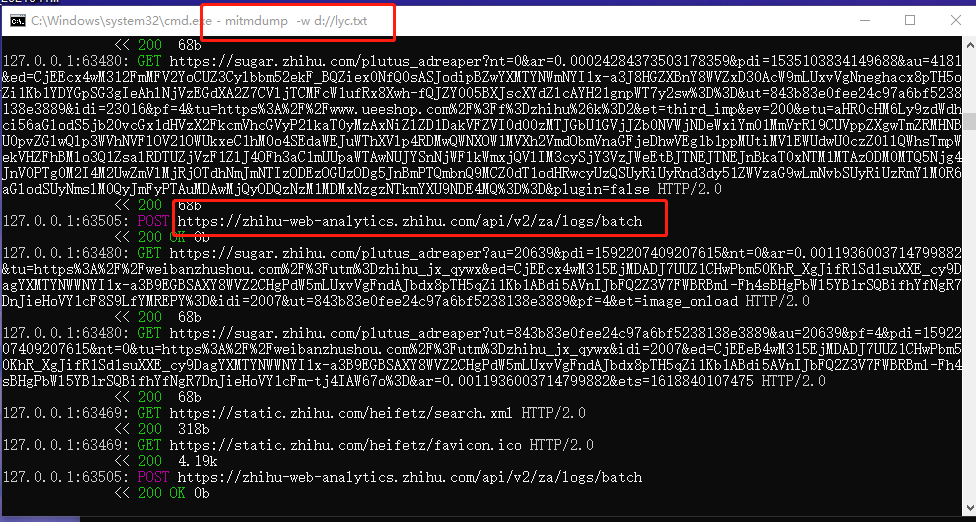
这些文本数据可以在编程中进行相应的操作,比如可以放到python中进行过来监听处理。
新开一个cmd(终端)窗口,输入下来命令启动mitmweb
mitmweb
之后会在浏览器自动打开一个网页(其实手动打开也可以,地址就是:http://127.0.0.1:8081)
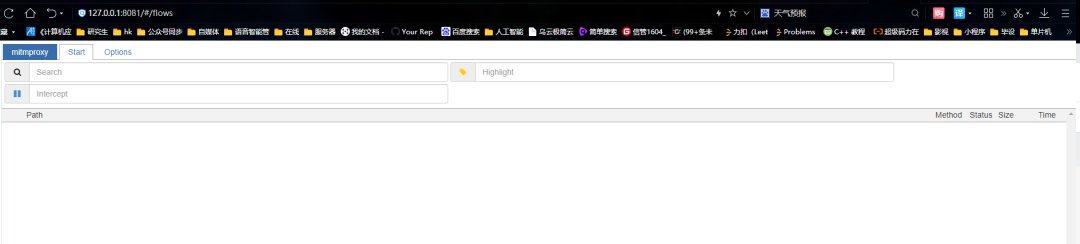
现在页面中什么也没有,那下面我们在刷新一个知乎页面
重点:关闭mitmproxy终端!关闭mitmproxy终端!关闭mitmproxy终端!
如果不改变在mitmweb中获取不到数据,数据只在mitmproxy中,因此需要关闭mitmproxy这个命令终端
刷新知乎页面之后如下:
在刚刚的网页版抓包页面就可以看到数据包了
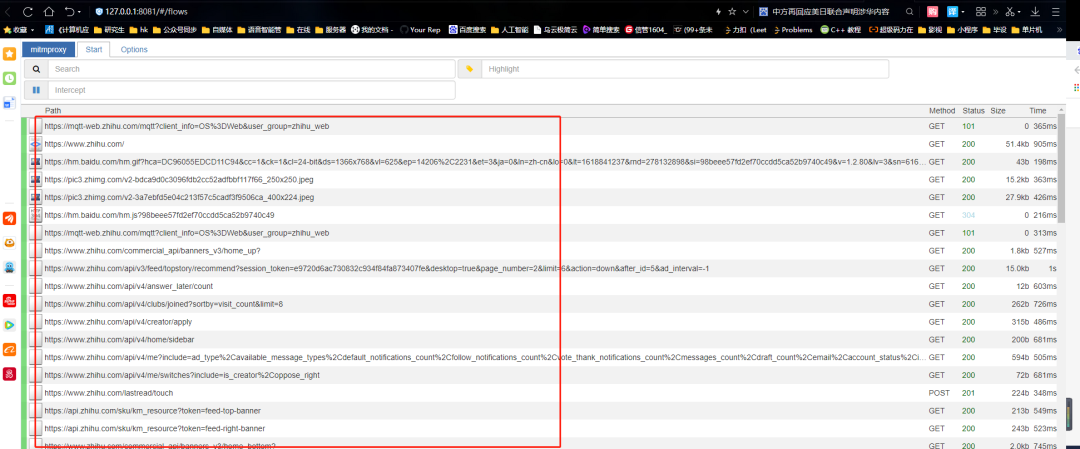
并且还包括https类型,比如查看其中一个数据包,找到数据是对应的,说明抓包成功。
mitmproxy代理(抓包)工具最强大之处在于对python脚步的支持(可以在python代码中直接处理数据包)
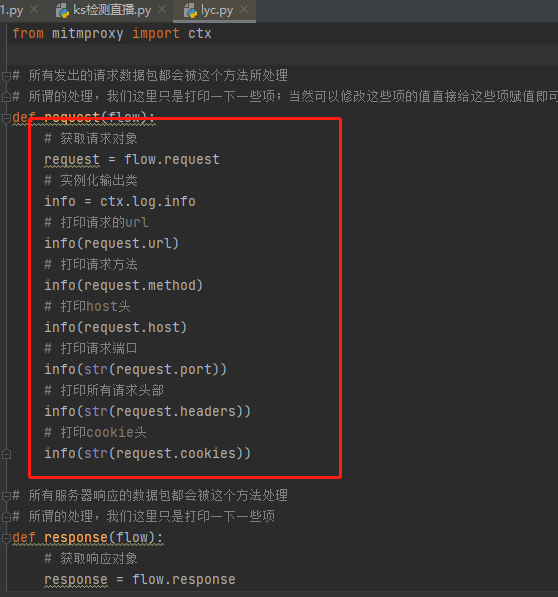
下面开始演示,先新建一个py文件(lyc.py)
from mitmproxy import ctx # 所有发出的请求数据包都会被这个方法所处理 # 所谓的处理,我们这里只是打印一下一些项;当然可以修改这些项的值直接给这些项赋值即可 def request(flow): # 获取请求对象 request = flow.request # 实例化输出类 info = ctx.log.info # 打印请求的url info(request.url) # 打印请求方法 info(request.method) # 打印host头 info(request.host) # 打印请求端口 info(str(request.port)) # 打印所有请求头部 info(str(request.headers)) # 打印cookie头 info(str(request.cookies)) # 所有服务器响应的数据包都会被这个方法处理 # 所谓的处理,我们这里只是打印一下一些项 def response(flow): # 获取响应对象 response = flow.response # 实例化输出类 info = ctx.log.info # 打印响应码 info(str(response.status_code)) # 打印所有头部 info(str(response.headers)) # 打印cookie头部 info(str(response.cookies)) # 打印响应报文内容 info(str(response.text))
在终端中输入一下命令启动
mitmdump.exe -s lyc.py

(PS:这里需要通过另一个端启动浏览器)
"C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors
然后访问某个网站
在终端中就可以看到信息
这些信息就是我们在 lyc.py 中指定的显示信息
PS:在手机上配置好代理之后,mitmproxy 同样可以抓取手机端数据
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
来源:文呓
本文内容包括Python性能可视化分析,逻辑优化,及根据不同的模型动态计算安全阈值,实现各个函数耗时及程序总耗时的自动化监控预警。
在做Python性能分析优化的时候,可以借助cProfile生成性能数据文件,通过pstats获取详细耗时分布数据,结合gprof2dot脚本生成函数调用栈结构图做可视化分析,提高性能分析的效率。
接着从具体的耗时分布,先从占用大头的函数分析具体逻辑实现,逐步优化,同时保存pstats函数耗时平均值数据作为后续异常自动化监控的样本数据。
实现耗时自动化监控必须是可以根据算法动态调整安全阈值,而不是人工定死安全阈值范围,这样才可以实现异常监控的自循环和迭代校准。
首先是性能数据文件的保存,cProfile和profile提供了Python程序的确定性性能分析。profile是一组统计数据,用来描述程序的各个部分执行的频率和时间。在程序开始的时候调用enable开始性能数据采集,结束的时候调用dump_stats停止性能数据采集并保存性能数据到指定路径的文件。
import cProfile # 程序开始的时候打开数据采集开关 pr = cProfile.Profile() pr.enable() # 在程序运行结束的时候dump性能数据到指定路径文件中,profliePath为保存文件的绝对路径参数 pr.dump_stats(profliePath)
保存性能数据到文件之后,可以用pstats读取文件中的数据,profile统计数据可以通过pstats模块格式化为报表。
import pstats
# 读取性能数据
pS = pstats.Stats(profliePath)
# 根据函数自身累计耗时做排序
pS.sort_stats('tottime')
# 打印所有耗时函数信息
pS.print_stats()
print_stats()输出示例:
79837 function calls (75565 primitive calls) in 37.311 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
2050 30.167 0.015 30.167 0.015 {time.sleep}
16 6.579 0.411 6.579 0.411 {select.select}
1 0.142 0.142 0.142 0.142 {method 'do_handshake' of '_ssl._SSLSocket' objects}
434 0.074 0.000 0.074 0.000 {method 'read' of '_ssl._SSLSocket' objects}
1 0.062 0.062 0.062 0.062 {method 'connect' of '_socket.socket' objects}
37 0.046 0.001 0.046 0.001 {posix.read}
14 0.024 0.002 0.024 0.002 {posix.fork}输出字段说明:
如果要获取print_stats()里面各个字段信息可以通过如下方式:
# func————filename:lineno(function)
# cc ———— call count,调用次数
# nc ———— ncalls
# tt ———— tottime
# ct ———— cumtime
# callers ———— 调用堆栈数组,每项数据包括了func, (cc, nc, tt, ct) 字段
for index in range(len(pS.fcn_list)):
func = pS.fcn_list[index]
cc, nc, tt, ct, callers = pS.stats[func]
print cc, nc, tt, ct, func, callers
for func, (cc, nc, tt, ct) in callers.iteritems():
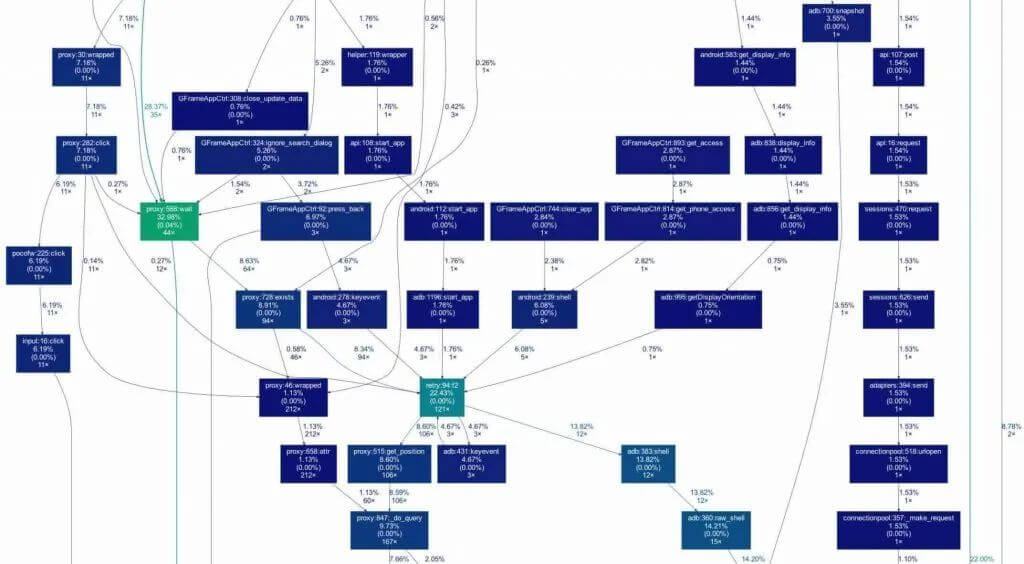
print func,cc, nc, tt, ctgprof2dot脚本把gprof或callgrind分析获得的信息,转化成一个以DOT语言描述的程序调用有向图对象,再通过Graphviz将DOT有向图对象渲染成图片,这样就可以很直观地看出整个程序的调用栈,包括函数所在的类和行数、耗时占比、函数递归次数、以及被调用的次数。
先从GitHub上下载gprof2dot.py脚本到本地,和执行的程序的脚本文件放在同一目录下,当然要使用这个脚本还需要安装graphviz,使用brew命令安装,若安装过程中遇到异常,根据异常提示执行命令安装需要的工具
brew install graphviz
生成程序函数调用栈结构图的逻辑可以参考如下逻辑实现,具体根据自身需求做下修改。
import os
# 获取当前gprof2dot.py脚本路径
gprof2dotPath = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'gprof2dot.py')
# 函数调用栈结构图保存文件名路径,这边使用生成PNG图片结果
dumpProfPath = profliePath.replace("stats", "png")
dumpCmd = "python %s -f pstats %s | dot -Tpng -o %s" % (gprof2dotPath, profliePath, dumpProfPath)
os.popen(dumpCmd)在生成函数调用栈结构图之后,就可以很容易的看出各个函数之间的调用关系,每个方块内包括的信息包括函数所在的类和行数,耗时百分比和被调用次数,如果这个函数存在递归的情况,方块边缘会有一个回旋的箭头标明递归的次数。
从结构图里面找到耗时占用较多的部分,分析具体函数的实现逻辑,定位具体耗时的原因,优化的策略如下:
如果是通过历史的耗时数据计算得到平均值+固定浮动百分比的方式,来配置耗时安全阈值参数实施异常监控存在很大的问题,因为函数执行的耗时容易受设备和运行环境的影响,人工固定浮动百分比的方式维护性差,数据本身不可迭代自循环,总不能每次出现误报问题之后都去手动调整参数。
这边监控的维度包括两方面,一方面是程序各个函数执行耗时的平均值,另一方面是完整程序执行的总耗时,在前期先把这些历史耗时数据保存在数据库中,供后续自动化异常监控的实现提供样本数据。
要实现自动化阈值调整,需要借助常规的模型算法实现,这边只对耗时单个维度的异常做自动化监控实现。
根据原理,无监督异常检测模型一般可分为以下几类:
异常耗时数据是波动的一维数据,这边就直接采用基于统计和概率模型的方式,根据保存的历史数据判断数据是否符合正态分布。
若符合正态分布则用 μ+3δ(平均值+3倍标准差)的方式计算得到安全阈值;
若不符合正态分布,则用Turkey 箱型图方案 Q+1.5IQR 计算安全阈值。
根据实际测试来看,随着样本数据的增加,会出现前期符合正态分布的函数耗时曲线,随着样本数据的增加会变成不符合正态分布。
Python中用于判断数据是否符合正态分布的代码如下,当pvalue值大于0.05时为正态分布,dataList是耗时数组数据:
from scipy import stats
import numpy
percallMean = numpy.mean(dataList) # 计算均值
# percallVar = numpy.var(dataList) # 求方差
percallStd = numpy.std(dataList) # 计算标准差
kstestResult = stats.kstest(dataList, 'norm', (percallMean, percallStd))
# 当pvalue值大于0.05为正态分布
if kstestResult[1] > 0.05:
pass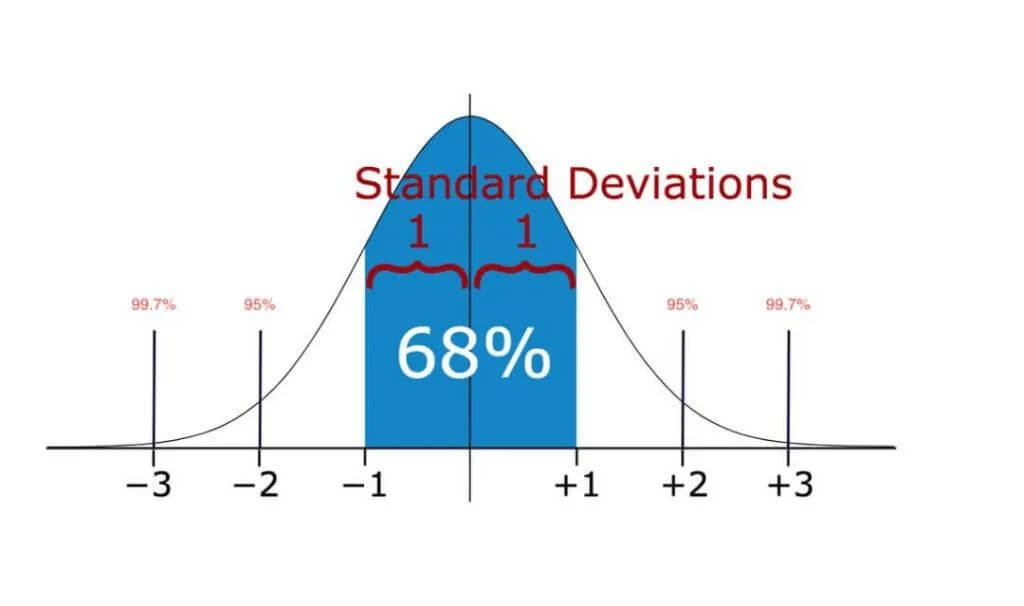
在统计学中,如果一个数据分布近似正态,那么大约 68% 的数据值会在均值的一个标准差范围内,大约 95% 会在两个标准差范围内,大约 99.7% 会在三个标准差范围内。因此,如果任何数据点超过标准差的 3 倍,那么这些点很有可能是异常值或离群点。即正态分布的安全阈值上限为:percallMean + 3 * percallStd
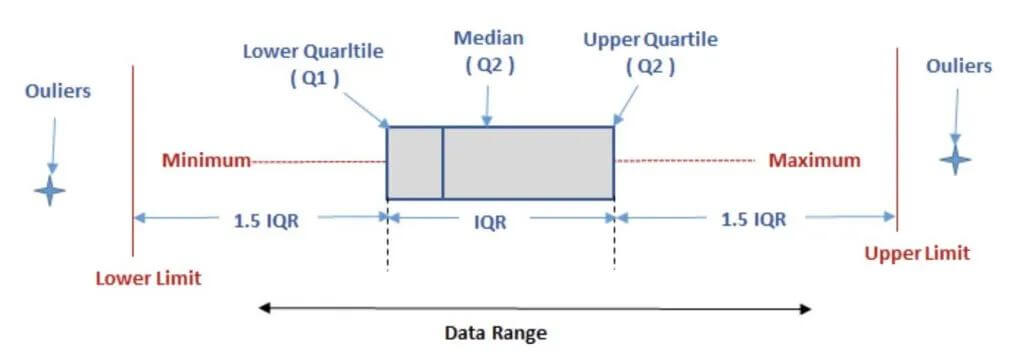
基于正态分布的 3σ 法则或 Z 分数方法的异常检测是以假定数据服从正态分布为前提的,但实际数据往往并不严格服从正态分布。应用这种方法于非正态分布数据中判断异常值,其有效性是有限的。Tukey 箱型图是一种用于反映原始数据分布的特征常用方法,也可用于异常点识别。在识别异常点时其主要依靠实际数据,因此有其自身的优越性。
箱型图为我们提供了识别异常值的一个标准:异常值被定义为小于 Q1-1.5IQR 或大于 Q+1.5IQR 的值。虽然这种标准有点任意性,但它来源于经验判断,经验表明它在处理需要特别注意的数据方面表现不错。
计算箱型图安全阈值Python实现逻辑如下:
import numpy percallMean = numpy.mean(dataList) # 计算均值 boxplotQ1 = numpy.percentile(dataList, 25) boxplotQ2 = numpy.percentile(dataList, 75) boxplotIQR = boxplotQ2 - boxplotQ1 upperLimit = boxplotQ2 + 1.5 * boxplotIQR
在程序实现中就是,在一个程序或用例执行完毕之后,先拿历史数据判断是否符合正态分布,当然历史样本数据至少要达到20个才比较准确,小于20个的时候就继续收集数据,不做异常判断。根据正态分布模型或箱型图模型计算安全阈值参数,判断当前各个函数耗时平均值或用例总耗时是否超过阈值,超过则预警。
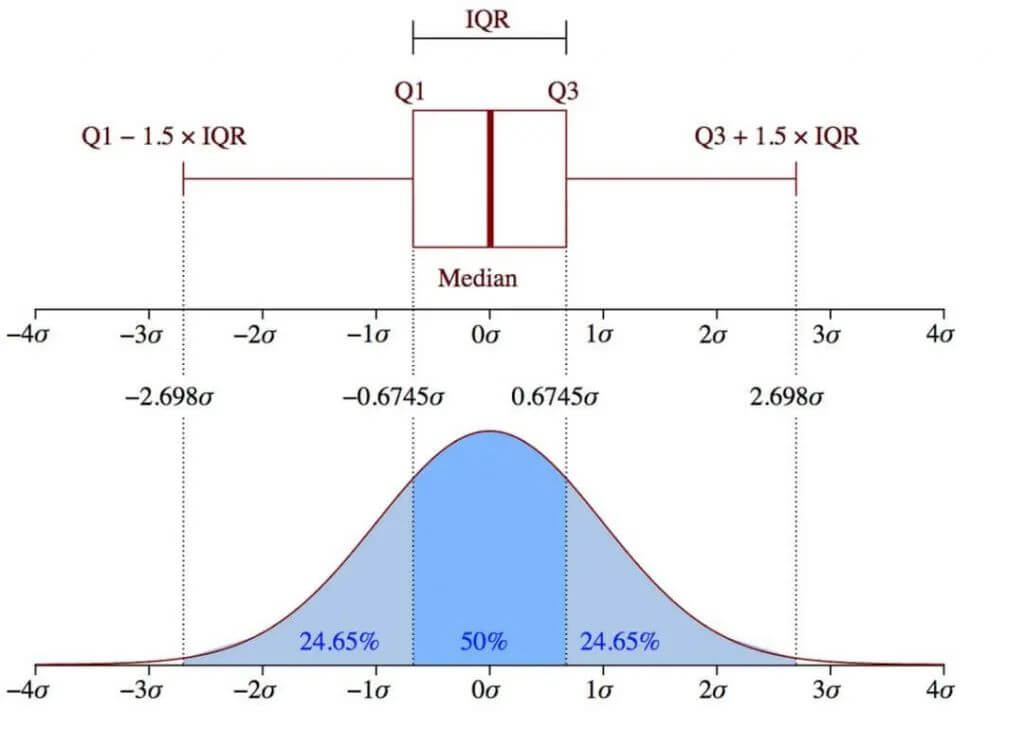
高斯模型和箱型图两种方式阈值范围对比
这边给出stats文件数据汇总解析之后,根据相应的模型绘制耗时曲线及阈值或正态曲线及阈值的代码实现,statFolder参数替换成自己stats文件所在文件夹即可。
# coding=utf-8
import os
import pstats
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import traceback
from scipy import stats
import numpy
"""
汇总函数耗时平均值数据
"""
def dataSummary(array, fileName, fcn, percall):
(funcPath, line, func) = fcn
exists = False
for item in array:
if item["func"] == func and item["funcPath"] == funcPath and item["line"] == line:
exists = True
item["cost"].append({
"percall": percall,
"fileName": fileName
})
if not exists:
array.append({
"func": func,
"funcPath": funcPath,
"line": line,
"cost": [{
"percall": percall,
"fileName": fileName
}]
})
"""
高斯函数计算Y值
"""
def gaussian(x, mu, delta):
exp = numpy.exp(- numpy.power(x - mu, 2) / (2 * numpy.power(delta, 2)))
c = 1 / (delta * numpy.sqrt(2 * numpy.pi))
return c * exp
"""
读取汇总所有stats文件数据
"""
def readStatsFile(statFolder, filterData):
for path, dir_list, file_list in os.walk(statFolder, "r"):
for fileName in file_list:
if fileName.find(".stats") > 0:
fileAbsolutePath = os.path.join(path, fileName)
pS = pstats.Stats(fileAbsolutePath)
# 先对耗时数据从大到小进行排序
pS.sort_stats('cumtime')
# pS.print_stats()
# 统计前100条耗时数据
for index in range(100):
fcn = pS.fcn_list[index]
(funcPath, line, func) = fcn
# cc ———— call count,调用次数
# nc ———— ncalls,调用次数(只有一个数字时表示不存在递归;有斜杠分割数字时,后面的数字表示非递归调用的次数)
# tt ———— tottime,函数总计运行时间,除去函数中调用的子函数运行时间
# ct ———— cumtime,函数总计运行时间,含调用的子函数运行时间
cc, nc, tt, ct, callers = pS.stats[fcn]
# print fileName, func, cc, nc, tt, ct, callers
percall = ct / nc
# 只统计单次函数调用大于1毫秒的数据
if percall >= 0.001:
dataSummary(filterData, fileName, fcn, percall)
"""
绘制高斯函数曲线和安全阈值
"""
def drawGaussian(func, line, percallMean, threshold, percallList, dumpFolder):
plt.title(func)
plt.figure(figsize=(10, 8))
for delta in [0.2, 0.5, 1]:
gaussY = []
gaussX = []
for item in percallList:
# 这边为了呈现正态曲线效果,减去平均值
gaussX.append(item - percallMean)
y = gaussian(item - percallMean, 0, delta)
gaussY.append(y)
plt.plot(gaussX, gaussY, label='sigma={}'.format(delta))
# 绘制水位线
plt.plot([threshold - percallMean, threshold - percallMean], [0, 5 * gaussian(percallMean, 0, 1)], color='red',
linestyle="-", label="Threshold:" + str("%.5f" % threshold))
plt.xlabel("Time(s)", fontsize=12)
plt.legend()
plt.tight_layout()
# 可能不同类中包含相同的函数名,加上行数参数避免覆盖
imagePath = dumpFolder + "cost_%s_%s.png" % (func, str(line))
plt.savefig(imagePath)
"""
绘制耗时曲线和安全阈值
"""
def drawCurve(func, line, percallList, dumpFolder):
boxplotQ1 = numpy.percentile(percallList, 25)
boxplotQ2 = numpy.percentile(percallList, 75)
boxplotIQR = boxplotQ2 - boxplotQ1
upperLimit = boxplotQ2 + 1.5 * boxplotIQR
# 不符合正态分布,绘制波动曲线
timeArray = [i for i in range(len(percallList))]
plt.title(dataItem["func"])
plt.figure(figsize=(10, 8))
# 绘制水位线
plt.plot([0, len(percallList)], [upperLimit, upperLimit], color='red', linestyle="-",
label="Threshold:" + str("%.5f" % upperLimit))
plt.plot(timeArray, percallList, label=dataItem["func"] + "_" + str(dataItem["line"]))
plt.ylabel("Time(s)", fontsize=12)
plt.legend()
plt.tight_layout()
imagePath = dumpFolder + "cost_%s_%s.png" % (func, str(line))
plt.savefig(imagePath)
if __name__ == "__main__":
try:
statFolder = "/Users/chenwenguan/Downloads/2aab7e17-a1b6-1253/"
chartFolder = statFolder + "chart/"
if not os.path.exists(chartFolder):
os.mkdir(chartFolder)
filterData = []
readStatsFile(statFolder, filterData);
for dataItem in filterData:
percallList = map(lambda x: x["percall"], dataItem["cost"])
func = dataItem["func"]
line = dataItem["line"]
# 样本个数大于20才进行绘制
if len(percallList) > 20:
percallMean = numpy.mean(percallList) # 计算均值
# percallVar = numpy.var(percallMap) # 求方差
percallStd = numpy.std(percallList) # 计算标准差
# pvalue值大于0.05为正太分布
kstestResult = stats.kstest(percallList, 'norm', (percallMean, percallStd))
print "percallStd:%s, pvalue:%s" % (percallStd, kstestResult[1])
# 符合正态分布绘制分布曲线
if kstestResult[1] > 0.05:
threshold = percallMean + 3 * percallStd
drawGaussian(func, line, percallMean, threshold, percallList, chartFolder)
else:
drawCurve(func, line, percallList, chartFolder)
else:
pass
except Exception:
print 'exeption:' + traceback.format_exc()两种耗时模型绘制的曲线效果图如下:
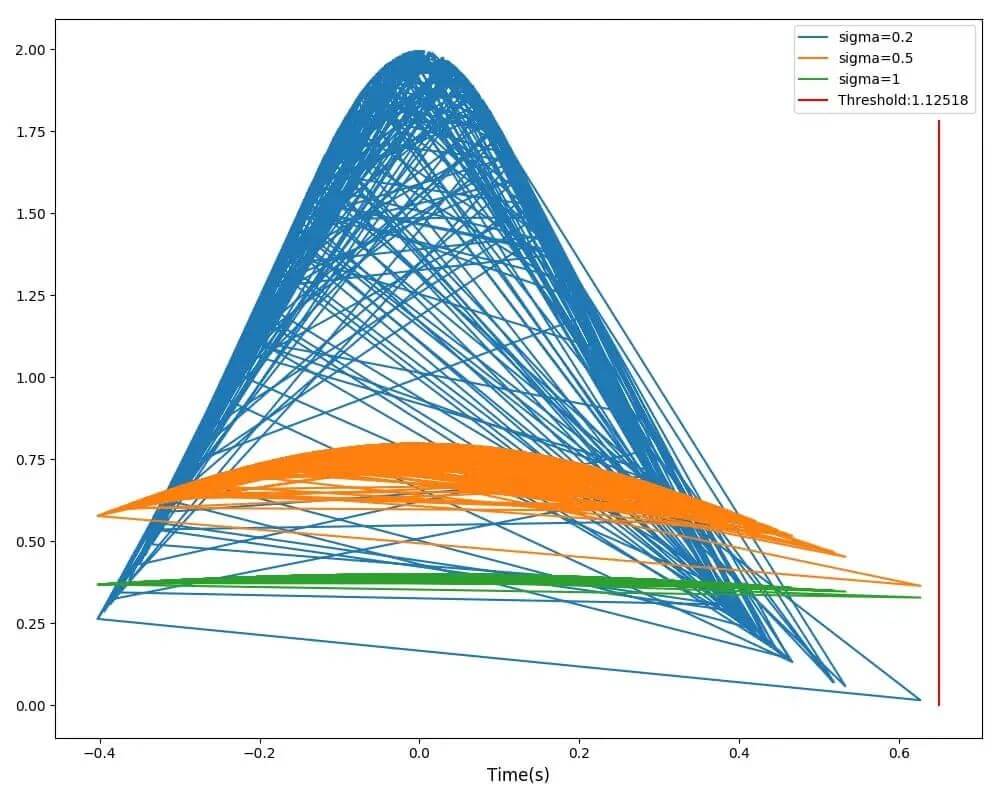
函数耗时高斯分布曲线及阈值效果示例
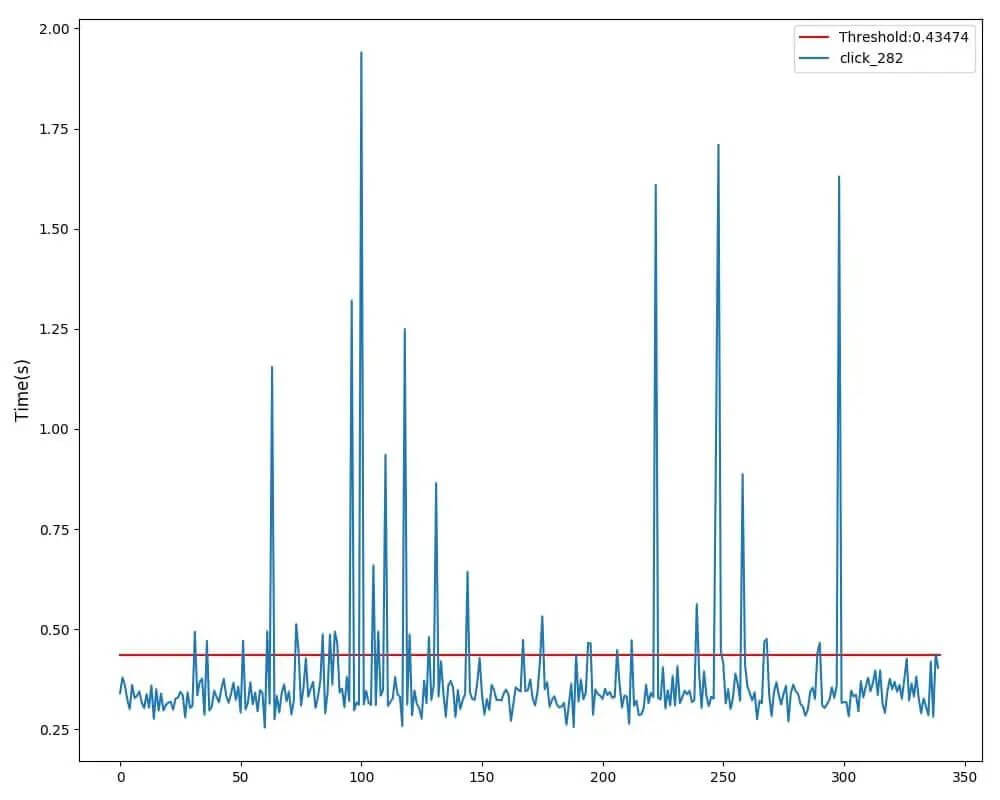
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
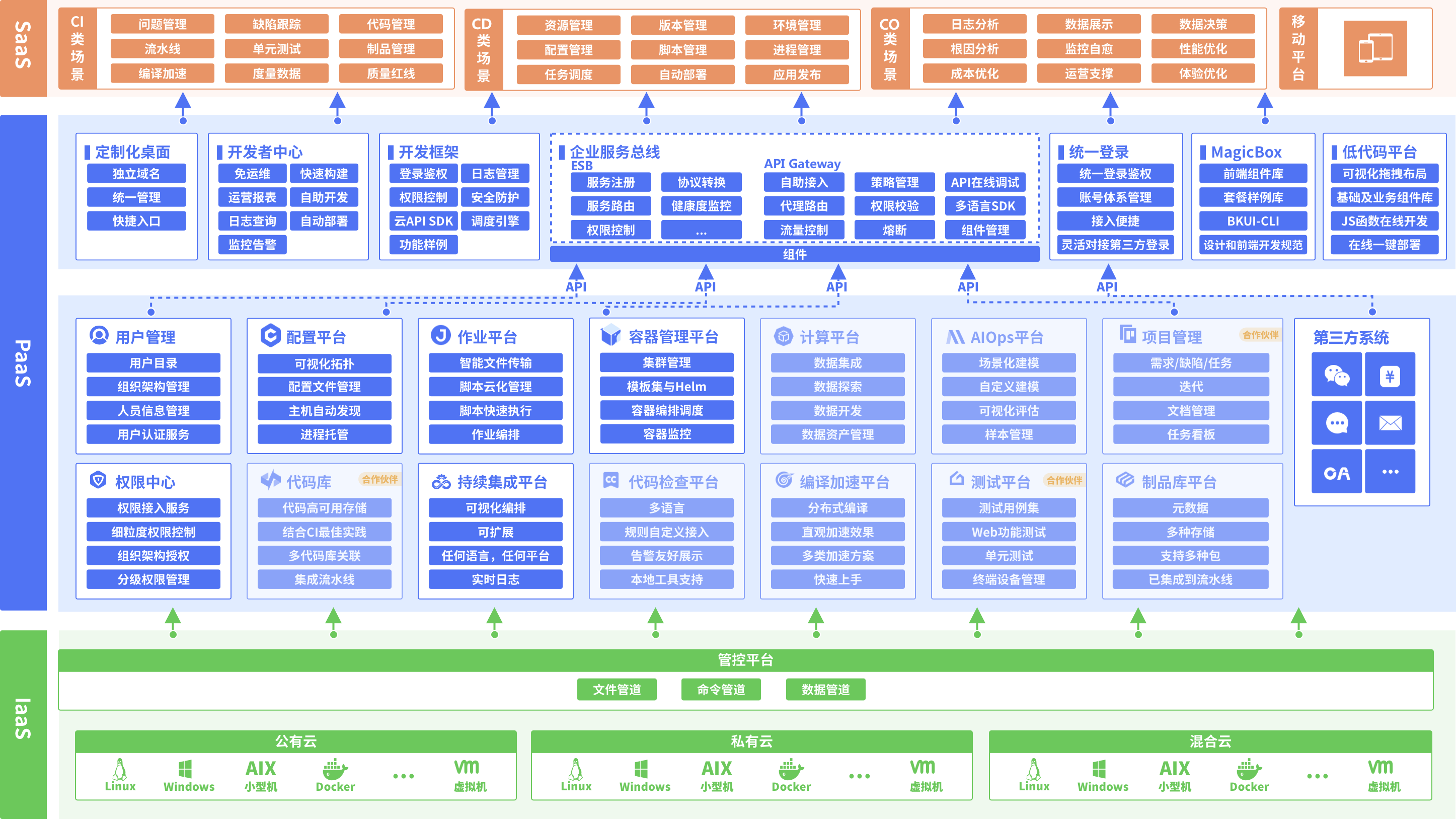
腾讯蓝鲸智云是一个高效的运维基础服务自动化体系,拥有支撑数百款腾讯业务的经验沉淀,是一个相对成熟稳定的运维系统。
简而言之,基于蓝鲸这套体系,你可以很方便地管控多个主机、执行作业、监控其运行状态。
此外,基于蓝鲸体系的PaaS平台,你可以非常方便地自动化部署那些使用Golang或Python开发面向内网的SaaS应用。
当然,蓝鲸这套体系不仅仅可以用于运维,比如蓝鲸监控赋予了用户比较大的灵活性,你可以配置脚本采集上报任意你需要监测的数据到蓝鲸监控并配置告警。
社区版是腾讯蓝鲸为运维社区用户免费开放的一套可独立搭建部署的版本,下面给大家提供单机部署的完整指引。
进入蓝鲸官网获取「蓝鲸社区版」安装包和部署脚本,并上传到服务器的data目录下,我这里在 xshell 使用 rz -E 上传文件包:
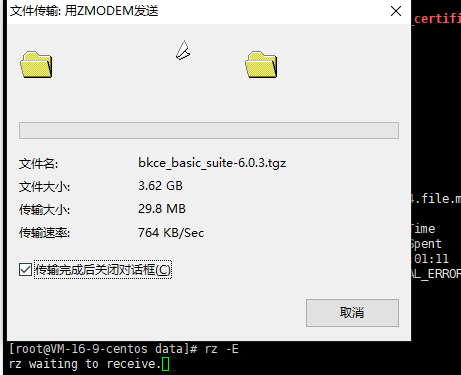
使用 tar -xvf 命令解压社区版软件包:
tar -xvf /data/bkce_src-xx.tar.gz -C /data/
xx 是你所下载的社区版版本号。
软件包比较大,解压需要一定时间。

运行以下命令,获取MAC地址,拷贝下来到官网输入证书并下载:
cat /sys/class/net/eth0/address # 52:54:00:xx:xx:xx
将下载完成的证书传到/data/目录下,并解压证书文件到 /data/src/cert 目录:
cd /data/install install -d -m 755 /data/src/cert tar -xvf /data/ssl_certificates.tar.gz -C /data/src/cert/
解压各个产品软件包并拷贝 rpm 软件包:
cd /data/src/; for f in *gz;do tar xf $f; done cp -a /data/src/yum /opt
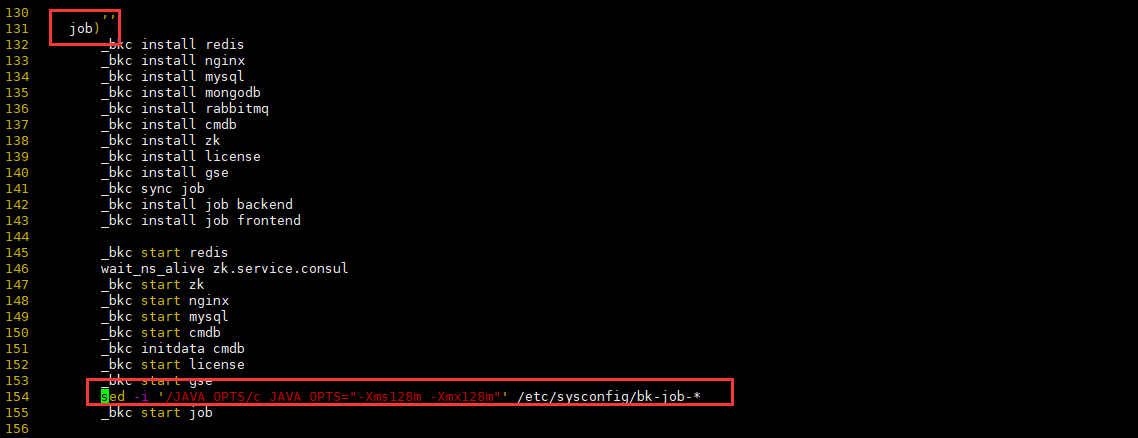
修改 bk_install 脚本,如图在 job 处添加以下内容:
vim /data/install/bk_install sed -i '/JAVA_OPTS/c JAVA_OPTS="-Xms128m -Xmx128m"' /etc/sysconfig/bk-job-*
去除 install_minibk 的 .path 配置:
sed -i '33,34d' /data/install/install_minibk
在 install.config.3ip.sample 文件追加一行空行:
echo >> /data/install/install.config.3ip.sample
install.config 这个文件安装脚本会自动生成,无需自行配置。
启动安装脚本,运行命令:
cd /data/install ./install_minibk -y
安装过程中遇到失败的情况,请先定位排查解决后,再重新运行失败时的安装指令。
执行完部署后,执行降低内存消耗脚本。以确保环境的稳定:
cd /data/install sed -i '/^cheaper/d' /data/bkce/etc/uwsgi-*.ini # 执行降低内存消耗脚本 bash bin/single_host_low_memory_config.sh tweak all
初始化蓝鲸业务拓扑:
./bkcli initdata topo
由于没有实际域名分配,所以需要配置你本地 PC 的 hosts 文件来访问;打开你电脑里的 hosts文件(windows: C:\windows\system32\drivers\etc\hosts, linux/mac: /etc/hosts)
将下面域名配置复制粘贴至底部,并保存!
10.0.0.1 paas.bktencent.com cmdb.bktencent.com job.bktencent.com jobapi.bktencent.com nodeman.bktencent.com
其中 10.0.0.1 记得替换为你的服务器地址,然后在机器上运行下列命令获取ADMIN账号的用户名和密码:
grep -E "BK_PAAS_ADMIN_USERNAME|BK_PAAS_ADMIN_PASSWORD" /data/install/bin/04-final/usermgr.env
打开下面网址并输入用户名和密码,就能成功访问蓝鲸了。
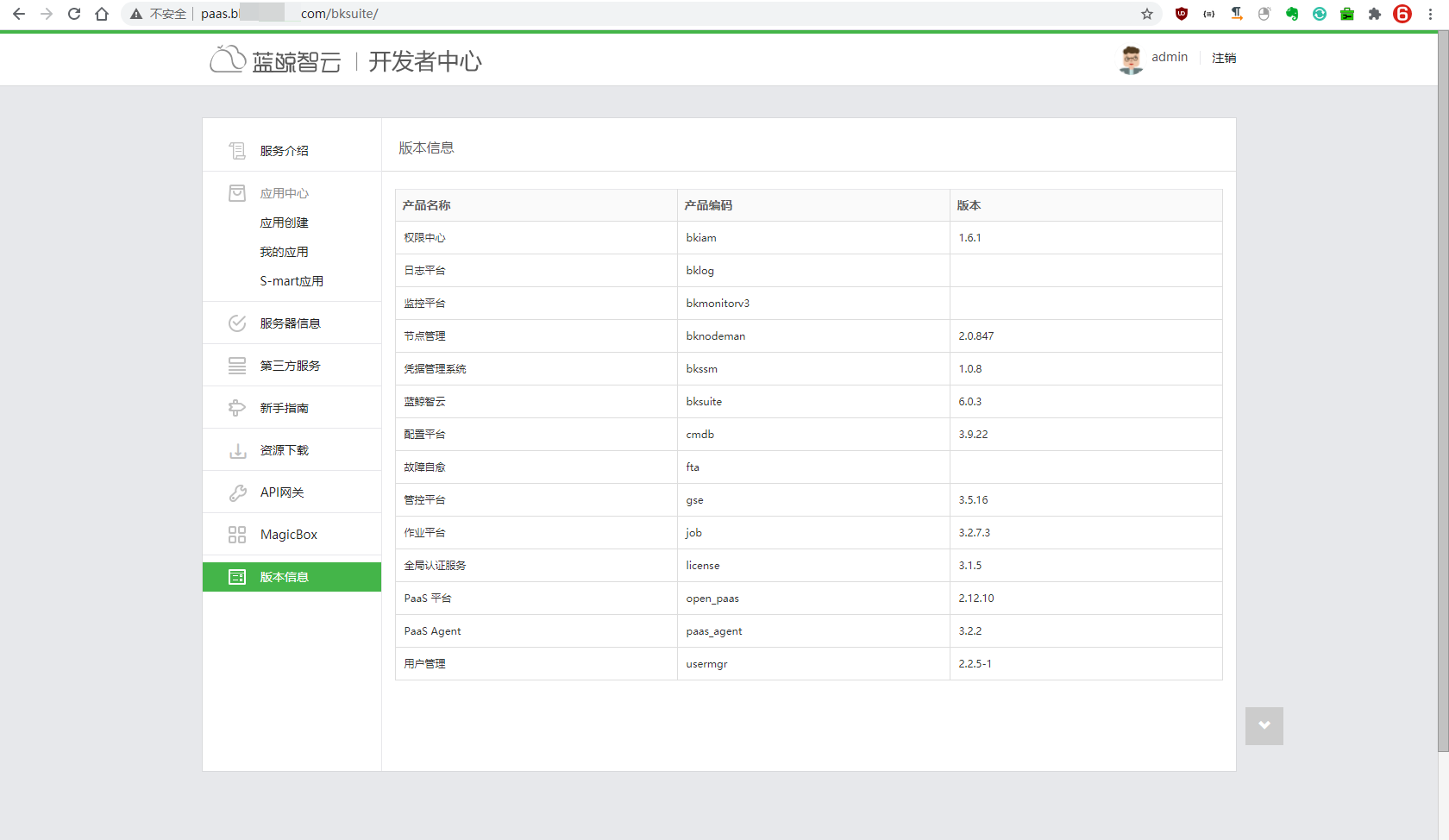
如果你想了解蓝鲸中配置平台、作业平台、监控平台等产品的使用方法,可以访问蓝鲸官方文档查询:
https://bk.tencent.com/docs/document/6.0/128/5859
下一篇文章,我们将给大家探讨蓝鲸监控的几种有趣的使用方法,基于蓝鲸监控的采集配置功能,我们能实现一些非常有趣的告警策略,敬请期待。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

















































































