<!doctype html>
<html>
<head>
<meta charset="utf-8">
<script type="text/javascript"
src="https://cdn.jsdelivr.net/npm/brython@3.8.9/brython.min.js">
</script>
</head>
<body onload="brython()">
<script type="text/python">
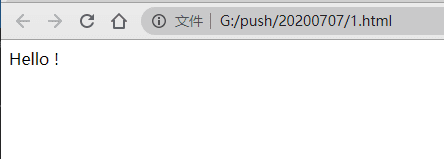
from browser import document, html
document <= html.B("Hello !")
document <= html.UL(html.LI(i) for i in range(5))
document <= html.A("Python实用宝典", href="https://pythondict.com")
</script>
</body>
</html>
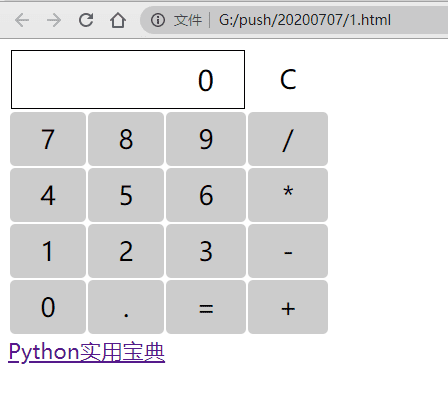
效果:
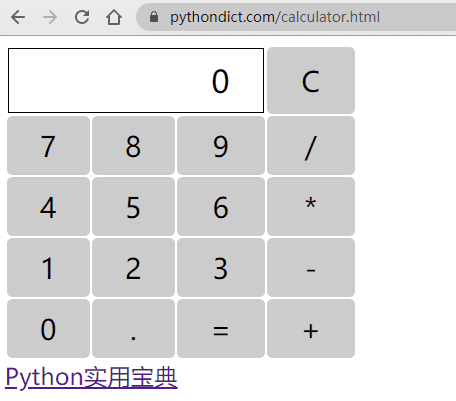
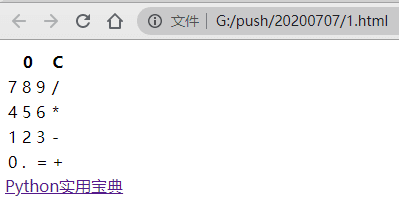
3.写一个简单的计算器
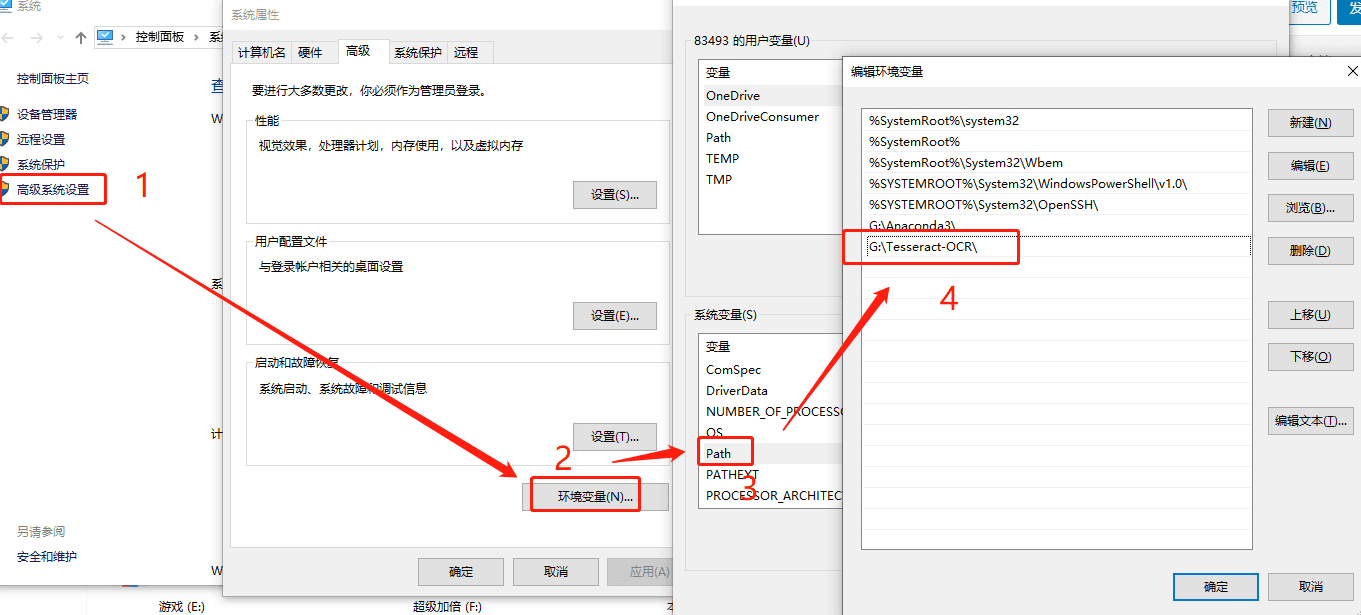
先写好简单的图形架构,用th和tr标签即可:
from browser import document, html
calc = html.TABLE()
calc <= html.TR(html.TH(html.DIV("0", id="result"), colspan=3) +
html.TH("C", id="clear"))
lines = ["789/",
"456*",
"123-",
"0.=+"]
calc <= (html.TR(html.TD(x) for x in line) for line in lines)
document <= calc
calc <= (html.TR(html.TD(x) for x in line) for line in lines)
可以看出,所有的按钮都被创建为td标签,因此我们要获得所有这些按钮是否被点击,仅需要:
for button in document.select("td"):
button.bind("click", action)
意思是,按钮被点击后便执行 action 操作,action操作定义如下:
def action(event):
"""Handles the "click" event on a button of the calculator."""
# The element the user clicked on is the attribute "target" of the
# event object
element = event.target
# The text printed on the button is the element's "text" attribute
value = element.text
if value not in "=C":
# update the result zone
if result.text in ["0", "error"]:
result.text = value
else:
result.text = result.text + value
elif value == "C":
# reset
result.text = "0"
elif value == "=":
# execute the formula in result zone
try:
result.text = eval(result.text)
except:
result.text = "error"
import time
def decrement(n):
while n > 0:
n -= 1
start = time.time()
decrement(100000000)
end = time.time()
print(f"{end - start}s.")
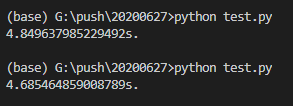
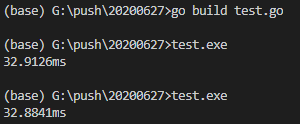
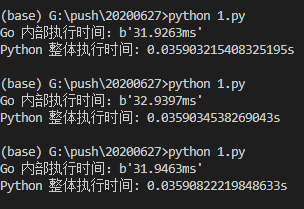
结果如下:
大约需要4秒-5秒才能完成这项工作,那么Go语言呢?
package main
import "fmt"
import "time"
var c chan int
func decrement(n int) {
for n > 0 {
n -= 1
}
}
func main() {
start := time.Now()
decrement(100000000)
fmt.Println(time.Since(start))
}
from oscar.defaults import *
from oscar import INSTALLED_APPS as OSCAR_APPS
# Path helper
location = lambda x: os.path.join(os.path.dirname(os.path.realpath(__file__)), x)
import pandas as pd import xlrd from docx import Document from docx.shared import Pt from docx.shared import Inches from docx.oxml.ns import qn from docx.enum.text import WD_PARAGRAPH_ALIGNMENT from docx.enum.section import WD_ORIENTATION
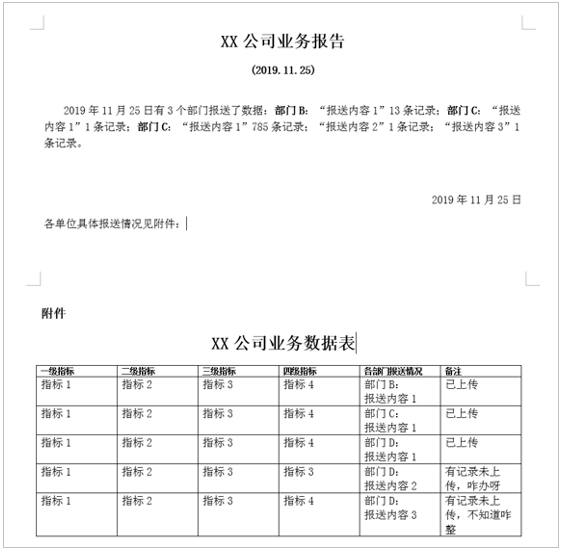
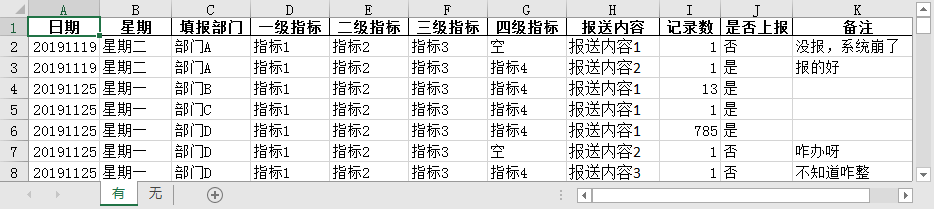
基本流程很简单,读入无填报记录的数据,按日期输出 word 文档。
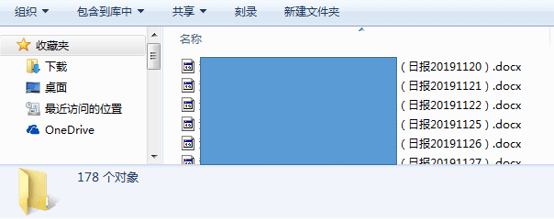
defwu_to_word(filepath): df = pd.read_excel(filepath, sheet_name="无") date_list = list(df['日期']) for d in date_list: filename = wordname+str(d)+").docx"# 输出的word文件名 title = "("+str(d)[:4]+"."+str(d)[4:6]+"."+str(d)[6:8]+")"# 副标题日期XXXX.XX.XX word = str(d)[:4]+"年"+str(d)[4:6]+"月"+str(d)[6:8]+"日"# 开头、落款日期XXXX年XX月XX日 wu_doc(title, word, filename) print(f"文件:{filename},{title},{word} 已保存")
defget_sentence(df_total, df_index): df_oneday = df_total[df_index] num = df_oneday['填报部门'].nunique() # 部门的数量 group = [] # 部门名称 detail = [] # 组合某个部门的数据,其中元素为元组格式(, , , ) info = ''# 报送情况描述 for item in df_oneday.groupby('填报部门'): group.append(item[0]) detail.append( list( zip( list(item[1]['报送内容']), list(item[1]['记录数']), list(item[1]['是否上报']), list(item[1]['备注']) ) ) ) for index, g in enumerate(group): # 整理每个部门的填报情况 mes = str(g)+':'# 部门开头 for i in range(len(detail[index])): _mes = detail[index][i] if int(_mes[1])>0: mes = mes + f'“{_mes[0]}”{_mes[1]}条记录;' info = info + mes info = info[:-1]+"。"#将最后一个分号替换成句号 sentence = f"有{num}个部门报送了数据:{info}" return sentence
rows = len(table)+1 word_table = doc.add_table(rows=rows, cols=6, style='Table Grid') # 创建rows行、6列的表格 word_table.autofit=True# 添加框线 table = [table_title] + table # 固定的表头+表数据 for row in range(rows): # 写入表格 cells = word_table.rows[row].cells for col in range(6): cells[col].text = str(table[row][col]) for i in range(len(word_table.rows)): # 遍历行列,逐格修改样式 for j in range(len(word_table.columns)): for par in word_table.cell(i, j).paragraphs: # 修改字号 for run in par.runs: run.font.size = Pt(10.5) for par in word_table.cell(0, j).paragraphs: # 第一行加粗 for run in par.runs: run.bold = True doc.save(dir+filename)