标签归档:development





Gitsome-增强型Git/GitHub命令行界面(CLI)。GitHub和GitHub企业的官方集成:https://github.com/works-with/category/desktop-tools
一个Official Integration对于GitHub和GitHub Enterprise
为什么gitsome?
Git命令行
虽然标准的Git命令行是管理基于Git的repo的一个很好的工具,但是它可以很难记住这个用法地址为:
- 150多个瓷器和管道命令
- 无数特定于命令的选项
- 标签和分支等资源
Git命令行不与GitHub集成,强制您在命令行和浏览器之间切换
gitsome-具有自动完成功能的增压Git/GitHub CLI
![]()
gitsome旨在通过专注于以下方面来增强您的标准git/shell界面:
- 提高易用性
- 提高工作效率
深度GitHub集成
并不是所有的GitHub工作流都能在终端中很好地工作;gitsome试图将目标对准那些这样做的人
gitsome包括29个与一起使用的GitHub集成命令ALL外壳:
$ gh <command> [param] [options]
跑gh命令以及Git-Extras和hub解锁更多GitHub集成的命令!
带有交互式帮助的Git和GitHub自动完成程序
您可以运行可选壳牌:
$ gitsome
要启用自动完成和交互式帮助对于以下内容:
- Git命令
- Git选项
- Git树枝、标签等
- Git-Extras commands
- GitHub integration commands
通用自动补全程序
gitsome自动完成以下内容:
- Shell命令
- 文件和目录
- 环境变量
- 手册页
- python
要启用其他自动完成,请查看Enabling Bash Completions部分
鱼式自动建议
gitsome支持鱼式自动建议。使用right arrow完成建议的关键
Python REPL
gitsome由以下人员提供动力xonsh,它支持Python REPL
在shell命令旁边运行Python命令:
附加内容xonsh功能可在xonsh tutorial
命令历史记录
gitsome跟踪您输入的命令并将其存储在~/.xonsh_history.json使用向上和向下箭头键循环查看命令历史记录
可自定义的突出显示
可以控制用于突出显示的ansi颜色,方法是更新~/.gitsomeconfig文件
颜色选项包括:
'black', 'red', 'green', 'yellow',
'blue', 'magenta', 'cyan', 'white'
对于无颜色,请将值设置为Nonewhite在某些终端上可能显示为浅灰色
可用的平台
gitsome适用于Mac、Linux、Unix、Windows,以及Docker
待办事项
并不是所有的GitHub工作流都能在终端中很好地工作;
gitsome试图将目标对准那些这样做的人
- 添加其他GitHub API集成
gitsome才刚刚开始。请随意……contribute!
索引
GitHub集成命令
- GitHub Integration Commands Syntax
- GitHub Integration Commands Listing
- GitHub Integration Commands Quick Reference
- GitHub Integration Commands Reference in COMMANDS.md
gh configuregh create-commentgh create-issuegh create-repogh emailsgh emojisgh feedgh followersgh followinggh gitignore-templategh gitignore-templatesgh issuegh issuesgh licensegh licensesgh megh notificationsgh octogh pull-requestgh pull-requestsgh rate-limitgh repogh reposgh search-issuesgh search-reposgh starredgh trendinggh usergh view
- Option: View in a Pager
- Option: View in a Browser
安装和测试
- Installation
- Developer Installation
杂项
GitHub集成命令语法
用法:
$ gh <command> [param] [options]
GitHub集成命令列表
configure Configure gitsome.
create-comment Create a comment on the given issue.
create-issue Create an issue.
create-repo Create a repo.
emails List all the user's registered emails.
emojis List all GitHub supported emojis.
feed List all activity for the given user or repo.
followers List all followers and the total follower count.
following List all followed users and the total followed count.
gitignore-template Output the gitignore template for the given language.
gitignore-templates Output all supported gitignore templates.
issue Output detailed information about the given issue.
issues List all issues matching the filter.
license Output the license template for the given license.
licenses Output all supported license templates.
me List information about the logged in user.
notifications List all notifications.
octo Output an Easter egg or the given message from Octocat.
pull-request Output detailed information about the given pull request.
pull-requests List all pull requests.
rate-limit Output the rate limit. Not available for Enterprise.
repo Output detailed information about the given filter.
repos List all repos matching the given filter.
search-issues Search for all issues matching the given query.
search-repos Search for all repos matching the given query.
starred Output starred repos.
trending List trending repos for the given language.
user List information about the given user.
view View the given index in the terminal or a browser.
GitHub集成命令参考:COMMANDS.md
请参阅GitHub Integration Commands Reference in COMMANDS.md对于详细讨论所有GitHub集成命令、参数、选项和示例
请查看下一节,了解快速参考
GitHub集成命令快速参考
配置gitsome
要与GitHub正确集成,您必须首先配置gitsome:
$ gh configure
对于GitHub Enterprise用户,使用-e/--enterprise标志:
$ gh configure -e
列表源
列出您的新闻源
$ gh feed
列出用户的活动摘要
查看您的活动订阅源或其他用户的活动订阅源,也可以选择使用寻呼机-p/--pager这个pager option可用于许多命令
$ gh feed donnemartin -p
列出回购的活动提要
$ gh feed donnemartin/gitsome -p
列出通知
$ gh notifications
列出拉式请求
查看您的回购的所有拉式请求:
$ gh pull-requests
过滤问题
查看您提到的所有未决问题:
$ gh issues --issue_state open --issue_filter mentioned
查看所有问题,只筛选分配给您的问题,而不考虑状态(打开、关闭):
$ gh issues --issue_state all --issue_filter assigned
有关过滤和州限定词的更多信息,请访问gh issues参考位置COMMANDS.md
过滤星级报告
$ gh starred "repo filter"
搜索问题和报告
搜索问题
+1最多的搜索问题:
$ gh search-issues "is:open is:issue sort:reactions-+1-desc" -p
评论最多的搜索问题:
$ gh search-issues "is:open is:issue sort:comments-desc" -p
使用“需要帮助”标签搜索问题:
$ gh search-issues "is:open is:issue label:\"help wanted\"" -p
已标记您的用户名的搜索问题@donnemartin:
$ gh search-issues "is:issue donnemartin is:open" -p
搜索您所有未解决的私人问题:
$ gh search-issues "is:open is:issue is:private" -p
有关查询限定符的更多信息,请访问searching issues reference
搜索报告
搜索2015年或之后创建的所有Python repos,>=1000星:
$ gh search-repos "created:>=2015-01-01 stars:>=1000 language:python" --sort stars -p
有关查询限定符的更多信息,请访问searching repos reference
列出趋势报告和开发人员
查看趋势回购:
$ gh trending [language] [-w/--weekly] [-m/--monthly] [-d/--devs] [-b/--browser]
查看趋势DEV(目前仅浏览器支持DEV):
$ gh trending [language] --devs --browser
查看内容
这个view命令
查看前面列出的通知、拉取请求、问题、回复、用户等,HTML格式适合您的终端,也可以选择在您的浏览器中查看:
$ gh view [#] [-b/--browser]
这个issue命令
查看问题:
$ gh issue donnemartin/saws/1
这个pull-request命令
查看拉取请求:
$ gh pull-request donnemartin/awesome-aws/2
设置.gitignore
列出所有可用的.gitignore模板:
$ gh gitignore-templates
设置您的.gitignore:
$ gh gitignore-template Python > .gitignore
设置LICENSE
列出所有可用的LICENSE模板:
$ gh licenses
设置您的或LICENSE:
$ gh license MIT > LICENSE
召唤十月猫
在十月猫那天打电话说出给定的信息或复活节彩蛋:
$ gh octo [say]
查看配置文件
查看用户的配置文件
$ gh user octocat
查看您的个人资料
使用查看您的个人资料gh user [YOUR_USER_ID]命令或使用以下快捷方式:
$ gh me
创建评论、问题和报告
创建评论:
$ gh create-comment donnemartin/gitsome/1 -t "hello world"
创建问题:
$ gh create-issue donnemartin/gitsome -t "title" -b "body"
创建回购:
$ gh create-repo gitsome
选项:在寻呼机中查看
许多gh命令支持-p/--pager在寻呼机中显示结果的选项(如果可用)
用法:
$ gh <command> [param] [options] -p
$ gh <command> [param] [options] --pager
选项:在浏览器中查看
许多gh命令支持-b/--browser在默认浏览器(而不是终端)中显示结果的选项
用法:
$ gh <command> [param] [options] -b
$ gh <command> [param] [options] --browser
请参阅COMMANDS.md有关所有GitHub集成命令、参数、选项和示例的详细列表
记住这些命令有困难吗?看看手边的autocompleter with interactive help来指导您完成每个命令
注意,您可以将gitsome与其他实用程序(如Git-Extras
安装
PIP安装
gitsome托管在PyPI将安装以下命令gitsome:
$ pip3 install gitsome
您还可以安装最新的gitsome来自GitHub源,可能包含尚未推送到PyPI的更改:
$ pip3 install git+https://github.com/donnemartin/gitsome.git
如果您没有安装在virtualenv,您可能需要运行sudo:
$ sudo pip3 install gitsome
pip3
根据您的设置,您可能还希望运行pip3使用-H flag:
$ sudo -H pip3 install gitsome
对于大多数Linux用户来说,pip3可以使用python3-pip套餐
例如,Ubuntu用户可以运行:
$ sudo apt-get install python3-pip
看这个ticket有关更多详细信息,请参阅
虚拟环境安装
您可以将Python包安装在virtualenv要避免依赖项或权限的潜在问题,请执行以下操作
如果您是Windows用户,或者如果您想了解更多有关virtualenv,看看这个guide
安装virtualenv和virtualenvwrapper:
$ pip3 install virtualenv
$ pip3 install virtualenvwrapper
$ export WORKON_HOME=~/.virtualenvs
$ source /usr/local/bin/virtualenvwrapper.sh
创建gitsomevirtualenv并安装gitsome:
$ mkvirtualenv gitsome
$ pip3 install gitsome
如果pip安装不起作用,您可能默认运行的是Python2。检查您正在运行的Python版本:
$ python --version
如果上面的调用结果是Python 2,请找到Python 3的路径:
$ which python3 # Python 3 path for mkvirtualenv's --python option
如果需要,安装Python 3。调用时设置Python版本mkvirtualenv:
$ mkvirtualenv --python [Python 3 path from above] gitsome
$ pip3 install gitsome
如果要激活gitsomevirtualenv稍后再次运行:
$ workon gitsome
要停用gitsomevirtualenv,运行:
$ deactivate
作为Docker容器运行
您可以在Docker容器中运行gitome,以避免安装Python和pip3当地的。要安装Docker,请查看official Docker documentation
一旦安装了docker,您就可以运行gitome:
$ docker run -ti --rm mariolet/gitsome
您可以使用Docker卷让gitome访问您的工作目录、本地的.gitSomeconfig和.gitconfig:
$ docker run -ti --rm -v $(pwd):/src/ \
-v ${HOME}/.gitsomeconfig:/root/.gitsomeconfig \
-v ${HOME}/.gitconfig:/root/.gitconfig \
mariolet/gitsome
如果您经常运行此命令,则可能需要定义别名:
$ alias gitsome="docker run -ti --rm -v $(pwd):/src/ \
-v ${HOME}/.gitsomeconfig:/root/.gitsomeconfig \
-v ${HOME}/.gitconfig:/root/.gitconfig \
mariolet/gitsome"
要从源构建Docker映像,请执行以下操作:
$ git clone https://github.com/donnemartin/gitsome.git
$ cd gitsome
$ docker build -t gitsome .
启动gitsome壳
安装后,运行可选的gitsome带有交互式帮助的自动完成程序:
$ gitsome
运行可选的gitsomeShell将为您提供自动完成、交互式帮助、鱼式建议、Python REPL等
正在运行gh命令
运行GitHub集成命令:
$ gh <command> [param] [options]
注意:运行gitsome不需要执行外壳程序gh命令。之后installinggitsome你可以跑gh来自任何shell的命令
运行gh configure命令
要与GitHub正确集成,gitsome必须正确配置:
$ gh configure
针对GitHub企业用户
使用-e/--enterprise标志:
$ gh configure -e
要查看更多详细信息,请访问gh configure部分
启用Bash完成
默认情况下,gitsome查看以下内容locations to enable bash completions
要添加其他bash完成,请更新~/.xonshrc包含bash完成位置的文件
如果~/.xonshrc不存在,请创建它:
$ touch ~/.xonshrc
例如,如果在/usr/local/etc/my_bash_completion.d/completion.bash,将以下行添加到~/.xonshrc:
$BASH_COMPLETIONS.append('/usr/local/etc/my_bash_completion.d/completion.bash')
您将需要重新启动gitsome要使更改生效,请执行以下操作
正在启用gh在外部完成制表符gitsome
你可以跑gh外部的命令gitsome外壳完成器。要启用gh此工作流的制表符完成,请将gh_complete.sh本地文件
让bash知道可以完成gh当前会话中的命令:
$ source /path/to/gh_complete.sh
要为所有终端会话启用制表符完成,请将以下内容添加到您的bashrc文件:
source /path/to/gh_complete.sh
重新加载您的bashrc:
$ source ~/.bashrc
提示:.是的缩写source,因此您可以改为运行以下命令:
$ . ~/.bashrc
对于Zsh用户
zsh包括与bash完成兼容的模块
下载gh_complete.sh文件,并将以下内容附加到您的.zshrc:
autoload bashcompinit
bashcompinit
source /path/to/gh_complete.sh
重新加载您的zshrc:
$ source ~/.zshrc
可选:安装PIL或Pillow
将化身显示为gh me和gh user命令需要安装可选的PIL或Pillow依赖性
Windows*和Mac:
$ pip3 install Pillow
*请参阅Windows Support有关化身限制的部分
Ubuntu用户,看看这些instructions on askubuntu
支持的Python版本
- Python 3.4
- Python 3.5
- Python 3.6
- Python 3.7
gitsome由以下人员提供动力xonsh,它当前不支持Python2.x,如本文中所讨论的ticket
支持的平台
- Mac OS X
- 在OS X 10.10上测试
- Linux、Unix
- 在Ubuntu 14.04 LTS上测试
- 窗口
- 在Windows 10上测试
Windows支持
gitsome已在Windows 10上进行了测试,cmd和cmder
虽然您可以使用标准的Windows命令提示符,但使用这两种命令提示符都可能会有更好的体验cmder或conemu
纯文本化身
命令gh user和gh me将永远拥有-t/--text_avatar标志已启用,因为img2txt不支持Windows上的ANSI头像
配置文件
在Windows上,.gitsomeconfig 文件可在以下位置找到%userprofile%例如:
C:\Users\dmartin\.gitsomeconfig
开发人员安装
如果您有兴趣为gitsome,请运行以下命令:
$ git clone https://github.com/donnemartin/gitsome.git
$ cd gitsome
$ pip3 install -e .
$ pip3 install -r requirements-dev.txt
$ gitsome
$ gh <command> [param] [options]
pip3
如果您在安装时收到一个错误,提示您需要Python 3.4+,这可能是因为您的pip命令是为旧版本的Python配置的。要解决此问题,建议安装pip3:
$ sudo apt-get install python3-pip
看这个ticket有关更多详细信息,请参阅
持续集成
有关持续集成的详细信息,请访问Travis CI
单元测试和代码覆盖率
在活动的Python环境中运行单元测试:
$ python tests/run_tests.py
使用运行单元测试tox在多个Python环境中:
$ tox
文档
源代码文档将很快在Readthedocs.org请查看source docstrings
运行以下命令构建文档:
$ scripts/update_docs.sh
贡献
欢迎投稿!
回顾Contributing Guidelines有关如何执行以下操作的详细信息,请执行以下操作:
- 提交问题
- 提交拉式请求
学分
- click通过mitsuhiko
- github_trends_rss通过ryotarai
- github3.py通过sigmavirus24
- html2text通过aaronsw
- img2txt通过hit9
- python-prompt-toolkit通过jonathanslenders
- requests通过kennethreitz
- xonsh通过scopatz
联系信息
请随时与我联系,讨论任何问题、问题或评论
我的联系信息可以在我的GitHub page
许可证
我在开放源码许可下向您提供此存储库中的代码和资源。因为这是我的个人存储库,您获得的我的代码和资源的许可证来自我,而不是我的雇主(Facebook)
Copyright 2016 Donne Martin
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


Interactive-coding-challenges-120+交互式Python编码面试挑战(算法和数据结构)
交互式编码-挑战
120多项持续更新、交互式和测试驱动的编码挑战,具有Anki flashcards
挑战集中在算法和数据结构在以下位置找到编码面试
每个挑战都有一个或多个参考解决方案,它们是:
- 全功能
- 单元测试
- 通俗易懂
Challenges将很快提供按需服务incremental hints以帮助您获得最佳解决方案
笔记本还详细介绍了:
- 约束条件
- 测试用例
- 算法
- 大O时空复杂性
还包括单元测试的参考实现各式各样的data structures和algorithms
挑战解决方案
Anki抽认卡:编码与设计
提供的Anki flashcard deck使用间隔重复来帮助您记住关键概念
非常适合在旅途中使用
设计资源:系统设计入门
寻找资源来帮助您准备系统设计和面向对象的设计访谈?
查看姊妹回购The System Design Primer,其中包含其他Anki甲板:
笔记本结构
每个挑战有两个笔记本,一个挑战笔记本有要解决的单元测试和解决方案笔记本以供参考
问题陈述
- 陈述要解决的问题
约束条件
- 描述任何约束或假设。
测试用例
- 描述将在单元测试中评估的常规测试用例和边缘测试用例。
算法
- [挑战笔记本]空,如果需要提示,请参阅解决方案笔记本算法部分
- [解决方案笔记本]一个或多个算法方案讨论,时间和空间复杂度大O
提示
- [挑战笔记本]提供按需服务incremental hints来帮助你找到最优的解决方案。马上就来!
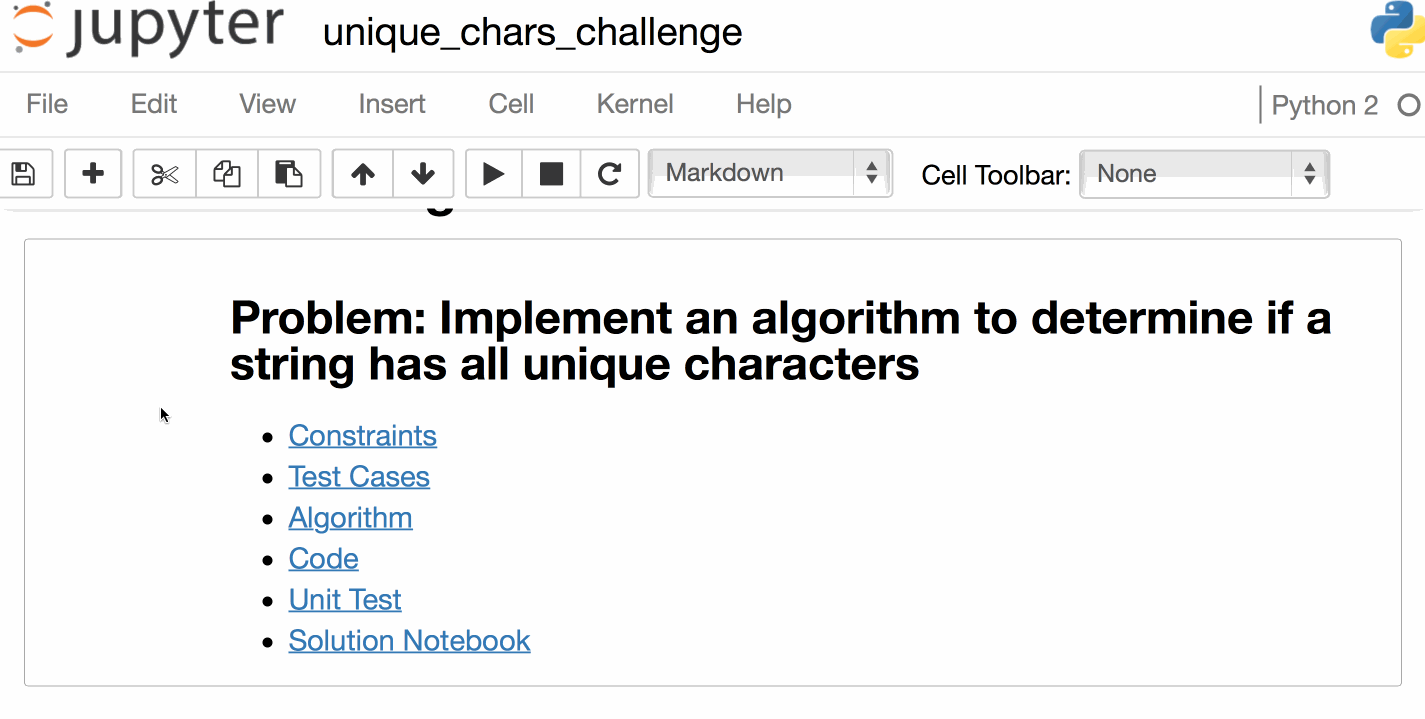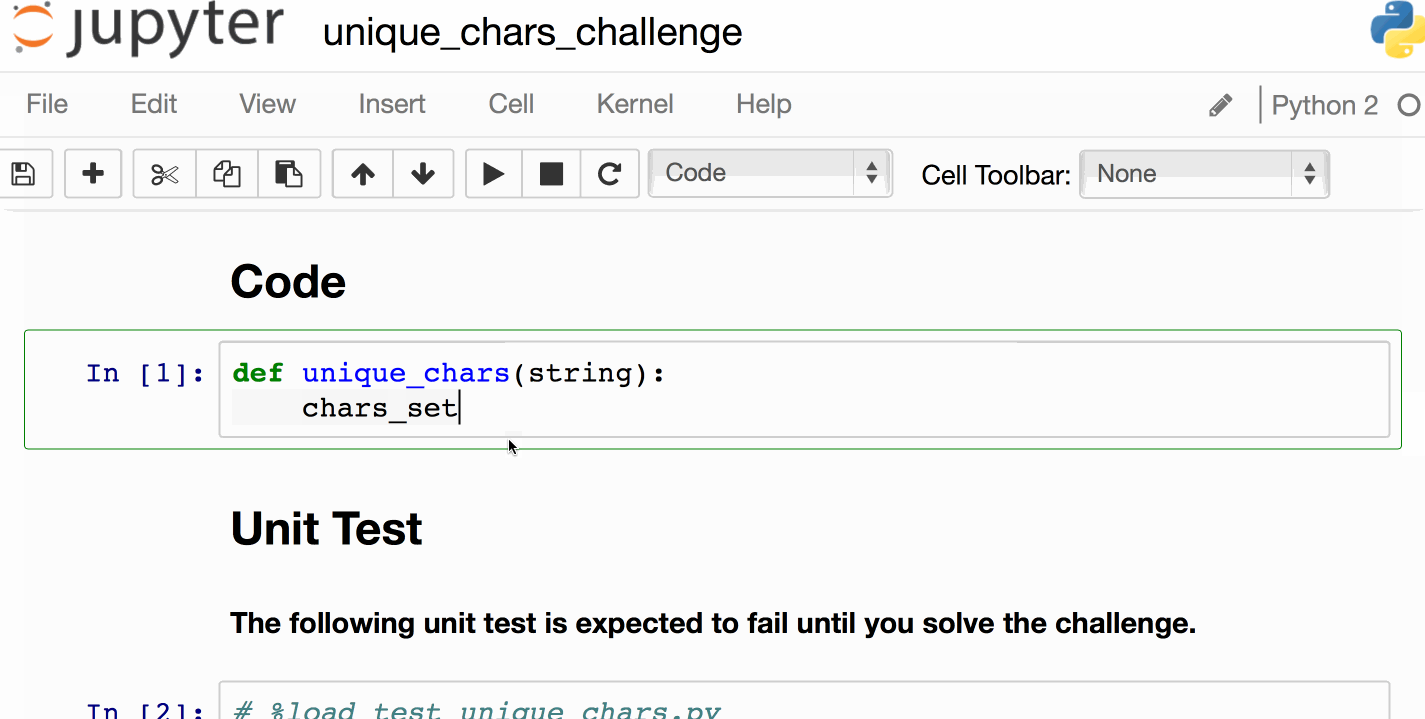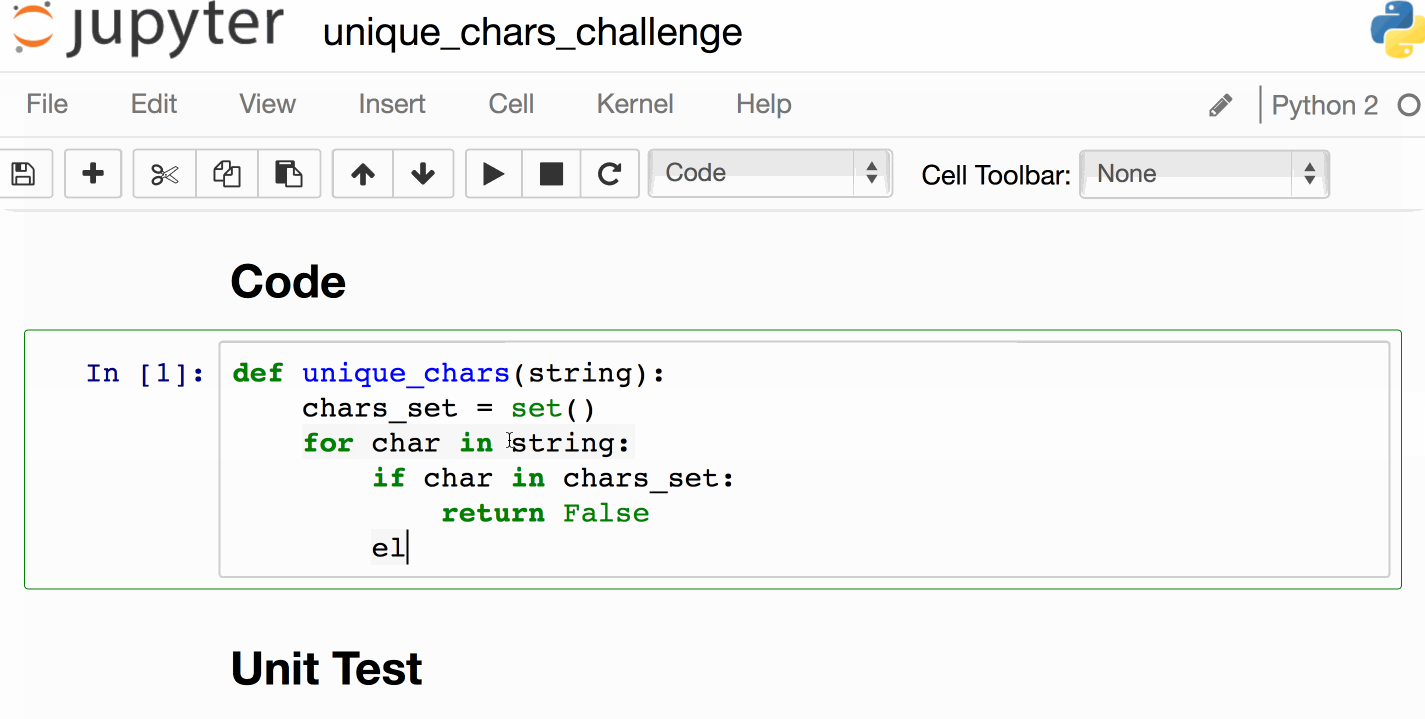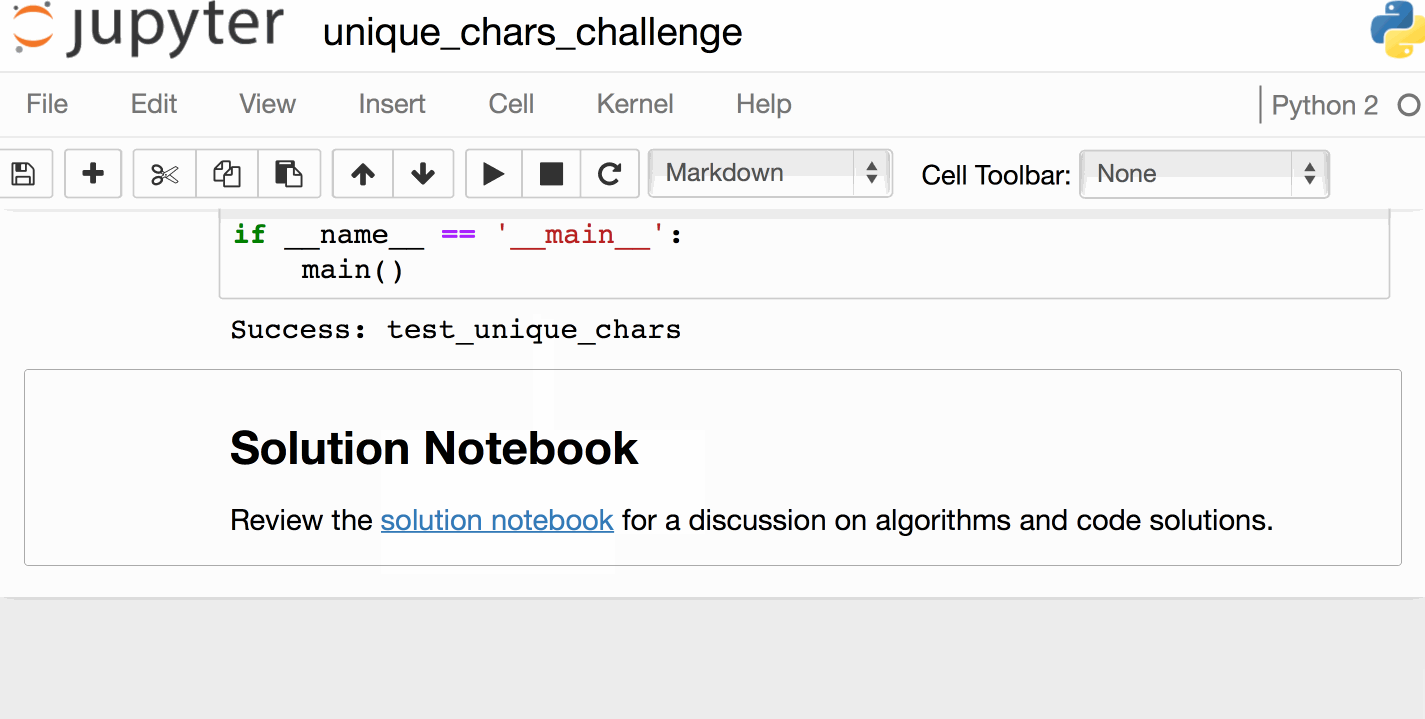
代码(挑战:实现我!)
- [挑战笔记本]供您实现的骨架代码
- [解决方案笔记本]一个或多个参考解决方案
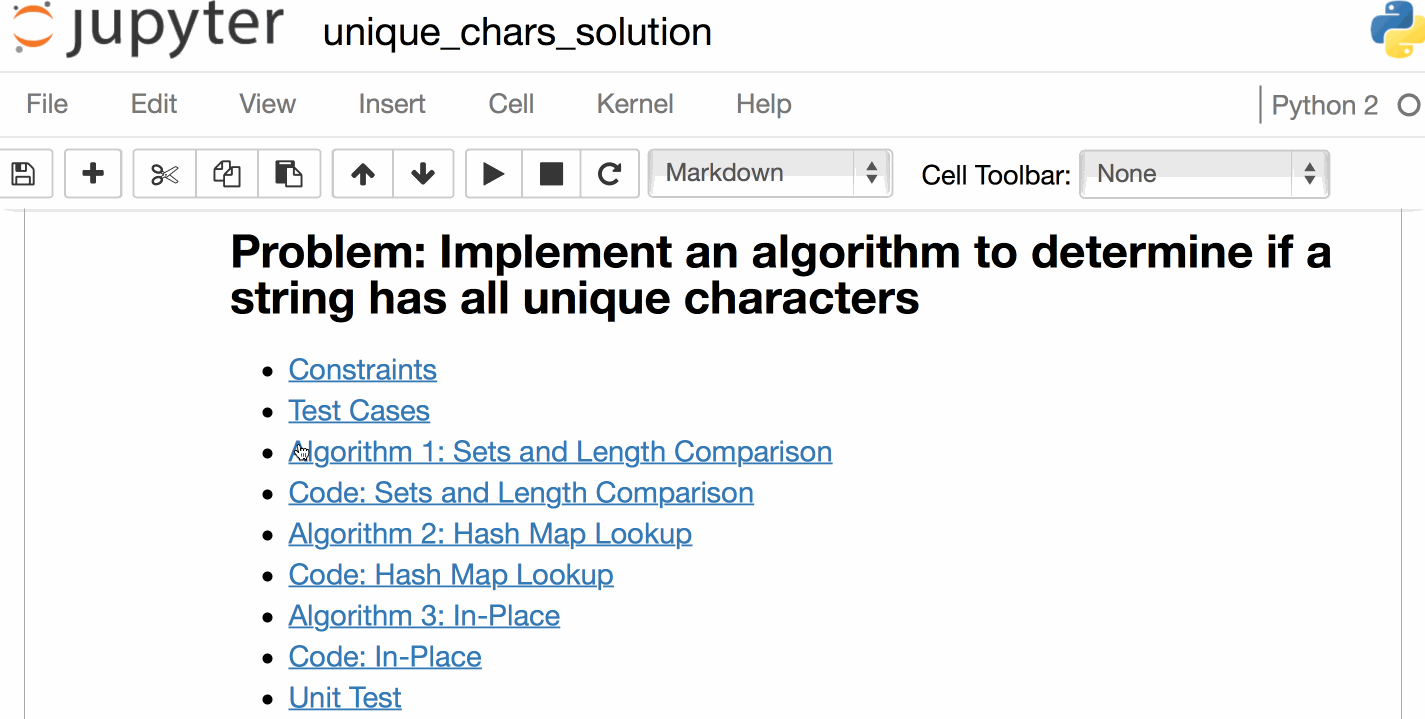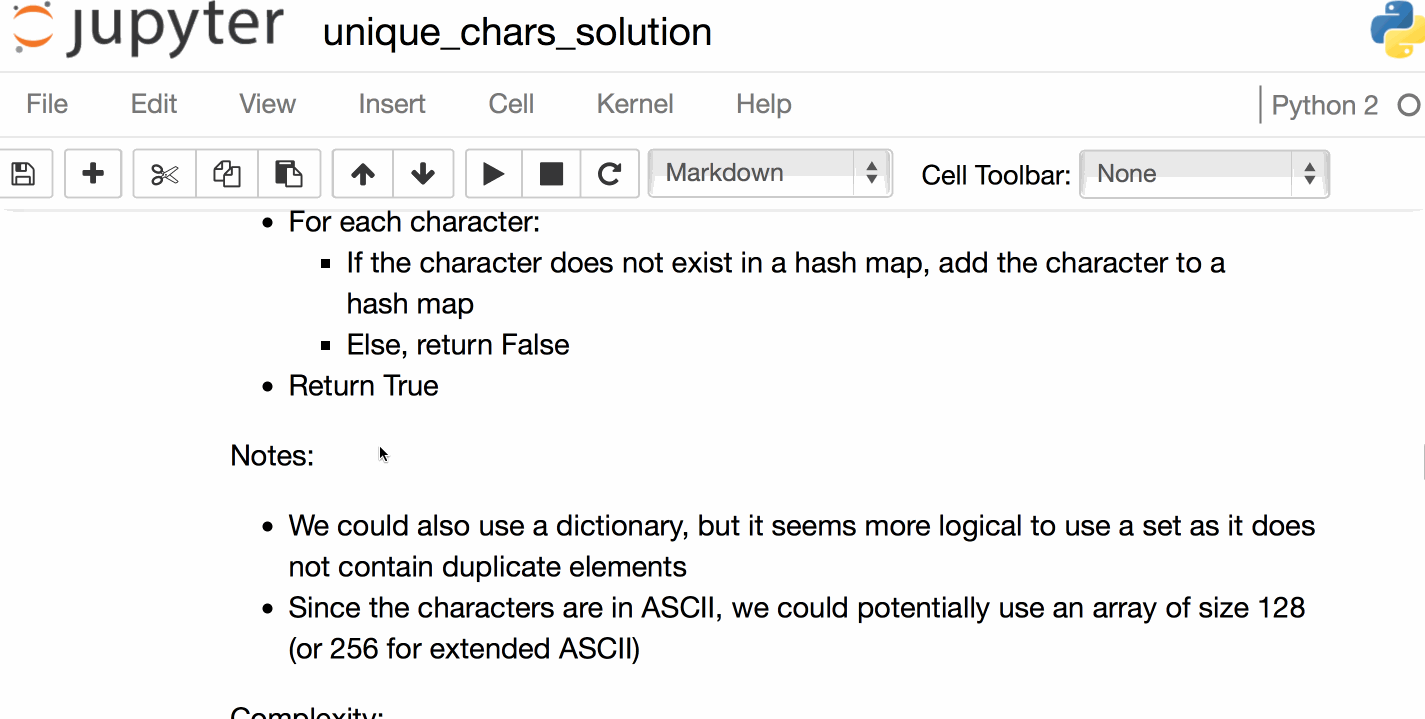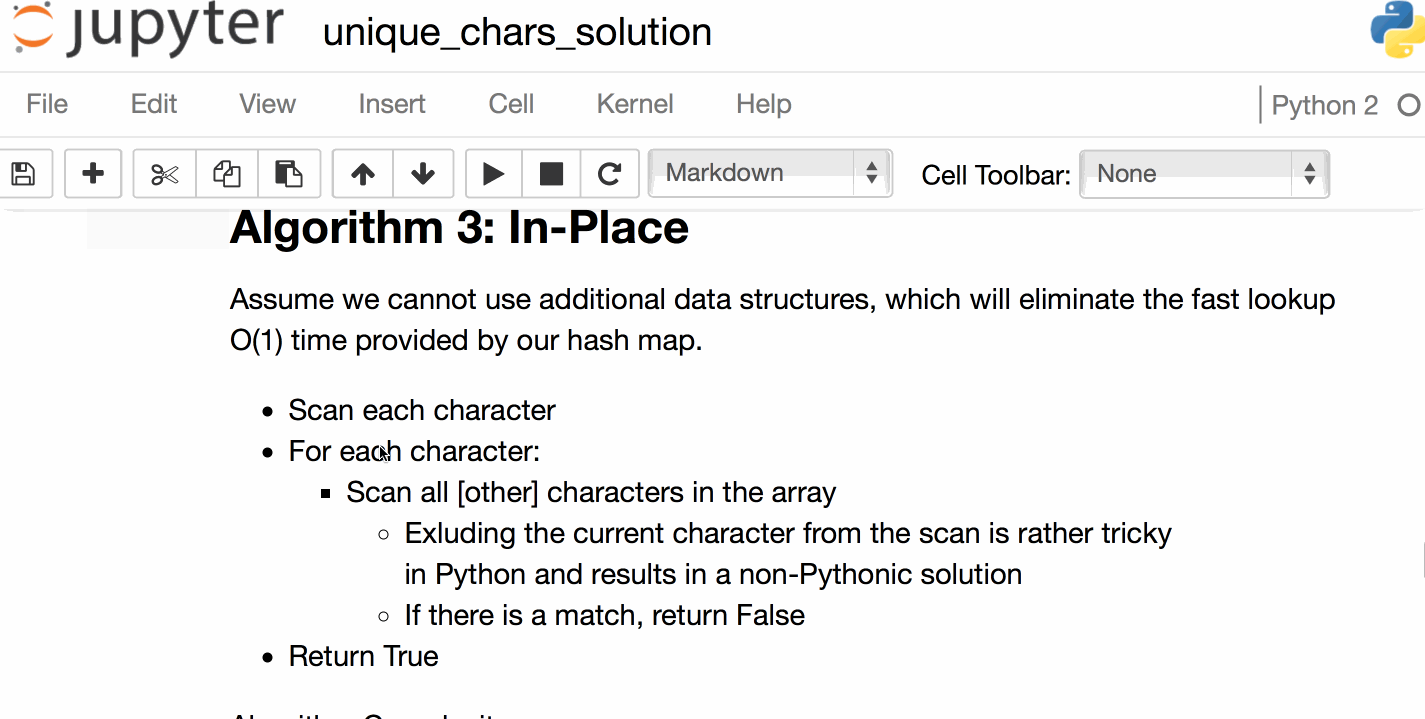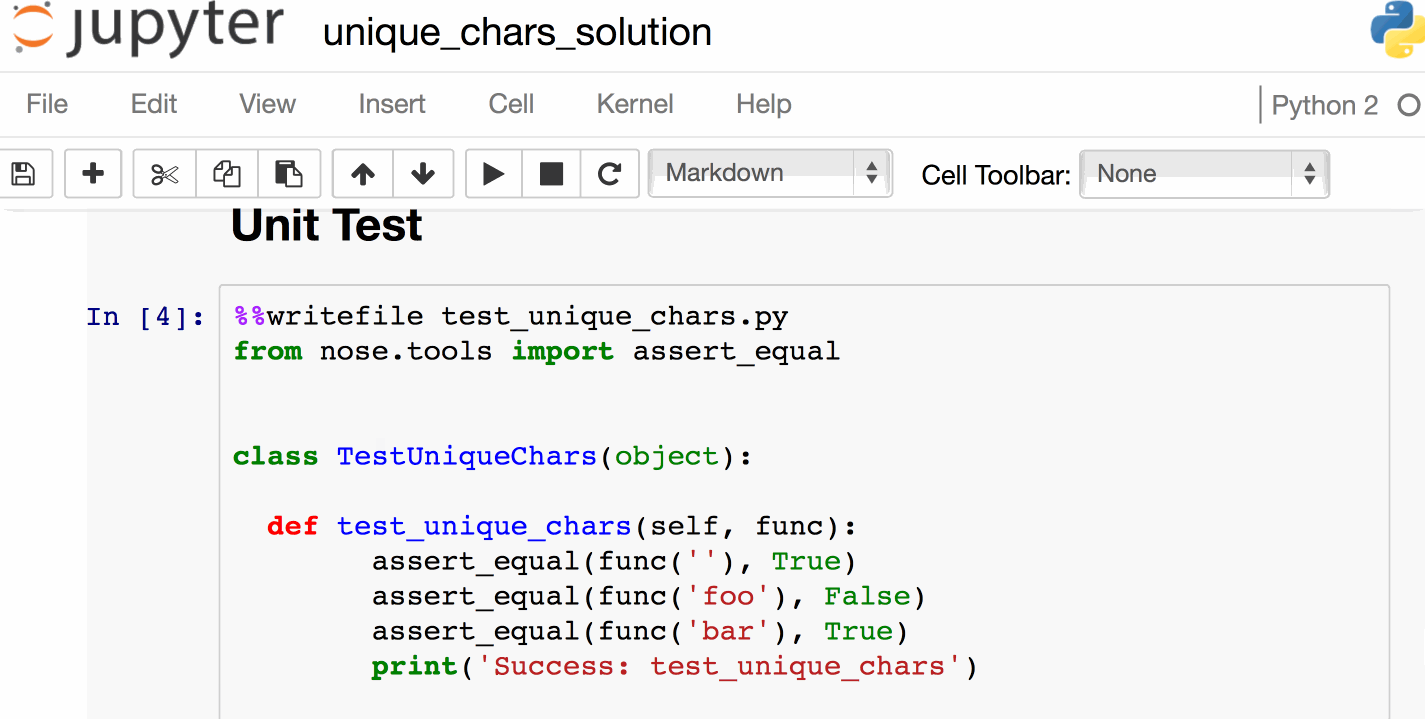
单元测试
- [挑战笔记本]代码的单元测试。预计在你解决挑战之前都会失败
- [解决方案笔记本]参考解决方案的单元测试
索引
挑战类别
格式化:挑战类别-挑战数量
- Arrays and Strings-10
- Linked Lists-8
- Stacks and Queues-8
- Graphs and Trees-21
- Sorting-10
- Recursion and Dynamic Programming-17
- Mathematics and Probability-6
- Bit Manipulation-8
- Online Judges-16
- System Design-8
- Object Oriented Design-8
挑战总数:120项
参考实现:数据结构
以下数据结构经过单元测试、功能齐全的实现:
参考实现:算法
以下算法经过单元测试、功能齐全的实现:
- Selection Sort
- Insertion Sort
- Quick Sort
- Merge Sort
- Radix Sort
- Topological Sort
- Tree Depth-First Search (Pre-, In-, Post-Order)
- Tree Breadth-First Search
- Graph Depth-First Search
- Graph Breadth-First Search
- Dijkstra’s Shortest Path
- Unweighted Graph Shortest Path
- Knapsack 0/1
- Knapsack Unbounded
- Sieve of Eratosthenes
参考实现:TODO
- A*
- Bellman-Ford
- Bloom Filter
- Convex Hull
- Fisher-Yates Shuffle
- Kruskal’s
- Max Flow
- Prim’s
- Rabin-Karp
- Traveling Salesman
- Union Find
- Contribute
安装和运行挑战
杂项
挑战
数组和字符串
| 挑战 | 静电笔记本 |
|---|---|
| 确定字符串是否包含唯一字符 | Challenge│Solution |
| 确定一个字符串是否为另一个字符串的排列 | Challenge│Solution |
| 确定一个字符串是否为另一个字符串的旋转 | Challenge│Solution |
| 压缩字符串 | Challenge│Solution |
| 颠倒字符串中的字符 | Challenge│Solution |
| 给定两个字符串,找到单个不同的字符 | Challenge│Solution |
| 查找两个总和为特定值的索引 | Challenge│Solution |
| 实现哈希表 | Challenge│Solution |
| 实施冒泡嗡嗡声 | Challenge│Solution |
| 查找字符串中的第一个非重复字符 | Contribute│Contribute |
| 删除字符串中的指定字符 | Contribute│Contribute |
| 颠倒字符串中的单词 | Contribute│Contribute |
| 将字符串转换为整数 | Contribute│Contribute |
| 将整数转换为字符串 | Contribute│Contribute |
| 添加质询 | Contribute│Contribute |
![]()

链表
| 挑战 | 静电笔记本 |
|---|---|
| 从链接列表中删除重复项 | Challenge│Solution |
| 查找链表最后一个元素的第k个元素 | Challenge│Solution |
| 删除链表中间的节点 | Challenge│Solution |
| 围绕给定值对链表进行分区 | Challenge│Solution |
| 将数字存储在链表中的两个数字相加 | Challenge│Solution |
| 查找链接列表循环的起点 | Challenge│Solution |
| 确定链表是否为回文 | Challenge│Solution |
| 实现链表 | Challenge│Solution |
| 确定列表是循环的还是非循环的 | Contribute│Contribute |
| 添加质询 | Contribute│Contribute |
堆栈和队列
| 挑战 | 静电笔记本 |
|---|---|
| 使用单个数组实施n个堆栈 | Challenge│Solution |
| 实现跟踪其最小元素的堆栈 | Challenge│Solution |
| 实现包装容量受限堆栈列表的一组Stacks类 | Challenge│Solution |
| 使用两个堆栈实现一个队列 | Challenge│Solution |
| 使用另一个堆栈作为缓冲区对堆栈进行排序 | Challenge│Solution |
| 实现堆栈 | Challenge│Solution |
| 实现一个队列 | Challenge│Solution |
| 实现由数组支持的优先级队列 | Challenge│Solution |
| 添加质询 | Contribute│Contribute |
图形和树
| 挑战 | 静电笔记本 |
|---|---|
| 在树上实现深度优先搜索(前、中、后顺序) | Challenge│Solution |
| 实现树的广度优先搜索 | Challenge│Solution |
| 确定树的高度 | Challenge│Solution |
| 从排序数组创建高度最小的二叉搜索树 | Challenge│Solution |
| 为二叉树的每个级别创建链表 | Challenge│Solution |
| 检查二叉树是否平衡 | Challenge│Solution |
| 确定树是否为有效的二叉搜索树 | Challenge│Solution |
| 在二叉搜索树中查找给定节点的有序后继节点 | Challenge│Solution |
| 查找二叉树中的第二大节点 | Challenge│Solution |
| 找到最底层的共同祖先 | Challenge│Solution |
| 反转二叉树 | Challenge│Solution |
| 实现二叉搜索树 | Challenge│Solution |
| 实现最小堆 | Challenge│Solution |
| 实现Trie | Challenge│Solution |
| 在图上实现深度优先搜索 | Challenge│Solution |
| 实现图的广度优先搜索 | Challenge│Solution |
| 确定图中的两个节点之间是否存在路径 | Challenge│Solution |
| 实现图形 | Challenge│Solution |
| 在给定项目和依赖项列表的情况下查找构建顺序 | Challenge│Solution |
| 在加权图中查找最短路径 | Challenge│Solution |
| 在未加权图中查找最短路径 | Challenge│Solution |
| 添加质询 | Contribute│Contribute |
排序
| 挑战 | 静电笔记本 |
|---|---|
| 实现选择排序 | Challenge│Solution |
| 实现插入排序 | Challenge│Solution |
| 实现快速排序 | Challenge│Solution |
| 实现合并排序 | Challenge│Solution |
| 实现基数排序 | Challenge│Solution |
| 对字符串数组进行排序,以便所有字谜都相邻 | Challenge│Solution |
| 在排序的旋转数组中查找项 | Challenge│Solution |
| 在排序矩阵中搜索项目 | Challenge│Solution |
| 在n个整数的输入中查找不是的整数 | Challenge│Solution |
| 给定排序数组A、B,按排序顺序将B合并到A中 | Challenge│Solution |
| 实现稳定选择排序 | Contribute│Contribute |
| 使不稳定排序稳定 | Contribute│Contribute |
| 实现高效的就地版本的快速排序 | Contribute│Contribute |
| 给定两个排序的数组,按排序顺序将一个合并到另一个 | Contribute│Contribute |
| 在经过旋转和排序的整数数组中查找元素 | Contribute│Contribute |
| 添加质询 | Contribute│Contribute |

递归与动态规划
| 挑战 | 静电笔记本 |
|---|---|
| 递归、动态和迭代地实现Fibonacci | Challenge│Solution |
| 最大化放置在背包中的物品 | Challenge│Solution |
| 最大化放置在背包中的无界项目 | Challenge│Solution |
| 查找最长的公共子序列 | Challenge│Solution |
| 找出最长的递增子序列 | Challenge│Solution |
| 最小化矩阵乘法的成本 | Challenge│Solution |
| 在给定k个交易的情况下最大化股票价格 | Challenge│Solution |
| 在给定一组硬币的情况下,找出表示n美分的最小方法数 | Challenge│Solution |
| 在给定一组硬币的情况下,找出表示n美分的唯一数量的方法 | Challenge│Solution |
| 打印n对括号的所有有效组合 | Challenge│Solution |
| 在迷宫中导航 | Challenge│Solution |
| 打印集合的所有子集 | Challenge│Solution |
| 打印字符串的所有排列 | Challenge│Solution |
| 在数组中查找魔术索引 | Challenge│Solution |
| 找出运行n个步骤的方式的数量 | Challenge│Solution |
| 用3个塔和N个圆盘实现河内之塔 | Challenge│Solution |
| 递归、动态和迭代地实现阶乘 | Contribute│Contribute |
| 对已排序的整数数组执行二进制搜索 | Contribute│Contribute |
| 打印字符串的所有组合 | Contribute│Contribute |
| 实现绘画填充功能 | Contribute│Contribute |
| 给出1、5、10、25美分硬币,找出代表n美分的所有排列 | Contribute│Contribute |
| 添加质询 | Contribute│Contribute |
数学与概率
| 挑战 | 静电笔记本 |
|---|---|
| 生成素数列表 | Challenge│Solution |
| 找到数字根 | Challenge│Solution |
| 在O(1)中创建支持插入、最大、最小、平均、模式的类 | Challenge│Solution |
| 确定一个数字是否为2的幂 | Challenge│Solution |
| 将不带+或-号的两个数字相加 | Challenge│Solution |
| 减去两个不带+或-号的数字 | Challenge│Solution |
| 检查数字是否为质数 | Contribute│Contribute |
| 确定笛卡尔平面上的两条直线是否相交 | Contribute│Contribute |
| 仅使用整数的加法、减法和除法实现乘法、减法和除法 | Contribute│Contribute |
| 找出第k个数,使其唯一的素因数为3、5和7 | Contribute│Contribute |
| 添加质询 | Contribute│Contribute |
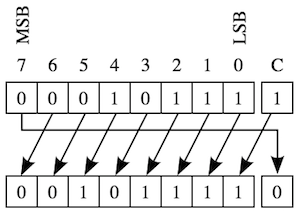
位操作
| 挑战 | 静电笔记本 |
|---|---|
| 实现常见的位操作操作 | Challenge│Solution |
| 确定要翻转以将a转换为b的位数 | Challenge│Solution |
| 在屏幕上画一条线 | Challenge│Solution |
| 翻转一位以最大化最长的1序列 | Challenge│Solution |
| 获取下一个最大和下一个最小的数字 | Challenge│Solution |
| 合并两个二进制数 | Challenge│Solution |
| 交换整数中的奇数位和偶数位 | Challenge│Solution |
| 打印介于0和1之间的数字的二进制表示法 | Challenge│Solution |
| 确定给定整数的二进制表示中的1的个数 | Contribute│Contribute |
| 添加质询 | Contribute│Contribute |
![]()
网上评委
| 挑战 | 静电笔记本 |
|---|---|
| 查找最多包含k个不同字符的最长子字符串 | Challenge│Solution |
| 找出三个数字的最高乘积 | Challenge│Solution |
| 通过1次买入和1次卖出最大化股票利润 | Challenge│Solution |
| 将列表中的所有零移动到末尾 | Challenge│Solution |
| 找出所有其他整数的乘积 | Challenge│Solution |
| 给出进场和出场的列表,找出最繁忙的时段 | Challenge│Solution |
| 确定岛屿的周长 | Challenge│Solution |
| 格式化许可证密钥 | Challenge│Solution |
| 查找最长的绝对文件路径 | Challenge│Solution |
| 合并元组范围 | Challenge│Solution |
| 分配Cookie | Challenge│Solution |
| 确定您是否可以在NIM中获胜 | Challenge│Solution |
| 检查一本杂志是否可能被用来制作赎金字条 | Challenge│Solution |
| 找出一个句子可以在屏幕上显示的次数 | Challenge│Solution |
| 乌托邦之树 | Challenge│Solution |
| 最大化异或 | Challenge│Solution |
| 添加质询 | Contribute│Contribute |
回购结构
interactive-coding-challenges # Repo
├─ arrays_strings # Category of challenges
│ ├─ rotation # Challenge folder
│ │ ├─ rotation_challenge.ipynb # Challenge notebook
│ │ ├─ rotation_solution.ipynb # Solution notebook
│ │ ├─ test_rotation.py # Unit test*
│ ├─ compress
│ │ ├─ compress_challenge.ipynb
│ │ ├─ compress_solution.ipynb
│ │ ├─ test_compress.py
│ ├─ ...
├─ linked_lists
│ ├─ palindrome
│ │ └─ ...
│ ├─ ...
├─ ...
*笔记本(.ipynb)读/写关联的单元测试(.py)文件
笔记本安装
零安装
本自述包含指向以下内容的链接Binder,哪些主机动态笔记本不需要安装的在线回购内容
木星笔记本
运行:
pip install jupyter
有关更优化地设置开发环境的详细说明、脚本和工具,请参阅dev-setup回购
有关笔记本安装的更多详细信息,请按照说明操作here
有关IPython/Jupyter笔记本的更多信息,请访问here
跑步挑战
笔记本电脑
挑战以以下形式提供IPython/Jupyter笔记本电脑一直以来都是使用Python 2.7和Python 3.x进行测试
如果您需要安装IPython/Jupyter笔记本,请参阅Notebook Installation部分
- 本自述包含指向以下内容的链接nbviewer,哪些主机静电笔记本回购的内容
- 中的元素进行交互或修改动态笔记本,请参阅以下说明
运行挑战笔记本:
$ git clone https://github.com/donnemartin/interactive-coding-challenges.git
$ cd interactive-coding-challenges
$ jupyter notebook
这将启动包含质询类别列表的Web浏览器:
- 导航到挑战笔记本你想要解决
- 运行挑战笔记本中的单元格(单元格->全部运行)
- 这将导致预期的单元测试错误
- 解决挑战并验证它是否通过了单元测试
- 查看随附的解决方案笔记本以供进一步讨论
至调试您的PDB解决方案,请参阅以下内容ticket
注意:如果您的解决方案与解决方案笔记本中列出的解决方案不同,请考虑提交Pull请求,以便其他人可以从您的工作中受益。回顾Contributing Guidelines有关详细信息,请参阅
未来发展方向
挑战、解决方案和单元测试以IPython/Jupyter笔记本电脑
- 笔记本目前主要包含Python解决方案(在Python2.7和Python3.x上都进行了测试),但可以进行扩展以包括40+ supported languages
- 回购将是不断更新新的解决方案和挑战
- Contributions欢迎光临!
贡献
欢迎投稿!
回顾Contributing Guidelines有关如何执行以下操作的详细信息,请执行以下操作:
- 提交问题
- 为现有挑战添加解决方案
- 添加新的挑战
学分
资源
- Cracking the Coding Interview|GitHub Solutions
- Programming Interviews Exposed
- The Algorithm Design Manual|Solutions
- CareerCup
- Quora
- HackerRank
- LeetCode
图像
- Arrays and Strings: nltk.org
- Linked Lists: wikipedia.org
- Stacks: wikipedia.org
- Queues: wikipedia.org
- Sorting: wikipedia.org
- Recursion and Dynamic Programming: wikipedia.org
- Graphs and Trees: wikipedia.org
- Mathematics and Probability: wikipedia.org
- Bit Manipulation: wikipedia.org
- Online Judges: topcoder.com
联系信息
请随时与我联系,讨论任何问题、问题或评论
我的联系信息可以在我的GitHub page
许可证
我在开放源码许可下向您提供此存储库中的代码和资源。因为这是我的个人存储库,您获得的我的代码和资源的许可证来自我,而不是我的雇主(Facebook)
Copyright 2015 Donne Martin
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


System-design-primer 学习如何设计大型系统 为系统设计面试做准备
了解如何设计大型系统
为系统设计面试做准备
为系统设计面试做准备
学习如何设计可伸缩的系统将帮助您成为一名更好的工程师
系统设计是一个宽泛的话题。网上有大量关于系统设计原则的资源。
此repo是一个有组织的资源集合,可帮助您了解如何大规模构建系统
编码资源:交互式编码挑战
这是一个不断更新的开放源码项目
欢迎投稿!
步骤1:概述用例、约束和假设
除了对面试进行编码外,系统设计在许多科技公司的技术面试流程中也是必不可少的组成部分
练习常见的系统设计面试问题,并将您的结果与示例解决方案(讨论、代码和图表)进行比较
面试准备的其他主题:
- Study guide
- How to approach a system design interview question
- System design interview questions, with solutions
- Object-oriented design interview questions, with solutions
- Additional system design interview questions
系统设计主题索引
提供的Anki抽认卡套装使用间隔重复来帮助您记住关键的系统设计概念
非常适合在旅途中使用
步骤2:创建高级设计
正在寻找资源来帮助您准备编码面试吗?
请查看姊妹版repo交互式编码挑战,其中包含额外的Anki幻灯片:
学习指导
向社区学习
请随时提交拉取请求以提供帮助:
- Fix errors
- Improve sections
- Add new sections
- Translate
需要润色的内容正在开发中
查看投稿指南
如何处理系统设计面试问题
各种系统设计主题的摘要,包括优缺点。每件事都是权衡的
每个部分都包含指向更深入资源的链接
- System design topics: start here
- Performance vs scalability
- Latency vs throughput
- Availability vs consistency
- Consistency patterns
- Availability patterns
- Domain name system
- Content delivery network
- Load balancer
- Reverse proxy (web server)
- Application layer
- Database
- Cache
- Asynchronism
- Communication
- Security
- Appendix
- Under development
- Credits
- Contact info
- License
系统设计面试问题及解决方案
根据您的面试时间表(短、中、长)建议复习的主题
问:对于面试,我需要知道这里的一切吗?
A:不,你不需要了解这里的一切来准备面试
你在面试中被问到的问题取决于以下变量:
- How much experience you have
- What your technical background is
- What positions you are interviewing for
- Which companies you are interviewing with
- Luck
更有经验的应聘者通常会对系统设计有更多的了解。架构师或团队领导可能会比单个贡献者了解更多。顶级科技公司可能会有一轮或多轮设计面试
从宽泛开始,在几个领域深入研究。它有助于您对各种关键的系统设计主题有所了解。根据您的时间表、经验、您面试的职位以及您面试的公司调整以下指南
- Short timeline – Aim for breadth with system design topics. Practice by solving some interview questions.
- Medium timeline – Aim for breadth and some depth with system design topics. Practice by solving many interview questions.
- Long timeline – Aim for breadth and more depth with system design topics. Practice by solving most interview questions.
| Short | Medium | Long | |
|---|---|---|---|
| Read through the System design topics to get a broad understanding of how systems work | :+1: | :+1: | :+1: |
| Read through a few articles in the Company engineering blogs for the companies you are interviewing with | :+1: | :+1: | :+1: |
| Read through a few Real world architectures | :+1: | :+1: | :+1: |
| Review How to approach a system design interview question | :+1: | :+1: | :+1: |
| Work through System design interview questions with solutions | Some | Many | Most |
| Work through Object-oriented design interview questions with solutions | Some | Many | Most |
| Review Additional system design interview questions | Some | Many | Most |
面向对象的设计面试问题及其解决方案
如何进行撞击系统设计面试题
系统设计面试是一场开放式的谈话。希望你来领导它
您可以使用以下步骤来指导讨论。要帮助巩固此过程,请使用以下步骤完成系统设计面试问题与解决方案部分
步骤3:设计核心组件
收集需求并确定问题范围。提出问题以澄清用例和约束。讨论假设
- Who is going to use it?
- How are they going to use it?
- How many users are there?
- What does the system do?
- What are the inputs and outputs of the system?
- How much data do we expect to handle?
- How many requests per second do we expect?
- What is the expected read to write ratio?
步骤4:调整设计比例
概述包含所有重要组件的高级设计
- Sketch the main components and connections
- Justify your ideas
粗略计算
深入了解每个核心组件的详细信息。例如,如果您被要求设计一个url缩短服务,请讨论:
- Generating and storing a hash of the full url
- Translating a hashed url to the full url
- Database lookup
- API and object-oriented design
来源和进一步阅读
在给定约束的情况下,确定并解决瓶颈问题。例如,您是否需要以下内容来解决可伸缩性问题?
- Load balancer
- Horizontal scaling
- Caching
- Database sharding
讨论潜在的解决方案和权衡。每件事都是权衡的。使用可扩展系统设计原则解决瓶颈问题
Design Pastebin.com(或bit.ly)
你可能会被要求手工做一些估算。有关以下资源,请参阅附录:
- Use back of the envelope calculations
- Powers of two table
- Latency numbers every programmer should know
设计Twitter时间表和搜索(或Facebook提要和搜索)
请查看以下链接,以更好地了解预期内容:
- How to ace a systems design interview
- The system design interview
- Intro to Architecture and Systems Design Interviews
- System design template
系统设计主题:从此处开始
带有示例讨论、代码和图表的常见系统设计面试问题
链接到解决方案/文件夹中内容的解决方案
| Question | |
|---|---|
| Design Pastebin.com (or Bit.ly) | Solution |
| Design the Twitter timeline and search (or Facebook feed and search) | Solution |
| Design a web crawler | Solution |
| Design Mint.com | Solution |
| Design the data structures for a social network | Solution |
| Design a key-value store for a search engine | Solution |
| Design Amazon’s sales ranking by category feature | Solution |
| Design a system that scales to millions of users on AWS | Solution |
| Add a system design question | Contribute |
设计一个网络爬虫程序
查看练习和解决方案
Design Mint.com
查看练习和解决方案
设计社交网络的数据结构
查看练习和解决方案
为搜索引擎设计键值存储
查看练习和解决方案
按类别功能设计亚马逊的销售排名
查看练习和解决方案
设计可扩展到数百万AWS用户的系统
查看练习和解决方案
第1步:复习可扩展性视频课程
查看练习和解决方案
步骤2:查看可伸缩性文章
查看练习和解决方案
性能与可扩展性
常见的面向对象设计面试问题,带有示例讨论、代码和图表
注:此部分正在开发中。
是系统设计的新手吗?
| Question | |
|---|---|
| Design a hash map | Solution |
| Design a least recently used cache | Solution |
| Design a call center | Solution |
| Design a deck of cards | Solution |
| Design a parking lot | Solution |
| Design a chat server | Solution |
| Design a circular array | Contribute |
| Add an object-oriented design question | Contribute |
延迟与吞吐量
首先,您需要基本了解通用原则,了解它们是什么、如何使用以及它们的优缺点
哈佛大学可伸缩性讲座
下一步
可扩展性
- Topics covered:
- Vertical scaling
- Horizontal scaling
- Caching
- Load balancing
- Database replication
- Database partitioning
盖子定理
接下来,我们来看看高级权衡:
- Topics covered:
弱一致性
请记住,每件事都是权衡的。
- Performance vs scalability
- Latency vs throughput
- Availability vs consistency
然后,我们将深入探讨更具体的主题,如DNS、CDN和负载均衡器
如果服务以与添加的资源成正比的方式提高性能,则该服务是可伸缩的。通常,提高性能意味着服务更多的工作单元,但也可以处理更大的工作单元,例如当数据集增长时。1
可用性与一致性
看待性能与可伸缩性的另一种方式:
延迟是执行某种操作或产生某种结果的时间
- If you have a performance problem, your system is slow for a single user.
- If you have a scalability problem, your system is fast for a single user but slow under heavy load.
最终一致性
一致性模式
吞吐量是每单位时间内此类操作或结果的数量
通常,您应该以具有可接受延迟的最大吞吐量为目标
资料来源:复习上限定理
强一致性
可用性模式
故障转移
在分布式计算机系统中,您只能支持以下两项保证:
网络不可靠,因此您需要支持分区容错。您需要在一致性和可用性之间进行软件权衡
- Consistency – Every read receives the most recent write or an error
- Availability – Every request receives a response, without guarantee that it contains the most recent version of the information
- Partition Tolerance – The system continues to operate despite arbitrary partitioning due to network failures
等待来自分区节点的响应可能会导致超时错误。如果您的业务需求需要原子读写,CP是一个很好的选择
SQL调优
响应返回任何节点上可用的最容易获得的数据版本,该版本可能不是最新版本。在解析分区时,写入可能需要一些时间才能传播
键值存储
如果业务需要考虑到最终的一致性,或者当系统需要在出现外部错误的情况下继续工作时,AP是一个很好的选择
对于同一数据的多个副本,我们面临着如何对它们进行同步操作的选择,以便客户对数据有一致的看法。回想一下CAP定理中的一致性定义-每次读取都会收到最近的写入或错误
缺点:故障转移
域名系统
写入后,读取可能会也可能看不到它。采取了尽力而为的方法
复制
这种方法可以在memcached等系统中看到。弱一致性适用于VoIP、视频聊天和实时多人游戏等实时用例。例如,如果您正在打电话,并且在几秒钟内失去接收,那么当您重新连接时,您听不到在连接中断期间所说的话
写入之后,读取最终会看到它(通常在毫秒内)。异步复制数据
数量上的可用性
在DNS和电子邮件等系统中可以看到这种方法。最终一致性在高可用性系统中运行良好
写入后,Reads将看到它。同步复制数据
缺点:DNS
这种方法可以在文件系统和RDBMS中看到。强一致性在需要事务的系统中运行良好
支持高可用性有两种互补模式:故障切换和复制
推流CDN
内容交付网络
使用主动-被动故障转移时,会在处于备用状态的主动服务器和被动服务器之间发送心跳。如果心跳中断,被动服务器将接管主动服务器的IP地址并恢复服务
拉取CDN
文档存储
停机时间的长短取决于被动服务器是否已经在“热”待机状态下运行,或者它是否需要从“冷”待机状态启动。只有活动服务器才能处理流量
主动-被动故障切换也可以称为主-从故障切换
在主动-主动模式下,两台服务器都在管理流量,在它们之间分担负载
宽列存储
如果服务器是面向公众的,则DNS需要知道两个服务器的公共IP。如果服务器是面向内部的,则应用程序逻辑需要了解这两个服务器
主动-主动故障切换也可以称为主-主故障切换
此主题将在数据库部分进一步讨论:
劣势:CDN
- Fail-over adds more hardware and additional complexity.
- There is a potential for loss of data if the active system fails before any newly written data can be replicated to the passive.
第4层负载均衡
图形数据库
可用性通常通过正常运行时间(或停机时间)作为服务可用时间的百分比来量化。可用性通常用数字9来衡量–99.99%可用性的服务被描述为有四个9
第7层负载均衡
如果服务由多个容易发生故障的组件组成,则服务的总体可用性取决于这些组件是顺序的还是并行的
来源和进一步阅读:NoSQL
| Duration | Acceptable downtime |
|---|---|
| Downtime per year | 8h 45min 57s |
| Downtime per month | 43m 49.7s |
| Downtime per week | 10m 4.8s |
| Downtime per day | 1m 26.4s |
后备缓存
| Duration | Acceptable downtime |
|---|---|
| Downtime per year | 52min 35.7s |
| Downtime per month | 4m 23s |
| Downtime per week | 1m 5s |
| Downtime per day | 8.6s |
直写
当两个可用性<100%的组件按顺序排列时,总体可用性会降低:
In sequence
如果Foo和Bar都有99.9%的可用性,那么它们的总可用性依次为99.8%
Availability (Total) = Availability (Foo) * Availability (Bar)
当两个可用性<100%的组件并行时,总体可用性会提高:
In parallel
如果Foo和BAR都有99.9%的可用性,那么它们并行的总可用性将是99.9999%
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
来源:DNS安全演示
负载均衡器
域名系统(DNS)将域名(如www.example.com)转换为IP地址
DNS是分层的,顶层有几个权威服务器。您的路由器或ISP提供有关执行查找时联系哪些DNS服务器的信息。较低级别的DNS服务器缓存映射,这些映射可能会因DNS传播延迟而变得陈旧。您的浏览器或操作系统还可以将DNS结果缓存一段时间,具体取决于生存时间(TTL)
CloudFlare和Route 53等服务提供托管DNS服务。某些DNS服务可以通过各种方法路由流量:
- NS record (name server) – Specifies the DNS servers for your domain/subdomain.
- MX record (mail exchange) – Specifies the mail servers for accepting messages.
- A record (address) – Points a name to an IP address.
- CNAME (canonical) – Points a name to another name or
CNAME(example.com to www.example.com) or to anArecord.
来源:为什么使用CDN
- Weighted round robin
- Prevent traffic from going to servers under maintenance
- Balance between varying cluster sizes
- A/B testing
- Latency-based
- Geolocation-based
水平缩放
- Accessing a DNS server introduces a slight delay, although mitigated by caching described above.
- DNS server management could be complex and is generally managed by governments, ISPs, and large companies.
- DNS services have recently come under DDoS attack, preventing users from accessing websites such as Twitter without knowing Twitter’s IP address(es).
缺点:负载均衡器
反向代理(Web服务器)
内容递送网络(CDN)是全球分布的代理服务器网络,提供来自更靠近用户的位置的内容。一般情况下,静电文件(如html/css/js)、照片和视频都是由云服务提供的,但有些云服务(如亚马逊的云前端)支持动态内容。站点的DNS解析将告诉客户端要联系哪个服务器
从CDN提供内容可以通过两种方式显著提高性能:
每当您的服务器发生更改时,推送CDN都会接收新内容。您负责提供内容、直接上传到CDN、重写指向CDN的URL。您可以配置内容何时过期以及何时更新。只有在内容是新的或更改的情况下才会上载内容,从而最大限度地减少流量,但最大限度地提高存储
- Users receive content from data centers close to them
- Your servers do not have to serve requests that the CDN fulfills
负载均衡器与反向代理
流量较小的站点或内容不经常更新的站点可以很好地使用推送CDN。内容只放在CDN上一次,而不是定期重新拉取
拉取CDN在第一个用户请求内容时从您的服务器抓取新内容。您将内容保留在服务器上,并重写URL以指向CDN。这会导致请求速度变慢,直到内容缓存在CDN上
缺点:反向代理
生存时间(TTL)确定缓存内容的时间长度。拉取CDN最大限度地减少了CDN上的存储空间,但如果文件过期并在实际更改之前被拉取,则可能会产生冗余流量
流量大的站点可以很好地使用拉式CDN,因为流量分布更均匀,只有最近请求的内容保留在CDN上
来源:可伸缩系统设计模式
微服务
- CDN costs could be significant depending on traffic, although this should be weighed with additional costs you would incur not using a CDN.
- Content might be stale if it is updated before the TTL expires it.
- CDNs require changing URLs for static content to point to the CDN.
服务发现
应用层
负载平衡器将传入的客户端请求分发到应用程序服务器和数据库等计算资源。在每种情况下,负载均衡器都会将来自计算资源的响应返回到相应的客户端。负载均衡器在以下方面有效:
负载均衡器可以通过硬件(昂贵)或软件(如HAProxy)实现
- Preventing requests from going to unhealthy servers
- Preventing overloading resources
- Helping to eliminate a single point of failure
其他优势包括:
为了防止故障,通常在主动-被动或主动-主动模式下设置多个负载均衡器
- SSL termination – Decrypt incoming requests and encrypt server responses so backend servers do not have to perform these potentially expensive operations
- Removes the need to install X.509 certificates on each server
- Session persistence – Issue cookies and route a specific client’s requests to same instance if the web apps do not keep track of sessions
负载均衡器可以根据各种指标路由流量,包括:
第4层负载均衡器查看传输层的信息,以决定如何分发请求。通常,这涉及报头中的源IP地址、目的IP地址和端口,但不涉及数据包的内容。第4层负载均衡器转发进出上游服务器的网络数据包,执行网络地址转换(NAT)
- Random
- Least loaded
- Session/cookies
- Round robin or weighted round robin
- Layer 4
- Layer 7
缺点:应用层
第7层负载均衡器查看应用层以决定如何分发请求。这可能涉及标头、消息和Cookie的内容。第7层负载均衡器终止网络流量,读取消息,做出负载平衡决策,然后打开到所选服务器的连接。例如,第7层负载均衡器可以将视频流量定向到托管视频的服务器,同时将更敏感的用户计费流量定向到经过安全强化的服务器
关系数据库管理系统(RDBMS)
以灵活性为代价,与第7层相比,第4层负载平衡需要更少的时间和计算资源,尽管对现代商用硬件的性能影响可能微乎其微
负载均衡器还可以帮助进行水平扩展,从而提高性能和可用性。与在更昂贵的硬件上纵向扩展单个服务器(称为垂直扩展)相比,使用商用计算机进行横向扩展更具成本效益,并带来更高的可用性。与专门的企业系统相比,在商用硬件上工作的人才也更容易招聘
NoSQL
来源:维基百科
写后(回写)
- Scaling horizontally introduces complexity and involves cloning servers
- Downstream servers such as caches and databases need to handle more simultaneous connections as upstream servers scale out
SQL或NoSQL
- The load balancer can become a performance bottleneck if it does not have enough resources or if it is not configured properly.
- Introducing a load balancer to help eliminate a single point of failure results in increased complexity.
- A single load balancer is a single point of failure, configuring multiple load balancers further increases complexity.
客户端缓存
- NGINX architecture
- HAProxy architecture guide
- Scalability
- Wikipedia
- Layer 4 load balancing
- Layer 7 load balancing
- ELB listener config
数据库
反向代理是集中内部服务并向公众提供统一接口的Web服务器。在反向代理将服务器的响应返回给客户端之前,将来自客户端的请求转发到可以实现该请求的服务器
来源:规模架构系统简介
通过将Web层与应用层(也称为平台层)分开,您可以分别扩展和配置这两个层。添加新API会导致添加应用程序服务器,而不必添加额外的Web服务器。单一责任原则主张共同工作的小型自主服务。拥有小型服务的小型团队可以更积极地规划快速增长
- Increased security – Hide information about backend servers, blacklist IPs, limit number of connections per client
- Increased scalability and flexibility – Clients only see the reverse proxy’s IP, allowing you to scale servers or change their configuration
- SSL termination – Decrypt incoming requests and encrypt server responses so backend servers do not have to perform these potentially expensive operations
- Removes the need to install X.509 certificates on each server
- Compression – Compress server responses
- Caching – Return the response for cached requests
- Static content – Serve static content directly
- HTML/CSS/JS
- Photos
- Videos
- Etc
CDN缓存
- Deploying a load balancer is useful when you have multiple servers. Often, load balancers route traffic to a set of servers serving the same function.
- Reverse proxies can be useful even with just one web server or application server, opening up the benefits described in the previous section.
- Solutions such as NGINX and HAProxy can support both layer 7 reverse proxying and load balancing.
Web服务器缓存
- Introducing a reverse proxy results in increased complexity.
- A single reverse proxy is a single point of failure, configuring multiple reverse proxies (ie a failover) further increases complexity.
数据库缓存
高速缓存
应用程序层中的工作者也有助于启用异步
与此讨论相关的是微服务,可以将其描述为一套可独立部署的小型模块化服务。每个服务都运行一个独特的流程,并通过定义良好的轻量级机制进行通信,以服务于业务目标。1个
例如,Pinterest可以拥有以下微服务:用户档案、追随者、馈送、搜索、照片上传等
应用程序缓存
诸如Consul、etcd和ZooKeeper这样的系统可以通过跟踪注册的名称、地址和端口来帮助服务找到彼此。运行状况检查有助于验证服务完整性,通常使用HTTP端点来完成。Consul和etcd都有一个内置的键值存储,可用于存储配置值和其他共享数据
来源:向上扩展至您的第一个1000万用户
数据库查询级别的高速缓存
像SQL这样的关系数据库是以表形式组织的数据项的集合
对象级别的缓存
- Adding an application layer with loosely coupled services requires a different approach from an architectural, operations, and process viewpoint (vs a monolithic system).
- Microservices can add complexity in terms of deployments and operations.
何时更新缓存
- Intro to architecting systems for scale
- Crack the system design interview
- Service oriented architecture
- Introduction to Zookeeper
- Here’s what you need to know about building microservices
异步
ACID是关系数据库事务的一组属性
缺点:缓存
扩展关系数据库有许多技术:主-从复制、主-主复制、联合、分片、反规范化和SQL调优
主机服务于读取和写入,将写入复制到一个或多个仅服务于读取的从机。从属设备还可以以树状方式复制到其他从属设备。如果主机脱机,系统可以继续以只读模式运行,直到将从属提升为主机或调配新主机
- Atomicity – Each transaction is all or nothing
- Consistency – Any transaction will bring the database from one valid state to another
- Isolation – Executing transactions concurrently has the same results as if the transactions were executed serially
- Durability – Once a transaction has been committed, it will remain so
来源:可伸缩性、可用性、稳定性、模式
提前刷新
两个主机都提供读写服务,并在写入时相互协调。如果任一主机发生故障,系统可以在读取和写入的情况下继续运行
来源:可伸缩性、可用性、稳定性、模式
Disadvantage(s): master-slave replication
- Additional logic is needed to promote a slave to a master.
- See Disadvantage(s): replication for points related to both master-slave and master-master.
来源和进一步阅读:HTTP
来源:向上扩展至您的第一个1000万用户
联合(或功能分区)按功能拆分数据库。例如,您可以拥有三个数据库,而不是一个单一的整体数据库:论坛、用户和产品,从而减少每个数据库的读写流量,从而减少复制延迟。较小的数据库会产生更多可以放入内存的数据,这反过来又会因为改进的高速缓存位置而导致更多的高速缓存命中率。由于没有单个中央主机串行化写入,您可以并行写入,从而增加吞吐量
Disadvantage(s): master-master replication
- You’ll need a load balancer or you’ll need to make changes to your application logic to determine where to write.
- Most master-master systems are either loosely consistent (violating ACID) or have increased write latency due to synchronization.
- Conflict resolution comes more into play as more write nodes are added and as latency increases.
- See Disadvantage(s): replication for points related to both master-slave and master-master.
Disadvantage(s): replication
- There is a potential for loss of data if the master fails before any newly written data can be replicated to other nodes.
- Writes are replayed to the read replicas. If there are a lot of writes, the read replicas can get bogged down with replaying writes and can’t do as many reads.
- The more read slaves, the more you have to replicate, which leads to greater replication lag.
- On some systems, writing to the master can spawn multiple threads to write in parallel, whereas read replicas only support writing sequentially with a single thread.
- Replication adds more hardware and additional complexity.
Source(s) and further reading: replication
来源和进一步阅读:TCP和UDP
来源:可伸缩性、可用性、稳定性、模式
分片将数据分布在不同的数据库中,以便每个数据库只能管理数据的一个子集。以用户数据库为例,随着用户数量的增加,集群中会添加更多的分片
Disadvantage(s): federation
- Federation is not effective if your schema requires huge functions or tables.
- You’ll need to update your application logic to determine which database to read and write.
- Joining data from two databases is more complex with a server link.
- Federation adds more hardware and additional complexity.
Source(s) and further reading: federation
缺点:RPC
与联合的优点类似,分片可以减少读写流量、减少复制和增加缓存命中率。索引大小也会减小,这通常会通过更快的查询提高性能。如果一个碎片发生故障,其他碎片仍可运行,尽管您需要添加某种形式的复制以避免数据丢失。与联合一样,没有单个串行化写入的中央主机,允许您在提高吞吐量的同时并行写入
共享用户表的常见方式是通过用户的姓氏首字母或用户的地理位置
反规格化试图以牺牲一些写入性能为代价来提高读取性能。数据的冗余副本被写入多个表中,以避免昂贵的联接。一些RDBMS(如PostgreSQL和Oracle)支持物化视图,物化视图处理存储冗余信息和保持冗余副本一致的工作
使用联合和分片等技术分发数据后,管理跨数据中心的联接会进一步增加复杂性。反规格化可能会绕过对这种复杂连接的需要。
Disadvantage(s): sharding
- You’ll need to update your application logic to work with shards, which could result in complex SQL queries.
- Data distribution can become lopsided in a shard. For example, a set of power users on a shard could result in increased load to that shard compared to others.
- Rebalancing adds additional complexity. A sharding function based on consistent hashing can reduce the amount of transferred data.
- Joining data from multiple shards is more complex.
- Sharding adds more hardware and additional complexity.
Source(s) and further reading: sharding
劣势:睡觉
在大多数系统中,读取的数量可能远远超过写入的数量100:1甚至1000:1。导致复杂数据库联接的读取可能非常昂贵,会花费大量时间进行磁盘操作
SQL调优是一个涉及面很广的主题,很多书都是作为参考编写的
重要的是要进行基准测试和性能分析,以模拟和发现瓶颈
Disadvantage(s): denormalization
- Data is duplicated.
- Constraints can help redundant copies of information stay in sync, which increases complexity of the database design.
- A denormalized database under heavy write load might perform worse than its normalized counterpart.
Source(s) and further reading: denormalization
来源及进一步阅读:睡觉和rpc
基准测试和性能分析可能会为您提供以下优化
NoSQL是键值存储、文档存储、宽列存储或图形数据库中表示的数据项的集合。数据被反规范化,连接通常在应用程序代码中完成。大多数NoSQL存储缺乏真正的ACID事务,倾向于最终的一致性
- Benchmark – Simulate high-load situations with tools such as ab.
- Profile – Enable tools such as the slow query log to help track performance issues.
BASE通常用来描述NoSQL数据库的属性。与CAP定理相比,BASE选择可用性而不是一致性
Tighten up the schema
- MySQL dumps to disk in contiguous blocks for fast access.
- Use
CHARinstead ofVARCHARfor fixed-length fields.CHAReffectively allows for fast, random access, whereas withVARCHAR, you must find the end of a string before moving onto the next one.
- Use
TEXTfor large blocks of text such as blog posts.TEXTalso allows for boolean searches. Using aTEXTfield results in storing a pointer on disk that is used to locate the text block. - Use
INTfor larger numbers up to 2^32 or 4 billion. - Use
DECIMALfor currency to avoid floating point representation errors. - Avoid storing large
BLOBS, store the location of where to get the object instead. VARCHAR(255)is the largest number of characters that can be counted in an 8 bit number, often maximizing the use of a byte in some RDBMS.- Set the
NOT NULLconstraint where applicable to improve search performance.
Use good indices
- Columns that you are querying (
SELECT,GROUP BY,ORDER BY,JOIN) could be faster with indices. - Indices are usually represented as self-balancing B-tree that keeps data sorted and allows searches, sequential access, insertions, and deletions in logarithmic time.
- Placing an index can keep the data in memory, requiring more space.
- Writes could also be slower since the index also needs to be updated.
- When loading large amounts of data, it might be faster to disable indices, load the data, then rebuild the indices.
Avoid expensive joins
- Denormalize where performance demands it.
Partition tables
- Break up a table by putting hot spots in a separate table to help keep it in memory.
Tune the query cache
- In some cases, the query cache could lead to performance issues.
Source(s) and further reading: SQL tuning
- Tips for optimizing MySQL queries
- Is there a good reason i see VARCHAR(255) used so often?
- How do null values affect performance?
- Slow query log
消息队列
除了在SQL或NoSQL之间进行选择之外,了解哪种类型的NoSQL数据库最适合您的用例也很有帮助。在下一节中,我们将回顾键值存储、文档存储、宽列存储和图形数据库
抽象:哈希表
- Basically available – the system guarantees availability.
- Soft state – the state of the system may change over time, even without input.
- Eventual consistency – the system will become consistent over a period of time, given that the system doesn’t receive input during that period.
键值存储通常允许O(1)次读取和写入,并且通常由内存或SSD支持。数据存储可以按字典顺序维护键,从而允许高效地检索键范围。键值存储可允许存储具有值的元数据
来源和进一步阅读
键值存储提供高性能,通常用于简单数据模型或快速变化的数据,如内存缓存层。由于它们只提供有限的操作集,因此如果需要额外的操作,复杂性将转移到应用层
键值存储是更复杂系统(如文档存储,在某些情况下还包括图形数据库)的基础
抽象:键值存储,文档存储为值
文档存储以文档(XML、JSON、二进制等)为中心,文档存储给定对象的所有信息。文档存储提供基于文档本身的内部结构进行查询的API或查询语言。请注意,许多键值存储包括用于使用值的元数据的功能,从而模糊了这两种存储类型之间的界限
Source(s) and further reading: key-value store
可视化的延迟数字
根据底层实现,文档按集合、标签、元数据或目录进行组织。尽管可以将文档组织或分组在一起,但文档的字段可能彼此完全不同
一些文档存储,如MongoDB和CouchDB,也提供了一种类似SQL的语言来执行复杂的查询。DynamoDB同时支持键值和文档
文档存储具有很高的灵活性,通常用于处理偶尔更改的数据
来源:SQL&NoSQL,简史
抽象:嵌套映射ColumnFamily<RowKey,Columns<ColKey,Value,Timestamp>>
Source(s) and further reading: document store
英语∙日本語∙简体中文∙繁體中文|العَرَبِيَّة∙বাংলা∙葡萄牙语do Brasil∙Deutsch∙ελληνικά∙עברית∙Italiano∙한국어∙فارسی∙Poliano∙русскийязык∙Español∙ภาษาไทย∙Türkçe∙tiếng Việt∙Français|添加翻译
宽列存储的基本数据单位是列(名称/值对)。列可以按列族分组(类似于SQL表)。超级柱族进一步将柱族分组。您可以使用行键单独访问每列,具有相同行键的列形成一行。每个值都包含一个用于版本化和冲突解决的时间戳
Google引入了Bigtable作为第一个宽列存储,它影响了Hadoop生态系统中经常使用的开源HBase,以及Facebook的Cassandra。Bigtable、HBase和Cassandra等存储按字典顺序维护键,从而允许高效地检索选择性键范围
宽列存储提供高可用性和高可伸缩性。它们通常用于非常大的数据集
来源:图表数据库
抽象:图表
Source(s) and further reading: wide column store
网络不可靠,因此您需要支持分区容错。您需要在一致性和可用性之间进行软件权衡
在图形数据库中,每个节点是一条记录,每条弧是两个节点之间的关系。对图形数据库进行了优化,以表示具有多个外键或多对多关系的复杂关系
图形数据库为具有复杂关系的数据模型(如社交网络)提供高性能。它们相对较新,尚未广泛使用;可能更难找到开发工具和资源。很多图表只能通过睡觉API访问
来源:从RDBMS过渡到NoSQL
SQL的原因:
Source(s) and further reading: graph
请注意,许多键值存储包括用于使用值的元数据的功能,从而模糊了这两种存储类型之间的界限
- Explanation of base terminology
- NoSQL databases a survey and decision guidance
- Scalability
- Introduction to NoSQL
- NoSQL patterns
任务队列
使用NoSQL的原因:
非常适合NoSQL的示例数据:
- Structured data
- Strict schema
- Relational data
- Need for complex joins
- Transactions
- Clear patterns for scaling
- More established: developers, community, code, tools, etc
- Lookups by index are very fast
来源:可伸缩系统设计模式
- Semi-structured data
- Dynamic or flexible schema
- Non-relational data
- No need for complex joins
- Store many TB (or PB) of data
- Very data intensive workload
- Very high throughput for IOPS
缓存可以缩短页面加载时间,并可以减少服务器和数据库的负载。在此模型中,调度程序将首先查找以前是否已发出请求,并尝试查找要返回的前一个结果,以便保存实际执行
- Rapid ingest of clickstream and log data
- Leaderboard or scoring data
- Temporary data, such as a shopping cart
- Frequently accessed (‘hot’) tables
- Metadata/lookup tables
Source(s) and further reading: SQL or NoSQL
沟通
数据库通常受益于跨其分区的读和写的统一分布。受欢迎的项目可能会扭曲分布,造成瓶颈。将缓存放在数据库前面有助于吸收不均匀的负载和流量高峰
缓存可以位于客户端(操作系统或浏览器)、服务器端或位于不同的缓存层中
CDN被认为是一种缓存
背压
反向代理和缓存(如varish)可以直接服务于静电和动态内容。Web服务器还可以缓存请求,无需联系应用程序服务器即可返回响应
缺点:异步
您的数据库通常在默认配置中包含某种级别的缓存,针对一般用例进行了优化。针对特定的使用模式调整这些设置可以进一步提高性能
超文本传输协议(HTTP)
内存缓存(如memcached和redis)是应用程序和数据存储之间的键值存储。由于数据保存在RAM中,因此它比数据存储在磁盘上的典型数据库快得多。RAM比磁盘更有限,因此缓存失效算法(如最近最少使用(LRU))可以帮助使“冷”条目无效,并将“热”数据保留在RAM中
传输控制协议(TCP)
Redis具有以下附加功能:
用户数据报协议(UDP)
您可以缓存多个级别,分为两个一般类别:数据库查询和对象:
通常,您应该尽量避免基于文件的缓存,因为这会增加克隆和自动缩放的难度
- Persistence option
- Built-in data structures such as sorted sets and lists
无论何时查询数据库,都要将查询作为键进行散列,并将结果存储到缓存中。此方法存在过期问题:
- Row level
- Query-level
- Fully-formed serializable objects
- Fully-rendered HTML
将数据视为对象,类似于您对应用程序代码所做的操作。让您的应用程序将数据库中的数据集组装成一个类实例或一个或多个数据结构:
远程过程调用(RPC)
缓存内容的建议:
- Hard to delete a cached result with complex queries
- If one piece of data changes such as a table cell, you need to delete all cached queries that might include the changed cell
表述性状态转移(睡觉)
由于您只能在缓存中存储有限数量的数据,因此您需要确定哪种缓存更新策略最适合您的用例
- Remove the object from cache if its underlying data has changed
- Allows for asynchronous processing: workers assemble objects by consuming the latest cached object
来源:从缓存到内存中数据网格
- User sessions
- Fully rendered web pages
- Activity streams
- User graph data
远程过程调用与睡觉调用比较
应用程序负责从存储中读取和写入。缓存不直接与存储交互。应用程序执行以下操作:
我在开放源码许可下向您提供此存储库中的代码和资源。因为这是我的个人存储库,您获得的我的代码和资源的许可证来自我,而不是我的雇主(Facebook)
memcached通常以这种方式使用
后续读取添加到高速缓存的数据速度很快。侧缓存也称为惰性加载。仅缓存请求的数据,从而避免使用未请求的数据填满缓存
- Look for entry in cache, resulting in a cache miss
- Load entry from the database
- Add entry to cache
- Return entry
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return user
来源:可伸缩性、可用性、稳定性、模式
应用程序使用高速缓存作为主数据存储,对其进行读写数据,而高速缓存负责对数据库进行读写:
Disadvantage(s): cache-aside
- Each cache miss results in three trips, which can cause a noticeable delay.
- Data can become stale if it is updated in the database. This issue is mitigated by setting a time-to-live (TTL) which forces an update of the cache entry, or by using write-through.
- When a node fails, it is replaced by a new, empty node, increasing latency.
Write-through
应用程序代码:
缓存代码:
- Application adds/updates entry in cache
- Cache synchronously writes entry to data store
- Return
由于写入操作,直写操作的总体速度较慢,但后续读取刚写入的数据会很快。用户在更新数据时通常比读取数据时更能容忍延迟。缓存中的数据未过时
set_user(12345, {"foo":"bar"})
来源:可伸缩性、可用性、稳定性、模式
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)
在Write-Back中,应用程序执行以下操作:
Disadvantage(s): write through
- When a new node is created due to failure or scaling, the new node will not cache entries until the entry is updated in the database. Cache-aside in conjunction with write through can mitigate this issue.
- Most data written might never be read, which can be minimized with a TTL.
Write-behind (write-back)
来源:从缓存到内存中数据网格
您可以将缓存配置为在任何最近访问的缓存条目到期之前自动刷新
- Add/update entry in cache
- Asynchronously write entry to the data store, improving write performance
Disadvantage(s): write-behind
- There could be data loss if the cache goes down prior to its contents hitting the data store.
- It is more complex to implement write-behind than it is to implement cache-aside or write-through.
Refresh-ahead
如果缓存可以准确预测将来可能需要哪些项目,则与直读相比,提前刷新可以降低延迟
来源:规模架构系统简介
异步工作流有助于减少代价高昂的操作的请求时间,否则这些操作将以内联方式执行。他们还可以通过提前执行耗时的工作来提供帮助,例如定期聚合数据
Disadvantage(s): refresh-ahead
- Not accurately predicting which items are likely to be needed in the future can result in reduced performance than without refresh-ahead.
二次幂表
- Need to maintain consistency between caches and the source of truth such as the database through cache invalidation.
- Cache invalidation is a difficult problem, there is additional complexity associated with when to update the cache.
- Need to make application changes such as adding Redis or memcached.
每个程序员都应该知道的延迟数字
- From cache to in-memory data grid
- Scalable system design patterns
- Introduction to architecting systems for scale
- Scalability, availability, stability, patterns
- Scalability
- AWS ElastiCache strategies
- Wikipedia
安全性
消息队列接收、保存和传递消息。如果操作速度太慢而无法以内联方式执行,则可以将消息队列与以下工作流结合使用:
用户不会被阻止,作业将在后台处理。在此期间,客户端可能会选择性地进行少量处理,使其看起来好像任务已经完成。例如,如果发布一条tweet,该tweet可以立即发布到您的时间表上,但可能需要一段时间才能真正将您的tweet发送给您的所有追随者
其他系统设计面试问题
Redis作为简单的消息代理很有用,但消息可能会丢失
- An application publishes a job to the queue, then notifies the user of job status
- A worker picks up the job from the queue, processes it, then signals the job is complete
RabbitMQ很流行,但需要您适应‘AMQP’协议并管理您自己的节点
Amazon SQS是托管的,但可能会有很高的延迟,并且可能会传递两次消息
任务队列接收任务及其相关数据,运行它们,然后交付结果。它们可以支持调度,并可用于在后台运行计算密集型作业
芹菜支持调度,并且主要支持python。
现实世界的建筑
如果队列开始显著增长,队列大小可能会大于内存,从而导致缓存未命中、磁盘读取,甚至会降低性能。反压可以通过限制队列大小来提供帮助,从而为队列中已有的作业保持较高的吞吐率和良好的响应时间。一旦队列填满,客户端就会收到服务器繁忙或HTTP 503状态代码,以便稍后重试。客户端可以稍后重试请求,可能会使用指数回退
来源:OSI 7层模型
公司架构
HTTP是一种在客户端和服务器之间编码和传输数据的方法。它是一种请求/响应协议:客户端发出请求,服务器发出响应,其中包含请求的相关内容和完成状态信息。HTTP是独立的,允许请求和响应流经许多执行负载平衡、缓存、加密和压缩的中间路由器和服务器
公司工程博客
- Use cases such as inexpensive calculations and realtime workflows might be better suited for synchronous operations, as introducing queues can add delays and complexity.
CP-一致性和划分容错
- It’s all a numbers game
- Applying back pressure when overloaded
- Little’s law
- What is the difference between a message queue and a task queue?
附录
基本HTTP请求由谓词(方法)和资源(端点)组成。以下是常见的HTTP谓词:
AP-可用性和分区容错
*可以多次调用,没有不同的结果
HTTP是依赖于较低级别协议(如TCP和UDP)的应用层协议
| Verb | Description | Idempotent* | Safe | Cacheable |
|---|---|---|---|---|
| GET | Reads a resource | Yes | Yes | Yes |
| POST | Creates a resource or trigger a process that handles data | No | No | Yes if response contains freshness info |
| PUT | Creates or replace a resource | Yes | No | No |
| PATCH | Partially updates a resource | No | No | Yes if response contains freshness info |
| DELETE | Deletes a resource | Yes | No | No |
来源:如何制作多人游戏
TCP是IP网络上的面向连接的协议。使用握手建立和终止连接。所有发送的数据包都保证按原始顺序到达目的地,并且通过以下方式不会损坏:
Source(s) and further reading: HTTP
主动-被动
如果发送方没有收到正确的响应,它将重新发送数据包。如果存在多个超时,则连接将断开。TCP还实施流量控制和拥塞控制。这些保证会导致延迟,并且通常会导致传输效率低于UDP
为了确保高吞吐量,Web服务器可以保持大量TCP连接处于打开状态,从而导致高内存使用率。在web服务器线程和memcached服务器(比方说)之间具有大量打开的连接可能代价高昂。除了在适用的情况下切换到UDP之外,连接池还可以提供帮助
- Sequence numbers and checksum fields for each packet
- Acknowledgement packets and automatic retransmission
TCP对于要求高可靠性但对时间要求较低的应用程序很有用。一些示例包括Web服务器、数据库信息、SMTP、FTP和SSH
在以下情况下使用UDP上的TCP:
来源:如何制作多人游戏
UDP是无连接的。数据报(类似于数据包)仅在数据报级别得到保证。数据报可能无序到达目的地,也可能根本没有到达目的地。UDP不支持拥塞控制。如果没有TCP支持的保证,UDP通常更有效
- You need all of the data to arrive intact
- You want to automatically make a best estimate use of the network throughput
主动-主动
UDP可以广播,向子网中的所有设备发送数据报。这对于DHCP很有用,因为客户端尚未接收到IP地址,因此阻止了TCP在没有IP地址的情况下流式传输
UDP的可靠性较低,但在VoIP、视频聊天、流和实时多人游戏等实时使用案例中运行良好
在以下情况下使用TCP上的UDP:
来源:破解系统设计访谈
在RPC中,客户端导致过程在不同的地址空间(通常是远程服务器)上执行。该过程的编码就好像它是一个本地过程调用,从客户端程序抽象出如何与服务器通信的细节。远程调用通常比本地调用更慢、更不可靠,因此区分RPC调用和本地调用很有帮助。流行的RPC框架包括Protobuf、Thrift和Avro
- You need the lowest latency
- Late data is worse than loss of data
- You want to implement your own error correction
Source(s) and further reading: TCP and UDP
- Networking for game programming
- Key differences between TCP and UDP protocols
- Difference between TCP and UDP
- Transmission control protocol
- User datagram protocol
- Scaling memcache at Facebook
主-从和主-主
RPC是一种请求-响应协议:
示例RPC调用:
RPC专注于公开行为。RPC通常用于内部通信的性能原因,因为您可以手工创建本地调用以更好地适应您的用例
- Client program – Calls the client stub procedure. The parameters are pushed onto the stack like a local procedure call.
- Client stub procedure – Marshals (packs) procedure id and arguments into a request message.
- Client communication module – OS sends the message from the client to the server.
- Server communication module – OS passes the incoming packets to the server stub procedure.
- Server stub procedure – Unmarshalls the results, calls the server procedure matching the procedure id and passes the given arguments.
- The server response repeats the steps above in reverse order.
在以下情况下选择本机库(也称为SDK):
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
睡觉之后的HTTP接口倾向于更常用于公共接口
睡觉是一种实施客户端/服务器模型的体系结构风格,其中客户端作用于由服务器管理的一组资源。服务器提供资源和动作的表示,这些资源和动作既可以操作资源,也可以获得新的资源表示。所有通信必须是无状态和可缓存的
- You know your target platform.
- You want to control how your “logic” is accessed.
- You want to control how error control happens off your library.
- Performance and end user experience is your primary concern.
REST风格的界面有四个特点:
Disadvantage(s): RPC
- RPC clients become tightly coupled to the service implementation.
- A new API must be defined for every new operation or use case.
- It can be difficult to debug RPC.
- You might not be able to leverage existing technologies out of the box. For example, it might require additional effort to ensure RPC calls are properly cached on caching servers such as Squid.
99.9%可用性-三个9
睡觉调用示例:
睡觉专注于数据曝光。它最大限度地减少了客户端/服务器之间的耦合,通常用于公共HTTPAPI。睡觉使用一种更通用、更统一的方法,通过URI公开资源,通过头部表示,通过GET、POST、PUT、DELETE和PATCH等动词进行操作。由于是无状态的,睡觉非常适合水平伸缩和分区
- Identify resources (URI in HTTP) – use the same URI regardless of any operation.
- Change with representations (Verbs in HTTP) – use verbs, headers, and body.
- Self-descriptive error message (status response in HTTP) – Use status codes, don’t reinvent the wheel.
- HATEOAS (HTML interface for HTTP) – your web service should be fully accessible in a browser.
来源:你真的知道为什么你更喜欢睡觉而不是rpc吗?
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
此部分可能需要一些更新。考虑捐款吧!
Disadvantage(s): REST
- With REST being focused on exposing data, it might not be a good fit if resources are not naturally organized or accessed in a simple hierarchy. For example, returning all updated records from the past hour matching a particular set of events is not easily expressed as a path. With REST, it is likely to be implemented with a combination of URI path, query parameters, and possibly the request body.
- REST typically relies on a few verbs (GET, POST, PUT, DELETE, and PATCH) which sometimes doesn’t fit your use case. For example, moving expired documents to the archive folder might not cleanly fit within these verbs.
- Fetching complicated resources with nested hierarchies requires multiple round trips between the client and server to render single views, e.g. fetching content of a blog entry and the comments on that entry. For mobile applications operating in variable network conditions, these multiple roundtrips are highly undesirable.
- Over time, more fields might be added to an API response and older clients will receive all new data fields, even those that they do not need, as a result, it bloats the payload size and leads to larger latencies.
99.99%可用性-四个9
| Operation | RPC | REST |
|---|---|---|
| Signup | POST /signup | POST /persons |
| Resign | POST /resign { “personid”: “1234” } |
DELETE /persons/1234 |
| Read a person | GET /readPerson?personid=1234 | GET /persons/1234 |
| Read a person’s items list | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Add an item to a person’s items | POST /addItemToUsersItemsList { “personid”: “1234”; “itemid”: “456” } |
POST /persons/1234/items { “itemid”: “456” } |
| Update an item | POST /modifyItem { “itemid”: “456”; “key”: “value” } |
PUT /items/456 { “key”: “value” } |
| Delete an item | POST /removeItem { “itemid”: “456” } |
DELETE /items/456 |
安全是一个广泛的话题。除非你有相当多的经验,有安全背景,或者正在申请一个需要安全知识的职位,否则你可能不需要知道更多的基础知识:
Source(s) and further reading: REST and RPC
- Do you really know why you prefer REST over RPC
- When are RPC-ish approaches more appropriate than REST?
- REST vs JSON-RPC
- Debunking the myths of RPC and REST
- What are the drawbacks of using REST
- Crack the system design interview
- Thrift
- Why REST for internal use and not RPC
正在开发中
有时你会被要求做“粗略”的估算。例如,您可能需要确定从磁盘生成100个图像缩略图需要多长时间,或者一个数据结构需要多少内存。每个程序员都应该知道的两个表的幂和延迟数字是很方便的参考资料
基于以上数字的便捷指标:
- Encrypt in transit and at rest.
- Sanitize all user inputs or any input parameters exposed to user to prevent XSS and SQL injection.
- Use parameterized queries to prevent SQL injection.
- Use the principle of least privilege.
并行可用性与顺序可用性
学分
缺点:水平缩放
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
Source(s) and further reading
主从复制
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
常见的系统设计面试问题,以及有关如何解决每个问题的资源链接
- Read sequentially from HDD at 30 MB/s
- Read sequentially from 1 Gbps Ethernet at 100 MB/s
- Read sequentially from SSD at 1 GB/s
- Read sequentially from main memory at 4 GB/s
- 6-7 world-wide round trips per second
- 2,000 round trips per second within a data center
Latency numbers visualized
有关如何设计真实系统的文章
Source(s) and further reading
- Latency numbers every programmer should know – 1
- Latency numbers every programmer should know – 2
- Designs, lessons, and advice from building large distributed systems
- Software Engineering Advice from Building Large-Scale Distributed Systems
主-主复制
来源:Twitter时间表按规模
| Question | Reference(s) |
|---|---|
| Design a file sync service like Dropbox | youtube.com |
| Design a search engine like Google | queue.acm.org stackexchange.com ardendertat.com stanford.edu |
| Design a scalable web crawler like Google | quora.com |
| Design Google docs | code.google.com neil.fraser.name |
| Design a key-value store like Redis | slideshare.net |
| Design a cache system like Memcached | slideshare.net |
| Design a recommendation system like Amazon’s | hulu.com ijcai13.org |
| Design a tinyurl system like Bitly | n00tc0d3r.blogspot.com |
| Design a chat app like WhatsApp | highscalability.com |
| Design a picture sharing system like Instagram | highscalability.com highscalability.com |
| Design the Facebook news feed function | quora.com quora.com slideshare.net |
| Design the Facebook timeline function | facebook.com highscalability.com |
| Design the Facebook chat function | erlang-factory.com facebook.com |
| Design a graph search function like Facebook’s | facebook.com facebook.com facebook.com |
| Design a content delivery network like CloudFlare | figshare.com |
| Design a trending topic system like Twitter’s | michael-noll.com snikolov .wordpress.com |
| Design a random ID generation system | blog.twitter.com github.com |
| Return the top k requests during a time interval | cs.ucsb.edu wpi.edu |
| Design a system that serves data from multiple data centers | highscalability.com |
| Design an online multiplayer card game | indieflashblog.com buildnewgames.com |
| Design a garbage collection system | stuffwithstuff.com washington.edu |
| Design an API rate limiter | https://stripe.com/blog/ |
| Design a Stock Exchange (like NASDAQ or Binance) | Jane Street Golang Implementation Go Implemenation |
| Add a system design question | Contribute |
联盟
在下面的文章中,不要把重点放在具体的细节上,而是:
您面试的公司的架构
您遇到的问题可能来自同一个域
- Identify shared principles, common technologies, and patterns within these articles
- Study what problems are solved by each component, where it works, where it doesn’t
- Review the lessons learned
| Type | System | Reference(s) |
|---|---|---|
| Data processing | MapReduce – Distributed data processing from Google | research.google.com |
| Data processing | Spark – Distributed data processing from Databricks | slideshare.net |
| Data processing | Storm – Distributed data processing from Twitter | slideshare.net |
| Data store | Bigtable – Distributed column-oriented database from Google | harvard.edu |
| Data store | HBase – Open source implementation of Bigtable | slideshare.net |
| Data store | Cassandra – Distributed column-oriented database from Facebook | slideshare.net |
| Data store | DynamoDB – Document-oriented database from Amazon | harvard.edu |
| Data store | MongoDB – Document-oriented database | slideshare.net |
| Data store | Spanner – Globally-distributed database from Google | research.google.com |
| Data store | Memcached – Distributed memory caching system | slideshare.net |
| Data store | Redis – Distributed memory caching system with persistence and value types | slideshare.net |
| File system | Google File System (GFS) – Distributed file system | research.google.com |
| File system | Hadoop File System (HDFS) – Open source implementation of GFS | apache.org |
| Misc | Chubby – Lock service for loosely-coupled distributed systems from Google | research.google.com |
| Misc | Dapper – Distributed systems tracing infrastructure | research.google.com |
| Misc | Kafka – Pub/sub message queue from LinkedIn | slideshare.net |
| Misc | Zookeeper – Centralized infrastructure and services enabling synchronization | slideshare.net |
| Add an architecture | Contribute |
切分
反规格化
想要添加博客吗?为避免重复工作,请考虑将您的公司博客添加到以下回购中:
有兴趣添加一个部分或帮助完成一个正在进行的部分吗?贡献自己的力量!
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
Source(s) and further reading
在整个回购过程中提供积分和来源
联系信息
特别感谢:
- Distributed computing with MapReduce
- Consistent hashing
- Scatter gather
- Contribute
许可证
请随时与我联系,讨论任何问题、问题或评论
我的联系信息可以在我的GitHub页面上找到
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
了解如何设计大型系统
我在开放源码许可下向您提供此存储库中的代码和资源。因为这是我的个人存储库,您获得的我的代码和资源的许可证来自我,而不是我的雇主(Facebook)
动机
向开源社区学习
Anki抽认卡
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/