明天又双叒叕是一年一度的七夕恋爱节了!
又是一波绝好的机会!恩爱秀起来!
购物车清空!礼物送起来!朋友圈晒起来!
等等! 什么?!
你还没准备好七夕礼物么?
但其实你不知道要送啥?
原来又双叒叕要到了
全民不知道送什么礼物的系列日子了…
哎呦 你们这些
磨人的小(lao)妖(you)精(tiao)!
Python倒是觉得你还可以抢救一下!
说到词云应该不陌生,不知道的童靴往下看
词云,就是把网络文本中出现频率较高的
“关键词”予以视觉上的突出
浏览者只要一眼扫过文本就可以领略其主旨
瞧 这是不是一个有声音、有画面的小爱心~
今天 我们采集情侣们之间的聊天日常
用此制作一份只属于你们的小浪漫!
第一步,我们需要导出自己和对象的数据~
微信的备份功能并不能直接给你导出文本格式,它导出来其实是一种叫sqlite的数据库。如果说用网上流传的方法提取文本数据,iOS则需要下载itunes备份整机,安卓则需要本机的root权限,无论是哪种都非常麻烦,在这里给大家介绍一种不需要整机备份和本机root权限,只导出和对象的聊天数据的方法。
那就是使用安卓模拟器导出,这样既能ios/安卓通用,又能够避免对本机造成不良影响,首先需要用电脑版的微信备份你和你对象的聊天记录。以windows系统为例:
2. 在夜神模拟器中下载微信
3. 使用windows客户端版的微信进行备份,如图左下角

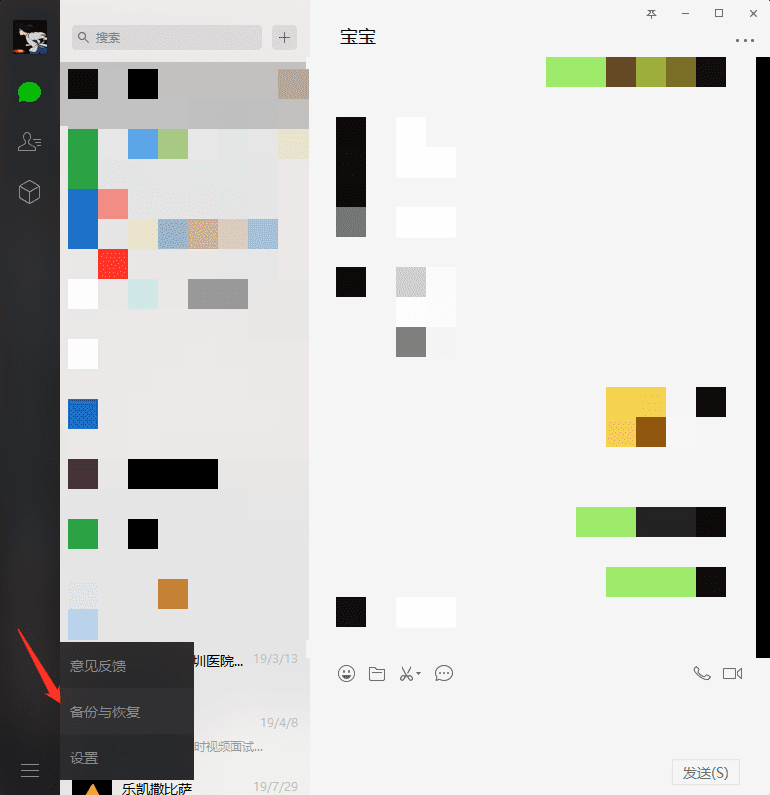
4. 点击备份聊天记录至电脑

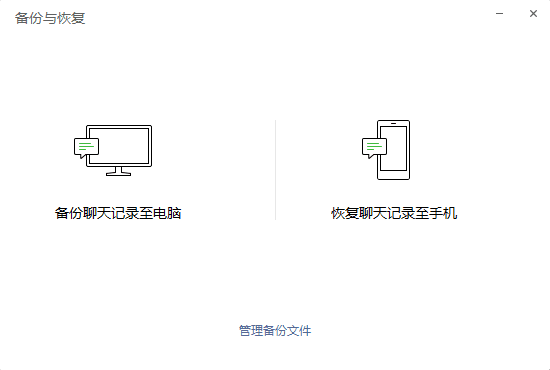
5. 手机端选择备份的对象
点击进入下方的选择聊天记录,然后选择和你对象的记录就可以啦

 选择聊天记录
选择聊天记录
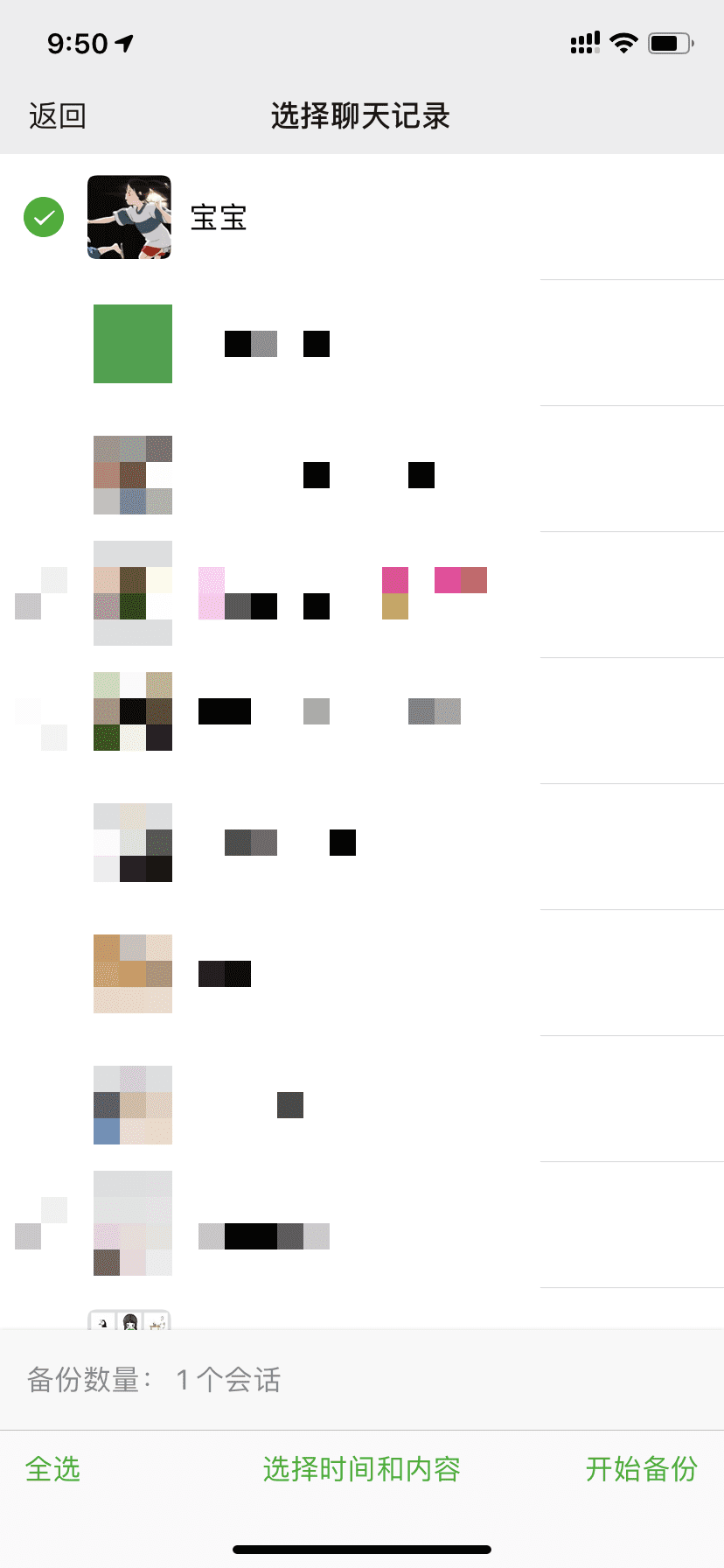 单击你的对象~
单击你的对象~
6. 导出完毕后打开模拟器,登录模拟器的微信

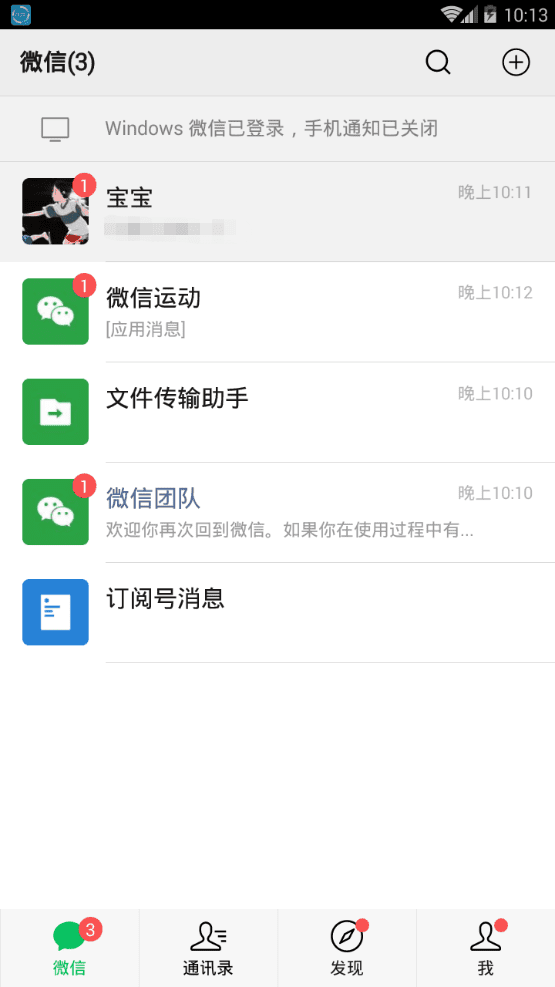 登录成功
登录成功
7. 登录成功后返回电脑版微信登录,打开备份与恢复,选择恢复聊天记录到手机
 备份与恢复
备份与恢复
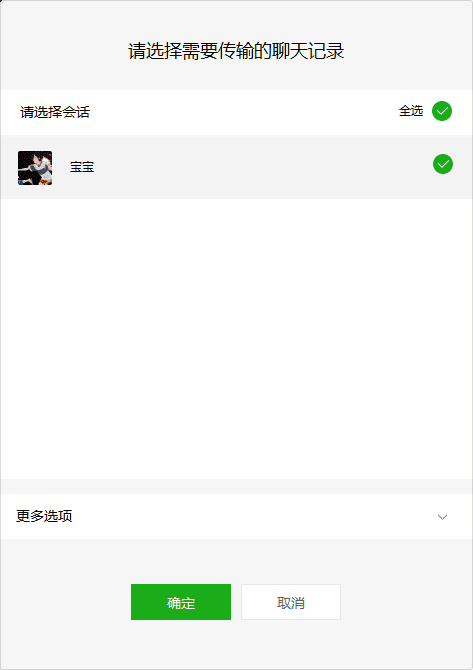
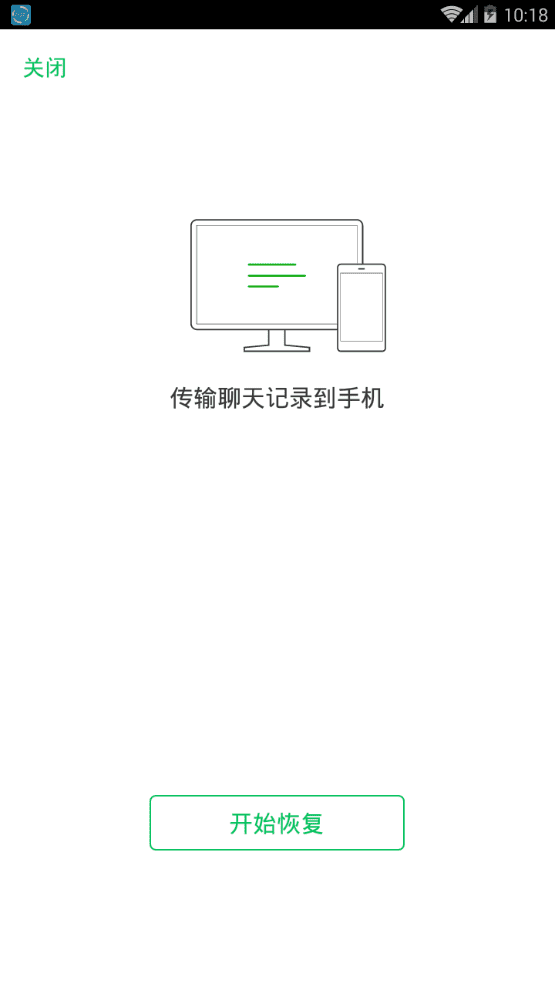
8. 勾选我们刚刚导出的聊天记录,并在手机上点击开始恢复


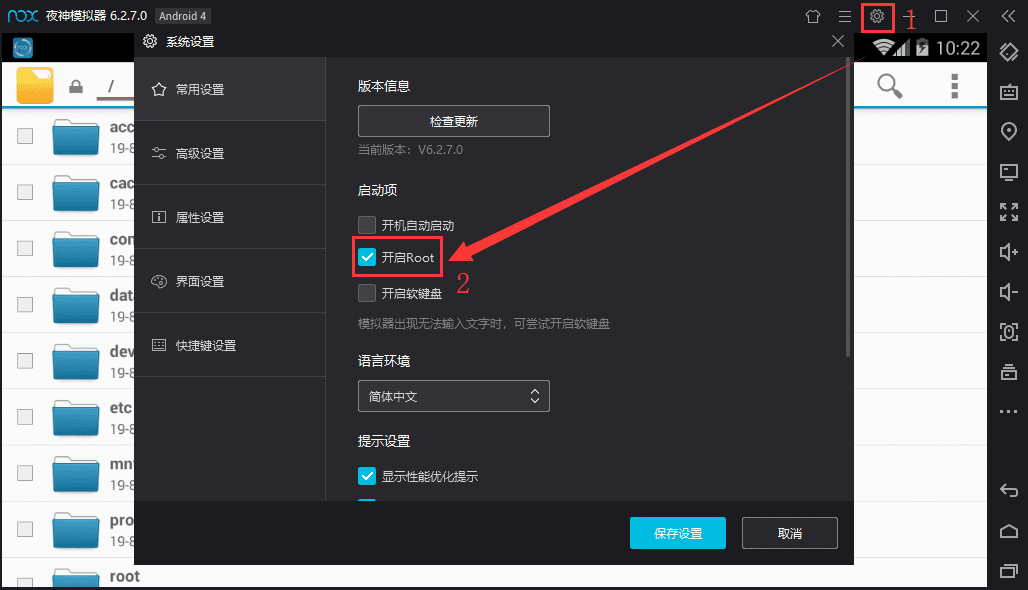
9. 打开夜神模拟器的root权限

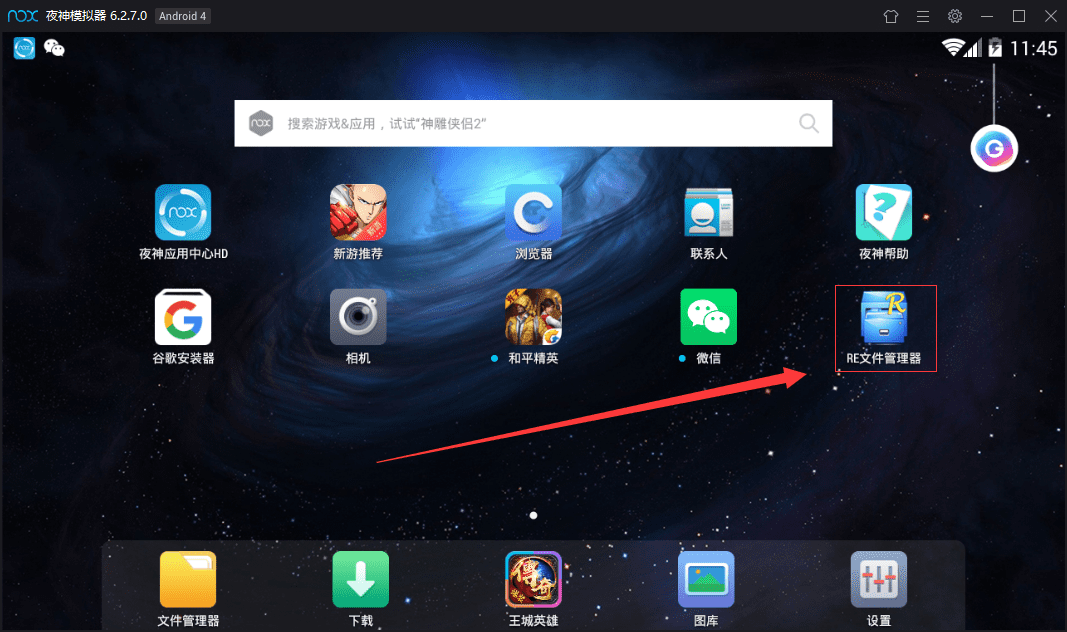
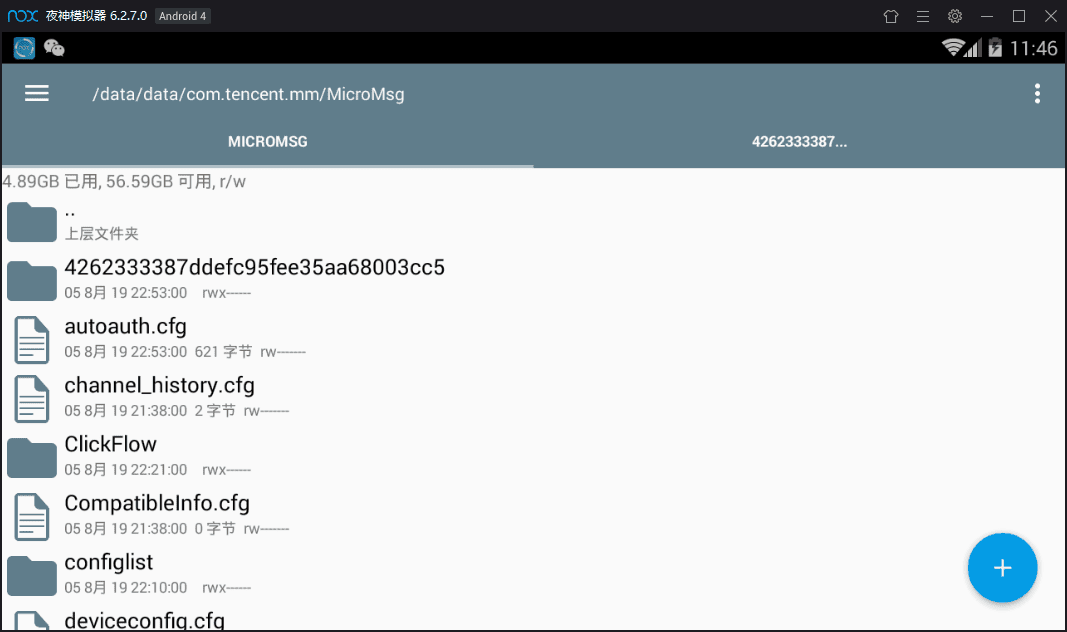
10. 用模拟器的浏览器百度搜索RE文件管理器,下载(图一)安装后打开,会弹出对话框让你给予root权限,选择永久给予,打开RE文件管理器(图二),进入以下文件夹(图三), 这是应用存放数据的地方。
/data/data/com.tencent.mm/MicroMsg

 图一
图一

 图二
图二

 图三
图三
然后进入一个由数字和字母组合而成的文件夹,如上 图三 的 4262333387ddefc95fee35aa68003cc5
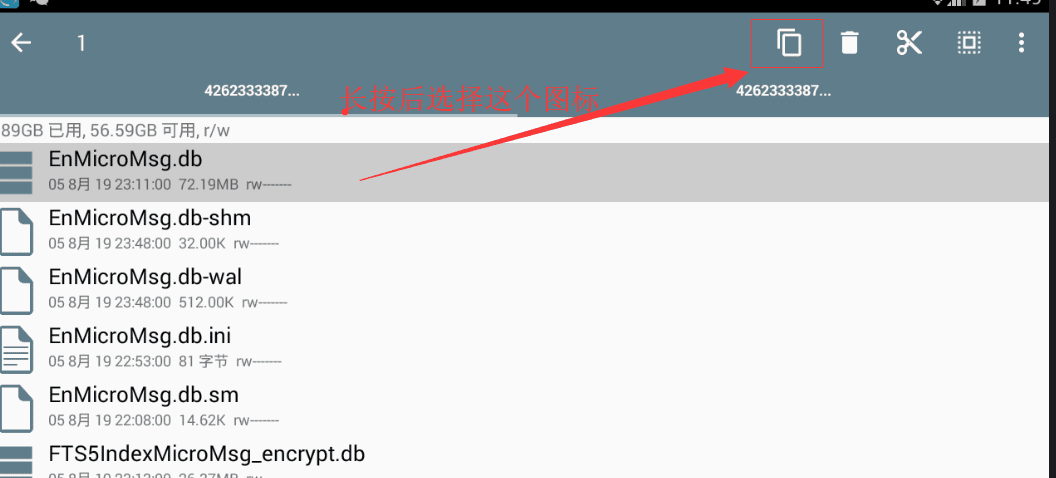
11. 找到该文件夹下的EnMicroMsg.db文件,将其复制到夜神模拟器的共享文件夹(图四)。
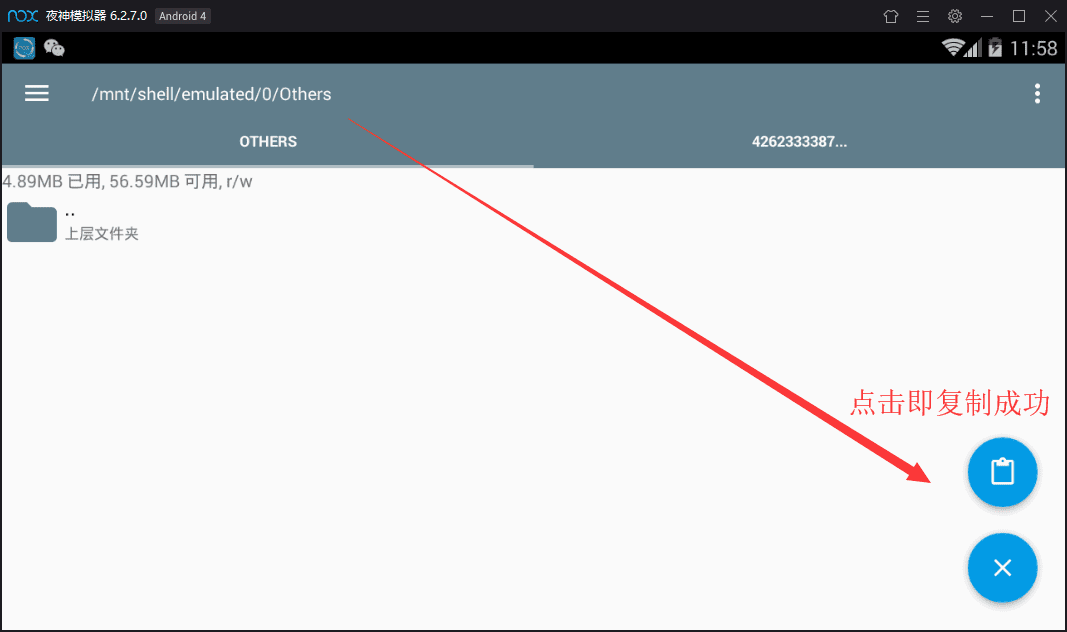
共享文件夹的位置为 /mnt/shell/emulated/0/others ( 图五 ),现在访问windows的 C:\Users\你的用户名\Nox_share\OtherShare 获取该数据库文件( EnMicroMsg.db )

 图四
图四

 图五
图五
在这之前,我们还需要知道该数据库的密码,根据前人的经验,该密码的公式如下
字符串 ” IMEI (手机序列号) UIN(用户信息号)“
将该字符串进行MD5计算后的前七位便是该数据库的密码,如 “355757010761231 857456862” 实际上中间没有空格,然后放入MD5计算取前面七位数字,后续会详细介绍。
哇,真是“简单易懂”啊,没关系,接下来告诉大家IMEI和UIN怎么获得。
首先是IMEI,在模拟器右上角的系统设置 —— 属性设置里就可以找得到啦,如图所示。

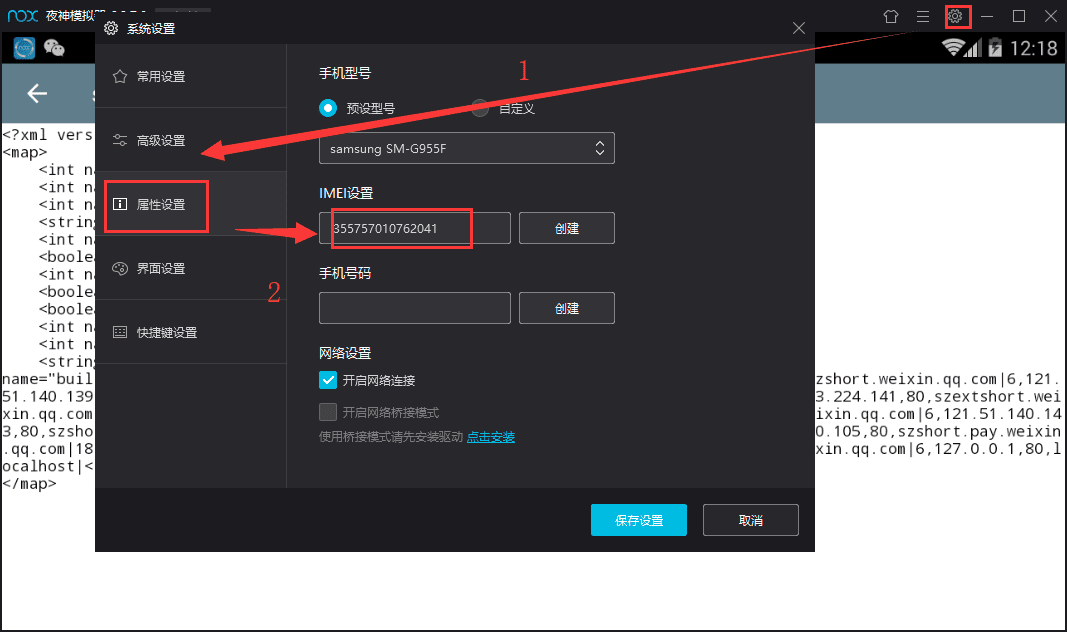 IMEI
IMEI
现在我们获得了IMEI号,那UIN号呢?
同样地,用RE文件管理器打开这个文件
/data/data/com.tencent.mm/shared_prefs/system_config_prefs.xml

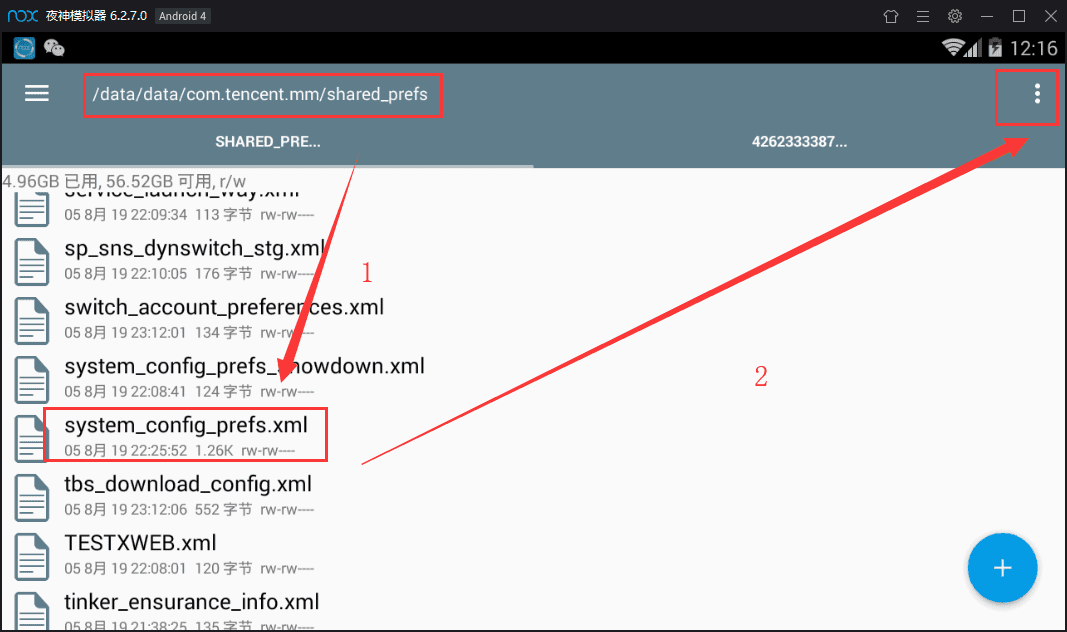
长按改文件,点击右上角的三个点—选择打开方式—文本浏览器,找到default_uin,后面的数字就是了 !

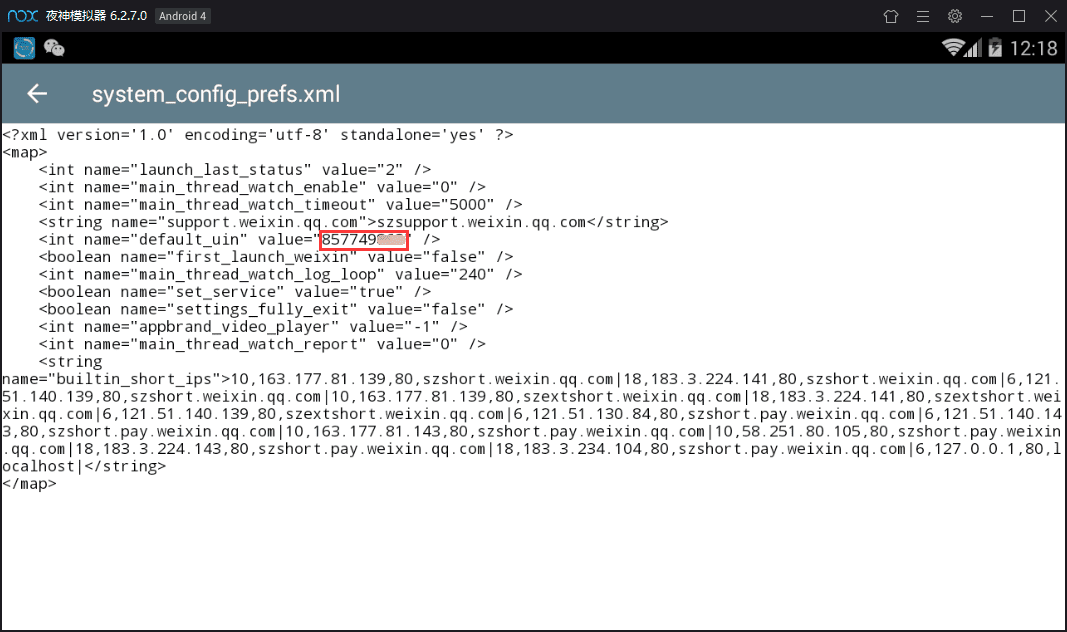
得到这两串数字后,就可以开始计算密码啦,如果我的IMEI是355757010762041,Uin是857749862,那么合起来就是355757010762041857749862,将这串数字放入免费MD5在线计算
得到的数字的前七位就是我们的密码了,像这一串就是 6782538.
如果uin是负的话,可以试试uin拼接手机IMEI码(就是和正的相反,进行拼接),取MD5的32位小写密文前7个字符。再不行就重装模拟器。
然后我们就可以进入我们的核心环节:使用 sqlcipher 导出聊天文本数据!

 sqlcipher
sqlcipher
点击 File – open database – 选择我们刚刚的数据库文件,会弹出框框让你输入密码,我们输入刚刚得到的七位密码,就可以进入到数据库了,选择message表格,这就是你与你的对象的聊天记录!

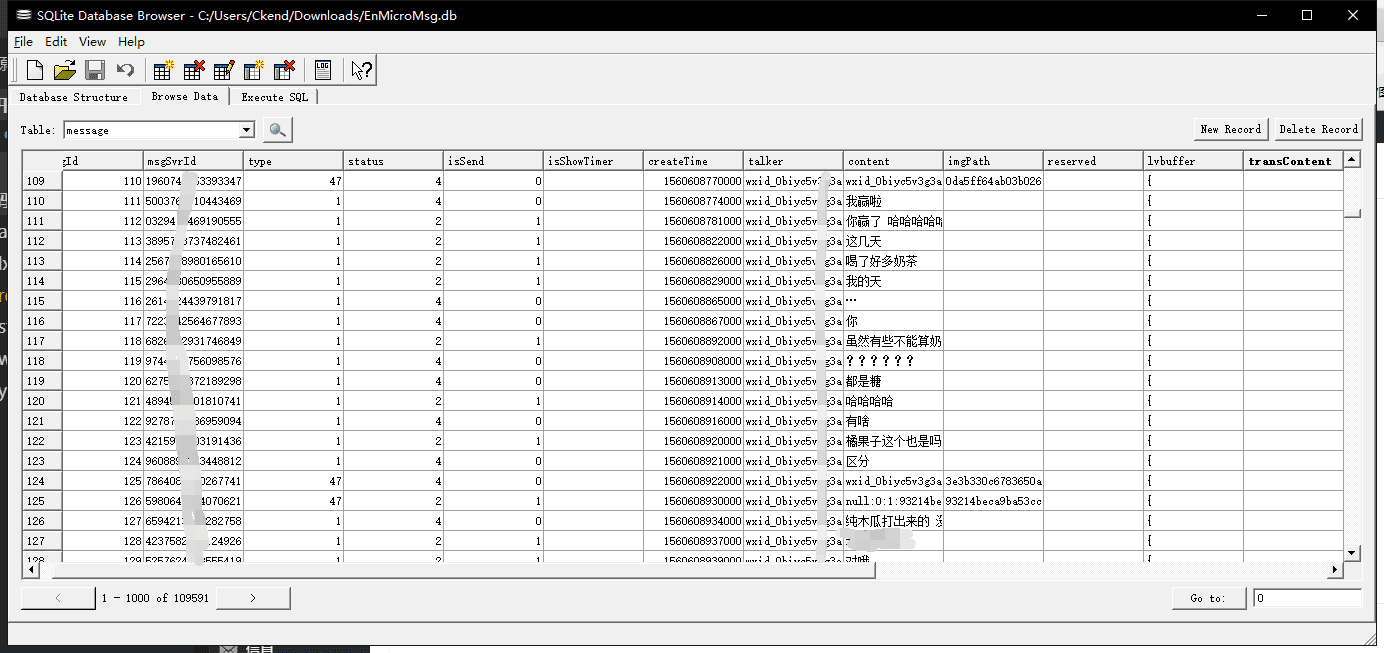
我们可以将它导出成csv文件:File – export – table as csv.
接下来,我们将使用Python代码,将里面真正的聊天内容:content信息提取出来,如下所示。虽然这个软件也允许select,但是它select后不允许导出,非常不好用,因此还不如我们自己写一个:
#!/usr/bin/python
import pandas
import csv, sqlite3
conn= sqlite3.connect('chat_log.db')
# 新建数据库为 chat_log.db
df = pandas.read_csv('chat_logs.csv', sep=",")
# 读取我们上一步提取出来的csv文件,这里要改成你自己的文件名
df.to_sql('my_chat', conn, if_exists='append', index=False)
# 存入my_chat表中
conn = sqlite3.connect('chat_log.db')
# 连接数据库
cursor = conn.cursor()
# 获得游标
cursor.execute('select content from my_chat where length(content)<30')
# 将content长度限定30以下,因为content中有时候会有微信发过来的东西
value=cursor.fetchall()
# fetchall返回筛选结果
data=open("聊天记录.txt",'w+',encoding='utf-8')
for i in value:
data.write(i[0]+'\n')
# 将筛选结果写入 聊天记录.txt
data.close()
cursor.close()
conn.close()
# 关闭连接记得把csv文件的编码格式转换成utf-8哦,不然可能会运行不下去:

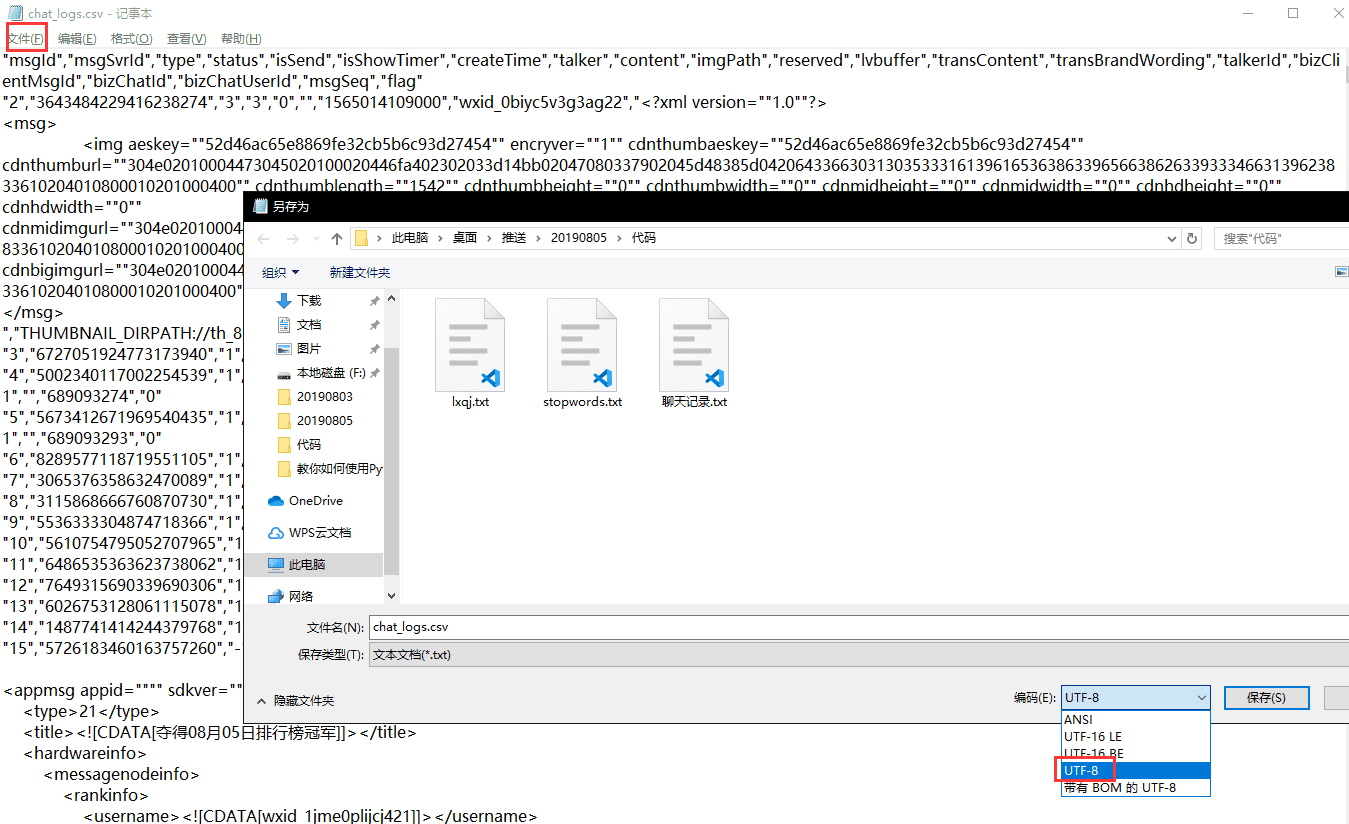 用记事本打开—文件—另存为—编码改为UTF-8即可
用记事本打开—文件—另存为—编码改为UTF-8即可
当然你还可以用正则表达式去除以下内容
- 微信发送的数据:wxid.*
- 表情:\[.*\]
不过我觉得这些也是必要的聊天信息之一,留着也无妨,因此在这里就不加入进去啦,有需要的同学可以阅读这个文档。
最后得到的文本格式就是一行一句聊天内容,处理后我们就准备好进入下一个环节了!那就是令人激动的!生成词云!!
第二步,根据第一步得到的聊天数据生成词云
1. 导入我们的聊天记录,并对每一行进行分词
聊天记录是一行一行的句子,我们需要使用分词工具把这一行行句子分解成由词语组成的数组,这时候我们就需要用到结巴分词了。
分词后我们还需要去除词语里一些语气词、标点符号等等(停用词),然后还要自定义一些词典,比如说你们之间恩恩爱爱的话,一般结巴分词是无法识别出来的,需要你自行定义,比如说:小傻瓜别感冒了,一般分词结果是
小/傻瓜/别/感冒/了
如果你把“小傻瓜”加入到自定义词典里(我们下面的例子里是mywords.txt),则分词结果则会是
小傻瓜/别/感冒/了
下面对我们的聊天记录进行分词:
# segment.py
import jieba
import codecs
def load_file_segment():
# 读取文本文件并分词
jieba.load_userdict("mywords.txt")
# 加载我们自己的词典
f = codecs.open(u"聊天记录.txt",'r',encoding='utf-8')
# 打开文件
content = f.read()
# 读取文件到content中
f.close()
# 关闭文件
segment=[]
# 保存分词结果
segs=jieba.cut(content)
# 对整体进行分词
for seg in segs:
if len(seg) > 1 and seg != '\r\n':
# 如果说分词得到的结果非单字,且不是换行符,则加入到数组中
segment.append(seg)
return segment
print(load_file_segment())在这个函数里,我们使用了codecs打开我们的聊天记录文件,然后进行结巴分词,最终返回一个包含所有词语的数组。记得运行前要安装jieba分词包,默认你已经安装了python3,如果没有请查阅这个文档:安装Python
windows打开CMD/macOS系统打开Terminal 输入:
安装完成后,在编辑器中输入我们刚刚的Python代码,我将其命名为segment.py,切记在同个目录下放置 聊天记录.txt 及 自定义词表 mywords.txt, 然后在CMD/Terminal中输入命令运行
你就可以看见你们的聊天记录分词后的效果啦
2. 计算分词后的词语对应的频数
为了方便计算,我们需要引入一个叫pandas的包,然后为了计算每个词的个数,我们还要引入一个叫numpy的包,cmd/terminal中输入以下命令安装pandas和numpy:
pip install pandas==0.25.1
pip install numpy
详细的解析我都写在下方的注释里啦,大家可以自行阅读并实践。不过需要注意的是,里面的load_file_segment()是我们第一步里的函数,如果你不知道如何把这两个步骤合在一起,没关系,最后我们会提供一份完整的代码.
import pandas
import numpy
def get_words_count_dict():
segment = load_file_segment()
# 获得分词结果
df = pandas.DataFrame({'segment':segment})
# 将分词数组转化为pandas数据结构
stopwords = pandas.read_csv("stopwords.txt",index_col=False,quoting=3,sep="\t",names=['stopword'],encoding="utf-8")
# 加载停用词
df = df[~df.segment.isin(stopwords.stopword)]
# 如果不是在停用词中
words_count = df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
# 按词分组,计算每个词的个数
words_count = words_count.reset_index().sort_values(by="计数",ascending=False)
# reset_index是为了保留segment字段,排序,数字大的在前面
return words_count
print(get_words_count_dict())同第一步一样,运行这份代码你就可以看到每个词语及其对应的频数。需要注意的是,这里有个加载停用词的操作,你需要把停用词表放在当前文件夹下,我们这里提供一份停用词表下载:stopwords.txt
3. 生成词云
终于到了最后一部分啦!你是不是开心而又满怀激动的心情呢(滑稽,在这一步开始之前,我们需要先安装需要使用的包,我们需要用到的包有:
pip install matplot
pip install scipy==1.2.1
pip install wordcloud
打开CMD/Terminal 输入以上命令即可安装,加上之前两个步骤的包,有:
pip install jieba
pip install codecs
pip install pandas==0.25.1
pip install numpy
如果你在安装这些包的时候出现了什么问题,请记得在我们下方评论区提出,我们会一一解答的哦。
运行目录的文件结构如下:
- 聊天记录.txt
- mywords.txt(如果你没有自定义的词的话可以为空)
- stopwords.txt
- wordCloud.py
- ai.jpg (可以为任意的图片,你喜欢就行)
完整代码,wordCloud.py 如下,附有详细的解析(simhei字体可在此下载):
# coding:utf-8
import jieba
import numpy
import codecs
import pandas
import matplotlib.pyplot as plt
from scipy.misc import imread
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
from wordcloud import WordCloud
def load_file_segment():
# 读取文本文件并分词
jieba.load_userdict("mywords.txt")
# 加载我们自己的词典
f = codecs.open(u"聊天记录.txt",'r',encoding='utf-8')
# 打开文件
content = f.read()
# 读取文件到content中
f.close()
# 关闭文件
segment=[]
# 保存分词结果
segs=jieba.cut(content)
# 对整体进行分词
for seg in segs:
if len(seg) > 1 and seg != '\r\n':
# 如果说分词得到的结果非单字,且不是换行符,则加入到数组中
segment.append(seg)
return segment
def get_words_count_dict():
segment = load_file_segment()
# 获得分词结果
df = pandas.DataFrame({'segment':segment})
# 将分词数组转化为pandas数据结构
stopwords = pandas.read_csv("stopwords.txt",index_col=False,quoting=3,sep="\t",names=['stopword'],encoding="utf-8")
# 加载停用词
df = df[~df.segment.isin(stopwords.stopword)]
# 如果不是在停用词中
words_count = df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
# 按词分组,计算每个词的个数
words_count = words_count.reset_index().sort_values(by="计数",ascending=False)
# reset_index是为了保留segment字段,排序,数字大的在前面
return words_count
words_count = get_words_count_dict()
# 获得词语和频数
bimg = imread('ai.jpg')
# 读取我们想要生成词云的模板图片
wordcloud = WordCloud(background_color='white', mask=bimg, font_path='simhei.ttf')
# 获得词云对象,设定词云背景颜色及其图片和字体
# 如果你的背景色是透明的,请用这两条语句替换上面两条
# bimg = imread('ai.png')
# wordcloud = WordCloud(background_color=None, mode='RGBA', mask=bimg, font_path='simhei.ttf')
words = words_count.set_index("segment").to_dict()
# 将词语和频率转为字典
wordcloud = wordcloud.fit_words(words["计数"])
# 将词语及频率映射到词云对象上
bimgColors = ImageColorGenerator(bimg)
# 生成颜色
plt.axis("off")
# 关闭坐标轴
plt.imshow(wordcloud.recolor(color_func=bimgColors))
# 绘色
plt.show()值得注意的是这里面的bimg和wordcloud对象的生成,我们知道png格式背景一般是透明的,因此如果你的图像是png格式的话,其生成词云的时候背景色应该设为None,然后mode应该设为RGBA。
我们还可以控制词云字体的大小和数目的多少,使用下面这两个参数:
max_font_size=60, max_words=3000
将其放入 wordcloud = WordCloud(background_color=’white’, mask=bimg, max_font_size=60, max_words=3000, font_path=’simhei.ttf’) 即可
运行前,确保安装了所有的包,并且当前目录下有我们所需要的所有文件哦
下面就可以用我们的聊天记录,画心型词云啦!!!:
CMD/Terminal 进入代码所在文件夹,运行:python wordcloud.py
得到的图像如下:

 ai.jpg
ai.jpg

 结果
结果








喜欢吗?喜欢就拿去用吧!
怎么样,是不是很好看,如果你想要这些图片的原图做一个属于自己的词云的话,请访问python实用宝典的官网(https://pythondict.com)的置顶文章,或者点击下方阅读原文直达!还有源代码等着你哦!最后,祝大家有情人众人眷属!七夕完美相会!
我们的文章到此结束啦!如果你喜欢我们的文章,持续关注Python实用宝典哦!请记住我们的官方网站:https://pythondict.com , 公众号:python实用宝典。