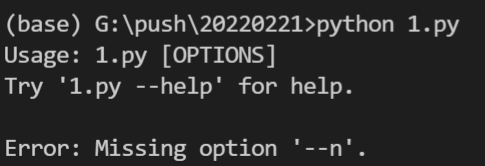
(gs3_9) zjr@sgd-linux-1:~/cnn_test$ asciinema rec first.cast
asciinema: recording asciicast to first.cast
asciinema: press <ctrl-d> or type "exit" when you're done
意思就是日志会被保存在当前文件夹下的first.cast,如果你想结束录制,按 Ctrl + D 即可。
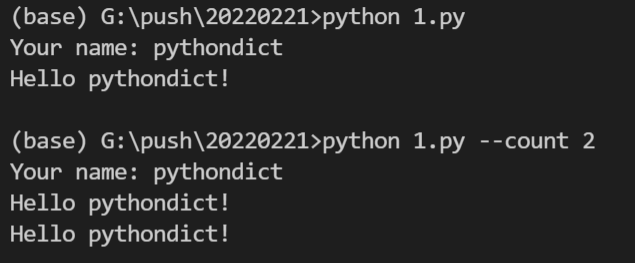
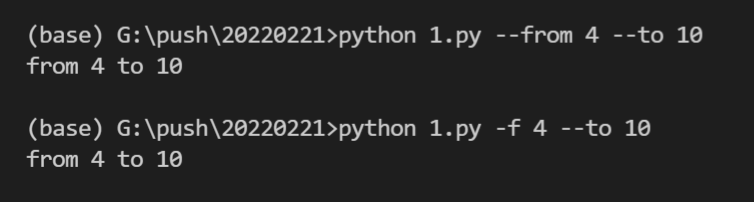
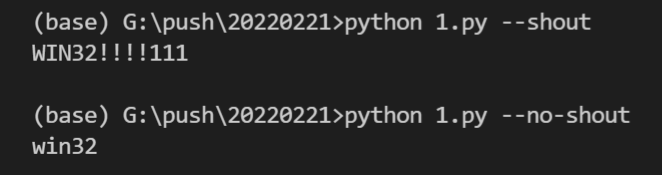
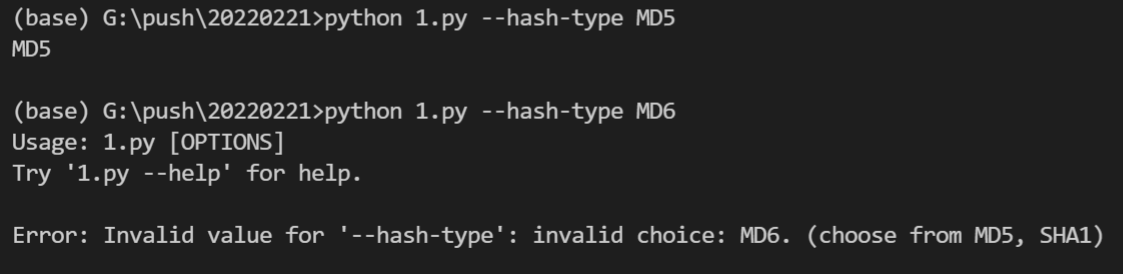
import click
@click.command()
@click.option('--count', default=1, help='Number of greetings.')
@click.option('--name', prompt='Your name',
help='The person to greet.')
def hello(count, name):
"""Simple program that greets NAME for a total of COUNT times."""
for x in range(count):
click.echo(f"Hello {name}!")
if __name__ == '__main__':
hello()
(freqtrade) D:\CODE\trader\freqtrade>freqtrade
2022-02-17 19:40:50,174 - freqtrade - ERROR - Usage of Freqtrade requires a subcommand to be specified.
To have the bot executing trades in live/dry-run modes, depending on the value of the `dry_run` setting in the config, run Freqtrade as `freqtrade trade [options...]`.
To see the full list of options available, please use `freqtrade --help` or `freqtrade <command> --help`.
# pragma pylint: disable=missing-docstring, invalid-name, pointless-string-statement
# flake8: noqa: F401
# isort: skip_file
# --- Do not remove these libs ---
from re import A
import numpy as np # noqa
import pandas as pd # noqa
from pandas import DataFrame
from freqtrade.strategy import (BooleanParameter, CategoricalParameter, DecimalParameter,
IStrategy, IntParameter)
# --------------------------------
# 你自己所需要的模块放在这里
import talib.abstract as ta
import freqtrade.vendor.qtpylib.indicators as qtpylib
# This class is a sample. Feel free to customize it.
class SampleStrategy(IStrategy):
"""
This is a sample strategy to inspire you.
More information in https://www.freqtrade.io/en/latest/strategy-customization/
You can:
:return: a Dataframe with all mandatory indicators for the strategies
- Rename the class name (Do not forget to update class_name)
- Add any methods you want to build your strategy
- Add any lib you need to build your strategy
You must keep:
- the lib in the section "Do not remove these libs"
- the methods: populate_indicators, populate_buy_trend, populate_sell_trend
You should keep:
- timeframe, minimal_roi, stoploss, trailing_*
"""
# Strategy interface version - allow new iterations of the strategy interface.
# Check the documentation or the Sample strategy to get the latest version.
INTERFACE_VERSION = 2
# 设定最小投资回报
minimal_roi = {
"60": 0.01,
"30": 0.02,
"0": 0.04
}
# 止损
stoploss = -0.10
# 指标参数
buy_rsi = IntParameter(low=1, high=50, default=30, space='buy', optimize=True, load=True)
sell_rsi = IntParameter(low=50, high=100, default=70, space='sell', optimize=True, load=True)
# K线时间
timeframe = '5m'
# 在新K线出现时执行
process_only_new_candles = False
# These values can be overridden in the "ask_strategy" section in the config.
use_sell_signal = True
sell_profit_only = False
ignore_roi_if_buy_signal = False
# 预准备K线数
startup_candle_count: int = 30
# 下单类型
order_types = {
'buy': 'limit',
'sell': 'limit',
'stoploss': 'market',
'stoploss_on_exchange': False
}
# 订单有效时间(gtc: 除非取消否则一直有效)
order_time_in_force = {
'buy': 'gtc',
'sell': 'gtc'
}
plot_config = {
'main_plot': {
'tema': {},
'sar': {'color': 'white'},
},
'subplots': {
"MACD": {
'macd': {'color': 'blue'},
'macdsignal': {'color': 'orange'},
},
"RSI": {
'rsi': {'color': 'red'},
}
}
}
def informative_pairs(self):
"""
Define additional, informative pair/interval combinations to be cached from the exchange.
These pair/interval combinations are non-tradeable, unless they are part
of the whitelist as well.
For more information, please consult the documentation
:return: List of tuples in the format (pair, interval)
Sample: return [("ETH/USDT", "5m"),
("BTC/USDT", "15m"),
]
"""
return []
def populate_indicators(self, dataframe: DataFrame, metadata: dict) -> DataFrame:
"""
Adds several different TA indicators to the given DataFrame
Performance Note: For the best performance be frugal on the number of indicators
you are using. Let uncomment only the indicator you are using in your strategies
or your hyperopt configuration, otherwise you will waste your memory and CPU usage.
:param dataframe: Dataframe with data from the exchange
:param metadata: Additional information, like the currently traded pair
:return: a Dataframe with all mandatory indicators for the strategies
"""
# Momentum Indicators
# ------------------------------------
dataframe['adx'] = ta.ADX(dataframe)
dataframe['rsi'] = ta.RSI(dataframe)
stoch_fast = ta.STOCHF(dataframe)
dataframe['fastd'] = stoch_fast['fastd']
dataframe['fastk'] = stoch_fast['fastk']
# MACD
macd = ta.MACD(dataframe)
dataframe['macd'] = macd['macd']
dataframe['macdsignal'] = macd['macdsignal']
dataframe['macdhist'] = macd['macdhist']
# MFI
dataframe['mfi'] = ta.MFI(dataframe)
# Bollinger Bands
bollinger = qtpylib.bollinger_bands(qtpylib.typical_price(dataframe), window=20, stds=2)
dataframe['bb_lowerband'] = bollinger['lower']
dataframe['bb_middleband'] = bollinger['mid']
dataframe['bb_upperband'] = bollinger['upper']
dataframe["bb_percent"] = (
(dataframe["close"] - dataframe["bb_lowerband"]) /
(dataframe["bb_upperband"] - dataframe["bb_lowerband"])
)
dataframe["bb_width"] = (
(dataframe["bb_upperband"] - dataframe["bb_lowerband"]) / dataframe["bb_middleband"]
)
# Parabolic SAR
dataframe['sar'] = ta.SAR(dataframe)
# TEMA - Triple Exponential Moving Average
dataframe['tema'] = ta.TEMA(dataframe, timeperiod=9)
hilbert = ta.HT_SINE(dataframe)
dataframe['htsine'] = hilbert['sine']
dataframe['htleadsine'] = hilbert['leadsine']
return dataframe
def populate_buy_trend(self, dataframe: DataFrame, metadata: dict) -> DataFrame:
"""
Based on TA indicators, populates the buy signal for the given dataframe
:param dataframe: DataFrame populated with indicators
:param metadata: Additional information, like the currently traded pair
:return: DataFrame with buy column
"""
dataframe.loc[
(
# Signal: RSI crosses above 30
(qtpylib.crossed_above(dataframe['rsi'], self.buy_rsi.value)) &
(dataframe['tema'] <= dataframe['bb_middleband']) & # Guard: tema below BB middle
(dataframe['tema'] > dataframe['tema'].shift(1)) & # Guard: tema is raising
(dataframe['volume'] > 0) # Make sure Volume is not 0
), 'buy'] = 1
return dataframe
def populate_sell_trend(self, dataframe: DataFrame, metadata: dict) -> DataFrame:
"""
Based on TA indicators, populates the sell signal for the given dataframe
:param dataframe: DataFrame populated with indicators
:param metadata: Additional information, like the currently traded pair
:return: DataFrame with sell column
"""
dataframe.loc[
(
# Signal: RSI crosses above 70
(qtpylib.crossed_above(dataframe['rsi'], self.sell_rsi.value)) &
(dataframe['tema'] > dataframe['bb_middleband']) & # Guard: tema above BB middle
(dataframe['tema'] < dataframe['tema'].shift(1)) & # Guard: tema is falling
(dataframe['volume'] > 0) # Make sure Volume is not 0
), 'sell'] = 1
return dataframe
import time
import numpy as np
size_of_vec = 1000
def pure_python_version():
t1 = time.time()
X = range(size_of_vec)
Y = range(size_of_vec)
Z = [X[i] + Y[i] for i in range(len(X)) ]
return time.time() - t1
def numpy_version():
t1 = time.time()
X = np.arange(size_of_vec)
Y = np.arange(size_of_vec)
Z = X + Y
return time.time() - t1
t1 = pure_python_version()
t2 = numpy_version()
print(t1, t2)
print("Numpy is in this example " + str(t1/t2) + " faster!")
结果如下:
0.00048732757568359375 0.0002491474151611328
Numpy is in this example 1.955980861244019 faster!
from datetime import datetime
from pydantic import BaseModel
class User(BaseModel):
id: int
name = 'John Doe'
signup_ts: datetime = None
m = User.parse_raw('{"id": 123, "name": "James"}')
print(m)
#> id=123 signup_ts=None name='James'
此外,它能直接将ORM的对象输入,转为Pydantic的对象,比如从Sqlalchemy ORM:
from typing import List
from sqlalchemy import Column, Integer, String
from sqlalchemy.dialects.postgresql import ARRAY
from sqlalchemy.ext.declarative import declarative_base
from pydantic import BaseModel, constr
Base = declarative_base()
class CompanyOrm(Base):
__tablename__ = 'companies'
id = Column(Integer, primary_key=True, nullable=False)
public_key = Column(String(20), index=True, nullable=False, unique=True)
name = Column(String(63), unique=True)
domains = Column(ARRAY(String(255)))
class CompanyModel(BaseModel):
id: int
public_key: constr(max_length=20)
name: constr(max_length=63)
domains: List[constr(max_length=255)]
class Config:
orm_mode = True
co_orm = CompanyOrm(
id=123,
public_key='foobar',
name='Testing',
domains=['example.com', 'foobar.com'],
)
print(co_orm)
#> <models_orm_mode.CompanyOrm object at 0x7f0bdac44850>
co_model = CompanyModel.from_orm(co_orm)
print(co_model)
#> id=123 public_key='foobar' name='Testing' domains=['example.com',
#> 'foobar.com']
从Json文件导入:
from datetime import datetime
from pathlib import Path
from pydantic import BaseModel
class User(BaseModel):
id: int
name = 'John Doe'
signup_ts: datetime = None
path = Path('data.json')
path.write_text('{"id": 123, "name": "James"}')
m = User.parse_file(path)
print(m)
from pydantic import BaseModel, ValidationError, validator
class UserModel(BaseModel):
name: str
username: str
password1: str
password2: str
@validator('name')
def name_must_contain_space(cls, v):
if ' ' not in v:
raise ValueError('must contain a space')
return v.title()
@validator('password2')
def passwords_match(cls, v, values, **kwargs):
if 'password1' in values and v != values['password1']:
raise ValueError('passwords do not match')
return v
@validator('username')
def username_alphanumeric(cls, v):
assert v.isalnum(), 'must be alphanumeric'
return v
上面,我们增加了三种自定义校验逻辑:
1.name 必须带有空格
2.password2 必须和 password1 相同
3.username 必须为字母
让我们试试这三个校验是否成功实现:
user = UserModel(
name='samuel colvin',
username='scolvin',
password1='zxcvbn',
password2='zxcvbn',
)
print(user)
#> name='Samuel Colvin' username='scolvin' password1='zxcvbn' password2='zxcvbn'
try:
UserModel(
name='samuel',
username='scolvin',
password1='zxcvbn',
password2='zxcvbn2',
)
except ValidationError as e:
print(e)
"""
2 validation errors for UserModel
name
must contain a space (type=value_error)
password2
passwords do not match (type=value_error)
"""