以下内容仅供参考学习,不构成投资意见。
可转债,是一种具有中国特色的、受到国家管理和保护的债券,之所以说它很有特色,是因为它身上具备了两种闪闪发光的特性:
1.债性 — 安全保本
可转债本质上是一种公司的债券,也就是我们生活中所说的“欠条”,每张“欠条”的价值是100块钱。
如果你持有一张可转债,它就代表着上市公司欠你100块钱,而且未来必须偿还这笔钱并附带利息。截止到目前,所有上市的可转债,都完成了保本的使命。
也就是说,如果你在转债价格低于100元的时候买入,此时就是保本的。而且公司在赎回时,会付你一定的利息,所以当你在可转债价格低于100元的时候买入,就是保本保利的。
2.股性(可转换) — 存在套利空间
可转债是一张可转换为股票的公司债券。比如目前 晨光转债 转股价为 12.25 元,100/12.25=8.16,那么一张晨光转债会被取证转为8股晨光生物,其余的尾数会被转换为证券账户资金。
目前晨光生物正股16.10元,转换后,你相当于获得了8*16.10=128.8元的股票,加上刚刚尾数补充的账户资金,转股后你相当于获得了131.43元,131.43元被称为转股价值。
也就是说,如果你在前一天收盘前买入了1张晨光转债,并在当前转换为股票,第二天你会获得价值为131.43元的股票+证券账户资金。目前晨光转债的价格为 130.2 元,净利0.93%,但这个套利逻辑有个大前提:第二天开盘股价不会跌,如果跌了,你就拿不到这么多的价值,甚至有可能亏本。
下面本文要研究和利用的,不是可转债的股性,而是可转债的债性。
就如前面所说的,如果你买入100元以下的可转债,除非公司老板带着小姨子跑路,否则都是保本的。于是就有了下面这个自动交易的逻辑:
对于100元以下的可转债,触发某种上涨信号时,买入。上涨0.5%则卖出。如果下跌则一直持有。
上涨就赚了,下跌的话长期持有也不亏,利用可转债的债性及T+0交易的特性实行日内高频率交易就是这个策略的主要逻辑。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
在终端输入以下命令安装我们所需要的依赖模块:
pip install backtrader pip install easytrader
看到 Successfully installed xxx 则说明安装成功。
某些券商在登录的时候可能需要识别验证码,这时候需要下载tesseract:
1.下载并安装tesseract
前往 tesseract-ocr 官网下载二进制包,此外你也可以在Python实用宝典公众号后台回复: 量化投资10,直接获得本文源代码和tesseract的安装包。
双击下载下来的安装包,然后傻瓜式安装就可以,这里只需要注意一点:安装过程中有一个让你选择 Additional language data(download) 表示选择的话帮你下载语言包,这里最好不要选择勾选,因为勾选的话,安装过程非常慢,本教程只需要用到数字和英文识别而已。
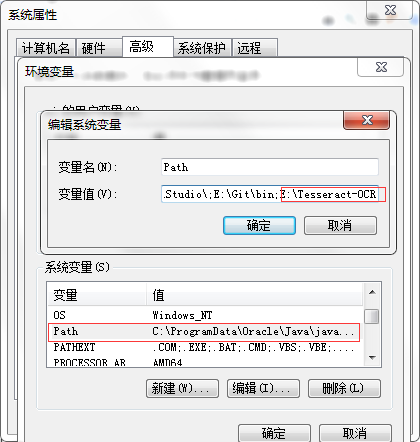
2.配置环境变量
右击我的电脑/计算机,选择属性,然后选择高级属性设置,选择环境变量,在系统变量的path变量中添加你的 tesseract 目录就可以了

3.判断是否安装成功
在命令行中输入:
tesseract --version
出现下面的提示说明安装成功:


2.回测
按照这个策略的逻辑,回测的目的不在于探讨是否会亏损,而在于最高能赚多少。
为什么不需要探讨亏损?因为实际上即便我们买入80元的广汇转债,一直持有,3年后它以100元的价格赎回,我们的3年收益都达到了20%,平均年化率达6.67%。
当然,风险是有的,广汇老板如果带着小姨子跑路了,那你的转债可能一文不值,但是目前还没有出现过这种情况,因为如果出现了这种情况,将出现严重的信用危机,监管部门不可能允许这种情况发生。
回测的主要目的在于:怎样进行自动化交易,能最大化我们的收益。
关于编写策略的方法我们前面九篇系列文章都讲的很清楚了,这里就不再赘述,这里只重点研究买入的逻辑。
2.1 基于分钟K线的Sma金叉策略
这是最简单的策略,如果sma5和sma10实现金叉,则买入债券。涨0.5%则卖出,否则不动。
部分代码如下:
def golden(self, a, b):
if a[-1] - b[-1] < 0 and a[0] - b[0] > 0:
return True
else:
return False
def next(self):
if self.order:
return
if not self.position:
if self.golden(self.sma5, self.sma10):
self.order = self.buy()
self.params.buydays.append(self.datas[0].datetime.date(0))
else:
condition = (self.dataclose[0] - self.bar_executed_close) / self.bar_executed_close
if condition > 0.005:
self.order = self.sell()
self.dead = False
self.params.selldays.append(self.datas[0].datetime.date(0))
self.params.hold_days.append((self.params.selldays[-1] - self.params.buydays[-1]).days)
if self.params.buydays[-1] != self.params.selldays[-1]:
days = get_every_day(self.params.buydays[-1], self.params.selldays[-1])
for day in days:
self.params.hold_count[day] += 1随机抽取了15只低价债券,回测了 2020-9-15 至 2020-11-8 之间的走势,一共交易了59次,每次买入50股。


可以看到每次交易的平均持有日期为4天,这是平均值,如果你看中位数会更大,有些交易可能连续持有了30天,有些可能当天买入当天卖出,两极分化比较大。
不过即便这样,按平均每次收益0.5%、平均每支债券价格为80元的情况来看, 59次交易*0.005*80*50股 = 1180元,如果可转债每次交易的平均手续费是1元,那么除去手续费 1180-2*59=1062元。看起来是一笔可观的羊毛,但是你必须忍受有部分资金被套牢在一些低价转债的情况。
2.2 基于分钟K线的EMA金叉的策略
接下来我们测试一下使用EMA均线的效果,这里选择的是ema(12)和ema(50):
def golden(self, a, b):
if a[-1] - b[-1] < 0 and a[0] - b[0] > 0:
return True
else:
return False
def next(self):
if self.order:
return
if not self.position:
if self.golden(self.exp1, self.exp2):
self.order = self.buy()
self.params.buydays.append(self.datas[0].datetime.date(0))
else:
condition = (self.dataclose[0] - self.bar_executed_close) / self.bar_executed_close
if condition > 0.005:
self.order = self.sell()
self.dead = False
self.params.selldays.append(self.datas[0].datetime.date(0))
self.params.hold_days.append((self.params.selldays[-1] - self.params.buydays[-1]).days)
if self.params.buydays[-1] != self.params.selldays[-1]:
days = get_every_day(self.params.buydays[-1], self.params.selldays[-1])
for day in days:
self.params.hold_count[day] += 1效果如下:

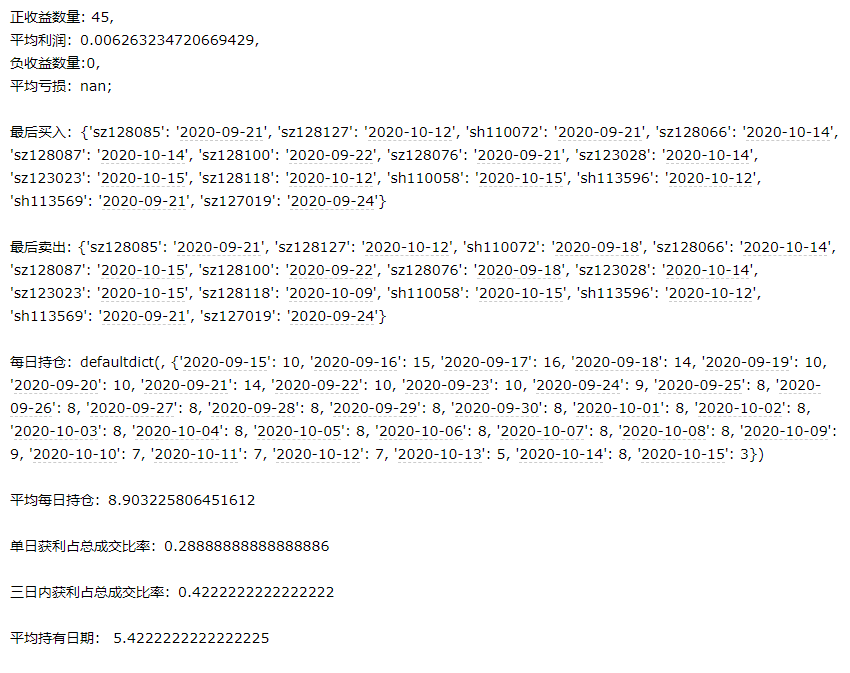
交易次数相对于sma策略少了14次,所以收益肯定也会下降。平均持有日期达到了5.4天,相比于sma策略也有所提高。因此ema在我们的整个策略逻辑里表现地比sma策略稍差一些。
上面展示了两种策略在我们的低价转债投资逻辑里的应用和分析,由于篇幅关系这里就不再展示一些其他策略的回测结果,大家有兴趣可以自己试一下。
3.自动交易
使用easytrader模块,可以简单实现一个单进程的自动交易程序。
对于本策略而言单进程的自动交易程序也够了,因为这个策略要求的实时性并不是很高。
由于这部分代码无法脱敏,因此不能进行深入地讲解。逻辑并不难,每分钟对指定的股票进行监控,当其符合相关策略时进行买入或卖出,下面进行简单的讲解。
1.读取今日需检测的股票
在一天开始交易之前,需要获取今日所符合条件的低价可转债:
def start():
account = Account()
codes = read_today_codes()
logger.info(f"总股票数 {len(codes)}")
last_ping_time = datetime.datetime.now().timestamp()2.巡检
在交易时间里,循环检测可转债是否符合买入策略
while True:
# 是否在交易时间
if not check_time():
continue
for code in codes:
now = int(datetime.datetime.now().timestamp())
logger.info(f"{now} - {code}")
try:
# TODO: 异步执行算法
buy_dict = algorithm(code)
if not buy_dict:
continue
logger.info(buy_dict)
buy_time = list(buy_dict.keys())[0]
buy_value = list(buy_dict.values())[0]
if abs(int(buy_time.timestamp()) - now) < 300:
logic(account, code, buy_time, buy_value)
except Exception as e:
traceback.print_exc()
logger.info(e)
# send_mail(f"算法解析失败: {traceback.print_exc()}", "WRONG", code)如果符合买入规则,在logic函数内,便会对可转债发布买单,同时挂一个0.5%利润的卖单。
3.卖单兜底
理想化情况下,在你挂了买单后立马成交,此时顺利挂出卖单。
不理想情况下,在你挂了买单后,几分钟后才成交,出现这种异步的情况后,卖单无法顺利挂出。
所以我们需要有一个兜底的措施:
now = datetime.datetime.now()
new_ping_time = now.timestamp()
if new_ping_time - last_ping_time > 15:
# 大于15秒,检测持仓,把未委托卖出的单子委托卖出
account.every_day_sell()
last_ping_time = new_ping_time
logger.info(f"{datetime.datetime.strftime(now, '%Y-%m-%d %H:%M:%S')} ping")每次巡检任务都检查持仓,如果存在未挂出卖单的可转债,则按成本价+0.5%的利润挂出卖单。这样保证没有漏掉的可转债。
上述只是简单的几个步骤,实现上你会还有许多细节需要考虑,大家可以自己尝试实现一个这样的自动交易流程。
欢迎在公众号后台回复:加群,回答相应红字验证信息,进入互助群交流。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典