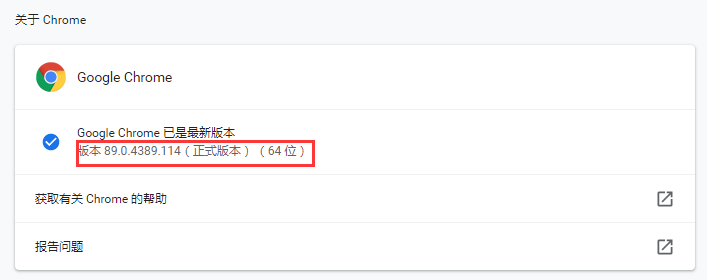
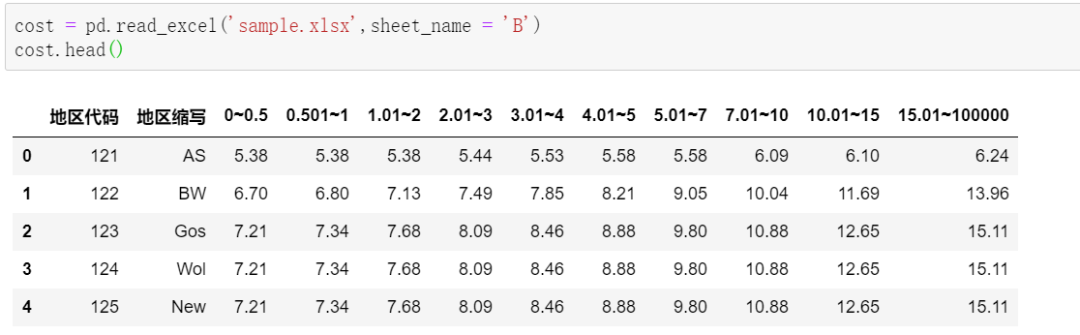
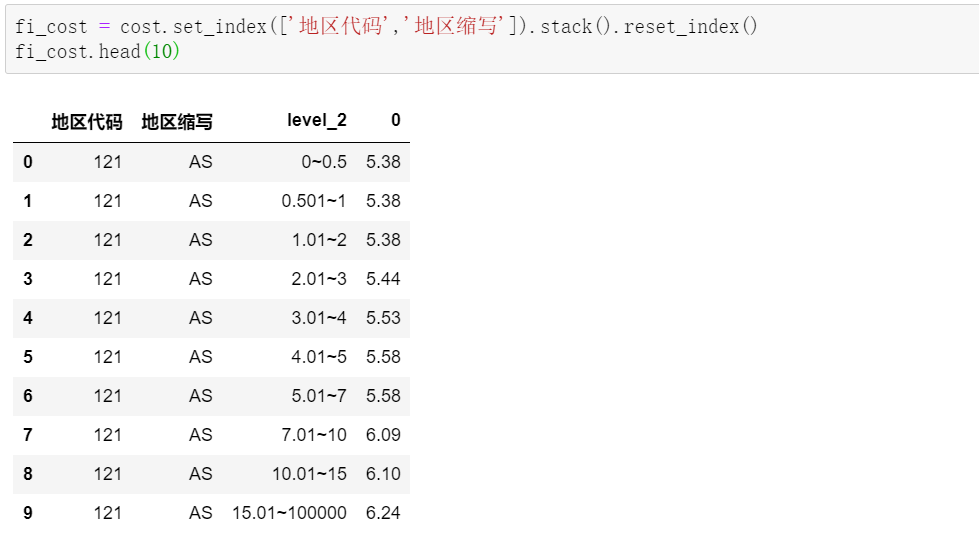
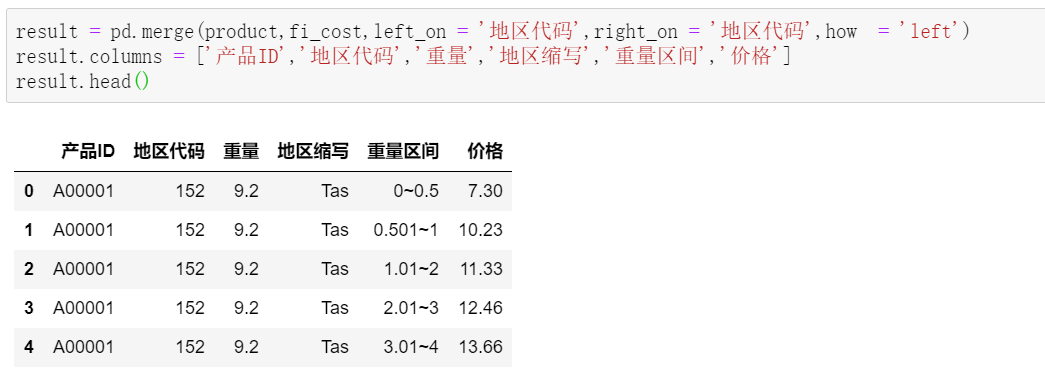
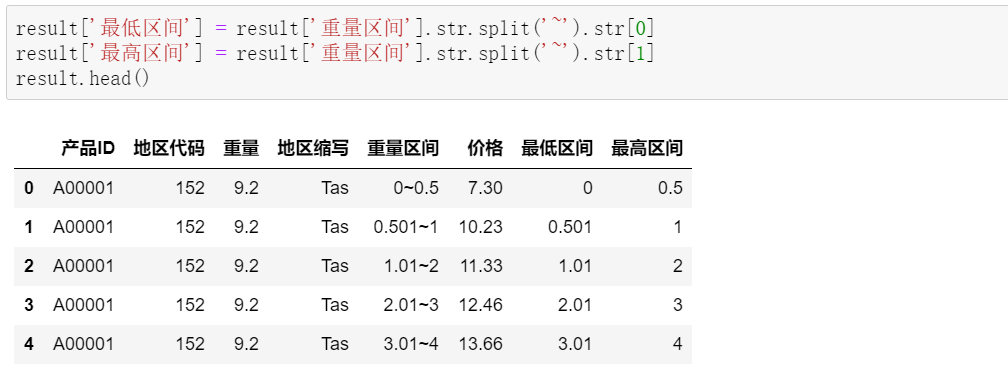
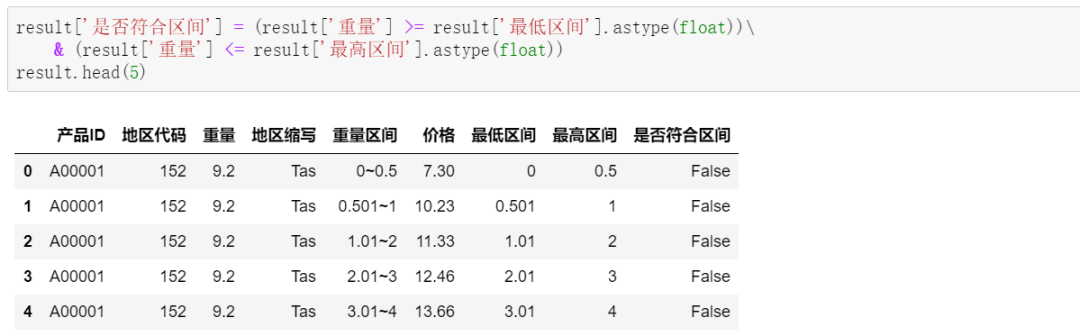
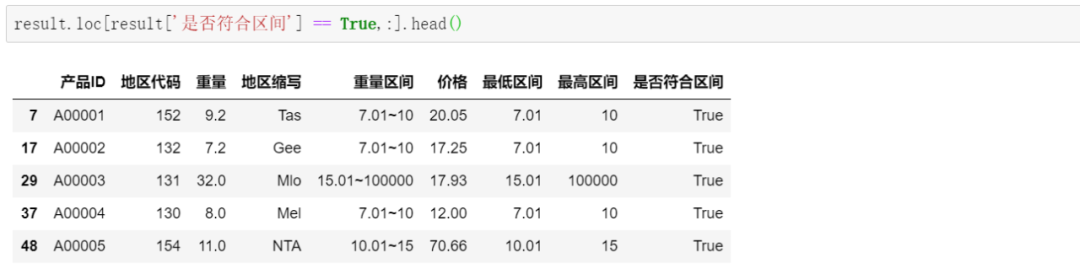
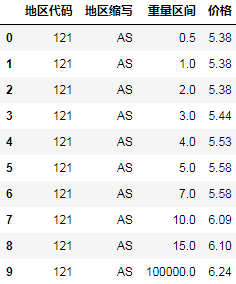
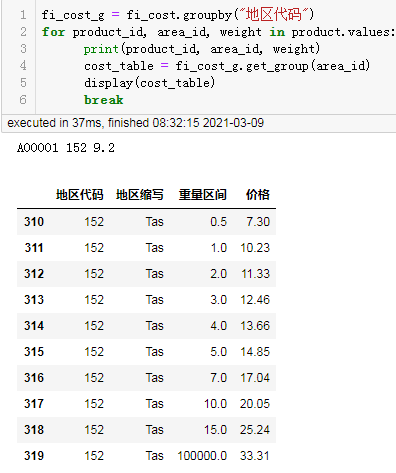
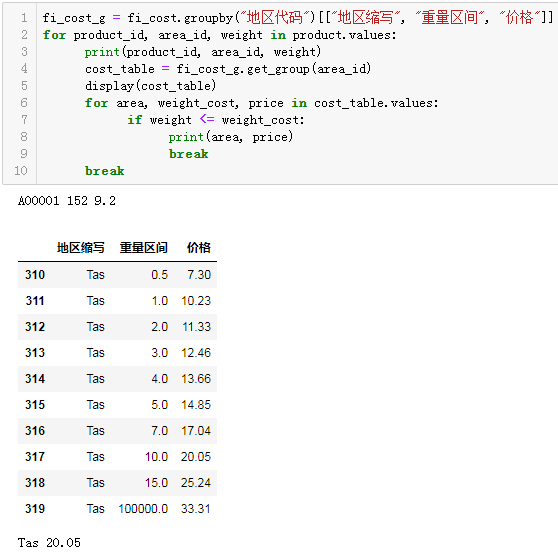
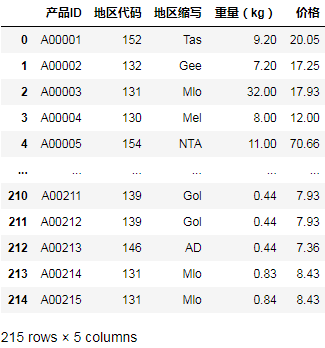
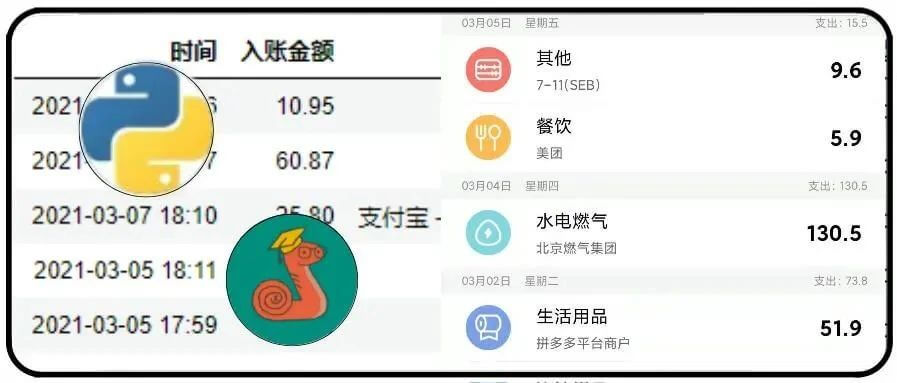
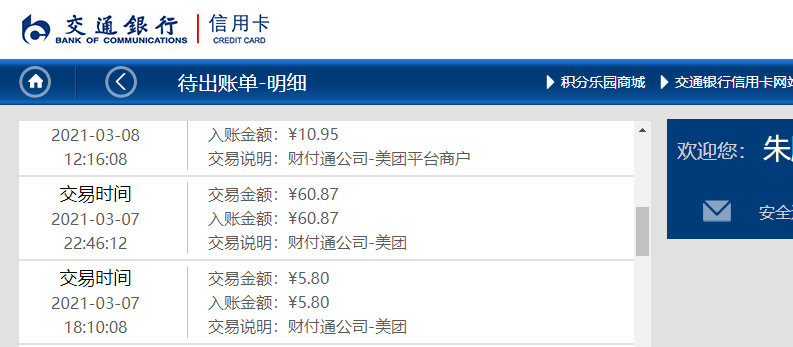
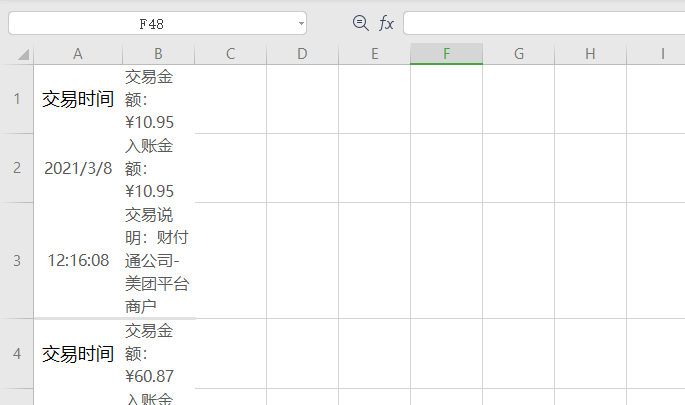
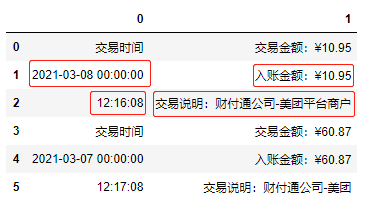
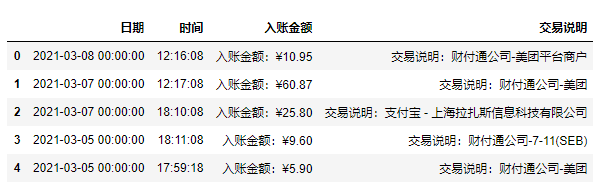
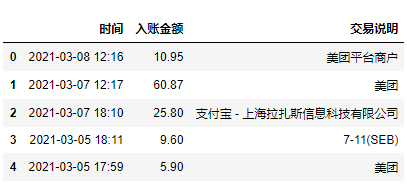
df2['日期'] = df.iloc[[ i+1for i in range(0,len(df),3)],[0]].reset_index()[0] df2['时间'] = df.iloc[[ i+2for i in range(0,len(df),3)],[0]].reset_index(drop=True) df2['入账金额'] = df.iloc[[ i+1for i in range(0,len(df),3)],[1]].reset_index(drop=True) df2['交易说明'] = df.iloc[[ i+2for i in range(0,len(df),3)],[1]].reset_index(drop=True)
defdownload_avatar(username,url): ''' 下载用户头像 ''' savePath = './avatars'# 头像存储目录 res = requests.get(url) with open('%s/%s.jpg'%(savePath,username),'wb') as f: f.write(res.content)
定义主函数,运行代码:
if __name__ == '__main__': fans = get_fansInfo() for f in fans['data']['list']: username = f['fans'] # 用户名 url = f['avatar'] # 头像地址 download_avatar(username,url) print('用户"%s"头像下载完成!'%username)
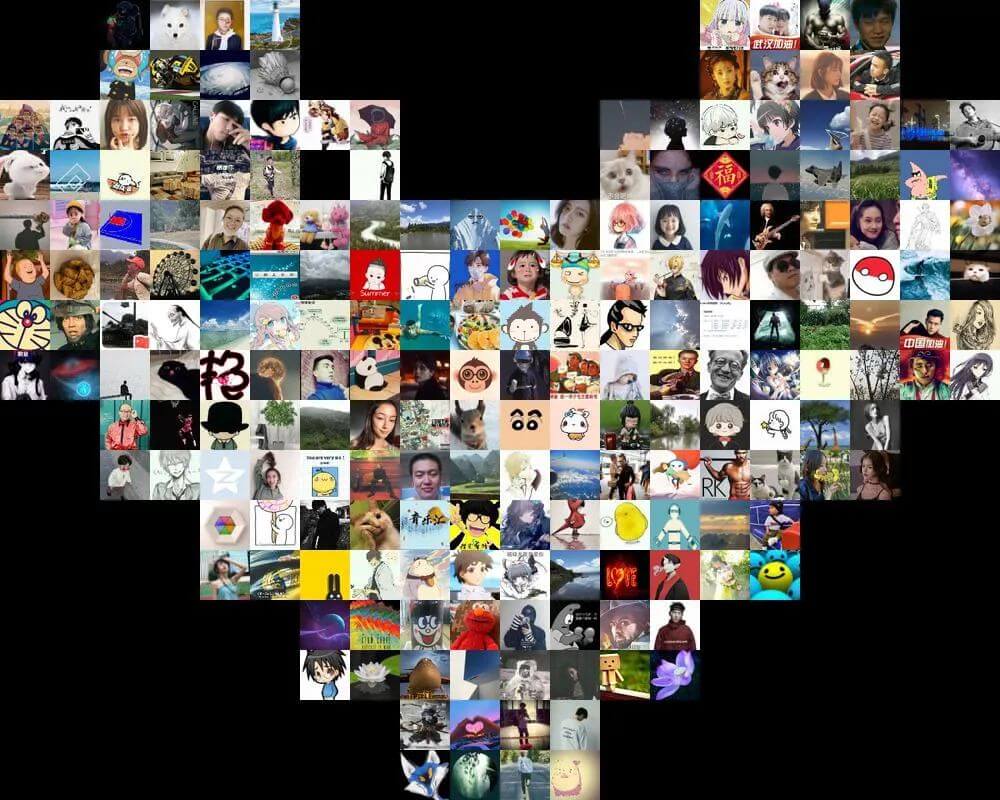
最后我成功将所有头像下载到本地文件夹中:
2.头像去重
聪明的你应该已经发现,在爬取到的头像中有两个头像重复出现(想必这应该是官方默认头像):
于是乎,为了更好地展示,我们得对头像进行去重
这里我们利用每个头像的 MD5 值来进行去重,然后定义函数来计算头像的 MD5 值
defget_md5(filename): ''' 获取文件的md5值cls ''' m = hashlib.md5() with open(filename,'rb') as f: for line in f: m.update(line) md5 = m.hexdigest() return md5
# 定义相关参数 SIZE = 50# 每张图片的尺寸为50*50 N = 2# 每个点位上放置2*2张图片
# 计算相关参数 width = np.shape(FRAME)[1]*N*SIZE # 照片墙宽度 height = np.shape(FRAME)[0]*N*SIZE # 照片墙高度 n_img = np.sum(FRAME)*(N**2) # 照片墙需要的照片数 filenames = random.sample(os.listdir('./avatars(dr)'),n_img) # 随机选取n_img张照片 filenames = ['./avatars(dr)/'+f for f in filenames]
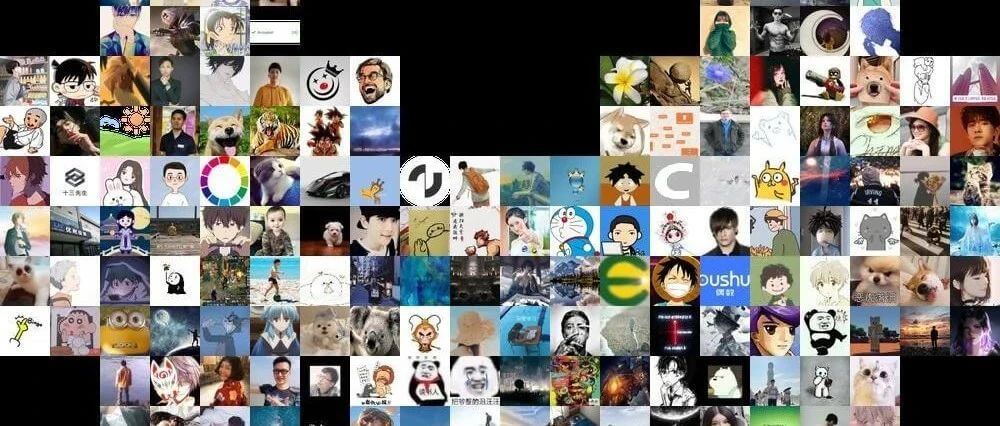
遍历 FRAME,用头像对背景图片进行填充:
# 绘制爱心墙 img_bg = Image.new('RGB',(width,height)) # 设置照片墙背景 i = 0 for y in range(np.shape(FRAME)[0]): for x in range(np.shape(FRAME)[1]): if FRAME[y][x] == 1: # 如果需要填充 pos_x = x*N*SIZE # 填充起始X坐标位置 pos_y = y*N*SIZE # 填充起始Y坐标位置 for yy in range(N): for xx in range(N): img = Image.open(filenames[i]) img = img.resize((SIZE,SIZE),Image.ANTIALIAS) img_bg.paste(img,(pos_x+xx*SIZE,pos_y+yy*SIZE)) i += 1
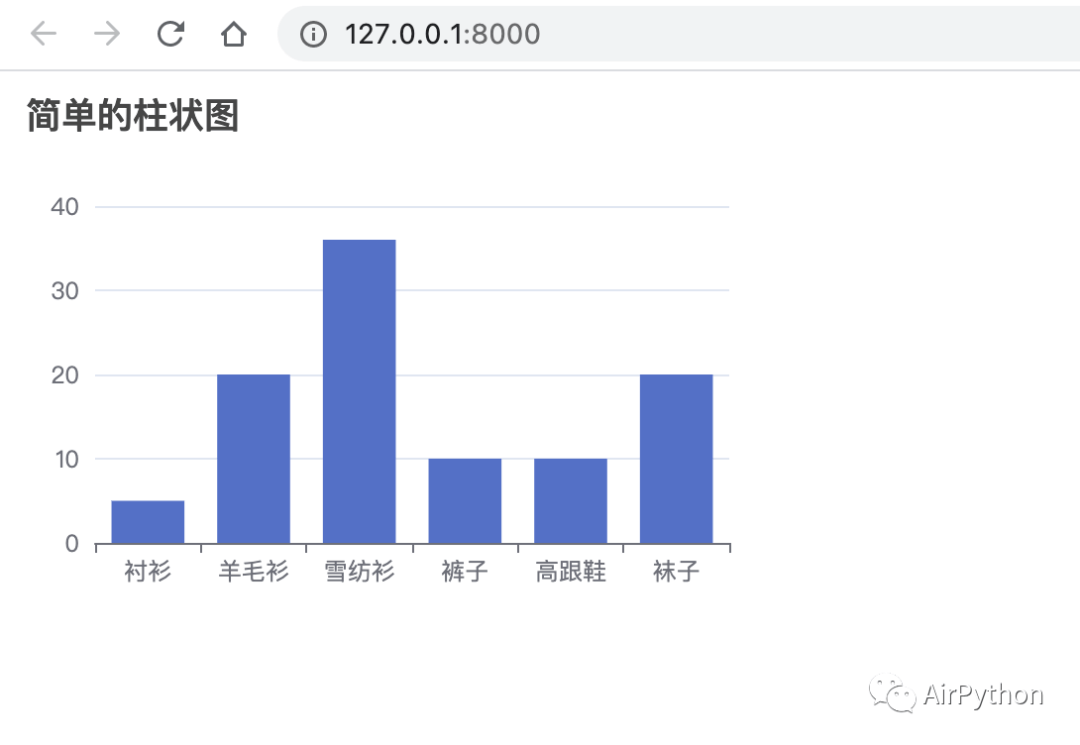
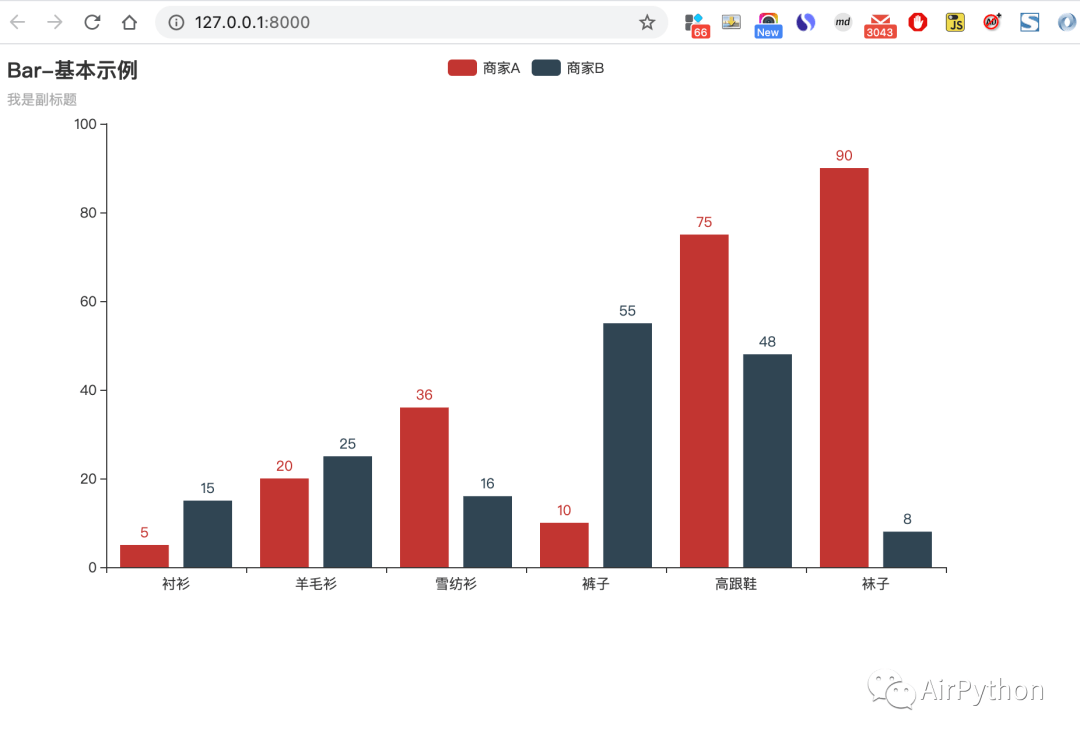
# Create your views here. from django.http import HttpResponse from jinja2 import Environment, FileSystemLoader from pyecharts.globals import CurrentConfig
Path to your journal file (leave blank for C:\Users\83493\.local\share\jrnl\journal.txt):
Do you want to encrypt your journal? You can always change this later [y/N] n
PS G:\push> jrnl -to today
2021-02-01 09:00 Called in sick.
| Used the time to clean and spent 4h on writing my book.
2021-02-01 09:00 2月初.
| 2月的第一天,祝大家2月万事如意,快快乐乐。
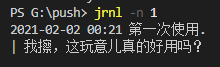
2021-02-02 00:21 第一次使用.
| 我擦,这玩意儿真的好用吗?
当然,不使用冒号也是可以记笔记的:
PS G:\push> jrnl 不用冒号也能记笔记吗?
[Entry added to default journal]
3.2 标签功能
jrnl 支持标签功能。默认标记符号为@(不用#号是因为它是保留字符)。
要使用标签,请在所需标记的文字前面加上@符号:
jrnl Had a wonderful day at the @beach with @Tom and @Anna.
尽管可以在标记条目时使用大写字母,但按标记搜索时不区分大小写。
条目中可以使用多个标签没有限制。
3.3 重点笔记
要将笔记标记为重点项,只需使用星号(*)对它进行“星标” :
jrnl last sunday *: Best day of my life.
如果你不想添加日期,则以下选项是等效的(确保*号后面没有空格):
jrnl *: Best day of my life.
jrnl *Best day of my life.
jrnl Best day of my life.*