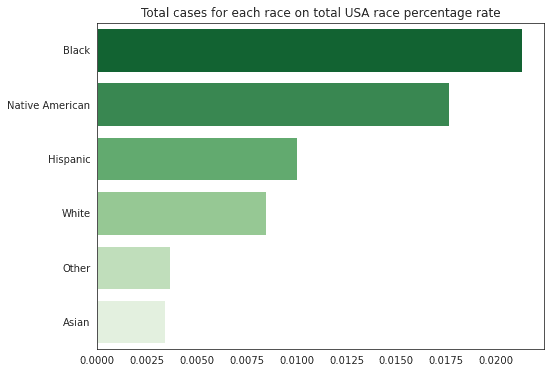
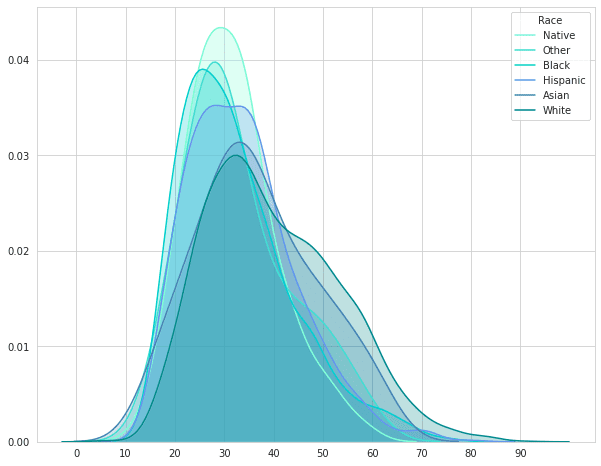
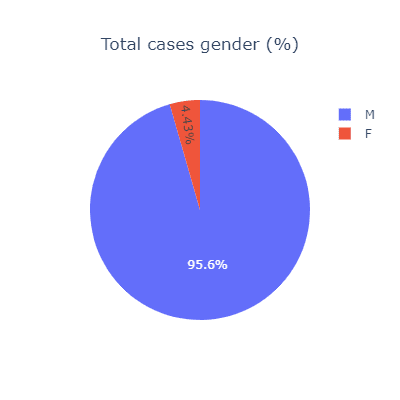
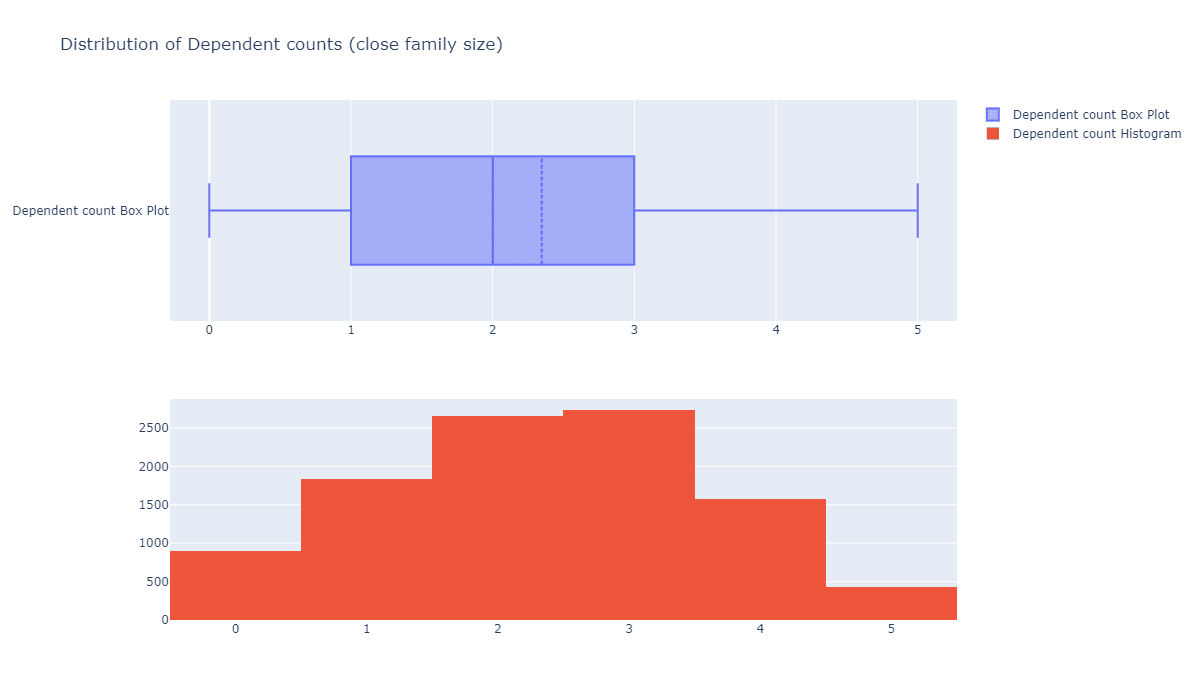
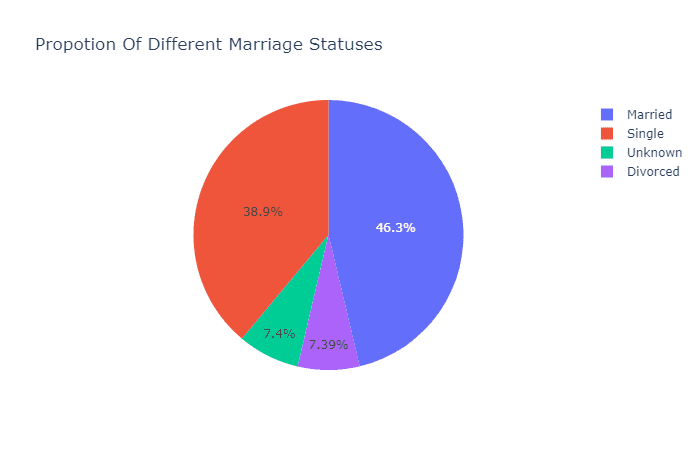
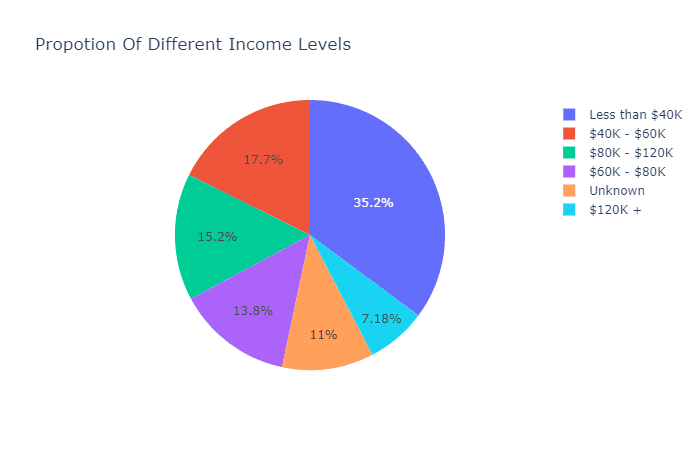
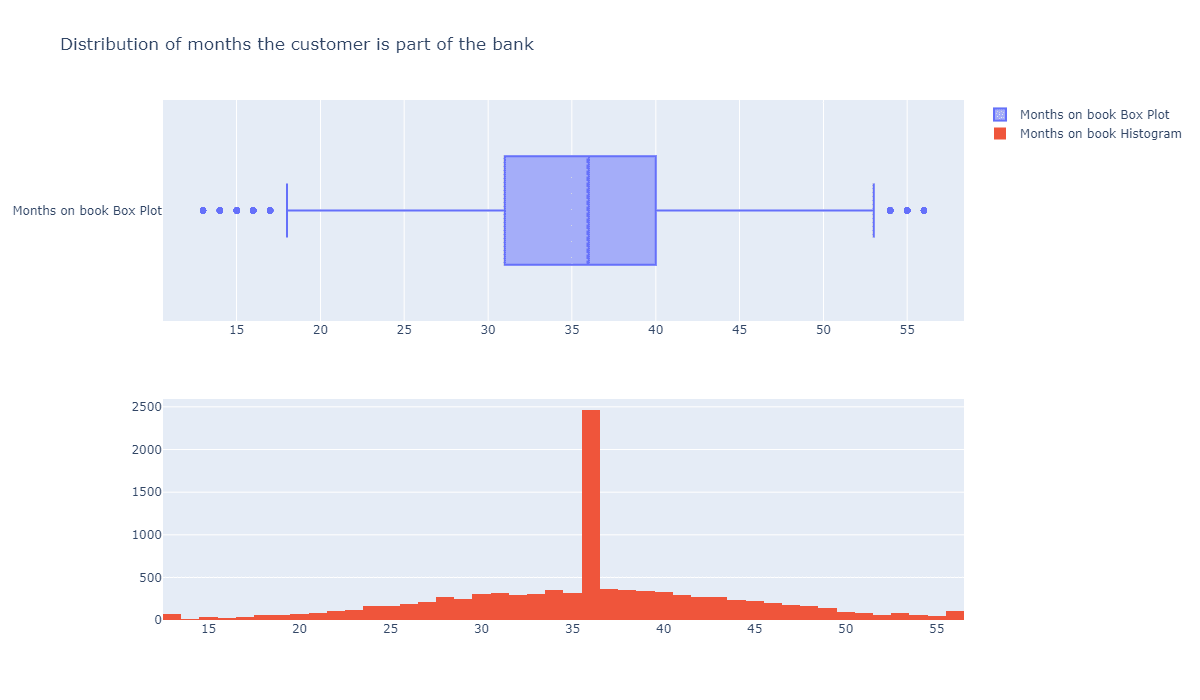
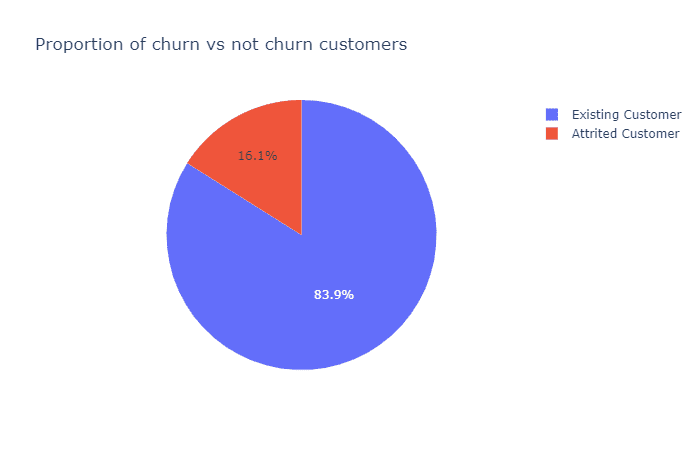
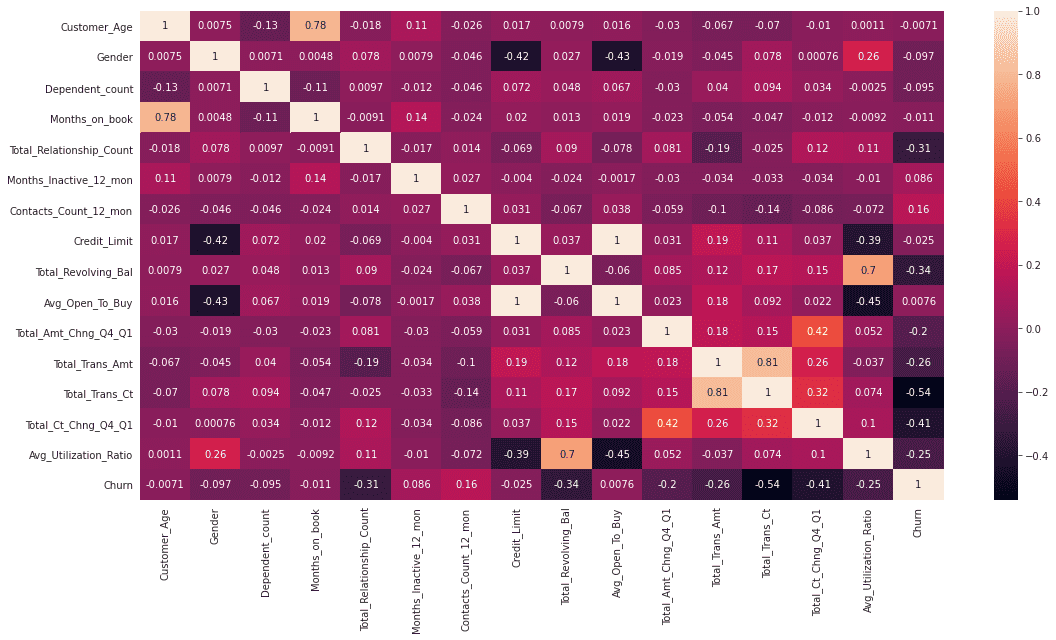
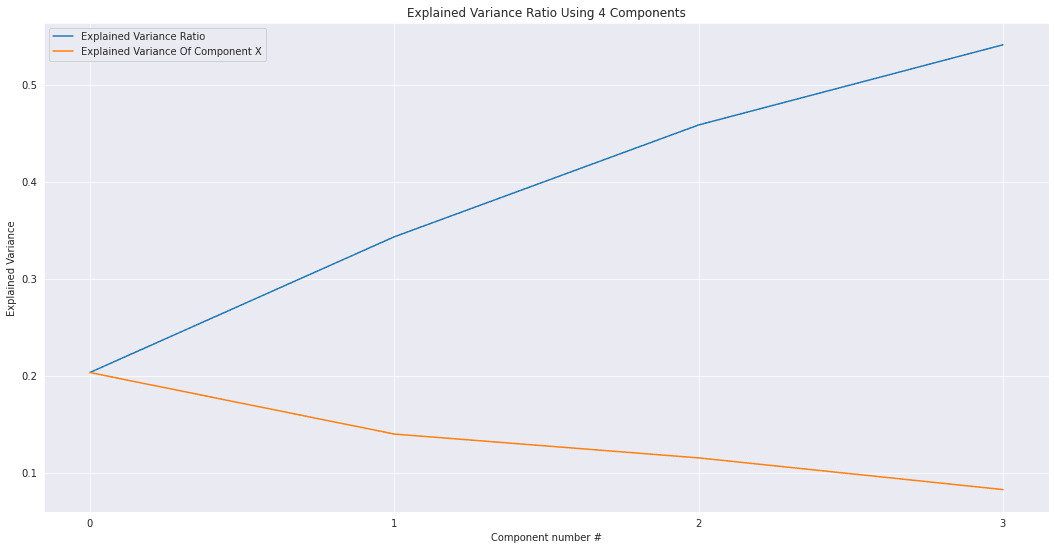
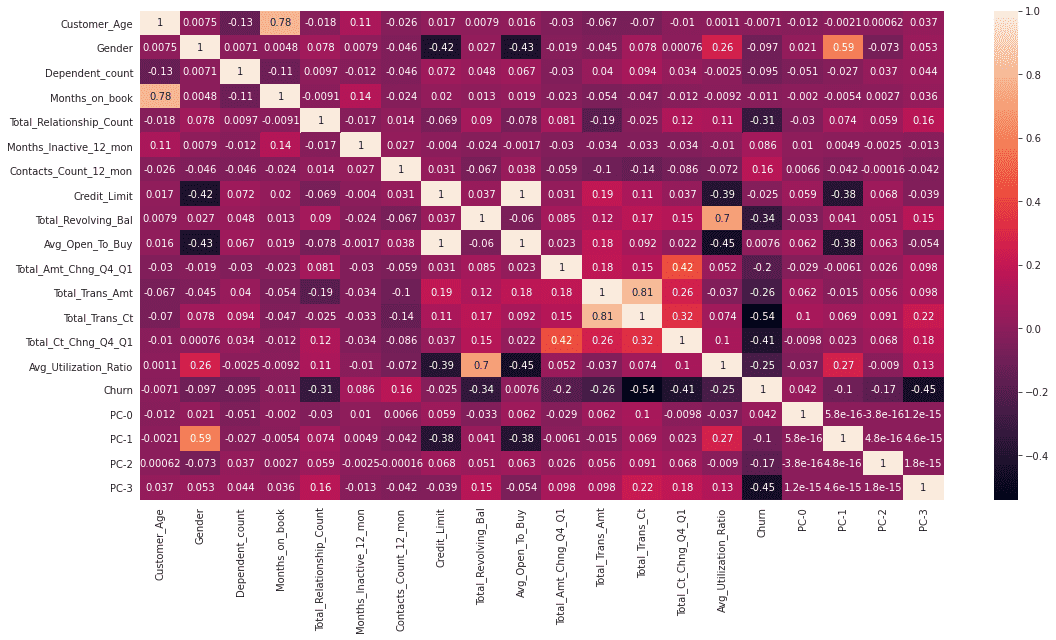
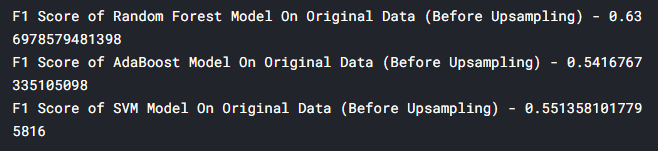
还记得疫情之初,我们用Python给头像戴口罩的文章吗?
当时只是简单的调用了第三方模块将口罩图片替换入原图,内容非常简短。
今天,我们将提供一个能够通过以下三种方式给头像戴上圣诞帽的Python教程:
- 1.实时打开摄像头读取头像图佩戴圣诞帽
- 2.从本地读取一幅头像图佩戴圣诞帽
- 3.从文件夹中批量读取头像图佩戴圣诞帽
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
此外,推荐大家用VSCode编辑器,因为它可以在编辑器下方的终端运行命令安装依赖模块:Python 编程的最好搭档—VSCode 详细指南。
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install https://pypi.python.org/packages/da/06/bd3e241c4eb0a662914b3b4875fc52dd176a9db0d4a2c915ac2ad8800e9e/dlib-19.7.0-cp36-cp36m-win_amd64.whl#md5=b7330a5b2d46420343fbed5df69e6a3f pip install opencv-python
有两个依赖,一个是 dlib模块,需要通过whl文件安装。一个是常用的opencv模块,直接pip安装即可。
文章源代码fork自:amusi/Merry_Christmas_Hat
本文全部源代码及图片可在此下载:
https://github.com/Ckend/Merry_Christmas_Hat
如果你访问不了Github,可在Python实用宝典公众号后台回复:圣诞帽 下载。
2.给头像戴上圣诞帽
为防大家没耐心看下去,我把佩戴圣诞帽的教程提前了。
下载源代码后,进入源代码的文件夹,一共有三种方式给你的头像佩戴圣诞帽。
1.打开摄像头读取头像图:
当摄像头打开后,会实时出现佩戴着圣诞帽的你。按q保存你最喜欢的图片即可。
def method_one(hat_img):
"""
方式1: 打开摄像头读取头像图
"""
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print('摄像头打开失败!')
else:
print('摄像头打开成功!')
print("请按下键盘上的'q',保存当前满意图像!")
while cap.isOpened():
_, img = cap.read()
cv2.imshow("img", img)
k = cv2.waitKey(33) & 0xFF
if(k == ord('q')):
cv2.imwrite("sefile.jpg", img)
face_flag, output = add_hat(img, hat_img)
if(-1 == face_flag):
break
cv2.imshow("output", output)
print("请按下键盘上的任意按键,退出当前程序!")
cv2.waitKey(0)
cv2.imwrite("output.jpg", output)
break
# 读取帽子图,第二个参数-1表示读取为rgba通道,否则为rgb通道
hat_img = cv2.imread("hat.png", -1)
# 选择你需要的方式
method_one(hat_img)
cv2.destroyAllWindows()这样,通过运行Merry_Chirstmas_Hat.py文件就能打开摄像头并实时显示佩戴圣诞帽的你:
python Merry_Chirstmas_Hat.py
2.读取一个图像佩戴圣诞帽
这是最常见的使用场景,你只需要的源代码文件夹下,放置你所需要佩戴圣诞帽的图像,命名为test.jpg(或其他,只需要改函数调用里你的指定文件名称)。
放置完成后运行Merry_Chirstmas_Hat.py文件即可佩戴圣诞帽。
def method_two(hat_img, filename):
"""
方式2: 从本地读取一幅头像图
"""
img = cv2.imread(filename)
success, output = add_hat(img, hat_img)
if not success:
print("戴失败了!")
return
# 展示效果
cv2.imshow("output", output)
cv2.waitKey(0)
cv2.imwrite("output.jpg", output)
# 读取帽子图,第二个参数-1表示读取为rgba通道,否则为rgb通道
hat_img = cv2.imread("hat.png", -1)
# 选择你需要的方式
method_two(hat_img, "test.jpg")
cv2.destroyAllWindows()3. 从文件夹中读取多张头像图(批量处理)
在源代码的文件夹下,创建一个名为images的文件夹,在里面放置所有以.jpg结尾的图像,运行Merry_Chirstmas_Hat.py文件后你能看到所有这些图像佩戴圣诞帽的效果。
def method_three(hat_img):
"""
方式3: 从文件夹中读取多张头像图(批量处理)
"""
import glob as gb
img_path = gb.glob("./images/*.jpg")
for path in img_path:
img = cv2.imread(path)
# 添加帽子
success, output = add_hat(img, hat_img)
if not success:
print("戴失败了!")
continue
# 展示效果
cv2.imshow("output", output)
cv2.waitKey(0)
# 读取帽子图,第二个参数-1表示读取为rgba通道,否则为rgb通道
hat_img = cv2.imread("hat.png", -1)
# 选择你需要的方式
method_three(hat_img)
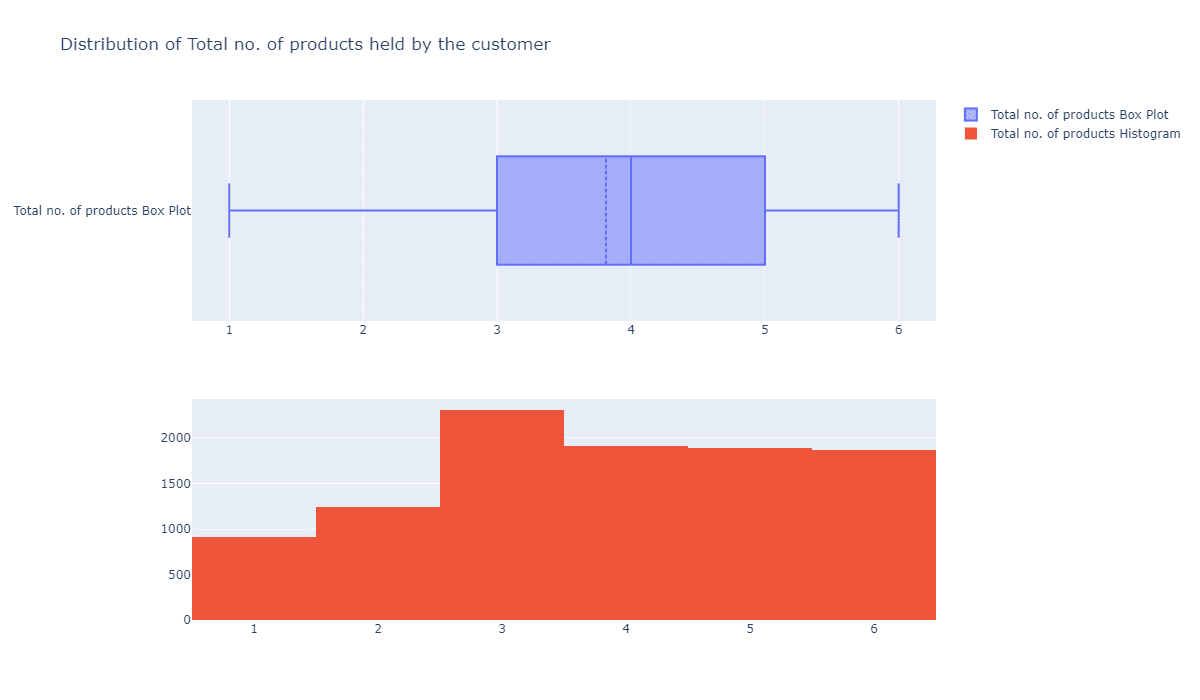
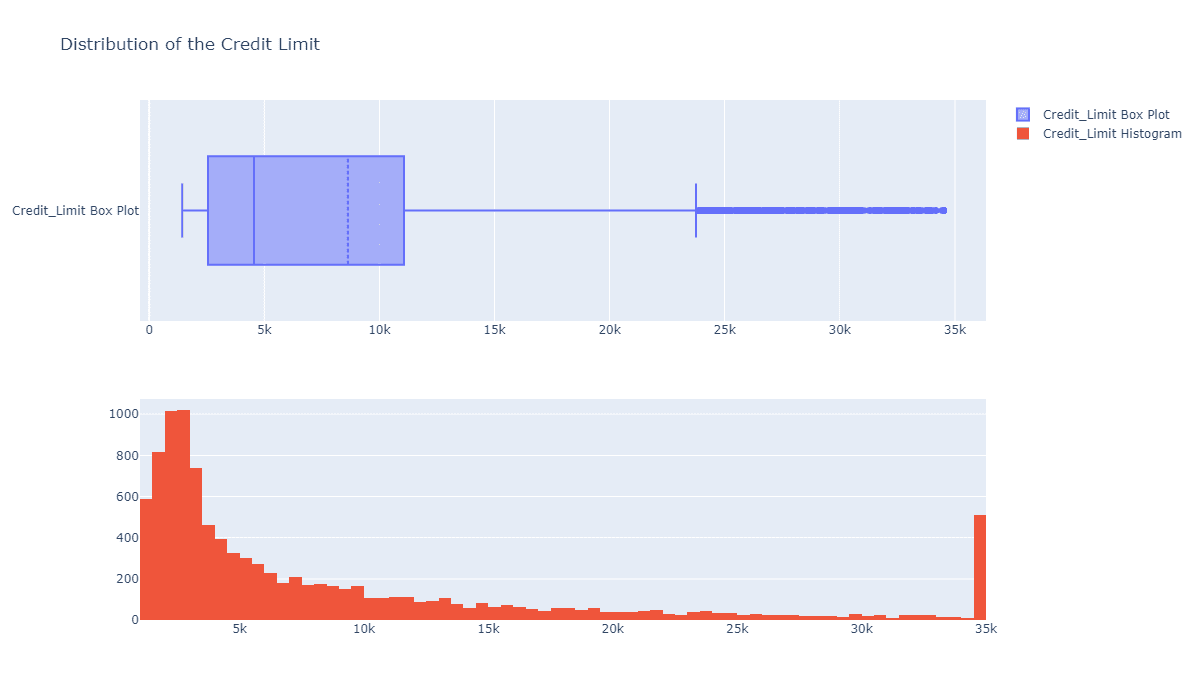
cv2.destroyAllWindows()我们的代码默认使用了第二种方式佩戴圣诞帽,你可以修改代码178行的method选择你所需要的方式。佩戴效果如下:
原图:


佩戴效果图:
3.原理分析
在上面的三种佩戴圣诞帽方法中,都调用了一个叫 add_hat 的函数。
顾名思义,这个函数里对原图像做了佩戴圣诞帽的逻辑,其步骤如下:
- 1. 正脸识别(才好佩戴帽子到头部)。
- 2. 遍历所有人脸,取5个关键点,并根据人脸大小调整帽子大小。
- 3. 利用alpha通道的图像提取放帽子的区域(提取空心区域)。
- 4. 将原帽子覆盖至第3步提取出来的空心区域上并放回原图。
下面分步骤阐述:
1.正脸识别
利用了dlib中已经训练好的人脸关键点检测模型对图像进行提取人脸的操作:
# dlib人脸关键点检测器(需要确保.py文件同级目录下有shape_predictor_5_face_landmarks.dat这个文件) predictor_path = "shape_predictor_5_face_landmarks.dat" predictor = dlib.shape_predictor(predictor_path) # dlib正脸检测器 detector = dlib.get_frontal_face_detector() # 正脸检测 dets = detector(img, 1)
检测到的人脸数据将会保存到dets变量中,因此dets的长度将大于0.
2.遍历人脸,取关键点并调整帽子大小
获取保存的人脸数据的各种参数,并根据这些参数对帽子进行比例转化:
# 如果检测到人脸
if len(dets) > 0:
# 遍历所有人脸
for d in dets:
x, y, w, h = d.left(), d.top(), d.right()-d.left(), d.bottom()-d.top()
# 关键点检测,5个关键点
shape = predictor(img, d)
# 选取左(0)右(2)眼眼角的点
point1 = shape.part(0)
point2 = shape.part(2)
# 求两点中心
eyes_center = ((point1.x+point2.x)//2, (point1.y+point2.y)//2)
# 根据人脸大小调整帽子大小
factor = 1.5 # 比例因子
resized_hat_h = int(
round(rgb_hat.shape[0]*w/rgb_hat.shape[1]*factor))
resized_hat_w = int(
round(rgb_hat.shape[1]*w/rgb_hat.shape[1]*factor))
# 避免帽子高度超出图像画面
if resized_hat_h > y:
resized_hat_h = y-1
# 根据人脸大小调整帽子大小
resized_hat = cv2.resize(rgb_hat, (resized_hat_w, resized_hat_h))3. 利用alpha通道的图像提取放帽子的区域(提取空心区域)。
通过alpha通道生成的黑白图像作为mask,将其填充到原图中。生成了bg.jpg.
# 用alpha通道作为mask(bitwise_not)
mask = cv2.resize(a, (resized_hat_w, resized_hat_h))
mask_inv = cv2.bitwise_not(mask)
# 帽子相对与人脸框上线的偏移量
dh = 0
dw = 0
# 原图ROI
bg_roi = img[y+dh-resized_hat_h:y+dh,
(eyes_center[0]-resized_hat_w//3):(eyes_center[0]+resized_hat_w//3*2)]
# 原图ROI中提取放帽子的区域
bg_roi = bg_roi.astype(float)
mask_inv = cv2.merge((mask_inv, mask_inv, mask_inv))
alpha = mask_inv.astype(float)/255
# 相乘之前保证两者大小一致(可能会由于四舍五入原因不一致)
alpha = cv2.resize(alpha, (bg_roi.shape[1], bg_roi.shape[0]))
bg = cv2.multiply(alpha, bg_roi)
bg = bg.astype('uint8')
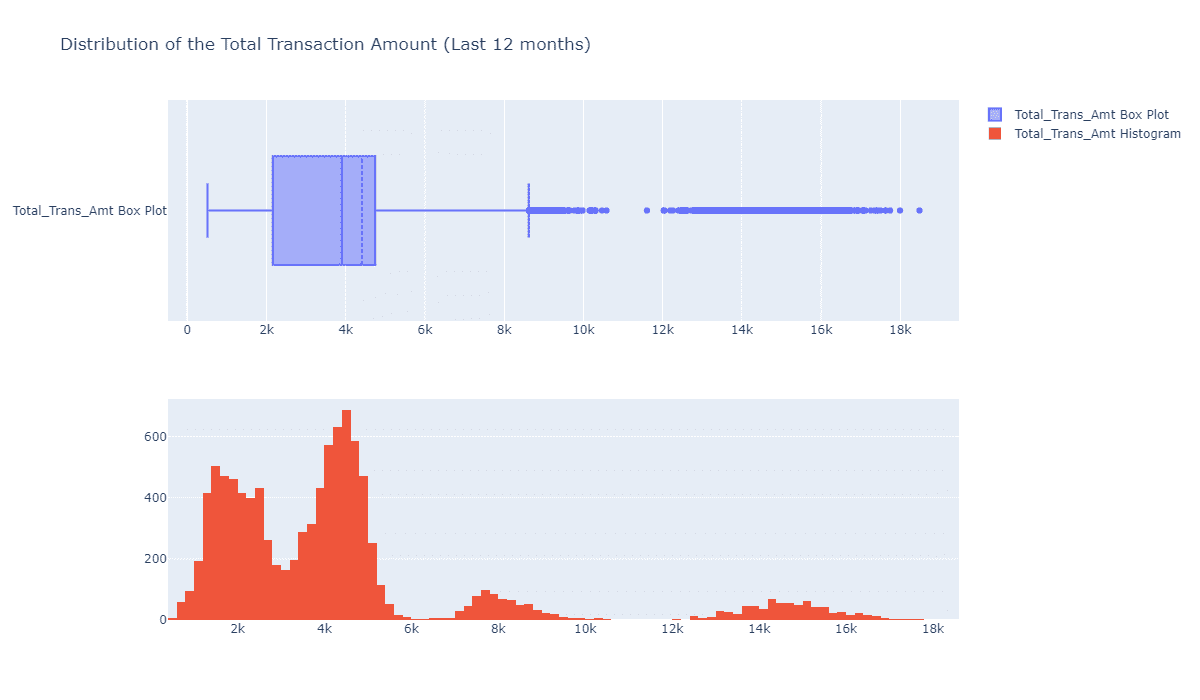
cv2.imwrite("bg.jpg", bg)如果你打开bg.jpg,你就会发现这是一个佩带黑色模板的原图帽子区域:


4.将原帽子覆盖至第3步提取出来的空心区域上并放回原图。
接下来要做的,就是将帽子替换到第3部生成的空心区域上并放回原图:
# 提取帽子区域
hat = cv2.bitwise_and(resized_hat, resized_hat, mask=mask)
cv2.imwrite("hat.jpg", hat)
# 相加之前保证两者大小一致(可能会由于四舍五入原因不一致)
hat = cv2.resize(hat, (bg_roi.shape[1], bg_roi.shape[0]))
# 两个ROI区域相加
add_hat = cv2.add(bg, hat)
# 把添加好帽子的区域放回原图
img[y+dh-resized_hat_h:y+dh, (eyes_center[0]-resized_hat_w//3):(
eyes_center[0]+resized_hat_w//3*2)] = add_hat
return 1, img这样,便完成了整个佩戴圣诞帽的流程。文章完整源代码可在Python实用宝典公众号后台回复:圣诞帽 下载。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典