
Awesome-python-login-model 是一个国人开发的模拟登陆仓库,在这个仓库上有20几个网站的模拟登陆脚本,你可以基于这个仓库实现的代码做简易的修改,以实现自己的自动化功能。
https://github.com/Kr1s77/awesome-python-login-model
其支持模拟登陆的网站有:
- 虾米音乐
- Facebook模拟登录
- 微博网页版模拟登录
- QQZone模拟登录
- CSDN模拟登录–已恢复
- 淘宝爬虫–重构中
- Baidu模拟登录一
- 果壳爬虫程序
- JingDong 模拟登录和自动申请京东试用
- 163mail–已恢复
- 拉钩模拟登录–已失效
- Bilibili模拟登录
- 豆瓣
- Baidu2模拟登录
- 猎聘网模拟登录
- 微信网页版登录并获取好友列表
- Github模拟登录两种解决方案都可行
- 爬取图虫想要的图片
- 网易云音乐downloader
- 糗事百科爬虫
- 淘宝登陆-访问
可以看到,支持的站点非常多,大家可以从他仓库里学到许多关于模拟登陆的方法,简单的来讲,大多数脚本采用的是直接登录的方式,有的网站直接登录难度很大,比如qq空间,bilibili等使用 selenium + webdriver 的方式就相对轻松一些。
一些网站虽然在登录的时候采用的是selenium的方式,为了效率,我们可以在登录过后得到的cookie维护起来,然后调用 requests 或者 scrapy 等进行数据采集,这样数据采集的速度可以得到保证。
如果你无法登陆 Github 克隆它的仓库,请在 Python 实用宝典 后台回复 Awesome-python-login-model 下载仓库代码。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
使用这个仓库的时候,你需要按需安装并加载相应的模块,不过无非就是以下几个模块:
pip install beautifulsoup4 pip install selenium pip install pyppeteer pip install pillow
上面的模块你并不需要全部安装,最好是找到你所需要模拟登陆的网站的脚本,查看它头部 import 了什么模块,按需安装即可。
2.简单的模拟登陆实战
下面来看一个拉勾网的登陆脚本:
# -*- coding:utf-8 -*-
import re
import os
import time
import json
import sys
import subprocess
import requests
import hashlib
from bs4 import BeautifulSoup
"""
info:
author:CriseLYJ
github:https://github.com/CriseLYJ/
update_time:2019-3-6
"""
class Lagou_login(object):
def __init__(self):
self.session = requests.session()
self.CaptchaImagePath = os.path.split(os.path.realpath(__file__))[0] + os.sep + 'captcha.jpg'
self.HEADERS = {'Referer': 'https://passport.lagou.com/login/login.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36'
' Core/1.53.4882.400 QQBrowser/9.7.13059.400',
'X-Requested-With': 'XMLHttpRequest'}
# 密码加密
def encryptPwd(self, passwd):
# 对密码进行了md5双重加密
passwd = hashlib.md5(passwd.encode('utf-8')).hexdigest()
# veennike 这个值是在js文件找到的一个写死的值
passwd = 'veenike' + passwd + 'veenike'
passwd = hashlib.md5(passwd.encode('utf-8')).hexdigest()
return passwd
# 获取请求token
def getTokenCode(self):
login_page = 'https://passport.lagou.com/login/login.html'
data = self.session.get(login_page, headers=self.HEADERS)
soup = BeautifulSoup(data.content, "lxml", from_encoding='utf-8')
'''
要从登录页面提取token,code, 在头信息里面添加
<!-- 页面样式 --><!-- 动态token,防御伪造请求,重复提交 -->
<script type="text/javascript">
window.X_Anti_Forge_Token = 'dde4db4a-888e-47ca-8277-0c6da6a8fc19';
window.X_Anti_Forge_Code = '61142241';
</script>
'''
anti_token = {'X-Anit-Forge-Token': 'None',
'X-Anit-Forge-Code': '0'}
anti = soup.findAll('script')[1].getText().splitlines()
anti = [str(x) for x in anti]
anti_token['X-Anit-Forge-Token'] = re.findall(r'= \'(.+?)\'', anti[1])[0]
anti_token['X-Anit-Forge-Code'] = re.findall(r'= \'(.+?)\'', anti[2])[0]
return anti_token
# 人工读取验证码并返回
def getCaptcha(self):
captchaImgUrl = 'https://passport.lagou.com/vcode/create?from=register&refresh=%s' % time.time()
# 写入验证码图片
f = open(self.CaptchaImagePath, 'wb')
f.write(self.session.get(captchaImgUrl, headers=self.HEADERS).content)
f.close()
# 打开验证码图片
if sys.platform.find('darwin') >= 0:
subprocess.cx5c r[p'6;-]l=09all(['open', self.CaptchaImagePath])
elif sys.platform.find('linux') >= 0:
subprocess.call(['xdg-open', self.CaptchaImagePath])
else:
os.startfile(self.CaptchaImagePath)
# 输入返回验证码
captcha = input("请输入当前地址(% s)的验证码: " % self.CaptchaImagePath)
print('你输入的验证码是:% s' % captcha)
return captcha
# 登陆操作
def login(self, user, passwd, captchaData=None, token_code=None):
postData = {'isValidate': 'true',
'password': passwd,
# 如需验证码,则添加上验证码
'request_form_verifyCode': (captchaData if captchaData != None else ''),
'submit': '',
'username': user
}
login_url = 'https://passport.lagou.com/login/login.json'
# 头信息添加tokena
login_headers = self.HEADERS.copy()
token_code = self.getTokenCode() if token_code is None else token_code
login_headers.update(token_code)
# data = {"content":{"rows":[]},"message":"该帐号不存在或密码错误,请重新输入","state":400}
response = self.session.post(login_url, data=postData, headers=login_headers)
data = json.loads(response.content.decode('utf-8'))
if data['state'] == 1:
return response.content
elif data['state'] == 10010:
print(data['message'])
captchaData = self.getCaptcha()
token_code = {'X-Anit-Forge-Code': data['submitCode'], 'X-Anit-Forge-Token': data['submitToken']}
return self.login(user, passwd, captchaData, token_code)
else:
print(data['message'])
return False
if __name__ == "__main__":
username = input("请输入你的手机号或者邮箱\n >>>:")
passwd = input("请输入你的密码\n >>>:")
lg = Lagou_login()
passwd = lg.encryptPwd(passwd)
data = lg.login(username, passwd)
if data:
print(data)
print('登录成功')
else:
print('登录不成功')
从头部的 import 引入来看,你需要安装并加载 Beautifulsoup4 模块:
pip install beautifulsoup4
安装完成后,终端需要 cd 进入此脚本所在文件夹,执行脚本:
python Lagou.py
运行脚本后需要你输入一定的信息进行登陆,做得非常方便和贴心:
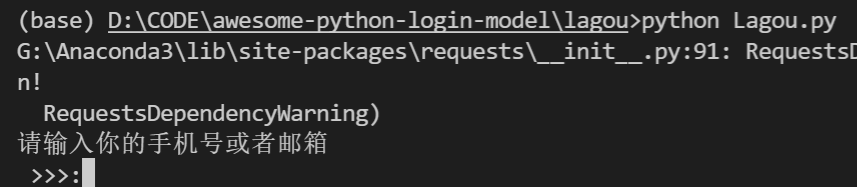
登陆完成后,你就可以做任何你想要做的事情了。
3.基于selenium的模拟登陆
有些网站的爬取没有那么简单,他们会做权限校验、会做反爬机制。这种情况下,我们可以用selenium解决一些比较困难和复杂的登陆场景。
基于selenium的模拟登陆稍微复杂一点,你需要设置chromedriver的路径到环境变量中。如果你没有设置,运行登陆脚本的时候会出现以下错误:

怎么下载并设置 Chromedriver 到环境变量里呢?你可以在这里下载到最新版的chromedriver:
https://chromedriver.chromium.org/
现在最新版 Chromedriver 版本号到了 91.0.4472.101,下载链接如下: https://chromedriver.storage.googleapis.com/index.html?path=91.0.4472.101
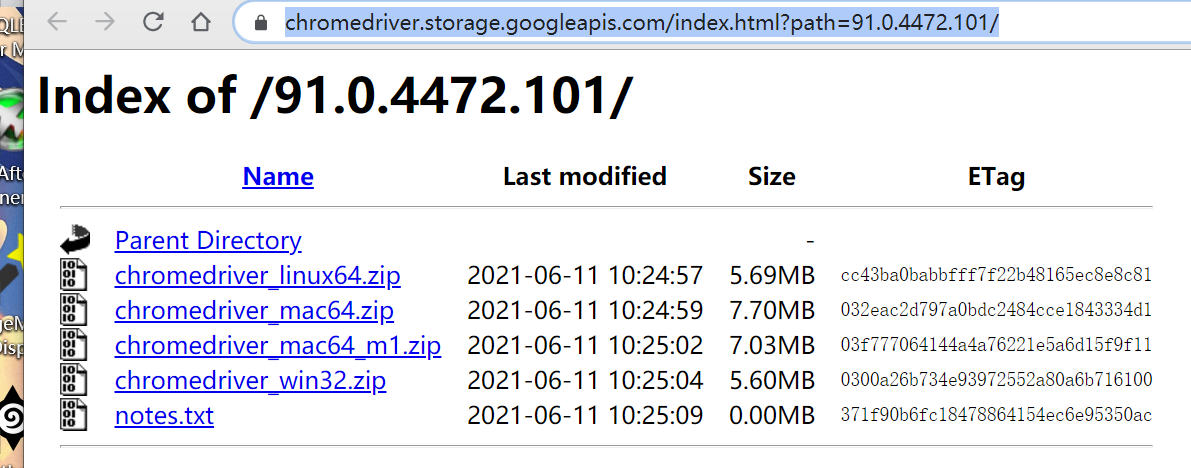
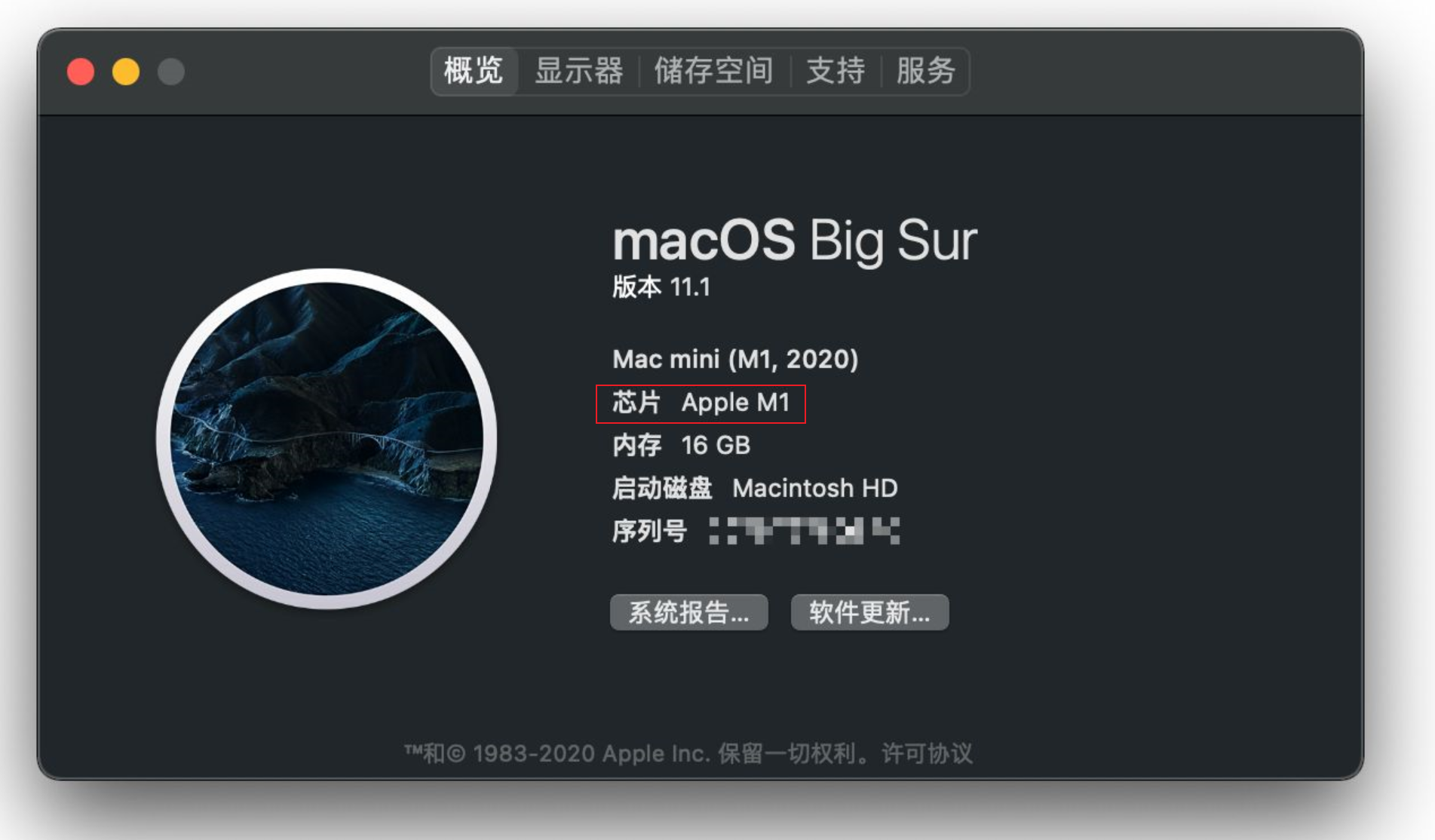
可以看到,每个系统需要下载的 Chromedriver 版本不一样,请对应你的系统下载指定的版本即可。mac64 和 mac_m1指的是使用了不同芯片的Mac笔记本,你可以在Mac上,单击菜单栏左上角的[Apple]图标,然后选择“关于本机”选项。看到如下写着芯片 Apple M1 则应该下载mac_m1版本。
如果你的网络存在问题无法下载,没关系,关注 Python实用宝典 公众号,后台回复 Chromedriver 即可下载,我已经把这4个版本放到了国内网盘上。
下载 Chromedriver 完成后,你还需要设置环境变量
(macOS 系统) 请这样设置环境变量:
1. 把解压得到的 Chromedriver 放到一个你不会经常变动的路径
如 /usr/local/bin/ ,你需要 Command+空格 输入并打开终端(Terminal),执行以下命令:
cd /usr/local/bin/ open .
然后将 Chromedriver 拖入,就能成功将 Chromedriver 放入其中。
2.添加环境变量
在终端输入下列命令就能添加到环境变量:
export PATH=$PATH:/usr/local/bin/chromedriver
执行完这一步,恭喜你成功在 macOS 上安装了 Chromedriver.
(Windows 系统) 请这样设置环境变量:
1.在左下角搜索环境变量,打开“编辑系统环境变量”的选项:
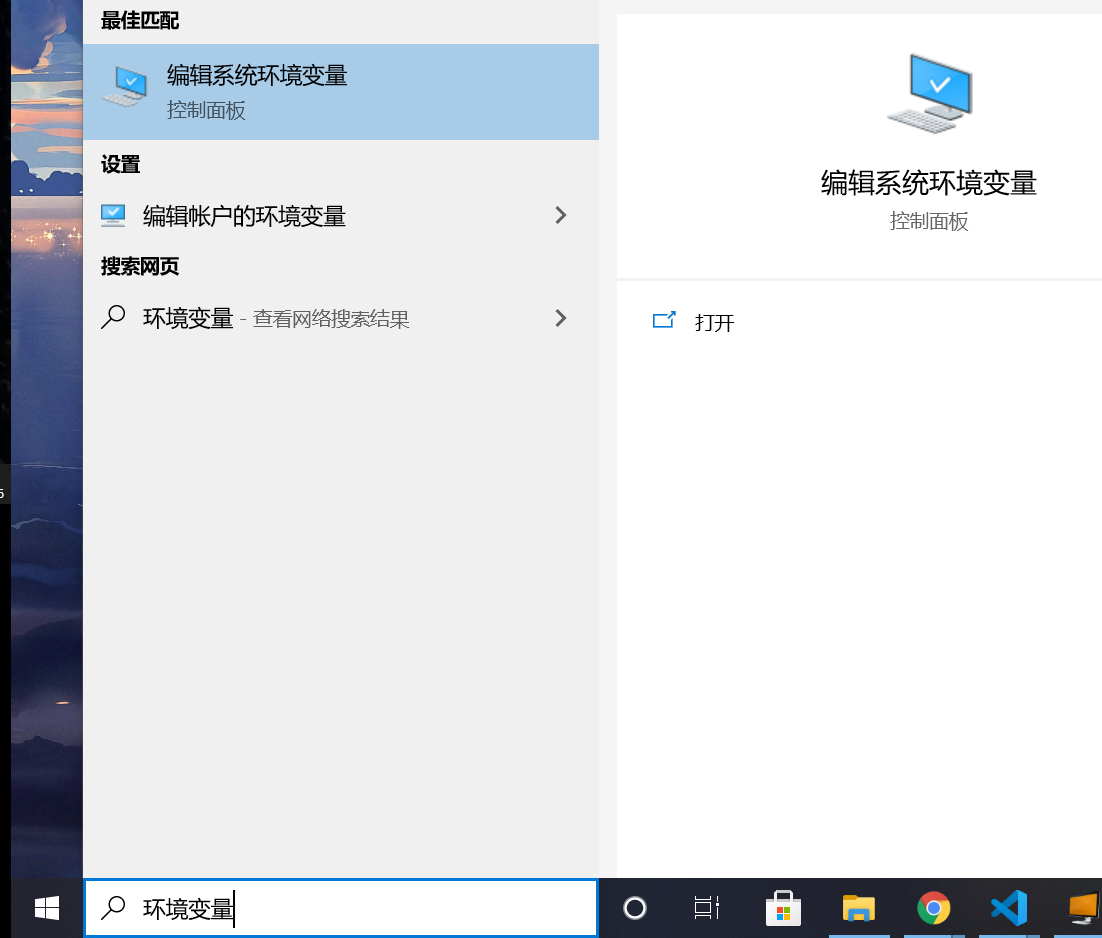
2.设置 Chromedriver 环境变量:
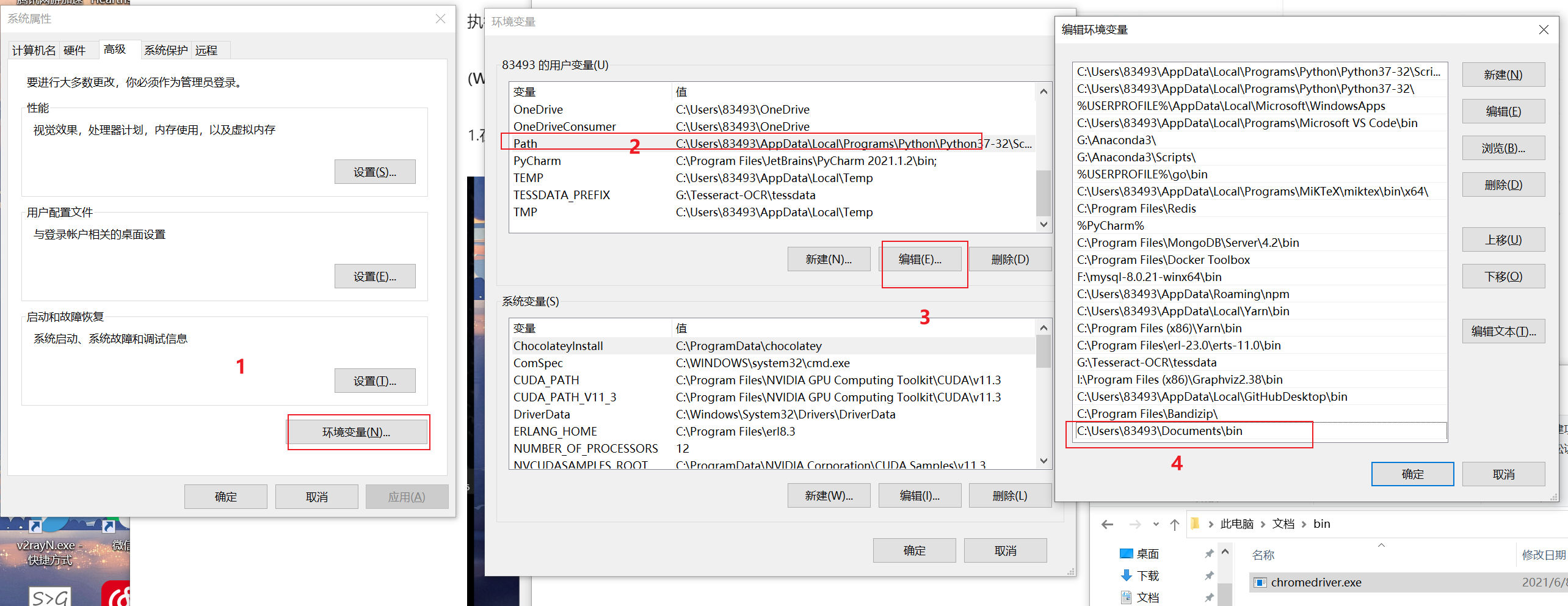
将你的 chromedriver 所在目录放入到 PATH 变量中,如图所示。比如我的 chromedriver.exe 的路径是C:\Users\83493\Documents\bin\chromedriver.exe, 那么此处就应该增加 C:\Users\83493\Documents\bin 路径。
设置完成后,你便成功在 Windows 上安装了 Chromedriver. 另外请注意设置后要重启终端或CMD让环境变量生效。
另外如果你在使用 Chromedriver 的时候出现了类似于以下的报错,不要慌:

这是由于当前 Chromedriver 版本是91, 而你现有的 Chrome 版本是 90 造成的,升级Chrome即可解决问题。
完成selenium的基本配置后,我们可以尝试运行QQ空间模拟登陆:
进入项目文件夹的qqzone文件夹:
cd awesome-python-login-model\qqzone
然后直接运行 qq_zone.py 文件:
python qq_zone.py
此时会弹出一个浏览器并让你输入信息:
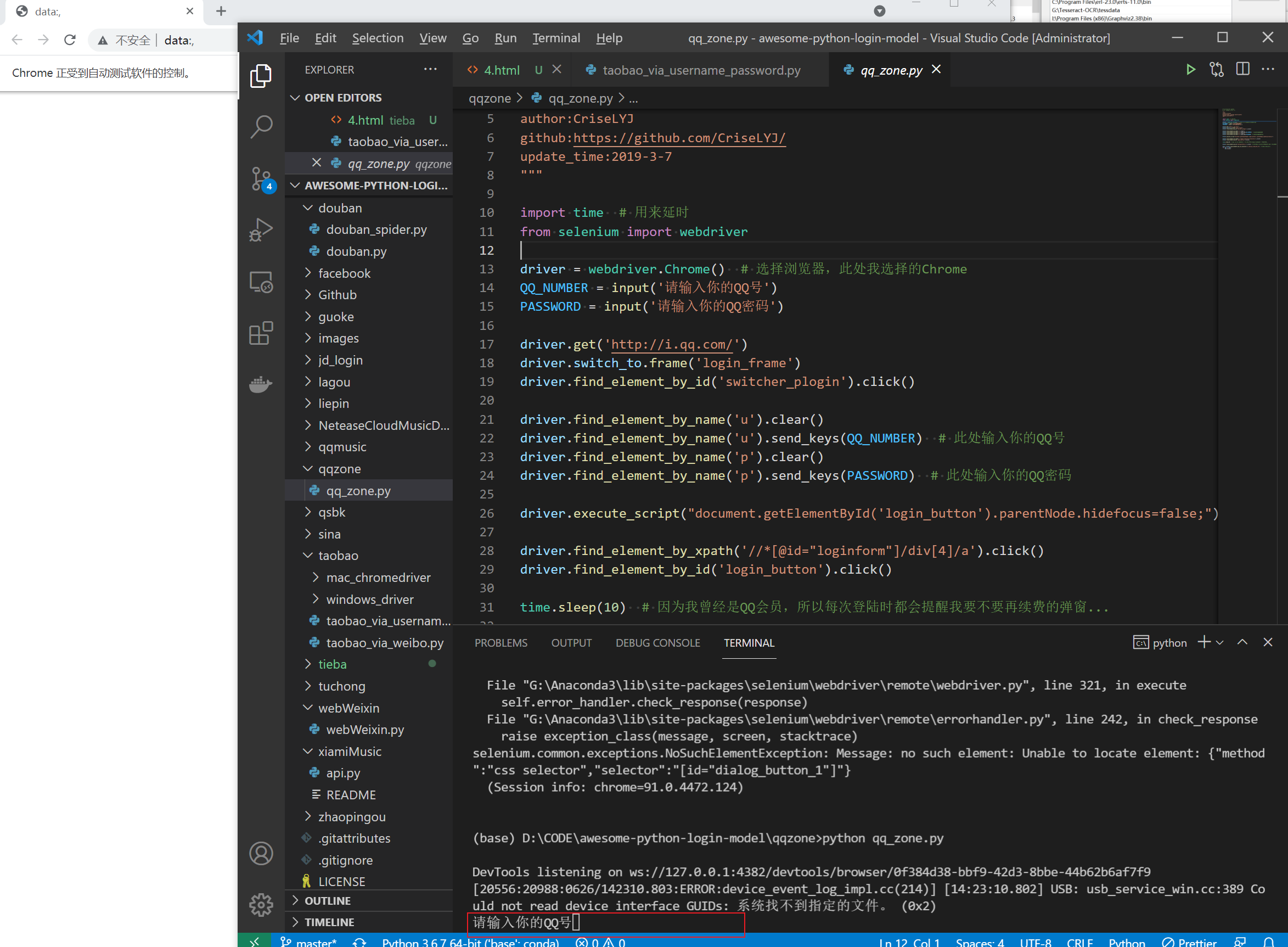
输入信息后,就会正常走登陆流程:

看到如上的界面,说明登陆完成,此时Cookie什么的都已经被设定完毕,你可以把Cookie存下来,并做任何你想做的事情了。
如果你愿意研究作者的代码,你会发现其实很简单:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
info:
author:CriseLYJ
github:https://github.com/CriseLYJ/
update_time:2019-3-7
"""
import time # 用来延时
from selenium import webdriver
driver = webdriver.Chrome() # 选择浏览器,此处我选择的Chrome
QQ_NUMBER = input('请输入你的QQ号')
PASSWORD = input('请输入你的QQ密码')
driver.get('http://i.qq.com/')
driver.switch_to.frame('login_frame')
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_name('u').clear()
driver.find_element_by_name('u').send_keys(QQ_NUMBER) # 此处输入你的QQ号
driver.find_element_by_name('p').clear()
driver.find_element_by_name('p').send_keys(PASSWORD) # 此处输入你的QQ密码
driver.execute_script("document.getElementById('login_button').parentNode.hidefocus=false;")
driver.find_element_by_xpath('//*[@id="loginform"]/div[4]/a').click()
driver.find_element_by_id('login_button').click()
time.sleep(10) # 因为我曾经是QQ会员,所以每次登陆时都会提醒我要不要再续费的弹窗...
driver.find_element_by_id('dialog_button_1').click() # 这个地方是我把那个弹窗给点击了,配合上面的延时用的,延时是等待那个弹窗出现,然后此处点击取消
btns = driver.find_elements_by_css_selector('a.item.qz_like_btn_v3') # 此处是CSS选择器
for btn in btns:
btn.click()
简单的讲,代码一共分了4个步骤,分别如下:
1.让使用者输入QQ号和密码。
2.切换浏览器焦点到登录框中,选择元素输入账号和密码。
3.为了显示登录按钮,执行了以下脚本:
driver.execute_script("document.getElementById('login_button').parentNode.hidefocus=false;")4.点击确认按钮,完成登录。
可以看到,基于 Selenium 的自动化控制一点都不难,一旦熟悉控制流程及相应的方法后应该如鱼得水。只要你度过一开始安装 Chromedriver 时的繁琐阶段,后面代码开发时多参考他人的代码,Selenium这个自动化工具是可以被熟练掌握的。
总而言之,Awesome-python-login-model 这个模拟登陆的代码库,可以给你带来不少的便利,你可以直接基于它提供的登陆脚本开发,也可以参考这些脚本自己写一个其他网站的模拟登陆脚本,并给作者提交PR。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

评论(0)