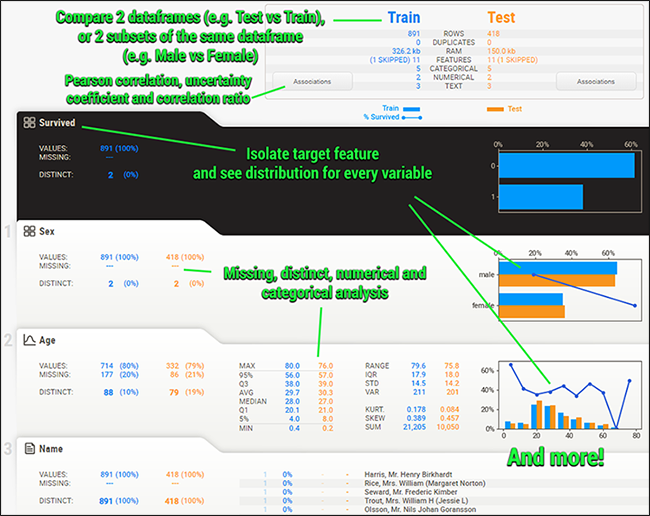
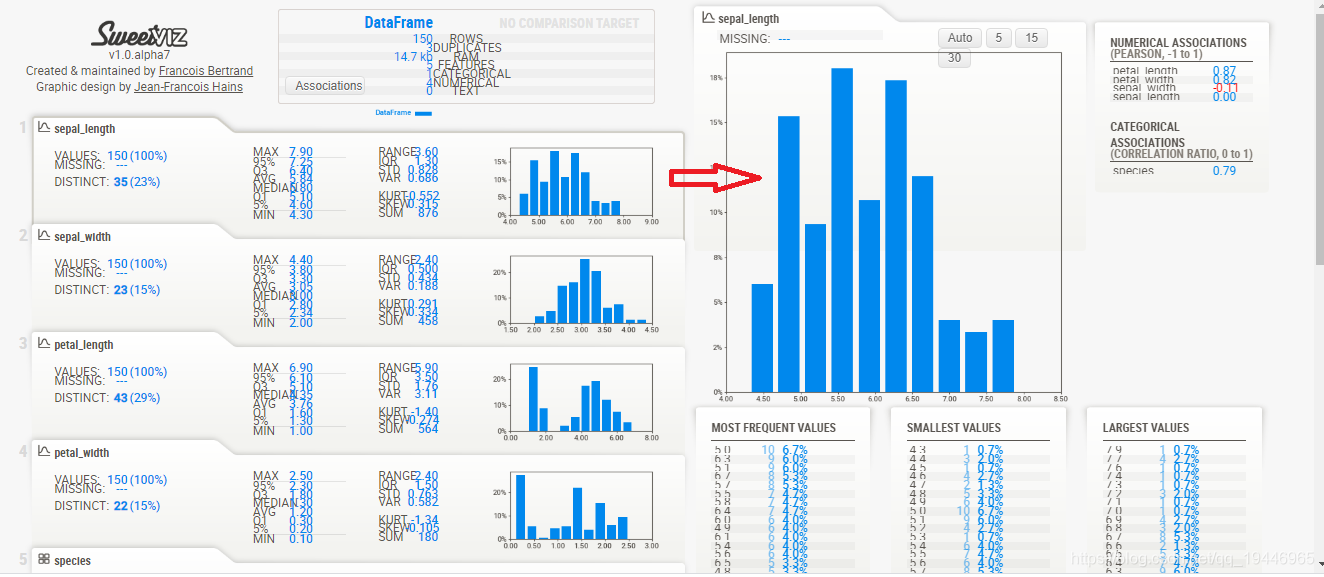
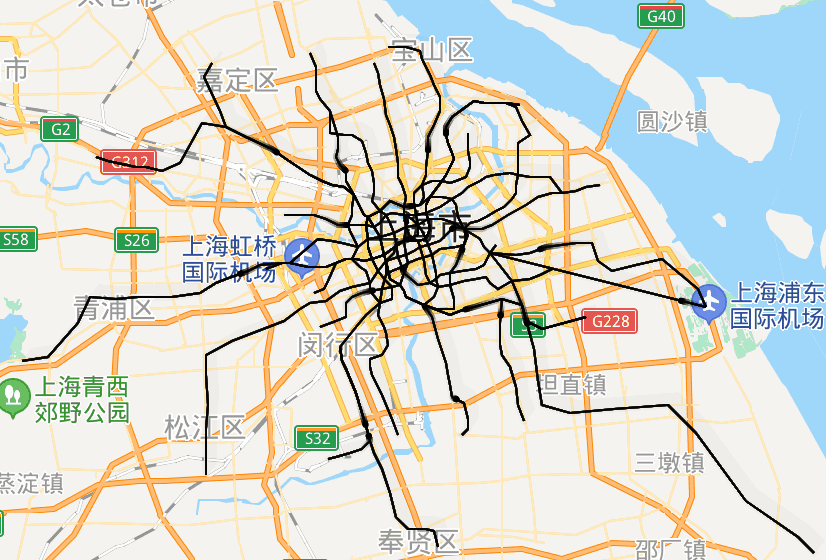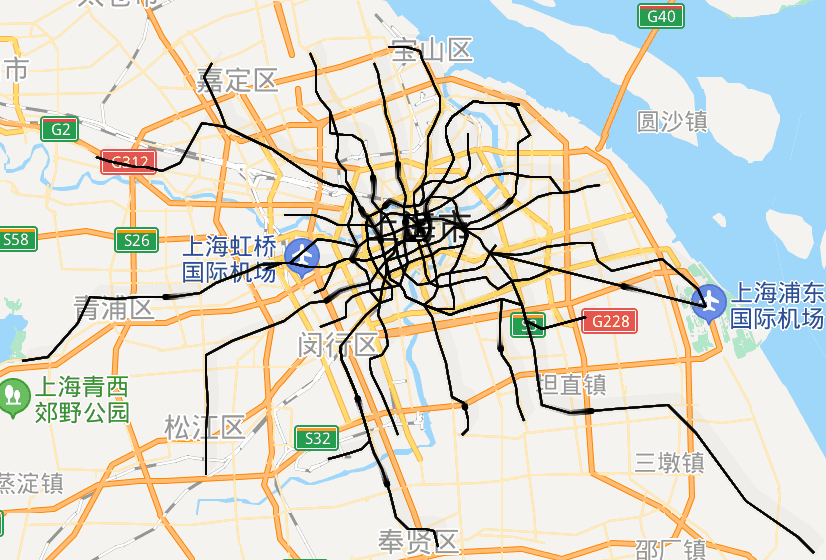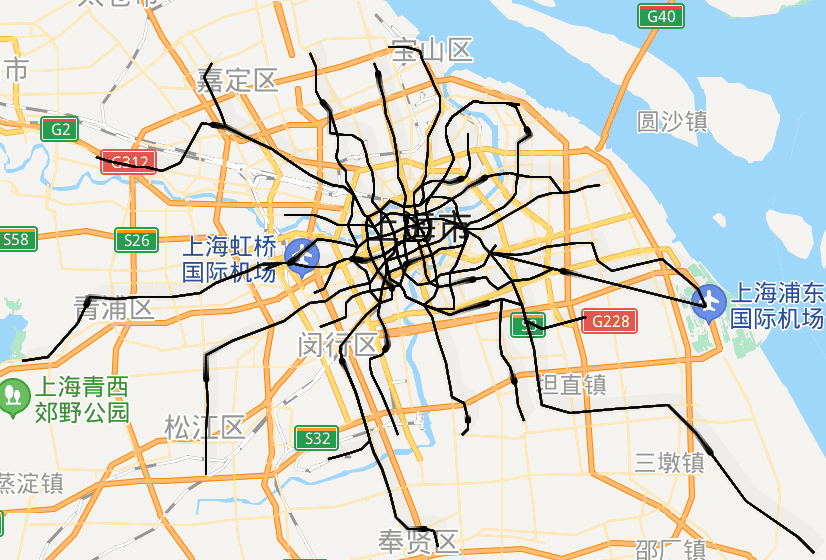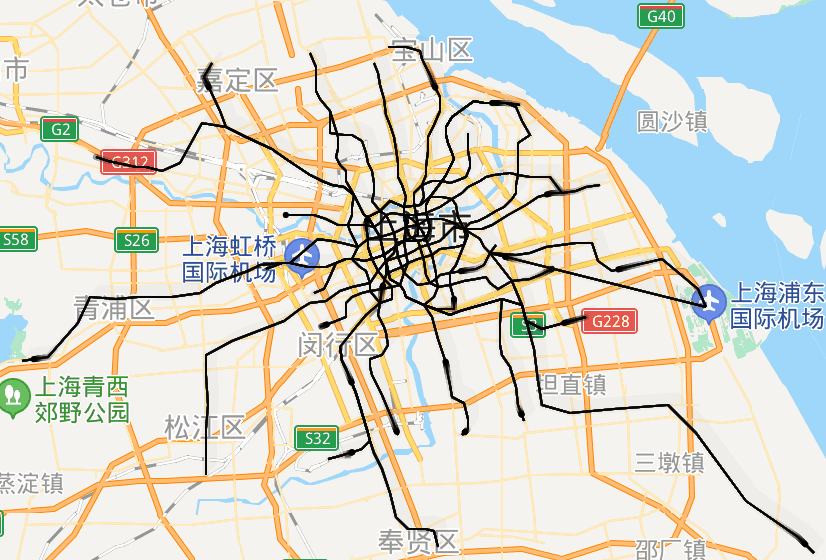
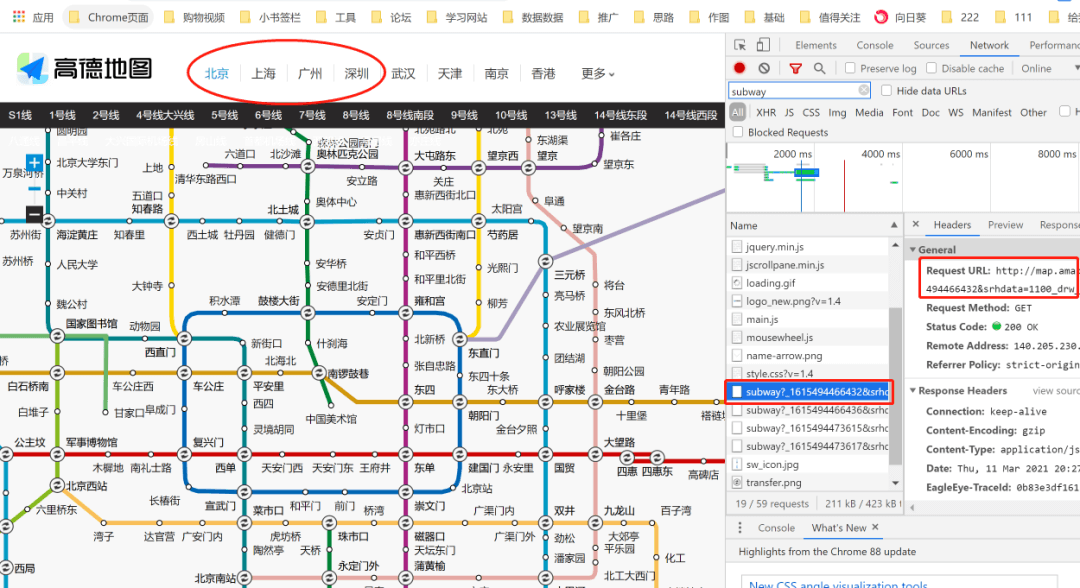
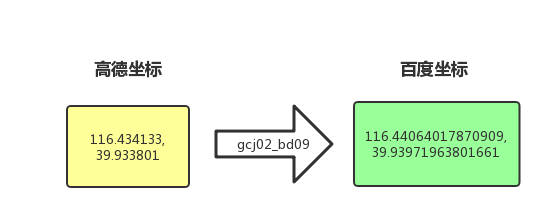
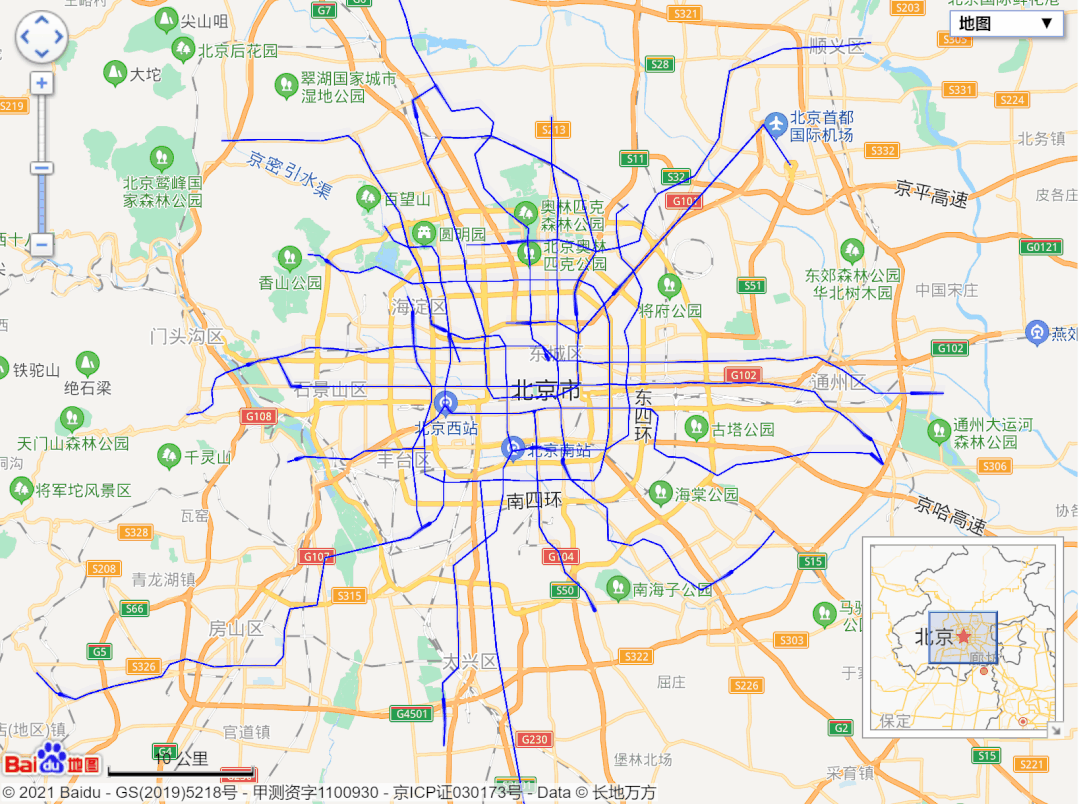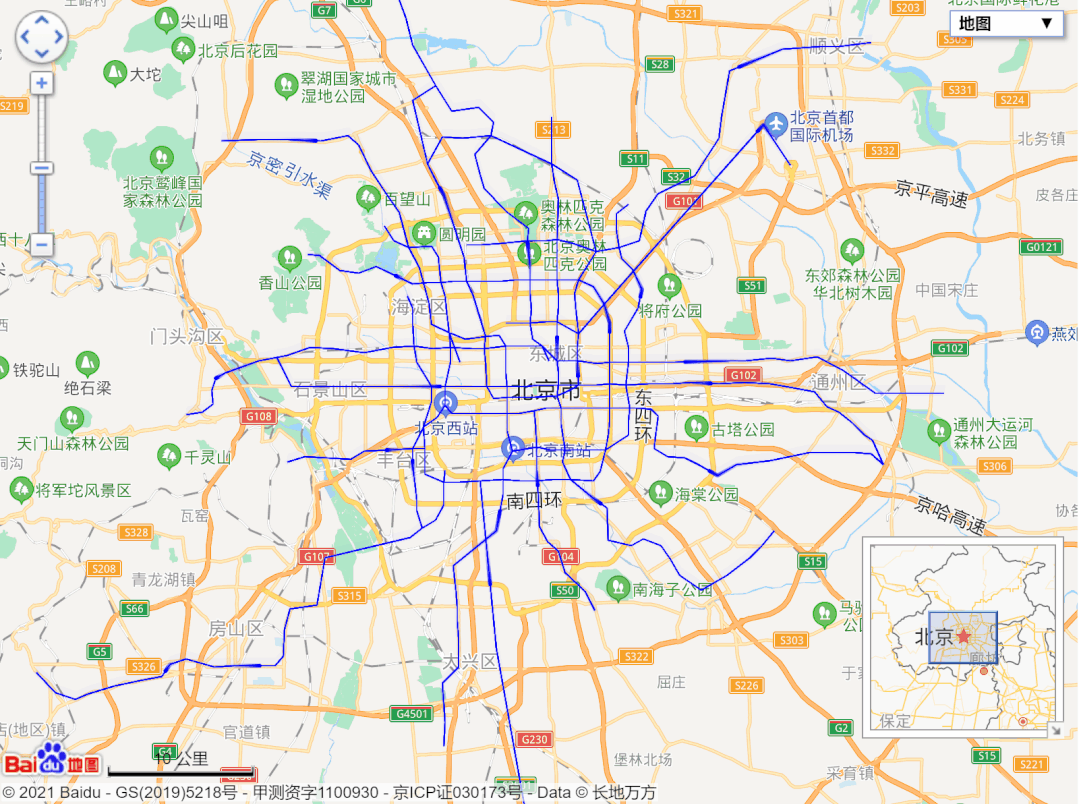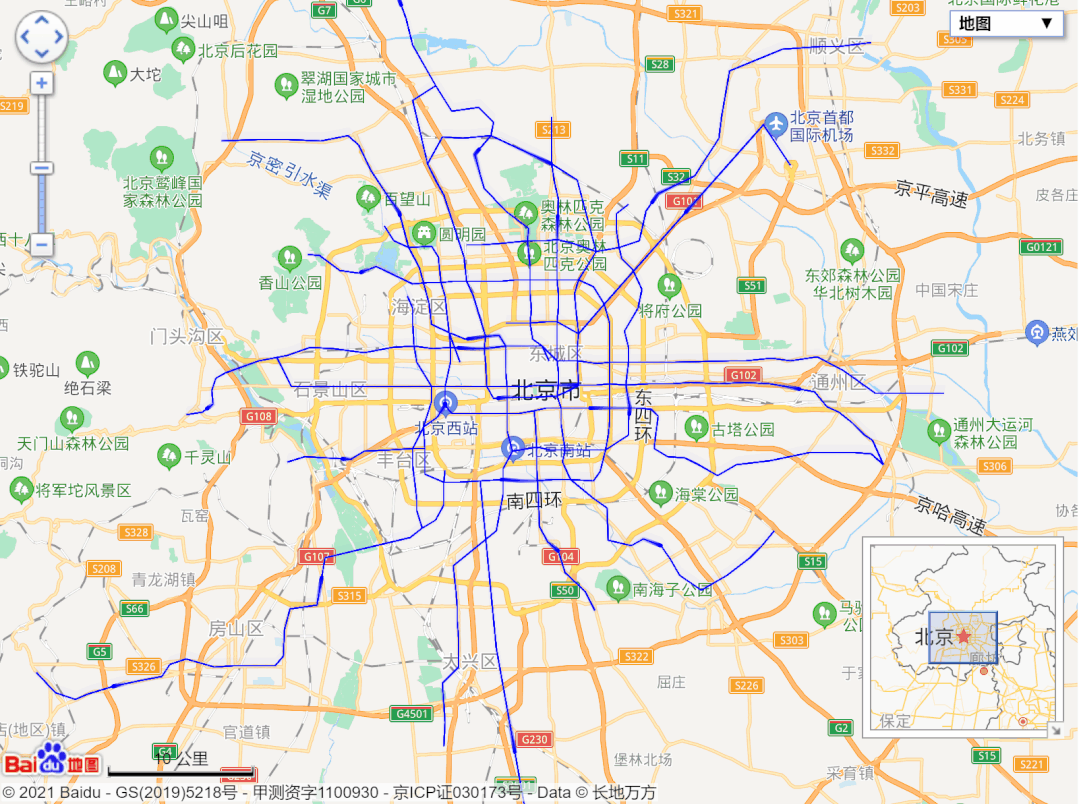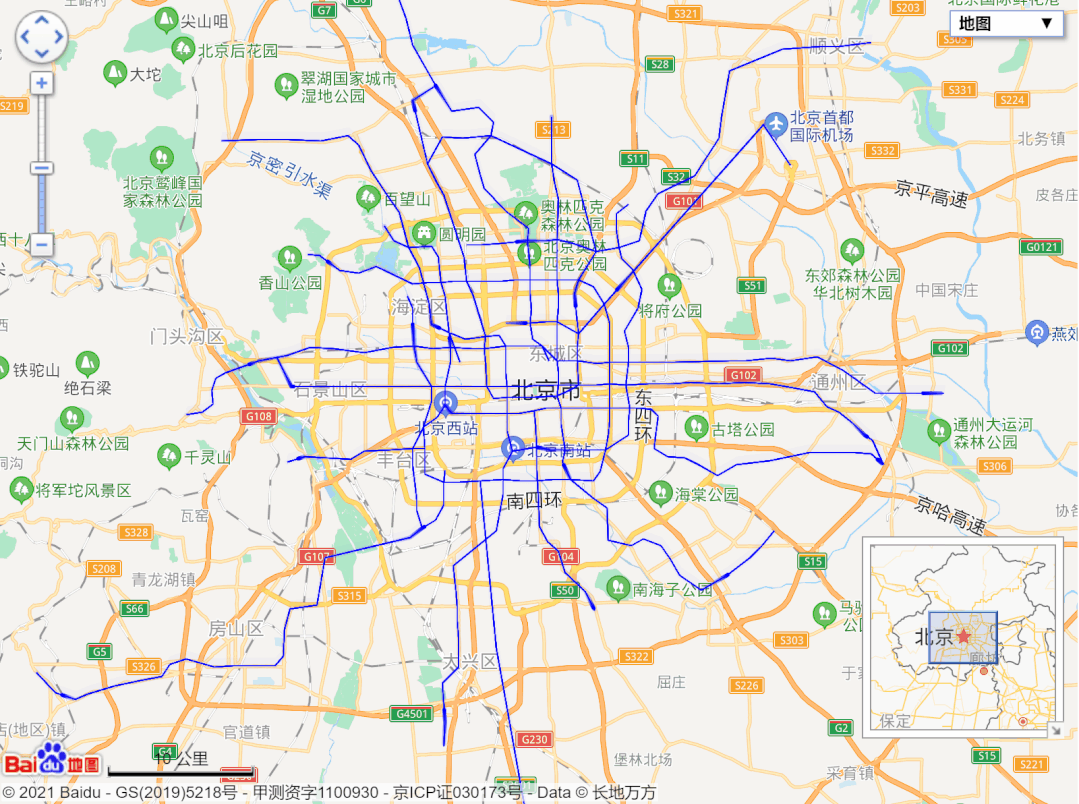
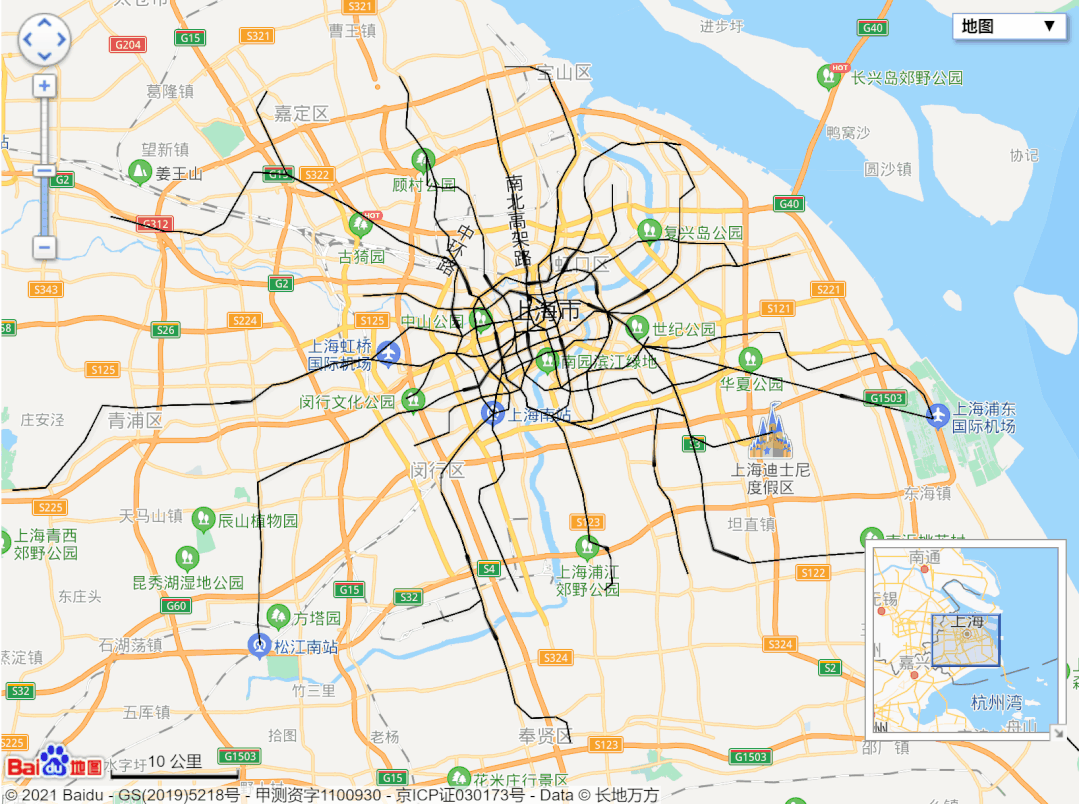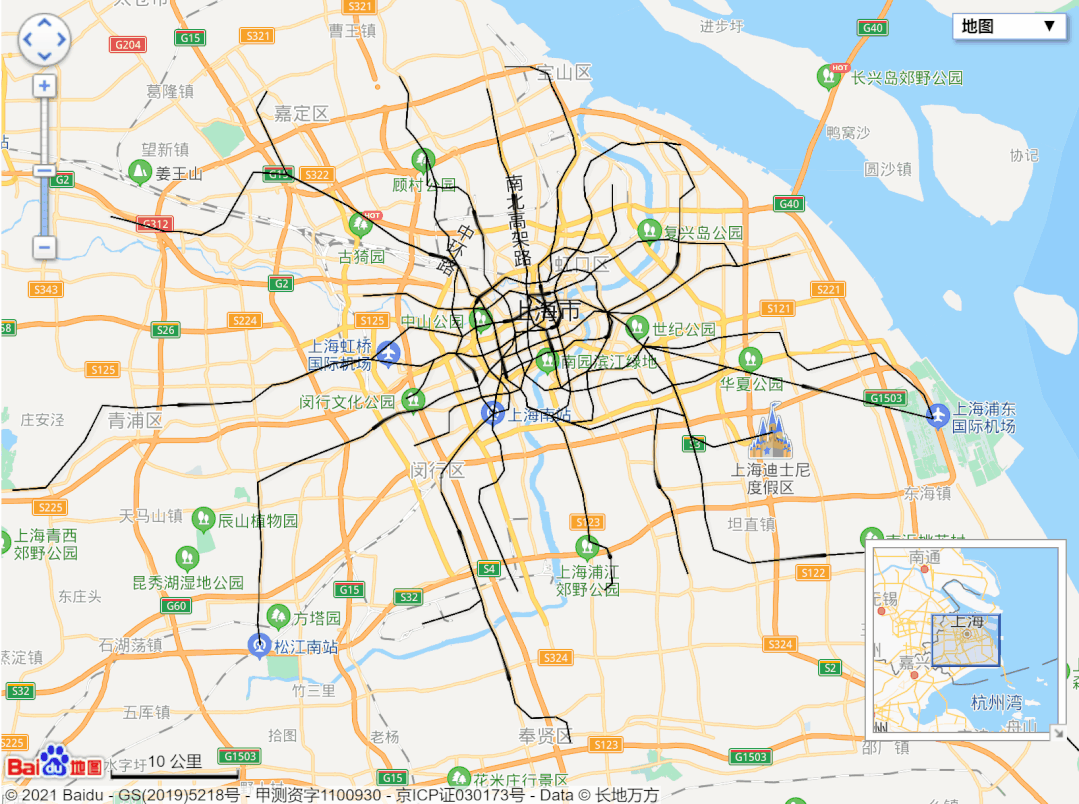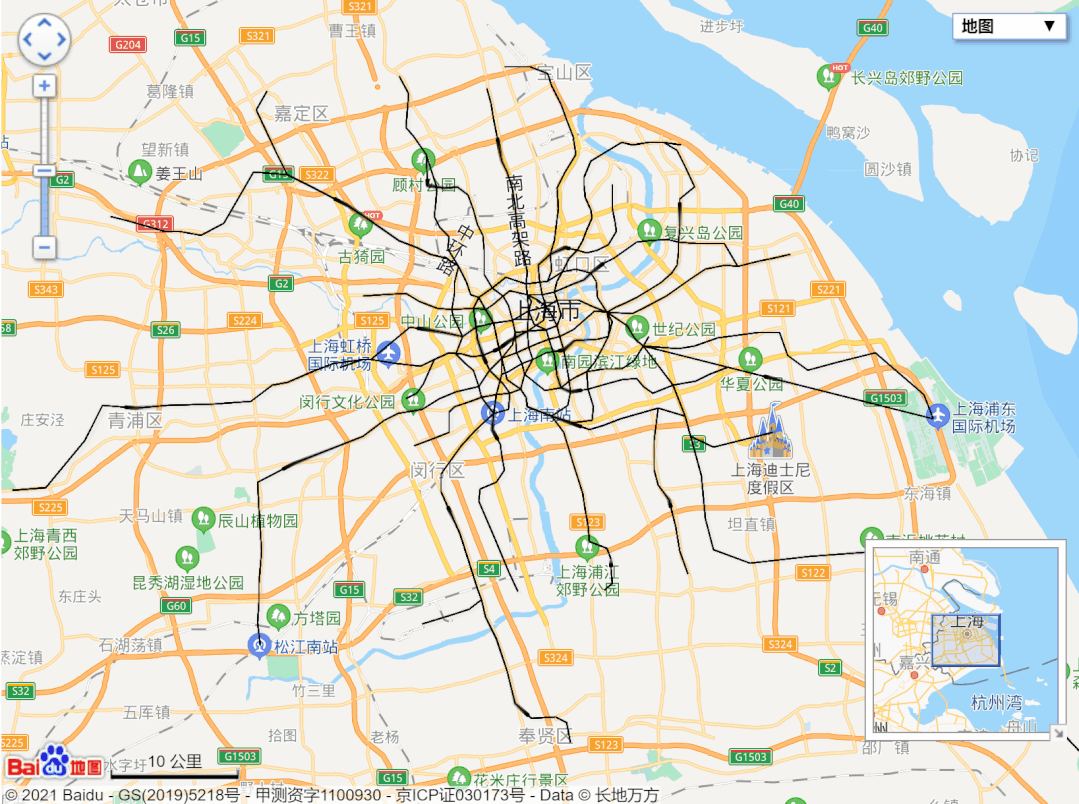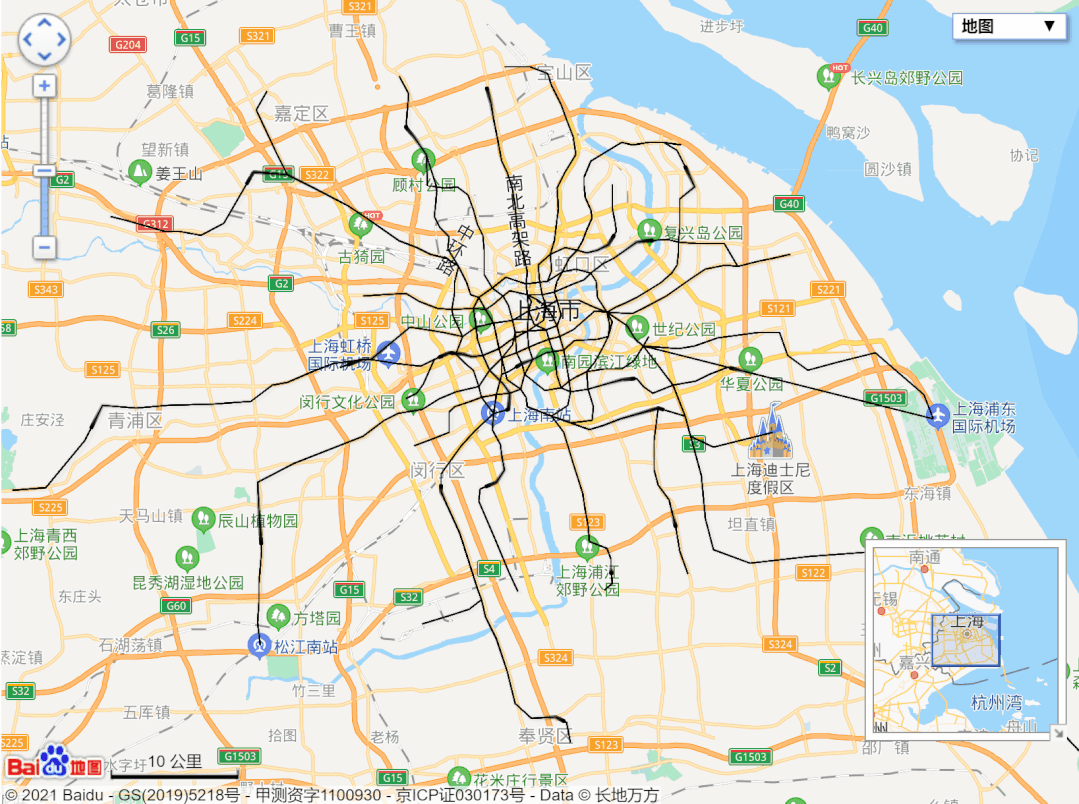
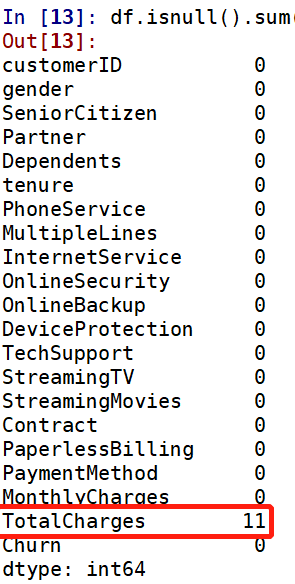
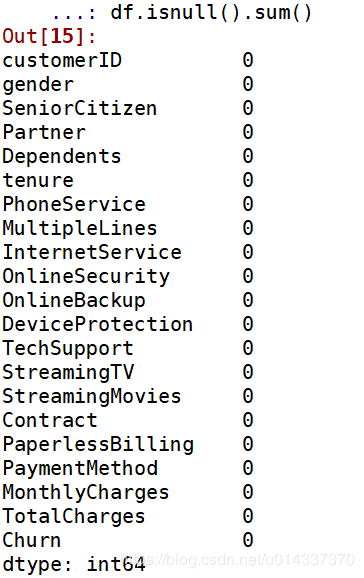
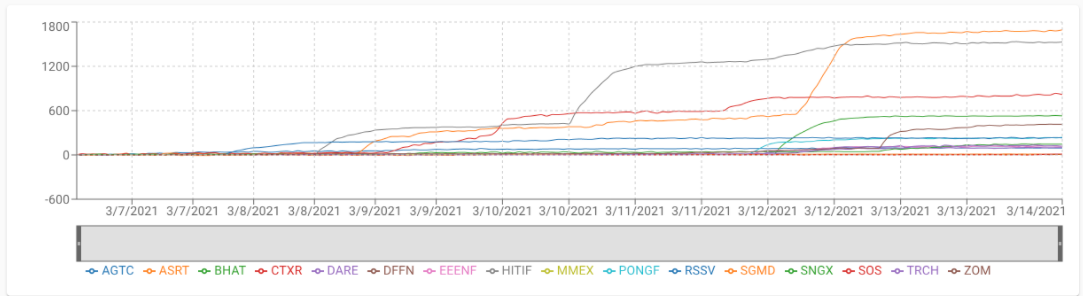
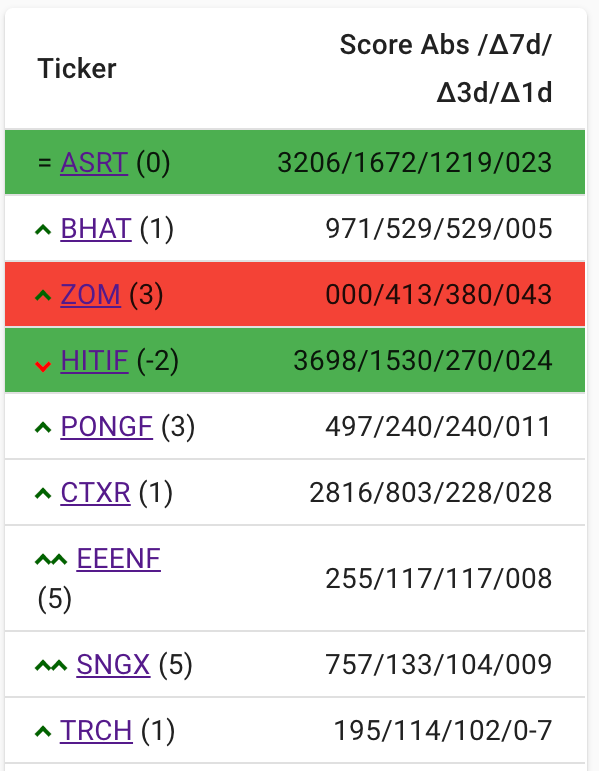
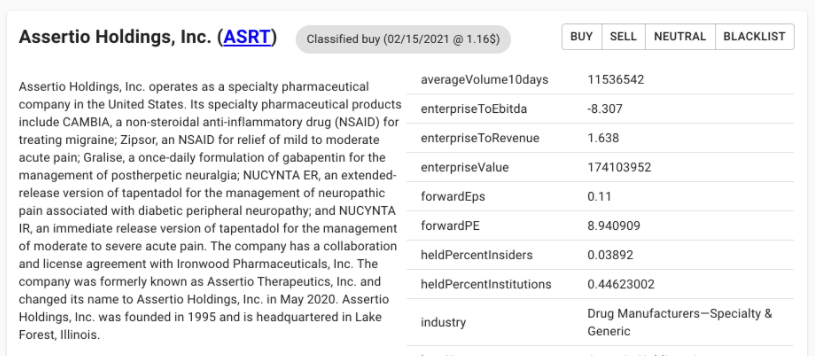
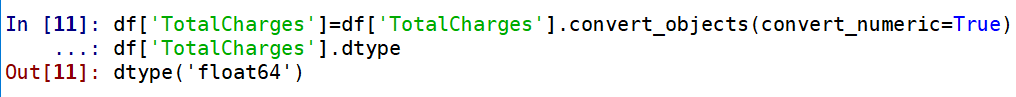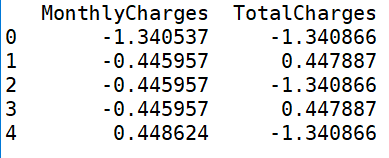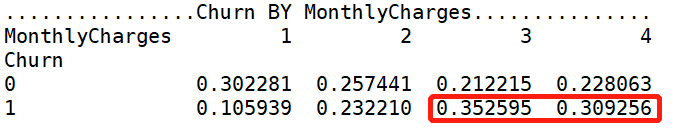url = 'http://map.amap.com/service/subway?_1615466846985&srhdata=1100_drw_beijing.json'
response = requests.get(url)
result = json.loads(response.text)
stations = []
for i in result['l']:
station = []
for a in i['st']:
station.append([float(b) for b in a['sl'].split(',')])
stations.append(station)
pprint.pprint(stations)
import matplotlib.pyplot as plt import seaborn as sns sns.set(style='darkgrid',font_scale=1.3) plt.rcParams['font.family']='SimHei' plt.rcParams['axes.unicode_minus']=False
6.1.3 特征工程
import sklearn from sklearn import preprocessing #数据预处理模块 from sklearn.preprocessing import LabelEncoder #编码转换 from sklearn.preprocessing import StandardScaler #归一化 from sklearn.model_selection import StratifiedShuffleSplit #分层抽样 from sklearn.model_selection import train_test_split #数据分区 from sklearn.decomposition import PCA #主成分分析 (降维)
6.1.4 分类算法
from sklearn.ensemble import RandomForestClassifier #随机森林 from sklearn.svm import SVC,LinearSVC #支持向量机 from sklearn.linear_model import LogisticRegression #逻辑回归 from sklearn.neighbors import KNeighborsClassifier #KNN算法 from sklearn.cluster import KMeans #K-Means 聚类算法 from sklearn.naive_bayes import GaussianNB #朴素贝叶斯 from sklearn.tree import DecisionTreeClassifier #决策树
6.1.5 分类算法–集成学习
import xgboost as xgb from xgboost import XGBClassifier from catboost import CatBoostClassifier from sklearn.ensemble import AdaBoostClassifier from sklearn.ensemble import GradientBoostingClassifier
6.1.6 模型评估
from sklearn.metrics import classification_report,precision_score,recall_score,f1_score #分类报告 from sklearn.metrics import confusion_matrix #混淆矩阵 from sklearn.metrics import silhouette_score #轮廓系数(评价k-mean聚类效果) from sklearn.model_selection import GridSearchCV #交叉验证 from sklearn.metrics import make_scorer from sklearn.ensemble import VotingClassifier #投票
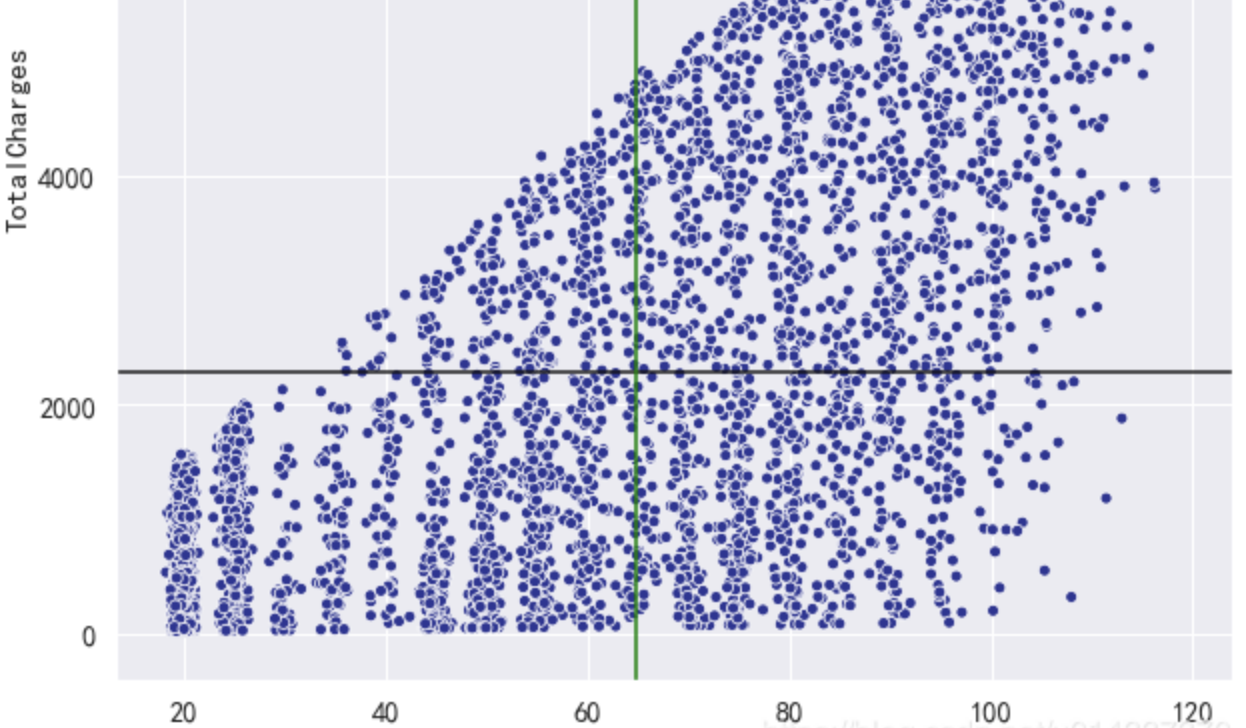
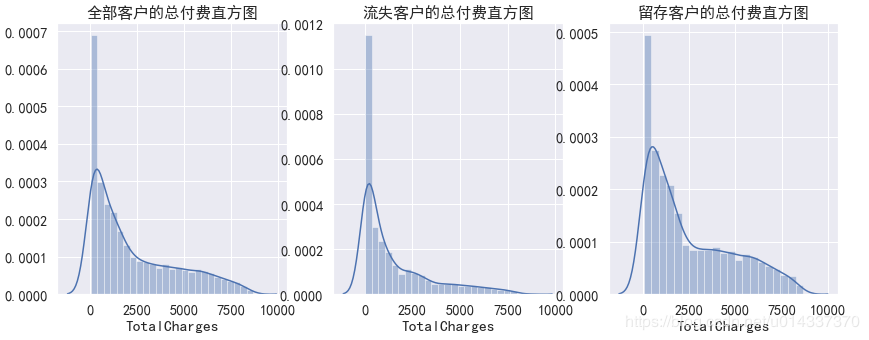
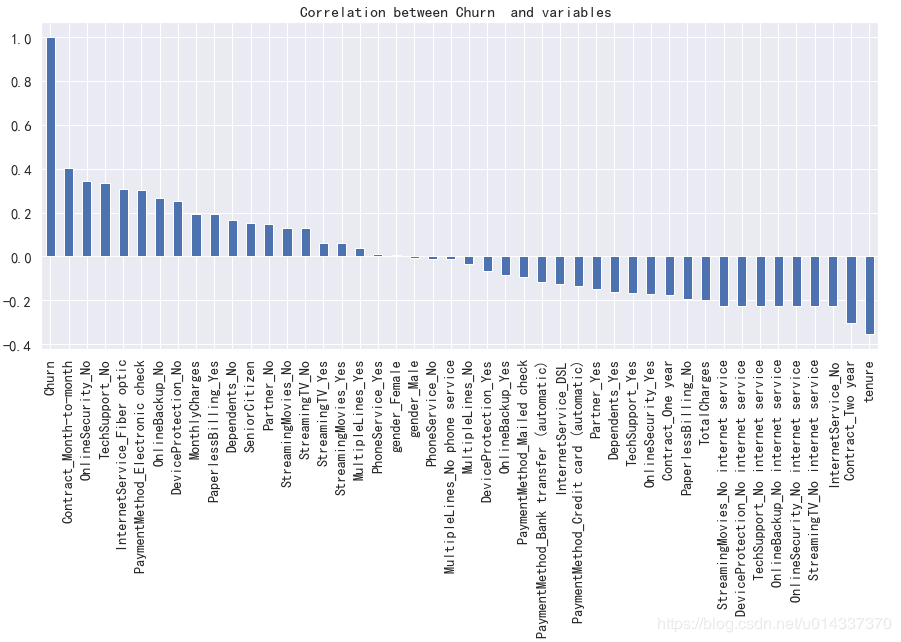
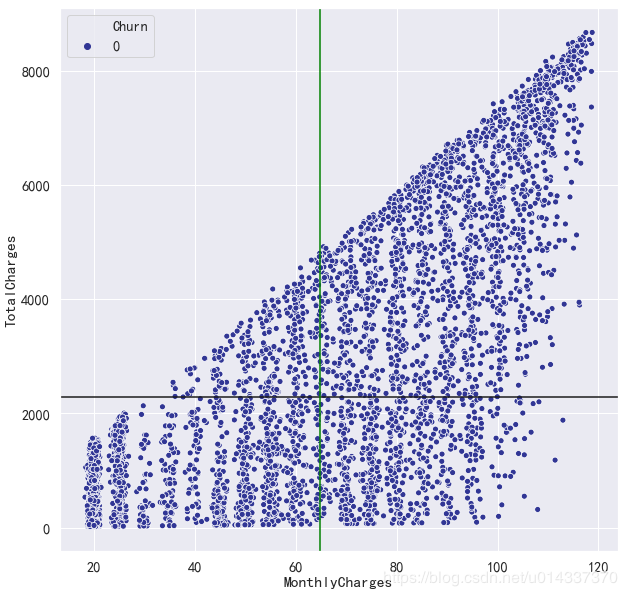
plt.figure(figsize=(15,6)) df_onehot.corr()['Churn'].sort_values(ascending=False).plot(kind='bar') plt.title('Correlation between Churn and variables ')
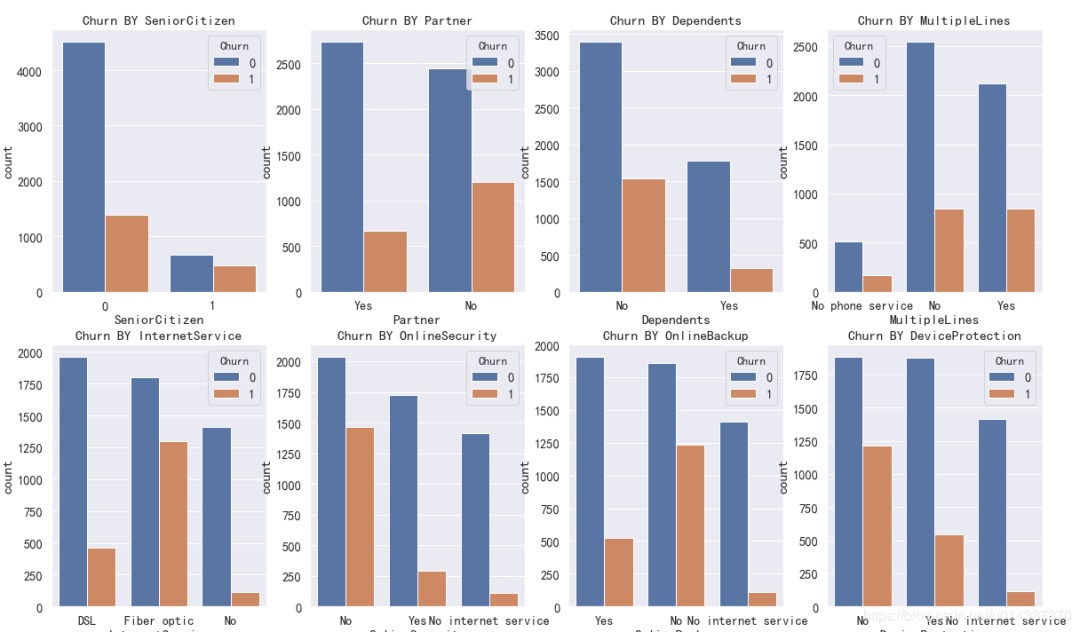
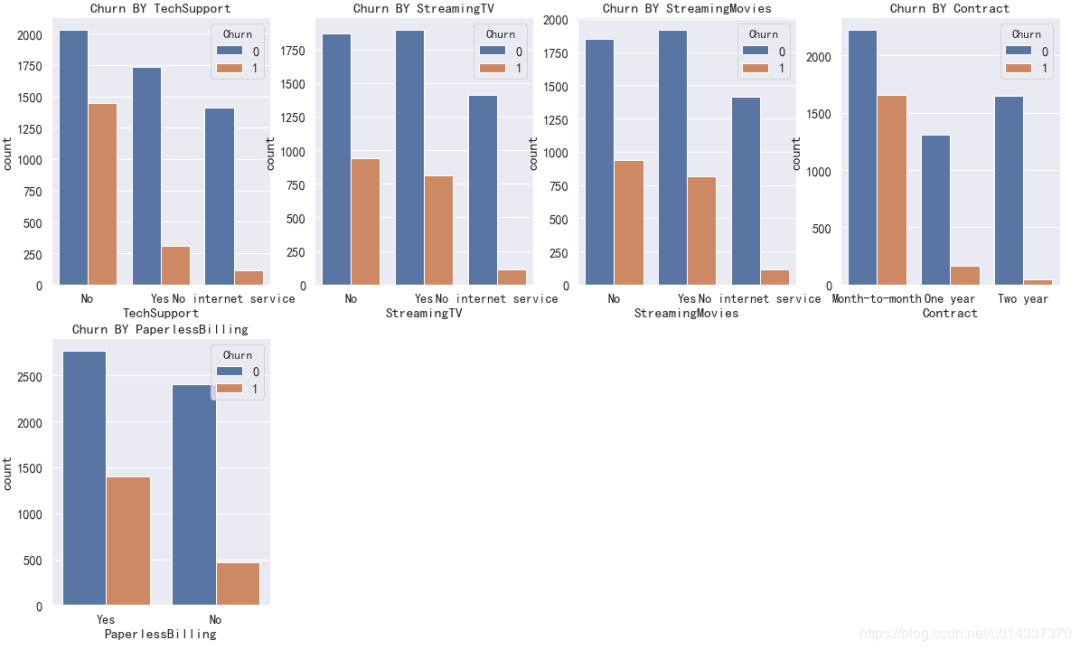
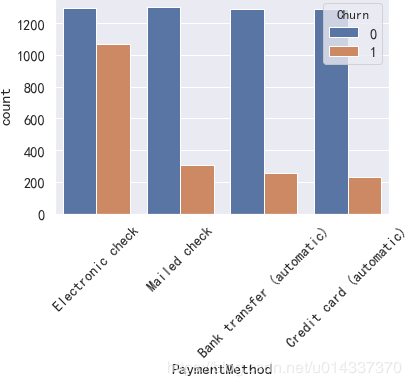
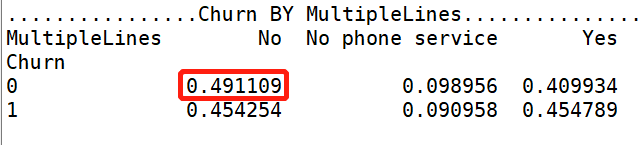
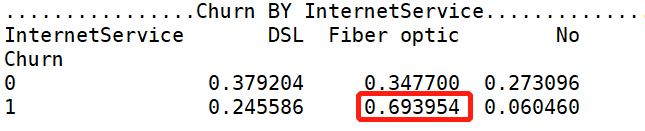
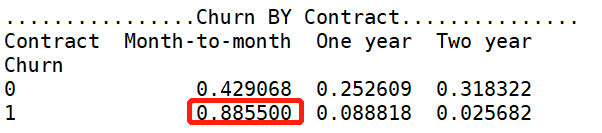
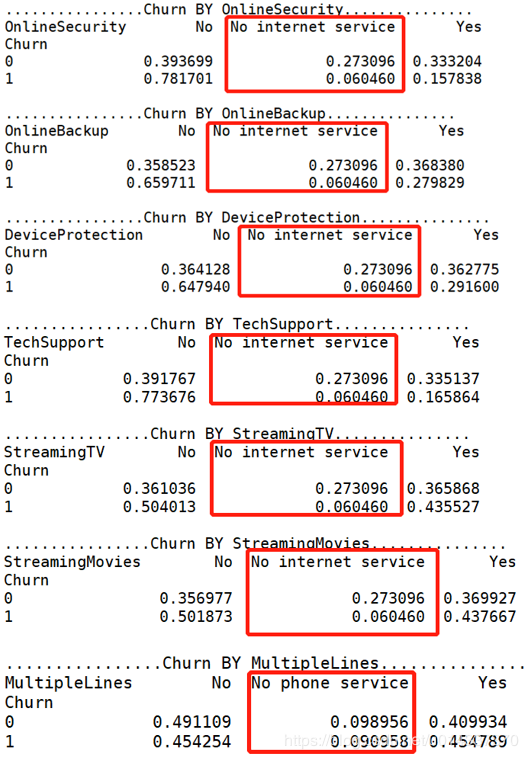
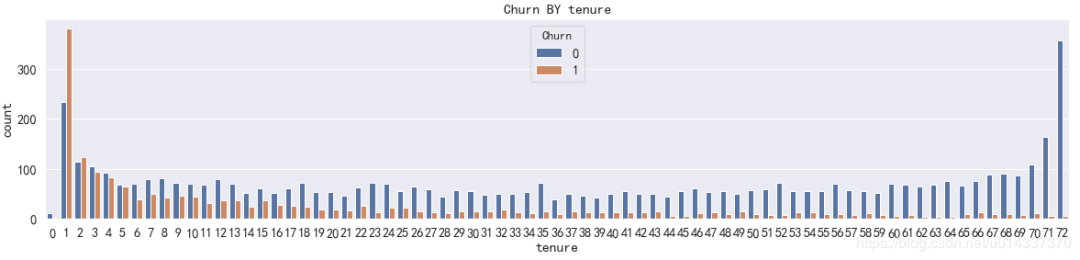
print('ka_var列表中的维度与Churn交叉分析结果如下:','\n') for i in kf_var: print('................Churn BY {}...............'.format(i)) print(pd.crosstab(df['Churn'],df[i],normalize=0),'\n') #交叉分析,同行百分比
#自定义齐性检验 & 方差分析 函数 defANOVA(x): li_index=list(df['Churn'].value_counts().keys()) args=[] for i in li_index: args.append(df[df['Churn']==i][x]) w,p=stats.levene(*args) #齐性检验 if p<0.05: print('警告:Churn BY {}的P值为{:.2f},小于0.05,表明齐性检验不通过,不可作方差分析'.format(x,p),'\n') else: f,p_value=stats.f_oneway(*args) #方差分析 print('Churn BY {} 的f值是{},p_value值是{}'.format(x,f,p_value),'\n') if p_value<0.05: print('Churn BY {}的均值有显著性差异,可进行均值比较'.format(x),'\n') else: print('Churn BY {}的均值无显著性差异,不可进行均值比较'.format(x),'\n')
deflabelencode(x): churn_var[x] = LabelEncoder().fit_transform(churn_var[x]) for i in range(0,len(df_object.columns)): labelencode(df_object.columns[i]) print(list(map(Label,df_object.columns)))
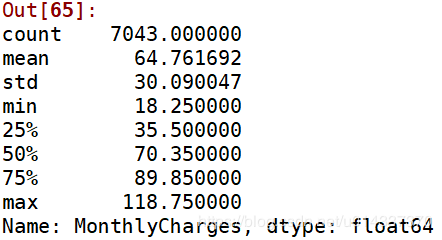
Churn by MonthlyCharges 的卡方临界值是0.00,小于0.05,表明MonthlyCharges组间有显著性差异,可进行【交叉分析】
Churn by TotalCharges 的卡方临界值是0.00,小于0.05,表明TotalCharges组间有显著性差异,可进行【交叉分析】
交叉分析
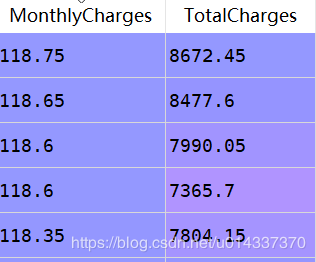
for i in ['MonthlyCharges','TotalCharges']: print('................Churn BY {}...............'.format(i)) print(pd.crosstab(df['Churn'],df[i],normalize=0),'\n')
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# 主要是新增了node_exporter的job,如果有多个node_exporter,在targets数组后面加即可
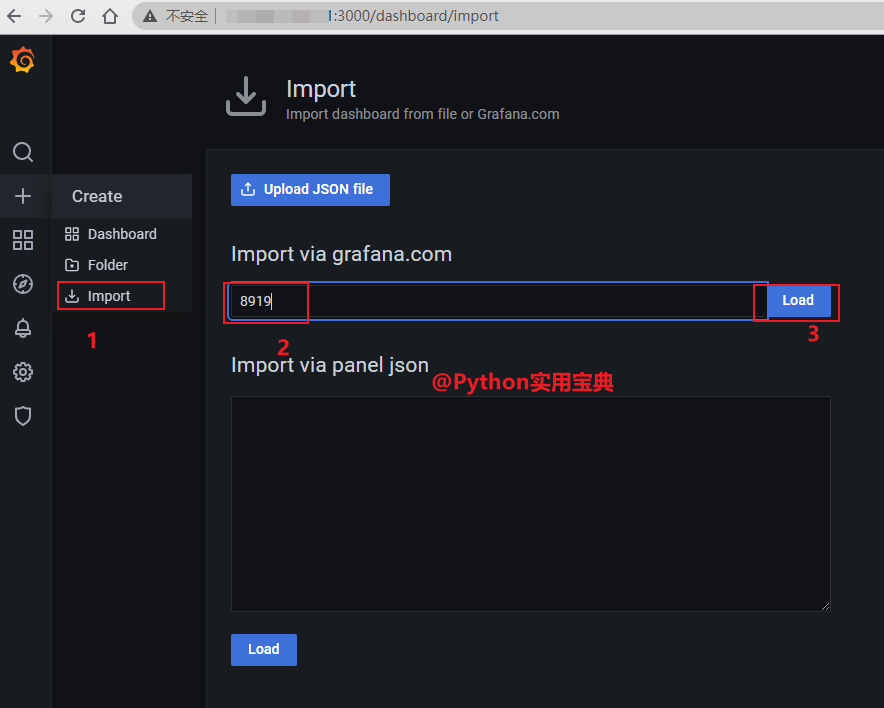
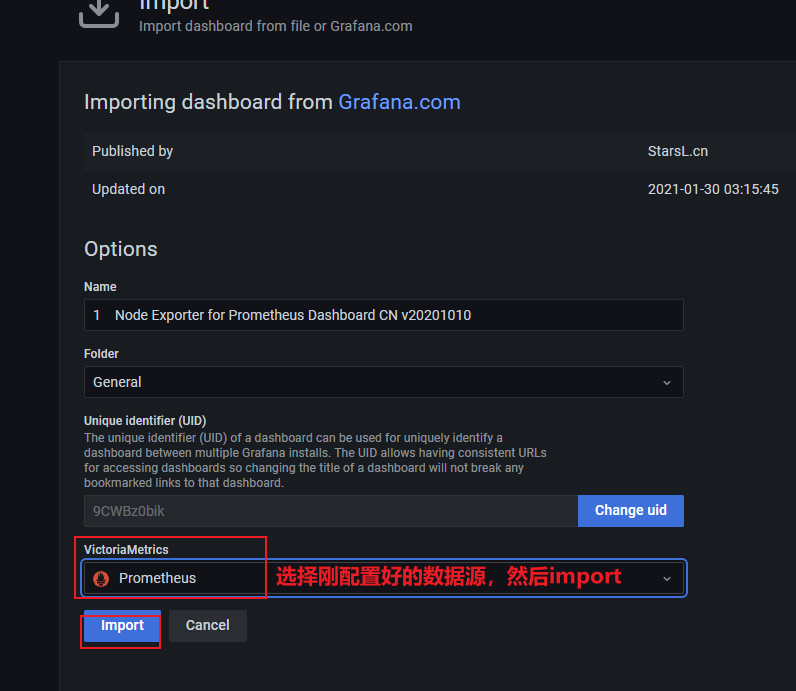
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100']
#(CentOS) vim /data/prometheus/conf/prometheus.yaml
vim /data/prometheus/conf/prometheus.yml # ubuntu
配置如下:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# 主要是新增了node_exporter的job,如果有多个node_exporter,在targets数组后面加即可
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100']
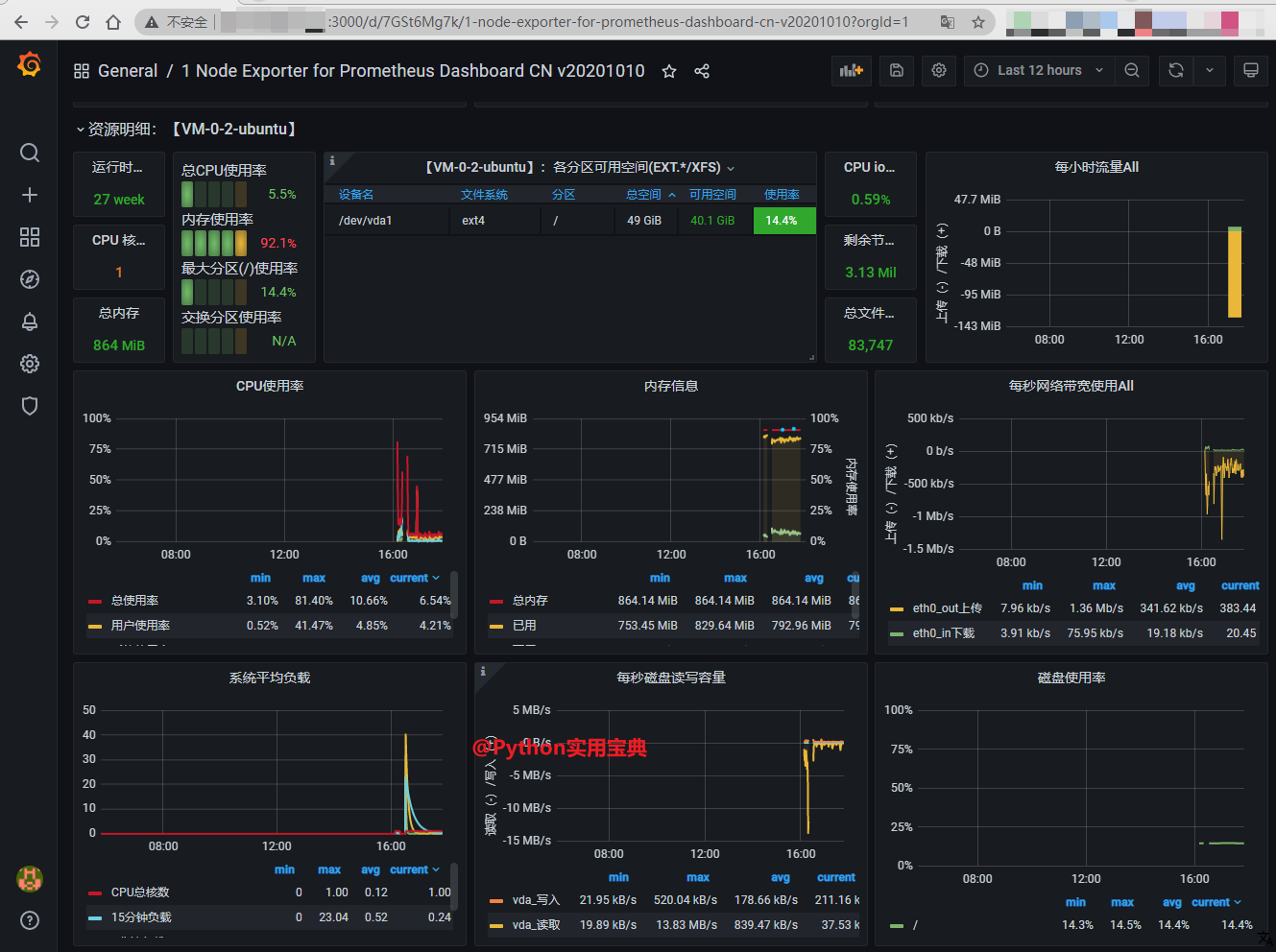
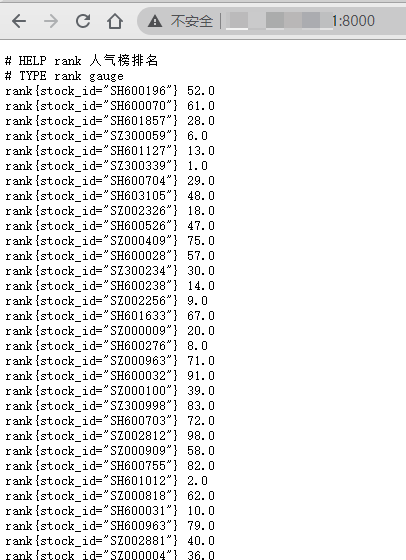
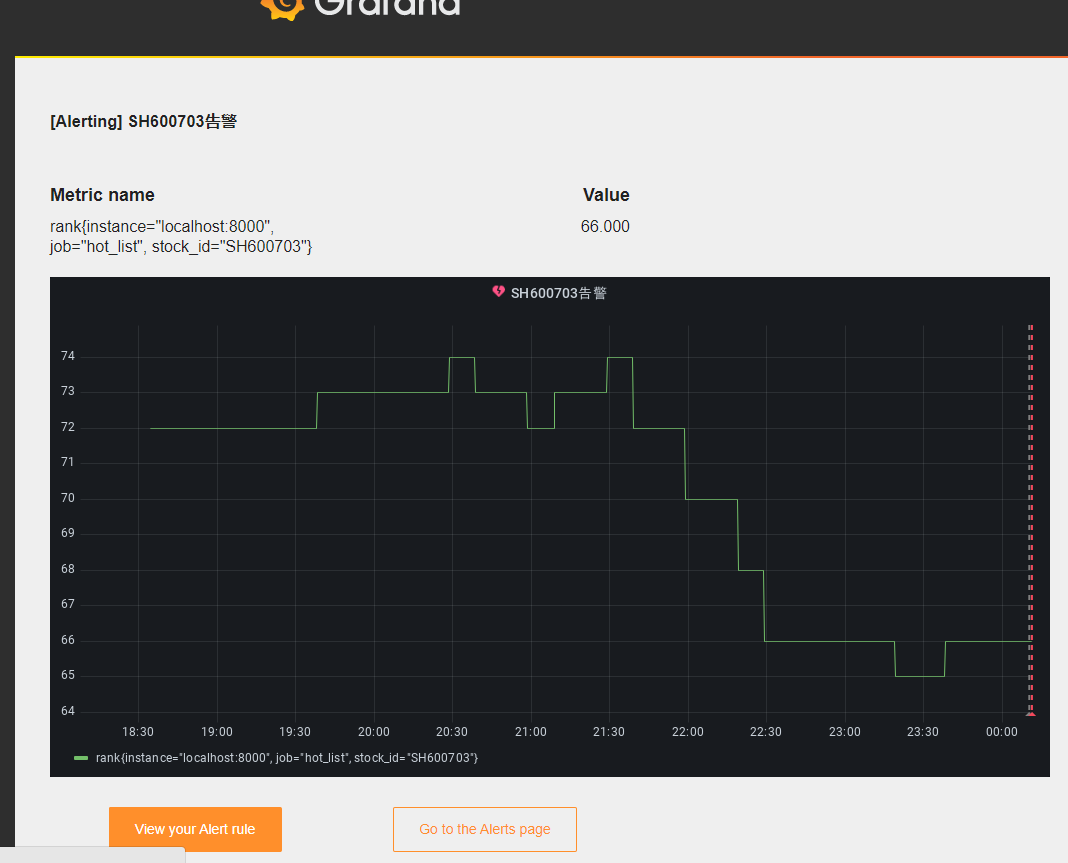
# 新增我们的Python股票采集脚本
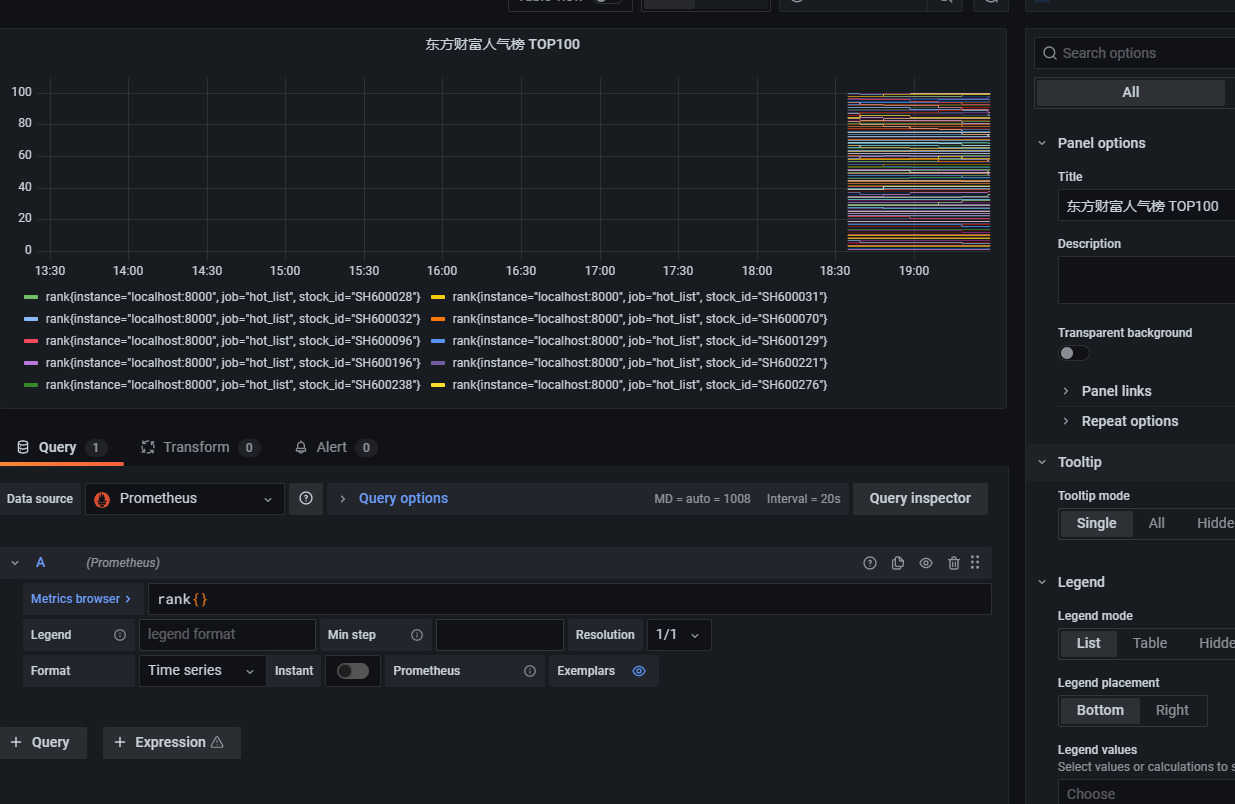
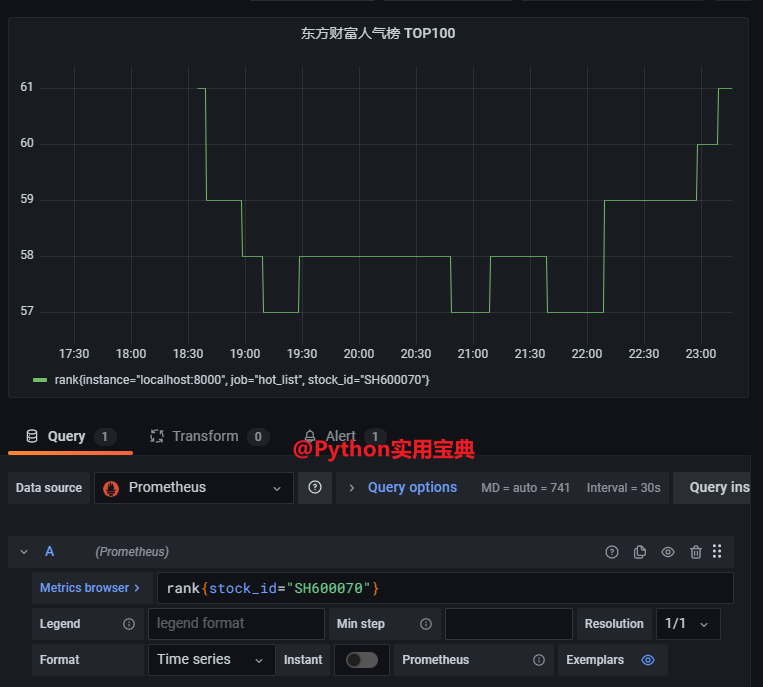
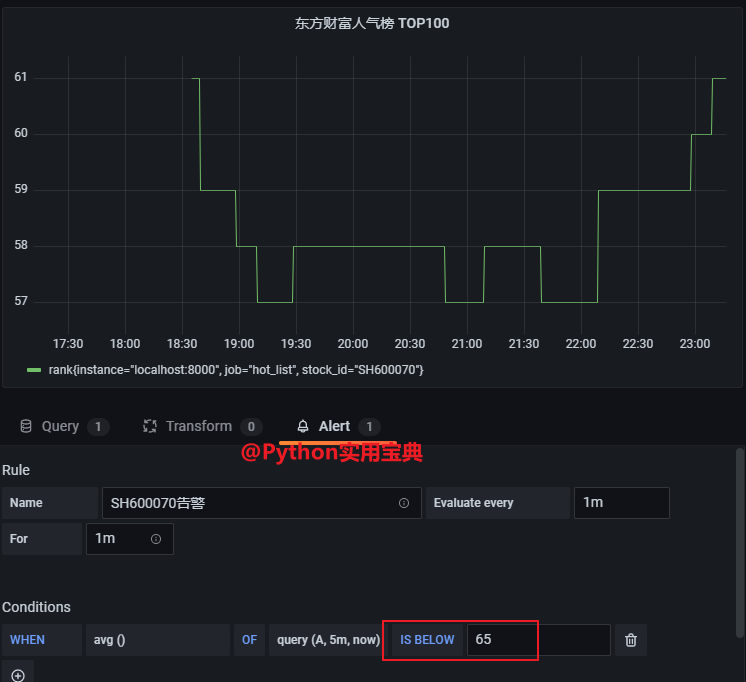
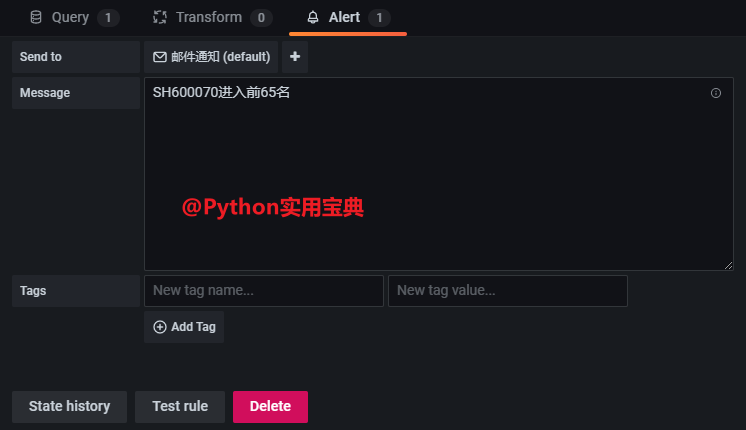
- job_name: 'hot_list'
static_configs:
- targets: ['localhost:8000']
# 使用 NLP 解析
article.nlp()
# 获取文章关键词
article.keywords
# ['New Years', 'resolution', ...]
# 获取文章摘要
article.summary
# 'The study shows that 93% of people ...'
你看,这个工具不无敌吗?它还能提取某个网站的所有新闻文章,比如我想提取CNN的新闻文章:
import newspaper
cnn_paper = newspaper.build('http://cnn.com')
for article in cnn_paper.articles:
print(article.url)
# http://www.cnn.com/2013/11/27/justice/tucson-arizona-captive-girls/
# http://www.cnn.com/2013/12/11/us/texas-teen-dwi-wreck/index.html
在此之上,你还能拿到CNN的其他新闻门户分类:
for category in cnn_paper.category_urls():
print(category)
# http://lifestyle.cnn.com
# http://cnn.com/world
# http://tech.cnn.com
# ...
input code full name
ar Arabic
be Belarusian
bg Bulgarian
da Danish
de German
el Greek
en English
es Spanish
et Estonian
fa Persian
fi Finnish
fr French
he Hebrew
hi Hindi
hr Croatian
hu Hungarian
id Indonesian
it Italian
ja Japanese
ko Korean
lt Lithuanian
mk Macedonian
nb Norwegian (Bokmål)
nl Dutch
no Norwegian
pl Polish
pt Portuguese
ro Romanian
ru Russian
sl Slovenian
sr Serbian
sv Swedish
sw Swahili
th Thai
tr Turkish
uk Ukrainian
vi Vietnamese
zh Chinese