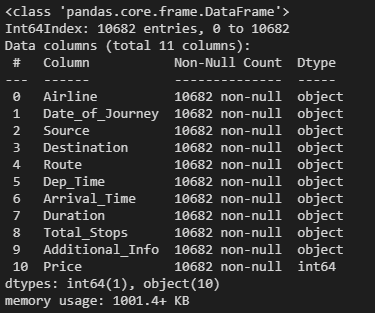
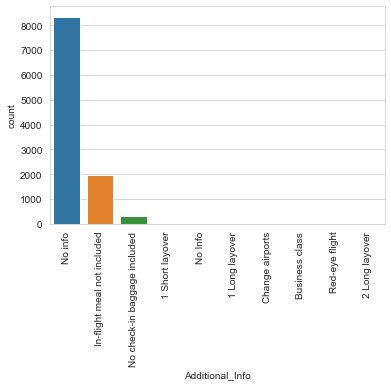
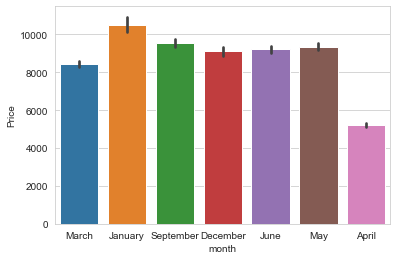
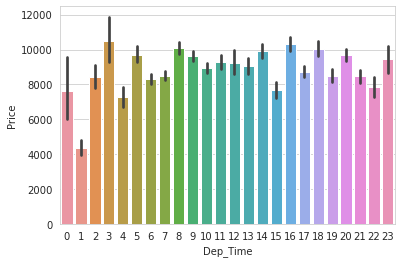
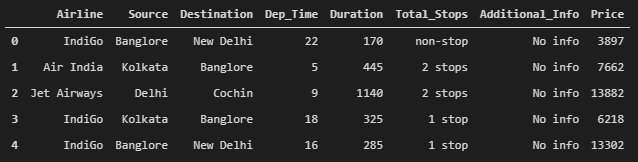
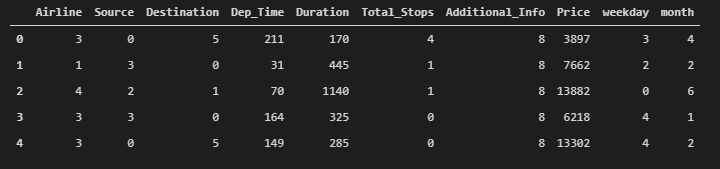
from sklearn.preprocessing import LabelEncoder
var_mod = ['Airline','Source','Destination','Additional_Info','Total_Stops','weekday','month','Dep_Time']
le = LabelEncoder()
for i in var_mod:
flights[i] = le.fit_transform(flights[i])
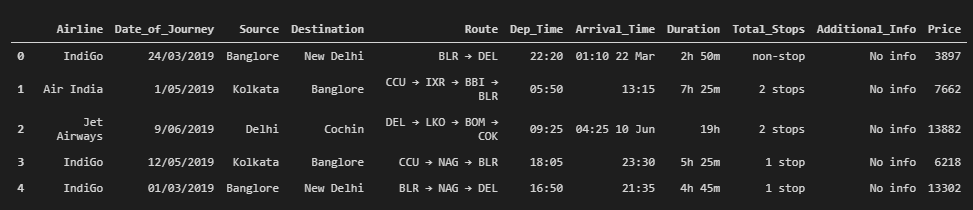
flights.head()
对每列数据进行特征缩放,提取自变量(x)和因变量(y):
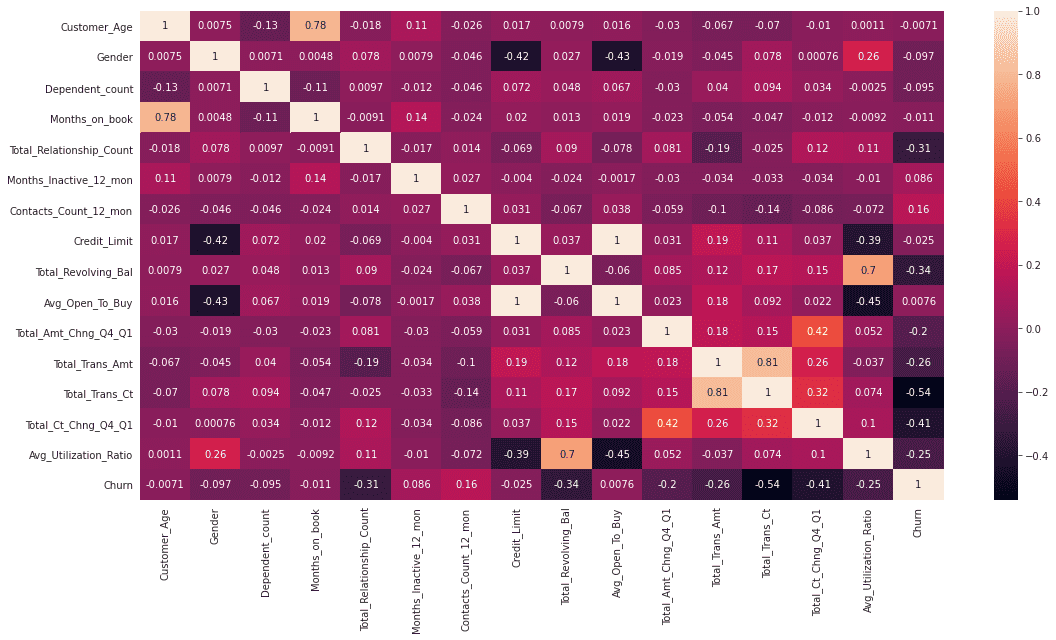
flights.corr()
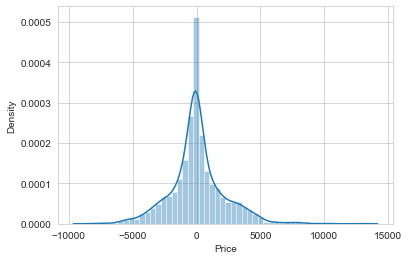
def outlier(df):
for i in df.describe().columns:
Q1=df.describe().at['25%',i]
Q3=df.describe().at['75%',i]
IQR= Q3-Q1
LE=Q1-1.5*IQR
UE=Q3+1.5*IQR
df[i]=df[i].mask(df[i]<LE,LE)
df[i]=df[i].mask(df[i]>UE,UE)
return df
flights = outlier(flights)
x = flights.drop('Price',axis=1)
y = flights['Price']
划分测试集和训练集:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=101)
4.2 模型训练及测试
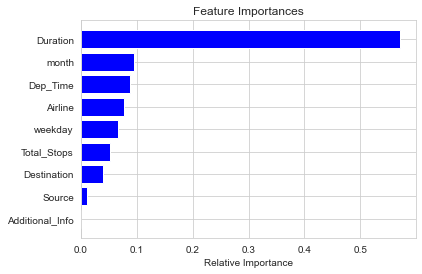
使用随机森林进行模型训练:
from sklearn.ensemble import RandomForestRegressor
rfr=RandomForestRegressor(n_estimators=100)
rfr.fit(x_train,y_train)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from datetime import datetime
import plotly.express as px
import plotly.graph_objects as go
import warnings
import plotly.offline as pyo
pyo.init_notebook_mode()
warnings.filterwarnings('ignore')
pd.set_option('display.max_columns', 500)
sns.set_style('white')
%matplotlib inline
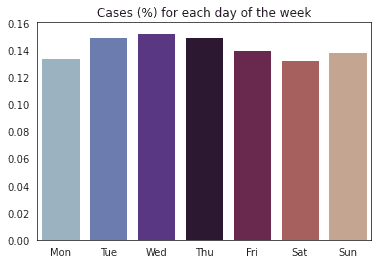
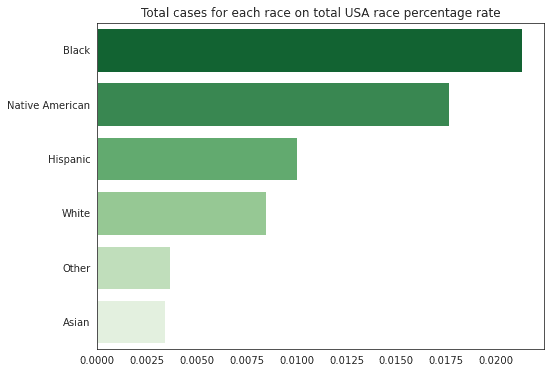
count = df['date'].apply(lambda x: x.dayofweek).value_counts(normalize=True).sort_index()
count.index = ['Mon','Tue','Wed','Thu','Fri','Sat','Sun']
f, ax = plt.subplots(1,1)
sns.barplot(x=count.index, y=count.values, ax=ax, palette='twilight')
ax.set_title('Cases (%) for each day of the week');
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as ex
import plotly.graph_objs as go
import plotly.figure_factory as ff
from plotly.subplots import make_subplots
import plotly.offline as pyo
pyo.init_notebook_mode()
sns.set_style('darkgrid')
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.ensemble import RandomForestClassifier,AdaBoostClassifier
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import f1_score as f1
from sklearn.metrics import confusion_matrix
import scikitplot as skplt
plt.rc('figure',figsize=(18,9))
%pip install imbalanced-learn
from imblearn.over_sampling import SMOTE
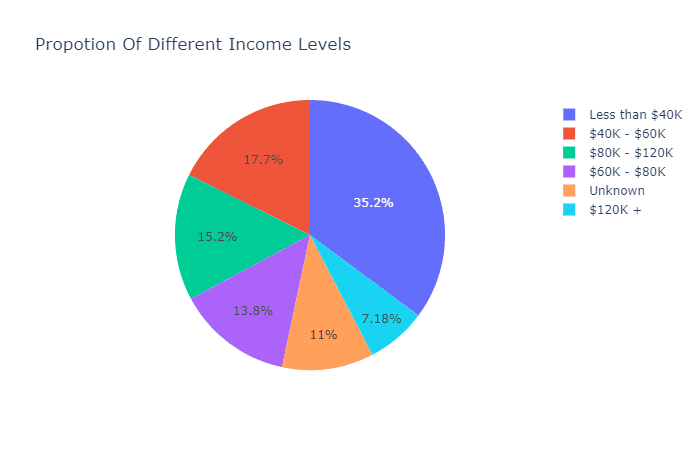
ex.pie(c_data,names='Income_Category',title='Propotion Of Different Income Levels')
ex.pie(c_data,names='Card_Category',title='Propotion Of Different Card Categories')
可见大部分人的年收入处于60K美元以下。
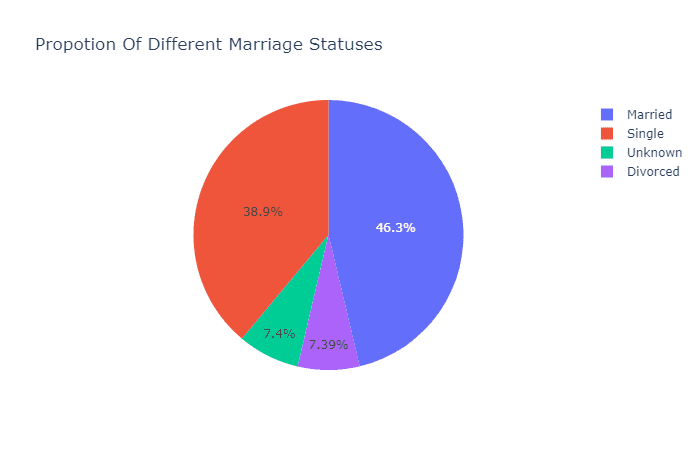
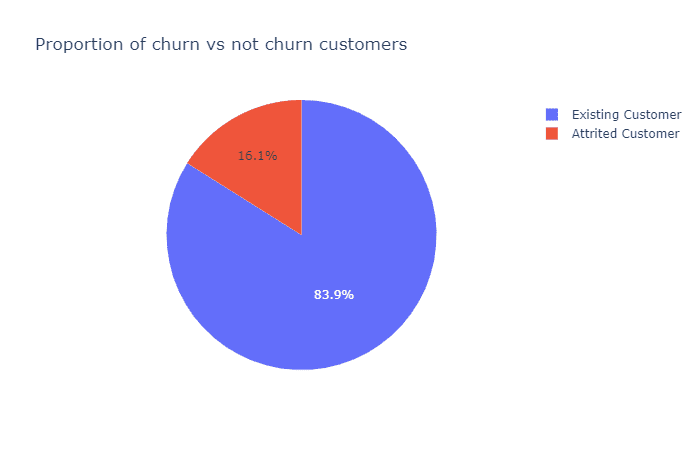
在持有的卡片的类型上,蓝卡占了绝大多数。
每月账单数量有没有特征?
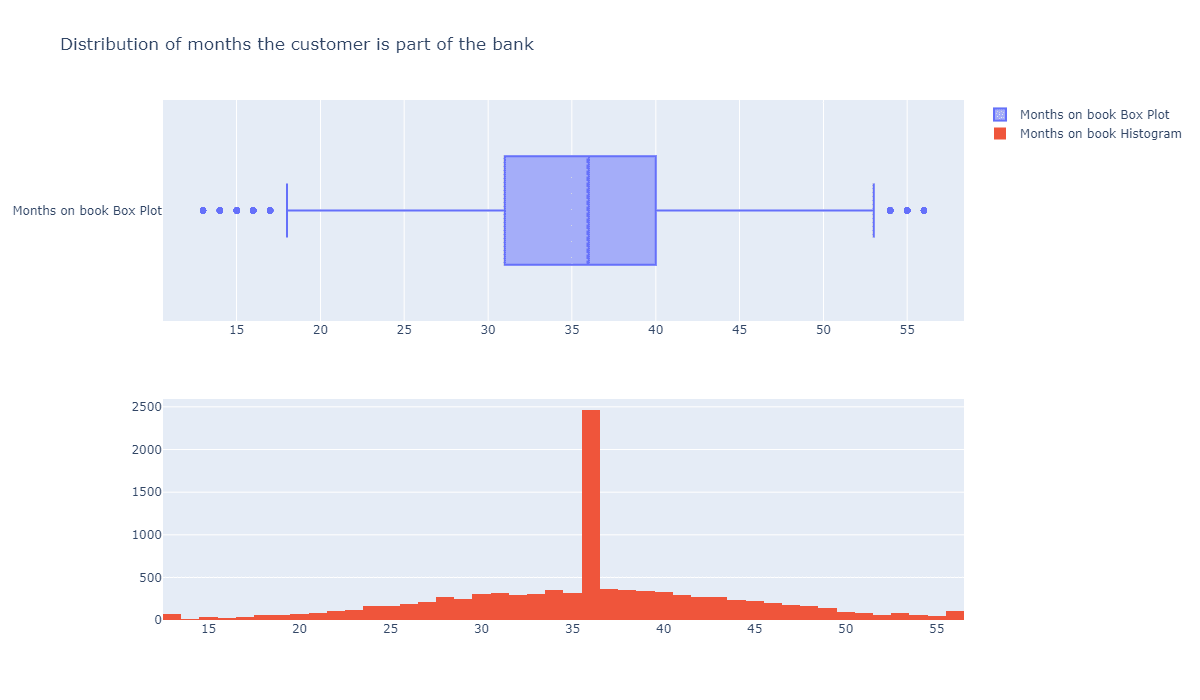
fig = make_subplots(rows=2, cols=1)
tr1=go.Box(x=c_data['Months_on_book'],name='Months on book Box Plot',boxmean=True)
tr2=go.Histogram(x=c_data['Months_on_book'],name='Months on book Histogram')
fig.add_trace(tr1,row=1,col=1)
fig.add_trace(tr2,row=2,col=1)
fig.update_layout(height=700, width=1200, title_text="Distribution of months the customer is part of the bank")
fig.show()
可以看到中间的峰值特别高,显然这个指标不是正态分布的。
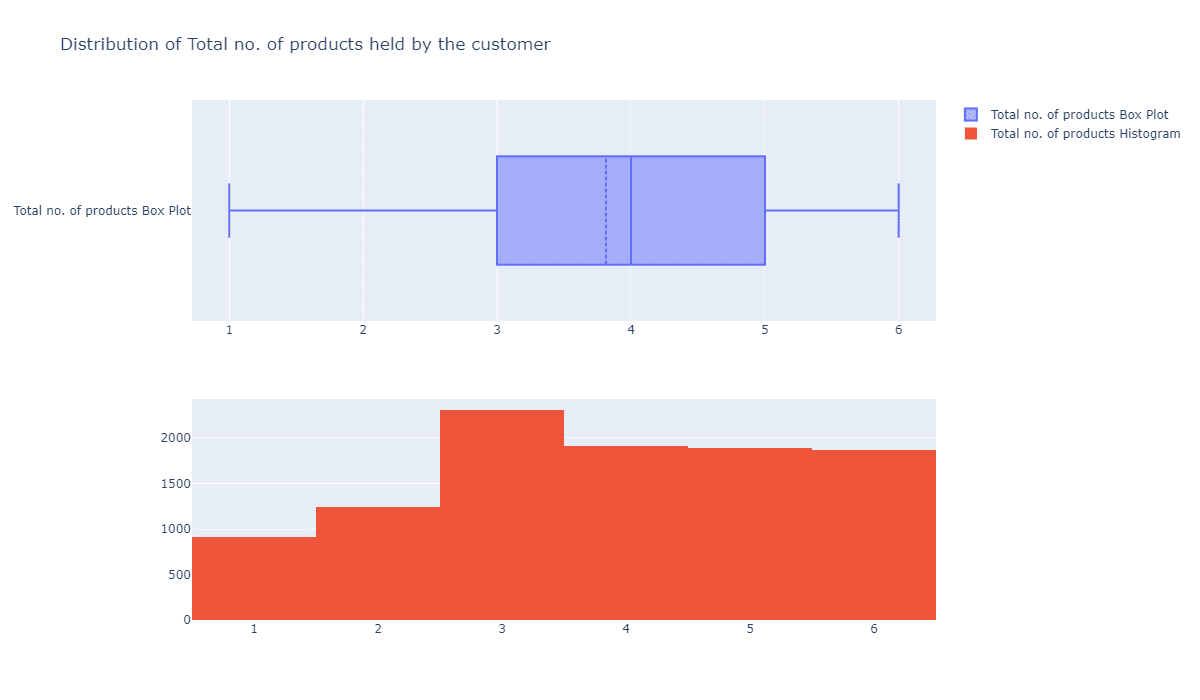
每位客户持有的银行业务数量有没有特征呢?
fig = make_subplots(rows=2, cols=1)
tr1=go.Box(x=c_data['Total_Relationship_Count'],name='Total no. of products Box Plot',boxmean=True)
tr2=go.Histogram(x=c_data['Total_Relationship_Count'],name='Total no. of products Histogram')
fig.add_trace(tr1,row=1,col=1)
fig.add_trace(tr2,row=2,col=1)
fig.update_layout(height=700, width=1200, title_text="Distribution of Total no. of products held by the customer")
fig.show()
基本上都是均匀分布的,显然这个指标对于我们而言也没太大意义。
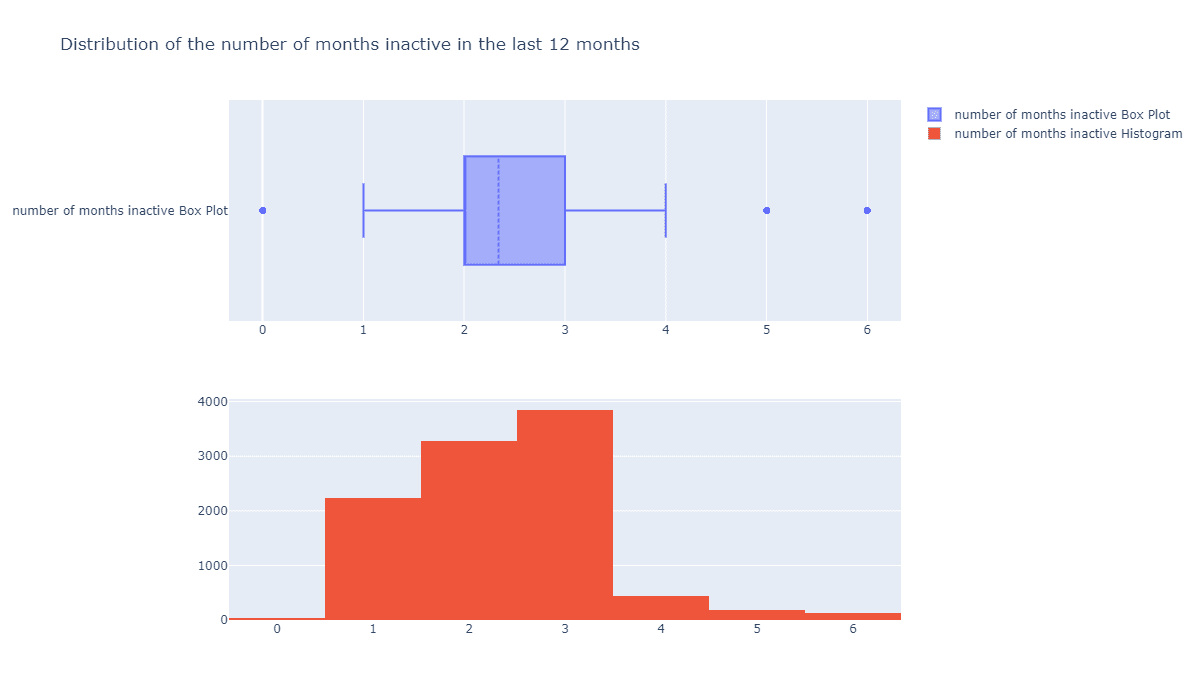
用户不活跃月份数量有没有好用的特征?
fig = make_subplots(rows=2, cols=1)
tr1=go.Box(x=c_data['Months_Inactive_12_mon'],name='number of months inactive Box Plot',boxmean=True)
tr2=go.Histogram(x=c_data['Months_Inactive_12_mon'],name='number of months inactive Histogram')
fig.add_trace(tr1,row=1,col=1)
fig.add_trace(tr2,row=2,col=1)
fig.update_layout(height=700, width=1200, title_text="Distribution of the number of months inactive in the last 12 months")
fig.show()
这个似乎有点用处,会不会越不活跃的用户越容易流失呢?
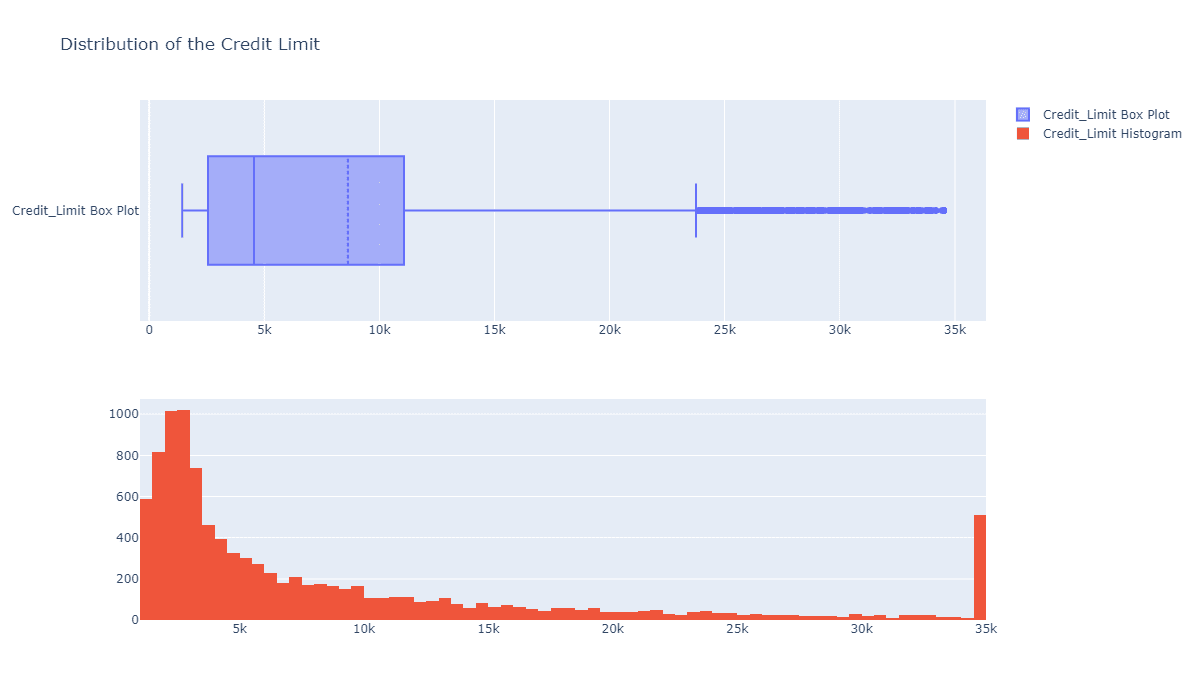
信用卡额度的分布如何?
fig = make_subplots(rows=2, cols=1)
tr1=go.Box(x=c_data['Credit_Limit'],name='Credit_Limit Box Plot',boxmean=True)
tr2=go.Histogram(x=c_data['Credit_Limit'],name='Credit_Limit Histogram')
fig.add_trace(tr1,row=1,col=1)
fig.add_trace(tr2,row=2,col=1)
fig.update_layout(height=700, width=1200, title_text="Distribution of the Credit Limit")
fig.show()
大部分人的额度都在0到10k之间,这比较正常,暂时看不出和流失有什么关系。
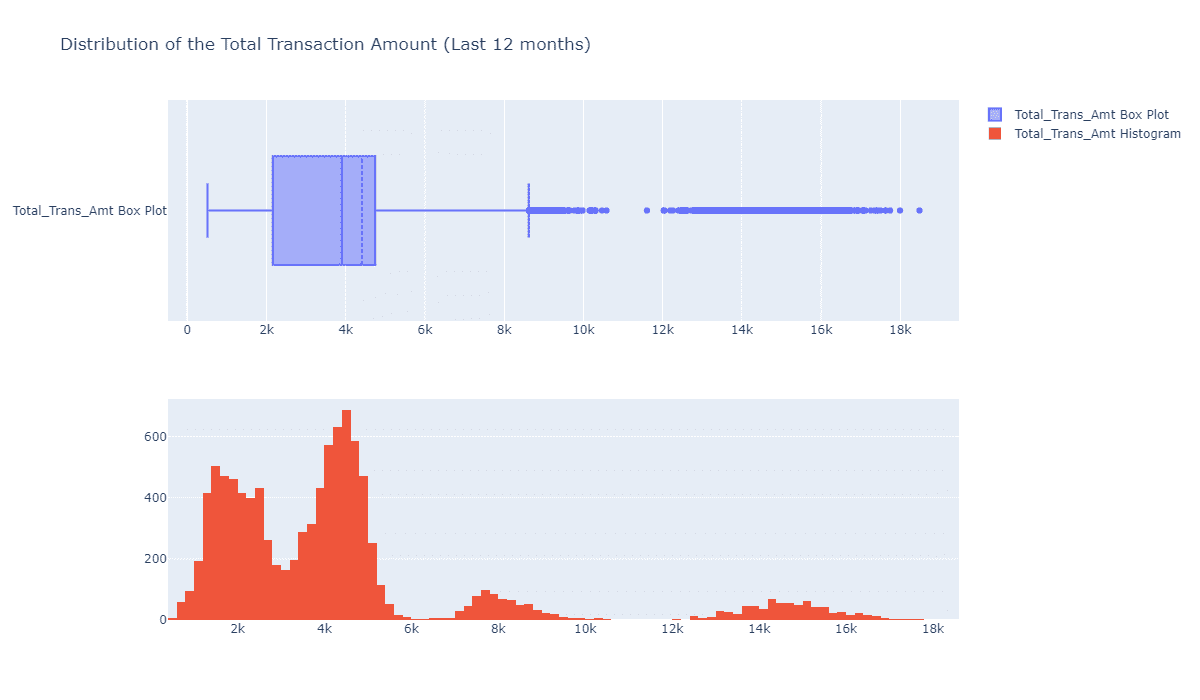
客户总交易额的分布怎么样?
fig = make_subplots(rows=2, cols=1)
tr1=go.Box(x=c_data['Total_Trans_Amt'],name='Total_Trans_Amt Box Plot',boxmean=True)
tr2=go.Histogram(x=c_data['Total_Trans_Amt'],name='Total_Trans_Amt Histogram')
fig.add_trace(tr1,row=1,col=1)
fig.add_trace(tr2,row=2,col=1)
fig.update_layout(height=700, width=1200, title_text="Distribution of the Total Transaction Amount (Last 12 months)")
fig.show()
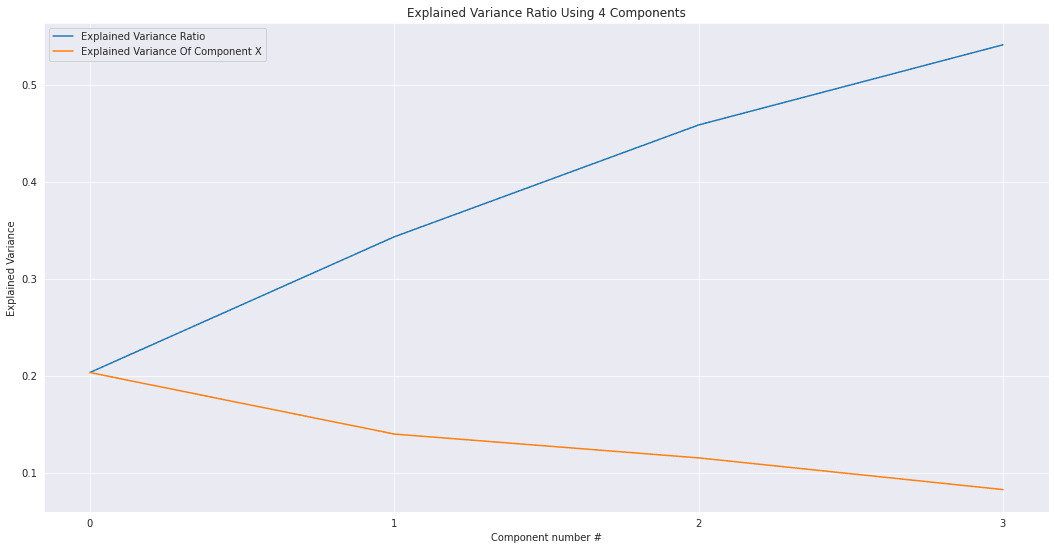
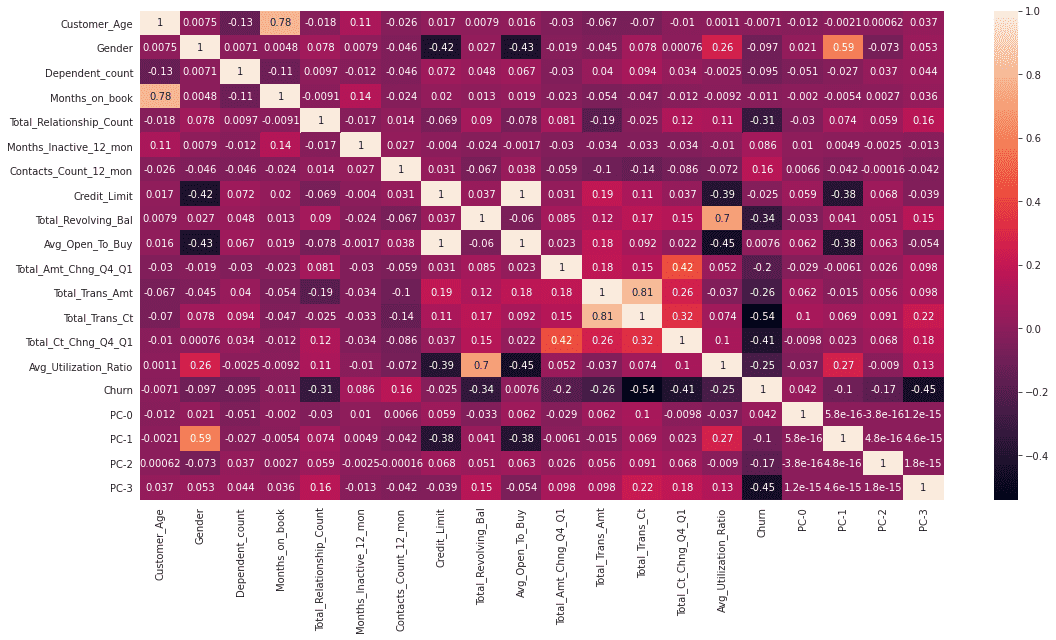
N_COMPONENTS = 4
pca_model = PCA(n_components = N_COMPONENTS )
pc_matrix = pca_model.fit_transform(ohe_data)
evr = pca_model.explained_variance_ratio_
cumsum_evr = np.cumsum(evr)
ax = sns.lineplot(x=np.arange(0,len(cumsum_evr)),y=cumsum_evr,label='Explained Variance Ratio')
ax.set_title('Explained Variance Ratio Using {} Components'.format(N_COMPONENTS))
ax = sns.lineplot(x=np.arange(0,len(cumsum_evr)),y=evr,label='Explained Variance Of Component X')
ax.set_xticks([i for i in range(0,len(cumsum_evr))])
ax.set_xlabel('Component number #')
ax.set_ylabel('Explained Variance')
plt.show()
usampled_df_with_pcs = pd.concat([usampled_df,pd.DataFrame(pc_matrix,columns=['PC-{}'.format(i) for i in range(0,N_COMPONENTS)])],axis=1)
usampled_df_with_pcs
plt.subplot(3,1,1)
ax = sns.lineplot(x=range(0,len(f1_cross_val_scores)),y=f1_cross_val_scores)
ax.set_title('Random Forest Cross Val Scores')
ax.set_xticks([i for i in range(0,len(f1_cross_val_scores))])
ax.set_xlabel('Fold Number')
ax.set_ylabel('F1 Score')
plt.show()
plt.subplot(3,1,2)
ax = sns.lineplot(x=range(0,len(ada_f1_cross_val_scores)),y=ada_f1_cross_val_scores)
ax.set_title('Adaboost Cross Val Scores')
ax.set_xticks([i for i in range(0,len(ada_f1_cross_val_scores))])
ax.set_xlabel('Fold Number')
ax.set_ylabel('F1 Score')
plt.show()
plt.subplot(3,1,3)
ax = sns.lineplot(x=range(0,len(svm_f1_cross_val_scores)),y=svm_f1_cross_val_scores)
ax.set_title('SVM Cross Val Scores')
ax.set_xticks([i for i in range(0,len(svm_f1_cross_val_scores))])
ax.set_xlabel('Fold Number')
ax.set_ylabel('F1 Score')
plt.show()
看看三种模型都有什么不同的表现:
看得出来随机森林 F1分数是最高的。
4.2 模型预测
对测试集进行预测,看看三种模型的效果:
rf_pipe.fit(train_x,train_y)
rf_prediction = rf_pipe.predict(test_x)
ada_pipe.fit(train_x,train_y)
ada_prediction = ada_pipe.predict(test_x)
svm_pipe.fit(train_x,train_y)
svm_prediction = svm_pipe.predict(test_x)
print('F1 Score of Random Forest Model On Test Set - {}'.format(f1(rf_prediction,test_y)))
print('F1 Score of AdaBoost Model On Test Set - {}'.format(f1(ada_prediction,test_y)))
print('F1 Score of SVM Model On Test Set - {}'.format(f1(svm_prediction,test_y)))
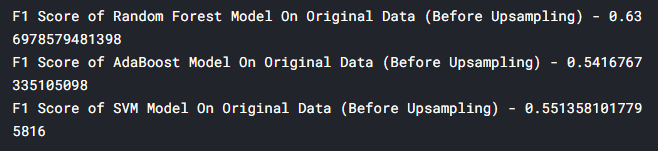
4.3 对原始数据(采样前)进行模型预测
接下来对原始数据进行模型预测:
ohe_data =c_data[c_data.columns[16:]].copy()
pc_matrix = pca_model.fit_transform(ohe_data)
original_df_with_pcs = pd.concat([c_data,pd.DataFrame(pc_matrix,columns=['PC-{}'.format(i) for i in range(0,N_COMPONENTS)])],axis=1)
unsampled_data_prediction_RF = rf_pipe.predict(original_df_with_pcs[X_features])
unsampled_data_prediction_ADA = ada_pipe.predict(original_df_with_pcs[X_features])
unsampled_data_prediction_SVM = svm_pipe.predict(original_df_with_pcs[X_features])
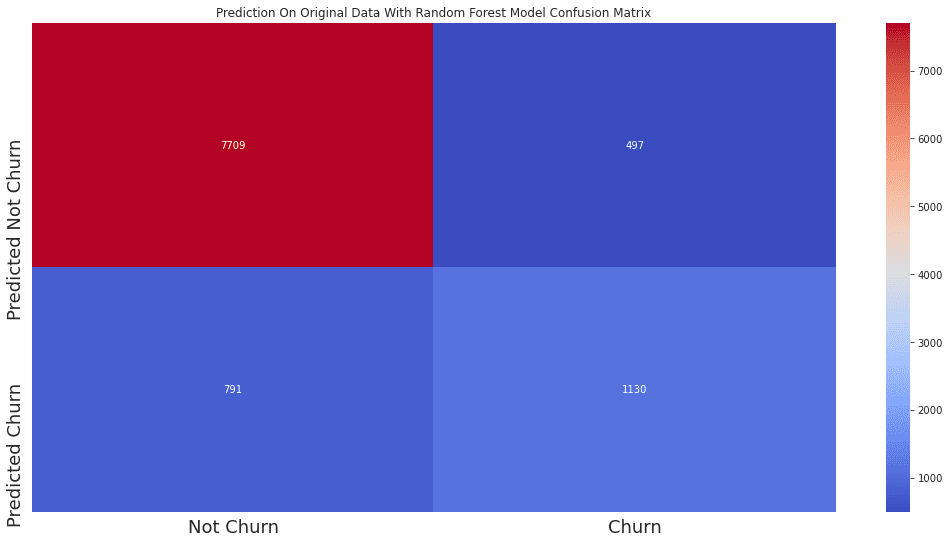
ax = sns.heatmap(confusion_matrix(unsampled_data_prediction_RF,original_df_with_pcs['Attrition_Flag']),annot=True,cmap='coolwarm',fmt='d')
ax.set_title('Prediction On Original Data With Random Forest Model Confusion Matrix')
ax.set_xticklabels(['Not Churn','Churn'],fontsize=18)
ax.set_yticklabels(['Predicted Not Churn','Predicted Churn'],fontsize=18)
plt.show()