部分引用自: Satwik Kansal
Develop a blockchain application from scratch in Python
这两天比特币暴涨到了9000美元,除了习大大重点点名的影响,还有明年4月比特币区块减半的因素在里面。不过这些都不是今天这篇文章的重点,今天我们要重点关注的是比特币的事务(在帐户之间转移比特币)的原理——区块链。并用它来搭建一个简单的去中心化的食品安全溯源区块链。
区块链是一种存储数字数据的方式,数据可以是任何内容。对于比特币而言,它就是账户之间转移比特币的事务,我们还可以将其应用到食品安全领域,那就是保存食品制作过程中的各个步骤的时间、原料、制作者等。
用区块链记录这些过程十分具备优势,因为区块链可以具备以下特点:
- 1.历史记录无法修改(本文重点讨论)
- 2.数据去中心化保存
- 3.无单点故障
扫描文章下方二维码关注Python实用宝典公众号,回复食品安全溯源可获得完整源代码。
1.将数据存储到区块中
我们将用json保存我们想要的数据,以下是一个例子:
{
"timestamp": "1572185927665",
"source": "香肠加工",
"recorder": "小詹"
}2.让区块不可被更改
为了保证历史记录无法被修改,一旦被修改我们能检测出对区块的数据的任何篡改,因此我们需要用到哈希函数SHA256,它能从任何一种数据中心创建数字指纹,以保证数据的唯一性。下面是一个例子:
from hashlib import sha256
data = "TEST".encode("utf-8")
print(sha256(data).hexdigest())然后我们将哈希得到的结果保存到区块的一个字段里,其作用类似于它所包含的数据的数字指纹:
from hashlib import sha256
import json
class Block:
def compute_hash(self):
"""
对区块进行哈希计算
"""
block_string = json.dumps(self.__dict__, sort_keys=True)
return sha256(block_string.encode()).hexdigest()3.链接区块
我们已经设置好了区块,但区块链应该是一个区块集合,我们可以把所有的区块存储在列表中,但是这远远不够,如果有人故意替换了一个区块怎么办?我们需要采用某种方法来确保对过去的区块的任何更改都会造成整个链的失效。我们将通过哈希值将区块连接起来,即将前一个区块的哈希值包含在当前区块中。所以如果当前的区块的内容发生更改,该区块的哈希值也会发生更改,导致与下一个区块的前一个区块(previous_hash)的哈希字段不匹配。
每一个区块都根据previous_hash字段链接到前一个区块,但是第一个区块(创始区块)怎么办?大多数情况下,我们将手动为他赋值。
将index、时间戳、数据段和previous_hash加到区块类的初始化中:
from hashlib import sha256
import json
class Block:
def __init__(self, index, data, timestamp, previous_hash):
self.index = index
self.data = data
self.timestamp = timestamp
self.previous_hash = previous_hash
def compute_hash(self):
"""
对区块进行哈希计算
"""
block_string = json.dumps(self.__dict__, sort_keys=True)
return sha256(block_string.encode()).hexdigest()这是我们的区块链类:
class Blockchain:
def __init__(self):
self.unconfirmed_data = [] # 尚未进入区块链的数据
self.chain = []
self.create_genesis_block()
def create_genesis_block(self):
"""
生成创始区块(genesis block)并将其附加到链中的函数。
该块的索引为0,previous_hash为0,并且是一个有效的散列。
"""
genesis_block = Block(0, [], time.time(), "0")
genesis_block.hash = genesis_block.compute_hash()
self.chain.append(genesis_block)
@property
def last_block(self):
return self.chain[-1]4.工作量证明算法
其实这样做,还远远不够。因为我们更改前一个区块就可以非常轻松地计算后续所有区块的哈希值,创建一个不同且有效的区块链。为了预防这种情况,我们必须让计算哈希值的任务变得困难和随机化。
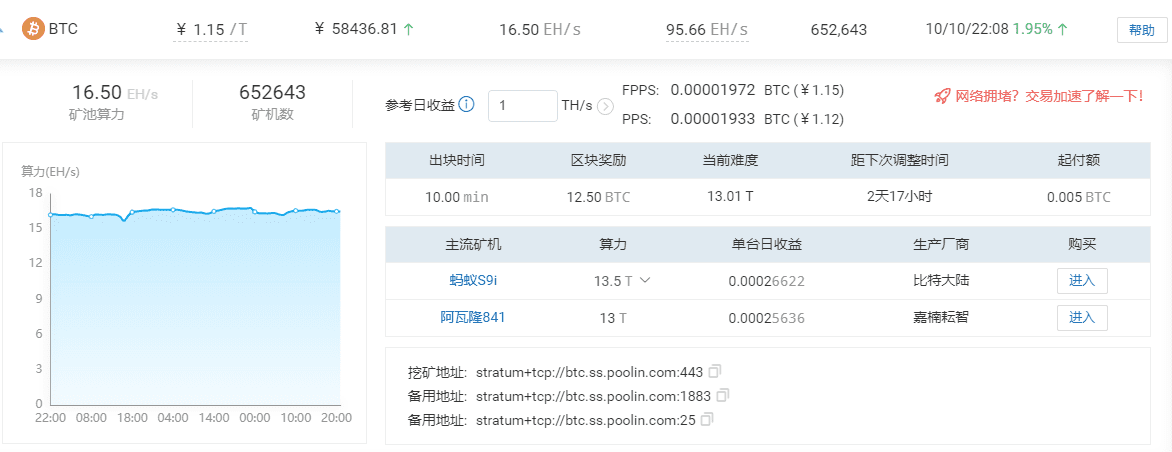
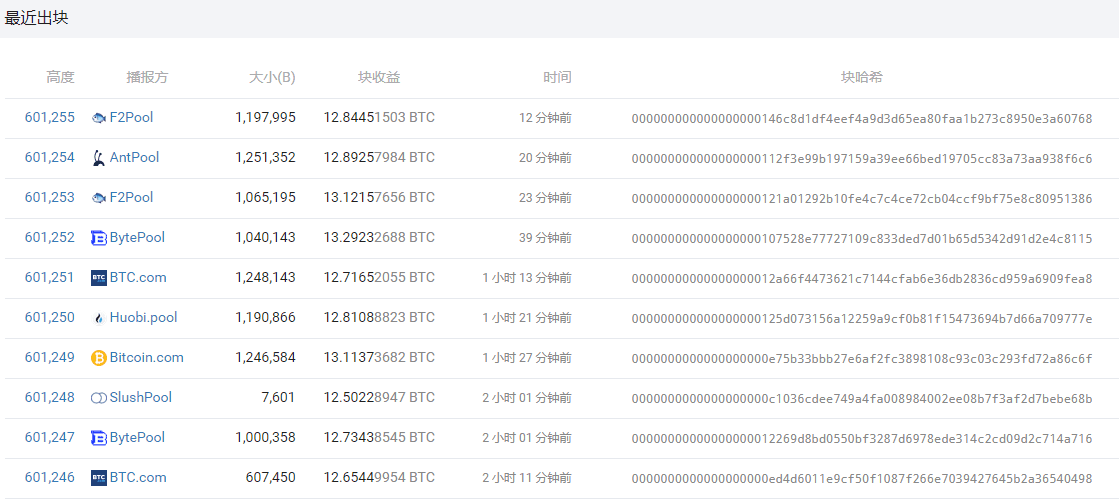
我们将引入一个约束条件和一个叫nonce的随机数的新字段。这个约束条件就是块哈希开头部分的零 (前导零) 的个数,随机数会不断变化,直到我们获得满足约束条件的哈希值。前导零的数量决定了工作量证明算法的难度。看看下面比特币出块图就知道了,比特币的难度的不断增加是通过增加前导零的数量实现的。

假设我们的难度是2,则编写工作量证明算法代码如下:
class Blockchain:
# 前面的代码略
# 难度
difficulty = 2
def proof_of_work(self, block):
"""
函数尝试不同的随机数以获得满足我们难度的块哈希。
"""
block.nonce = 0
computed_hash = block.compute_hash()
while not computed_hash.startswith('0' * Blockchain.difficulty):
block.nonce += 1
computed_hash = block.compute_hash()
return computed_hash 这样做有一个好处:只能通过暴力破解确定随机数,这就是为什么现在挖矿行业这么火爆的原因。
5.将区块添加到链中
要将区块添加到链中,我们得先验证工作量证明是否正确,以及要添加的区块的previous_hash 字段是否指向链中最新区块的哈希值。
class Blockchain:
# 前面的代码略
def is_valid_proof(self, block, block_hash):
"""
工作量证明验证,并确保previous_hash正确
"""
return (block_hash.startswith('0' * Blockchain.difficulty) and
block_hash == block.compute_hash())
def add_block(self, block, proof):
"""
在验证成功后将块链接起来
"""
previous_hash = self.last_block.hash
if previous_hash != block.previous_hash:
return False
if not self.is_valid_proof(block, proof):
return False
block.hash = proof
self.chain.append(block)
return True6.挖矿
数据将存储在unconfirmed_data中,将unconfirmed_data中的数据放入区块中并计算工作量证明的过程称为挖矿。一旦找到满足约束条件的随机数,就可以说我们挖到了一个区块,这个区块就会放入区块链中。
在比特币中,作为对耗费算力来计算工作量证明的奖励,矿工可以获得一些加密货币,以下是我们的挖矿函数:
class Blockchain:
# 前面代码略
def add_new_data(self, data):
self.unconfirmed_data.append(data)
def mine(self):
"""
此函数充当一个接口,将未决数据添加到块中并计算工作证明,
然后将它们添加到区块链。
"""
if not self.unconfirmed_data:
return False
last_block = self.last_block
new_block = Block(index=last_block.index + 1,
data=self.unconfirmed_data,
timestamp=time.time(),
previous_hash=last_block.hash)
proof = self.proof_of_work(new_block)
self.add_block(new_block, proof)
self.unconfirmed_data = []
return new_block.index测试
现在,这条链基本建造完成了,让我们试一试效果。尝试往里面添加一个区块:
def new_data(data):
# 这里传入字典数据或json数据都可以
required_fields = ["source", "recorder"]
for field in required_fields:
if not data.get(field):
return "Invlaid data"
data["timestamp"] = time.time()
bc.add_new_data(data)
return "Success"
bc = Blockchain()
a = new_data({"source": "香肠加工", "recorder": "小詹"})
print(a)添加成功:
F:\push\20191027>python block.py Success
现在数据是在 unconfirmed_data 中,我们需要挖矿,让它成功添加到区块链上:
def new_data(data):
# 这里传入字典数据或json数据都可以
required_fields = ["source", "recorder"]
for field in required_fields:
if not data.get(field):
return "Invlaid data"
data["timestamp"] = time.time()
bc.add_new_data(data)
return "Success"
def get_chain(blockchain):
chain_data = []
for block in blockchain.chain:
chain_data.append(block.__dict__)
return json.dumps({"length": len(chain_data),
"chain": chain_data})
def mine_unconfirmed_transactions(blockchain):
result = blockchain.mine()
if not result:
print("No data need to mine")
print("Block #{} is mined.".format(result))
bc = Blockchain()
a = new_data({"source": "香肠加工", "recorder": "小詹"})
print(a)
mine_unconfirmed_transactions(bc)输出结果:
F:\push\20191027>python block.py Success Block #1 is mined.
现在来看看区块链上是不是有两个区块了(一个创始块,一个我们新增的区块)显示数据:
def get_chain(blockchain):
chain_data = []
for block in blockchain.chain:
chain_data.append(block.__dict__)
return json.dumps({"length": len(chain_data),
"chain": chain_data})
print(get_chain(bc)) 结果:
F:\push\20191027>python block.py
Success
Block #1 is mined.
{"length": 2, "chain": [{"index": 0, "data": [], "timestamp": 1572187230.2847784, "previous_hash": "0", "hash": "f30161fc8ffa278f26713a73780b939fe9734d9d459fe4307e72926d9eb9c3aa"}, {"index": 1, "data": [{"source": "\u9999\u80a0\u52a0\u5de5", "recorder": "\u5c0f\u8a79", "timestamp": 1572187230.2847784}], "timestamp": 1572187230.2847784, "previous_hash": "f30161fc8ffa278f26713a73780b939fe9734d9d459fe4307e72926d9eb9c3aa", "nonce": 0, "hash": "0026b22937fdcb24978814dd26cdf64a6210966c26914e66b73ca68805f1cd5a"}]}非常nice,这样我们就成功新建了一个非常简单的食品安全溯源区块链,当然离上线还有很远的距离(如去中心化及建立共识),但是万事开头难,解决了开头部分,后续就不再会有什么难题了。
扫描文章下方二维码关注Python实用宝典公众号,回复食品安全溯源可获得完整源代码。
文章到此就结束啦,如果你喜欢今天的Python 教程,请持续关注Python实用宝典,如果对你有帮助,麻烦在下面点一个赞/在看哦![]()

Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典