

一、爱心墙
通过爬虫搜集到粉丝的头像,然后利用 PIL 库拼接出爱心墙的形状
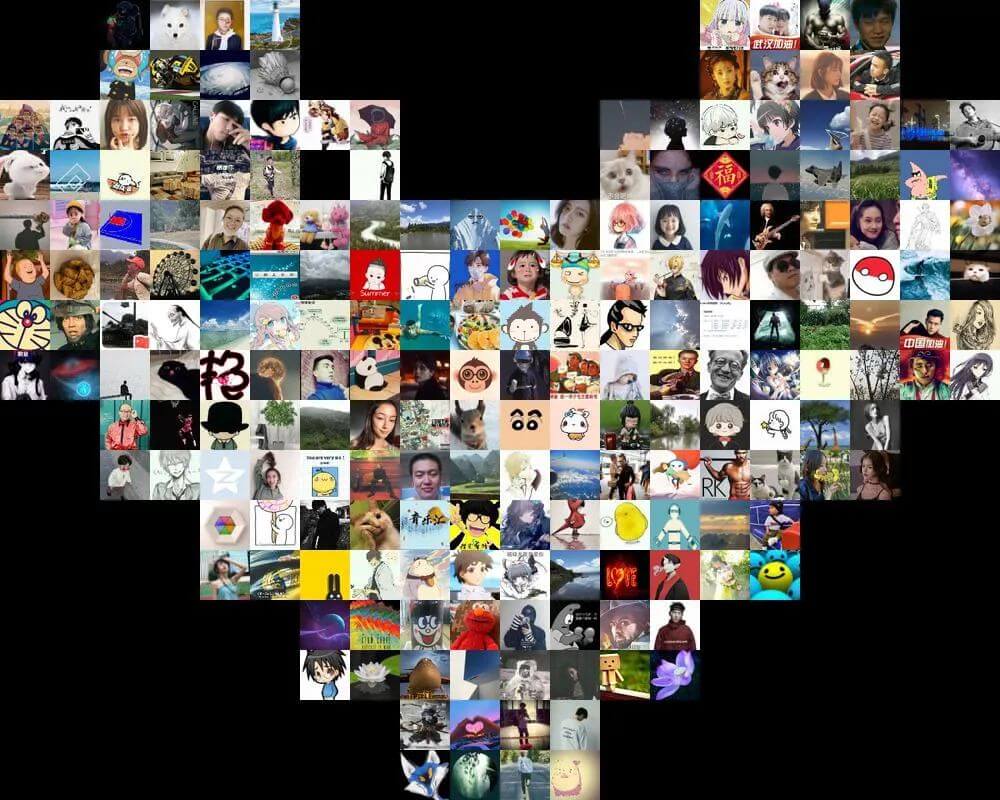
二、代码分析
1.头像爬取
在个人中心点击我的粉丝便可以看到自己的粉丝
通过抓包可知对应的接口为:
url = 'https://me.csdn.net/api/relation/index?pageno=1&pagesize=20&relation_type=fans' # 接口地址
那么,可以定义一个函数来获取粉丝的信息:
def get_fansInfo():
'''
获取粉丝相关信息
'''
url = 'https://me.csdn.net/api/relation/index?pageno=%d&pagesize=%d&relation_type=fans' # 接口地址
cookies = {} # 用户登陆cookies
headers = { # 请求头
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:81.0) Gecko/20100101 Firefox/81.0',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Referer': 'https://i.csdn.net/',
'Origin': 'https://i.csdn.net',
'Connection': 'keep-alive',
'TE': 'Trailers',
}
# 获取粉丝总数
res = requests.get(url%(1,10),headers=headers,cookies=cookies)
res_json = res.json()
N_fans = res_json['data']['data_all']
print('一共有%d个粉丝'%N_fans)
# 获取全部粉丝数据
res = requests.get(url%(1,N_fans),headers=headers,cookies=cookies)
res_json = res.json()
return res_json
在返回的数据中,包括一个avatar字段,这个就是用户的头像地址
拿到头像地址之后便可以定义个函数来下载相应的头像:
def download_avatar(username,url):
'''
下载用户头像
'''
savePath = './avatars' # 头像存储目录
res = requests.get(url)
with open('%s/%s.jpg'%(savePath,username),'wb') as f:
f.write(res.content)
定义主函数,运行代码:
if __name__ == '__main__':
fans = get_fansInfo()
for f in fans['data']['list']:
username = f['fans'] # 用户名
url = f['avatar'] # 头像地址
download_avatar(username,url)
print('用户"%s"头像下载完成!'%username)
最后我成功将所有头像下载到本地文件夹中: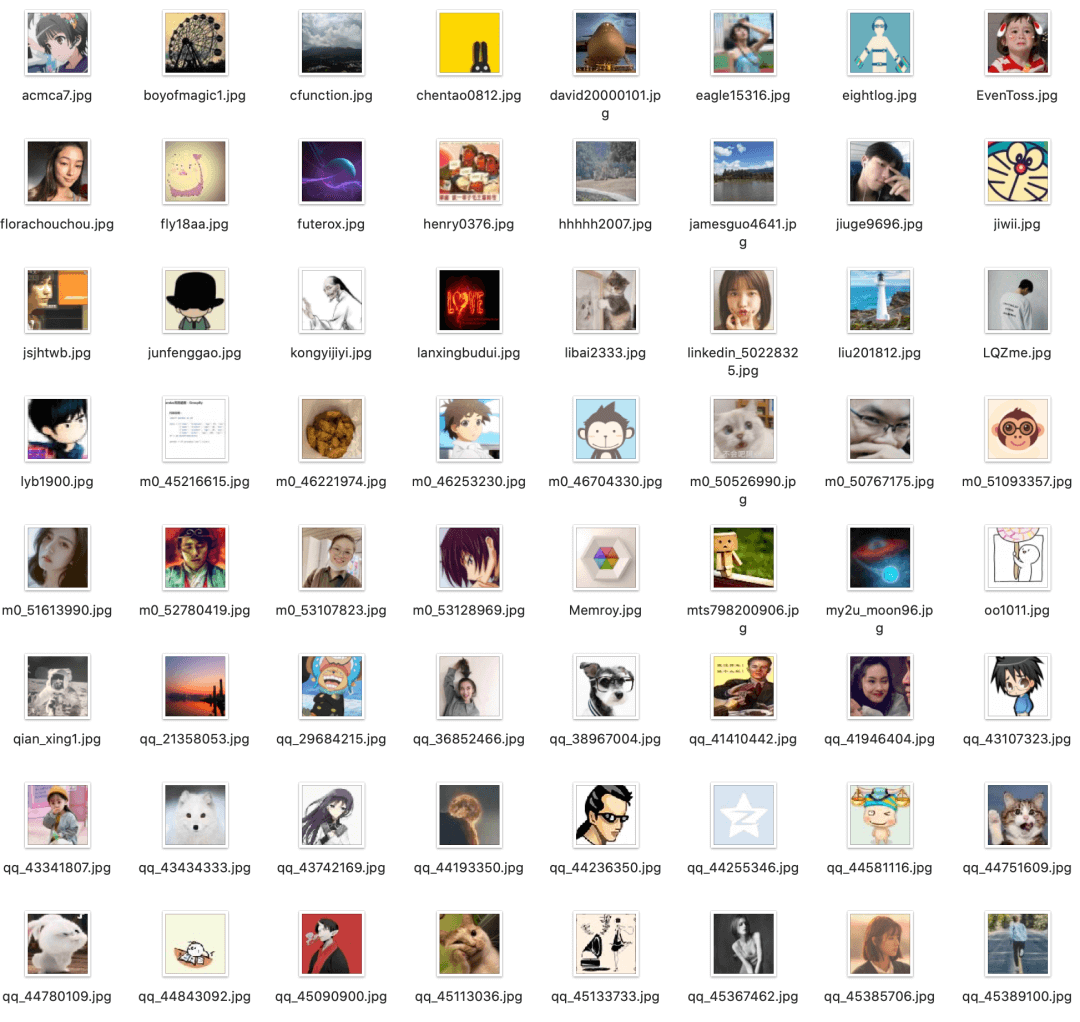
2.头像去重
聪明的你应该已经发现,在爬取到的头像中有两个头像重复出现(想必这应该是官方默认头像):


于是乎,为了更好地展示,我们得对头像进行去重
这里我们利用每个头像的 MD5 值来进行去重,然后定义函数来计算头像的 MD5 值
def get_md5(filename):
'''
获取文件的md5值cls
'''
m = hashlib.md5()
with open(filename,'rb') as f:
for line in f:
m.update(line)
md5 = m.hexdigest()
return md5
说明:每个文件通过 MD5 计算出摘要,理论来说只有文件完全一致 MD5 值才会相同。因此,可以利用它来进行图像的去重
对头像进行去重,并把去重后的头像保存到另外的目录中:
# 照片去重
md5_already = [] # 用于存储已经记录过的图片,便于去重
for filename in os.listdir('./avatars'):
md5 = get_md5('./avatars/'+filename)
if md5 not in md5_already:
md5_already.append(md5)
shutil.copyfile('./avatars/'+filename,'./avatars(dr)/'+filename)
3.绘制爱心墙
这一步,主要是利用 PIL 库来把头像按照设定的框架拼接成一个更大的图片
首先导入相关库:
import os
import random
import numpy as np
import PIL.Image as Image
定义绘制图形的框架(用二维数组表示):
FRAME = [[0,1,1,0,0,0,0,1,1,0],
[1,1,1,1,0,0,1,1,1,1],
[1,1,1,1,1,1,1,1,1,1],
[1,1,1,1,1,1,1,1,1,1],
[0,1,1,1,1,1,1,1,1,0],
[0,0,1,1,1,1,1,1,0,0],
[0,0,0,1,1,1,1,0,0,0],
[0,0,0,0,1,1,0,0,0,0]]
这里大家完全可以发挥自己的想象,画你心中所想
其中,0 表示不进行填充,1 表示用头像进行填充。
定义相关参数,包括每张用于填充的头像的大小、每个点位填充的次数等
# 定义相关参数
SIZE = 50 # 每张图片的尺寸为50*50
N = 2 # 每个点位上放置2*2张图片
# 计算相关参数
width = np.shape(FRAME)[1]*N*SIZE # 照片墙宽度
height = np.shape(FRAME)[0]*N*SIZE # 照片墙高度
n_img = np.sum(FRAME)*(N**2) # 照片墙需要的照片数
filenames = random.sample(os.listdir('./avatars(dr)'),n_img) # 随机选取n_img张照片
filenames = ['./avatars(dr)/'+f for f in filenames]
遍历 FRAME,用头像对背景图片进行填充:
# 绘制爱心墙
img_bg = Image.new('RGB',(width,height)) # 设置照片墙背景
i = 0
for y in range(np.shape(FRAME)[0]):
for x in range(np.shape(FRAME)[1]):
if FRAME[y][x] == 1: # 如果需要填充
pos_x = x*N*SIZE # 填充起始X坐标位置
pos_y = y*N*SIZE # 填充起始Y坐标位置
for yy in range(N):
for xx in range(N):
img = Image.open(filenames[i])
img = img.resize((SIZE,SIZE),Image.ANTIALIAS)
img_bg.paste(img,(pos_x+xx*SIZE,pos_y+yy*SIZE))
i += 1
# 保存图片
img_bg.save('love.jpg')
写在最后
天气逐渐微寒,愿这次小小的表白可以给你们带来些许暖意;愿风雨兼程,不忘归途;愿身能似月亭亭,千里伴君行!
转自AirPython.
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。