最近由于论文写作需要涉及到人脸的提取操作,结合以前做过的人脸识别项目:Python自动识别人脸开机 和 ffmpeg 的影片逐帧提取功能,实现了自动提取电影中所有人脸的操作。
我们知道,机器学习、深度学习算法需要数据量到达一定量级之后效果才比较好。所以我们今天的这个功能主要可以用于一些人脸识别算法的训练集提取。
1.准备
我们使用ffmpeg提取视频中的图片,它的安装方法如下:
1.1 windows安装ffmpeg :
1.下载:https://www.gyan.dev/ffmpeg/builds/ffmpeg-release-essentials.zip
2.解压 zip 文件到指定目录;
将解压后的文件目录中 bin 目录(包含 ffmpeg.exe )添加进 path 环境变量(此电脑->右键->属性->高级系统设置->环境变量->编辑Path用户变量->新建-> 输入 bin目录的完整路径)中;
3.进入 cmd,输入 ffmpeg -version,可验证当前系统是否识别 ffmpeg,以及查看 ffmpeg 的版本;如果可以,则说明安装成功。
1.1 macOS安装ffmpeg:
1.Command+空格 搜索终端(Terminal)
2.输入以下命令安装homebrew:
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
3.输入以下命令安装ffmpeg:
brew install ffmpeg
1.2 安装用于提取人脸的OpenCV模块:
如果你已经安装好了Python(如果没有的话请看这篇文章:超详细Python安装指南),打开CMD/终端(Termianl)输入以下命令即可安装:
pip install opencv-python
接下来,让我们先学会从影片中逐帧提取图片。
2.提取图片
FFmpeg从视频中提取图片非常简单,而且功能很强大,能选择多少秒提取一帧,或者每秒提取X帧。
如果我们只需要1秒1帧,在CMD或Terminal中输入以下命令即可:
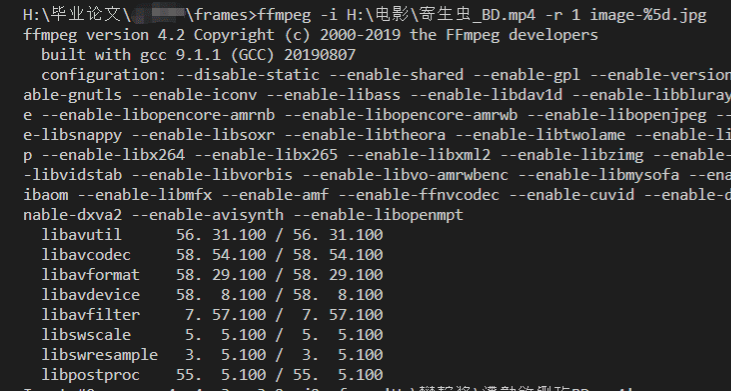
ffmpeg -i 视频路径.mp4 -r 1 image-%5d.jpg
其中:
-r 1 代表每秒取1帧
image-%5d.jpg是指命名格式为 image-00001.jpg
如图所示:

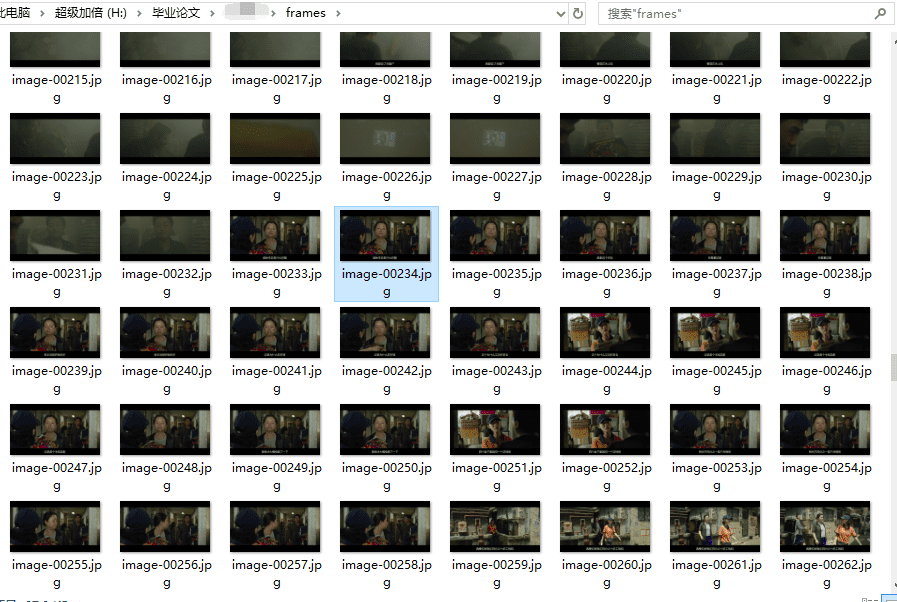
这样就能获得视频里的帧图:

3.从图片中提取人脸
如果你阅读过我以前的这篇文章: Python自动识别人脸开机 就会知道其实用OpenCV提取人脸是一件非常简单的事情。
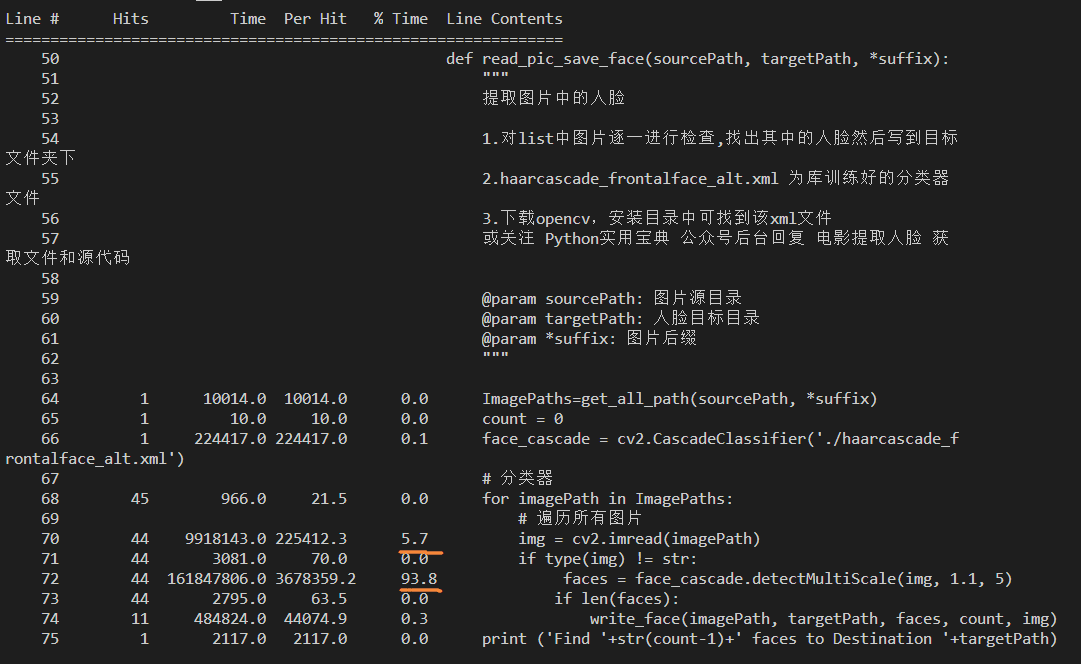
它只需要你将图片使用cv2.imread函数读取进来,然后再使用一个训练好的分类器文件就能获得人脸的位置。如下代码所示:
def read_pic_save_face(sourcePath, targetPath, *suffix):
"""
提取图片中的人脸
1.对list中图片逐一进行检查,找出其中的人脸然后写到目标文件夹下
2.haarcascade_frontalface_alt.xml 为库训练好的分类器文件
3.下载opencv,安装目录中可找到该xml文件
或关注 Python实用宝典 公众号后台回复 电影提取人脸 获取文件和源代码
@param sourcePath: 图片源目录
@param targetPath: 人脸目标目录
@param *suffix: 图片后缀
"""
ImagePaths=get_all_path(sourcePath, *suffix)
count = 0
face_cascade = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
# 分类器
for imagePath in ImagePaths:
# 遍历所有图片
img = cv2.imread(imagePath)
if type(img) != str:
faces = face_cascade.detectMultiScale(img, 1.1, 5)
if len(faces):
write_face(targetPath, faces)
print ('Find '+str(count-1)+' faces to Destination '+targetPath)获得了人脸的位置后,我们只需要将这部分位置写入到新的图片中即可:
def write_face(imagePath, targetPath, faces, count, img):
"""
写入脸部图片到目标目录
@param imagePath: 图片目录
@param targetPath: 目标目录
@param faces: 脸部数据
@param count: 数目
@param img: 图片数据
"""
for (x, y, w, h) in faces:
# 设置人脸宽度大于16像素,去除较小的人脸
if w>=16 and h>=16:
# 以时间戳和读取的排序作为文件名称
listStr = [str(int(time.time())), str(count)]
fileName = ''.join(listStr)
# 扩大图片,可根据坐标调整
X = int(x)
W = min(int(x + w),img.shape[1])
Y = int(y)
H = min(int(y + h),img.shape[0])
f = cv2.resize(img[Y:H, X:W], (W-X,H-Y))
cv2.imwrite(targetPath+os.sep+'%s.jpg' % fileName, f)
count += 1
print (imagePath + "have face") 怎么样,是不是特别简单?完整代码如下:
#-*-coding:utf8-*-
import os
import cv2
import time
def get_all_path(dirpath, *suffix):
"""
获得所有路径
@param dirpath: 目录
@param *suffix: 后缀
"""
PathArray = []
for r, ds, fs in os.walk(dirpath):
for fn in fs:
if os.path.splitext(fn)[1] in suffix:
fname = os.path.join(r, fn)
PathArray.append(fname)
return PathArray
def write_face(imagePath, targetPath, faces, count, img):
"""
写入脸部图片到目标目录
@param imagePath: 图片目录
@param targetPath: 目标目录
@param faces: 脸部数据
@param count: 数目
@param img: 图片数据
"""
for (x, y, w, h) in faces:
# 设置人脸宽度大于16像素,去除较小的人脸
if w>=16 and h>=16:
# 以时间戳和读取的排序作为文件名称
listStr = [str(int(time.time())), str(count)]
fileName = ''.join(listStr)
# 扩大图片,可根据坐标调整
X = int(x)
W = min(int(x + w),img.shape[1])
Y = int(y)
H = min(int(y + h),img.shape[0])
f = cv2.resize(img[Y:H, X:W], (W-X,H-Y))
cv2.imwrite(targetPath+os.sep+'%s.jpg' % fileName, f)
count += 1
print (imagePath + "have face")
def read_pic_save_face(sourcePath, targetPath, *suffix):
"""
提取图片中的人脸
1.对list中图片逐一进行检查,找出其中的人脸然后写到目标文件夹下
2.haarcascade_frontalface_alt.xml 为库训练好的分类器文件
3.下载opencv,安装目录中可找到该xml文件
或关注 Python实用宝典 公众号后台回复 电影提取人脸 获取文件和源代码
@param sourcePath: 图片源目录
@param targetPath: 人脸目标目录
@param *suffix: 图片后缀
"""
ImagePaths=get_all_path(sourcePath, *suffix)
count = 0
face_cascade = cv2.CascadeClassifier('./haarcascade_frontalface_alt.xml')
# 分类器
for imagePath in ImagePaths:
# 遍历所有图片
img = cv2.imread(imagePath)
if type(img) != str:
faces = face_cascade.detectMultiScale(img, 1.1, 5)
if len(faces):
write_face(imagePath, targetPath, faces, count, img)
print ('Find '+str(count-1)+' faces to Destination '+targetPath)
if __name__ == '__main__':
sourcePath = 'frames/greenbooks'
targetPath1 = 'target/greenbooks'
read_pic_save_face(sourcePath, targetPath1, '.jpg', '.JPG', 'png', 'PNG')最后让我们来看看效果:

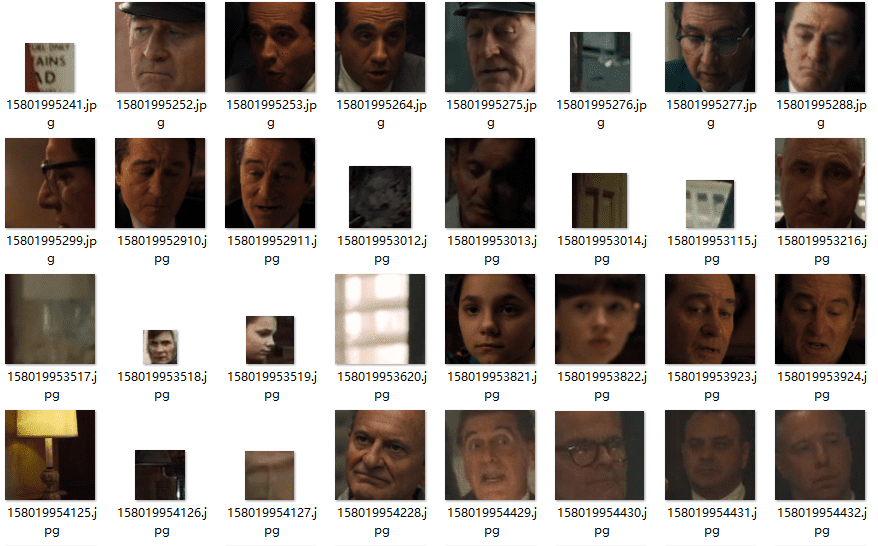
大部分提取都是正确的,当然不排除有些例外出现,这时候你就要手动去除了,比如说这个(汗):
您这也能分类成人脸???嗯???(不过仔细看还真挺像的)
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦
 有任何问题都可以在下方留言区留言,我们都会耐心解答的!
有任何问题都可以在下方留言区留言,我们都会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典