百度指数是一款非常好用的工具,通过它我们能知道某些关键词在过去的一些日子里的热度变化趋势并能够对这些数据进行分析。如果能用得好百度指数,我们将能产出巨大的价值。
你可以通过关注文章下方的公众号(Python实用宝典),回复 百度指数突变点 获得本文所有的源代码。
今天的教程主要是来教大家如何找出百度指数中突变值的位置,如图所示画框框的部分:

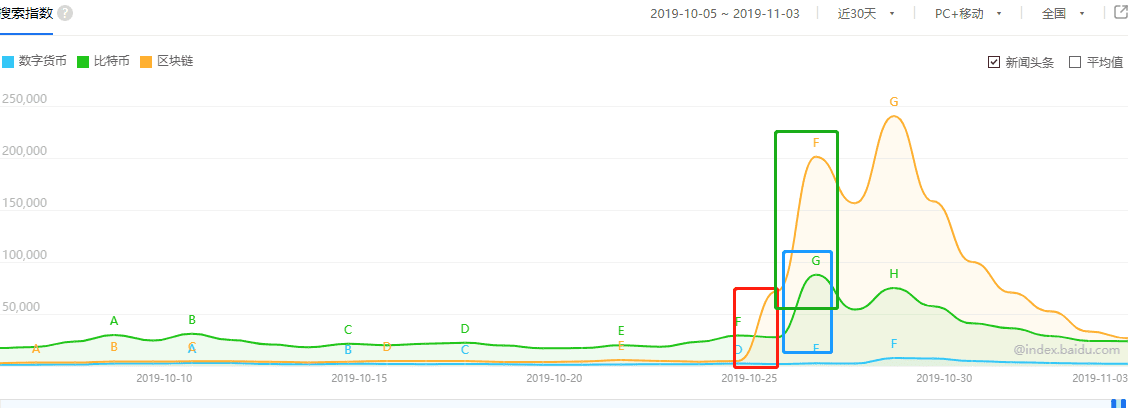
30天的数据流中很容易通过人工的方法找到突变数据的位置,但如果是180天呢?这可就不好通过人工的方法找了:

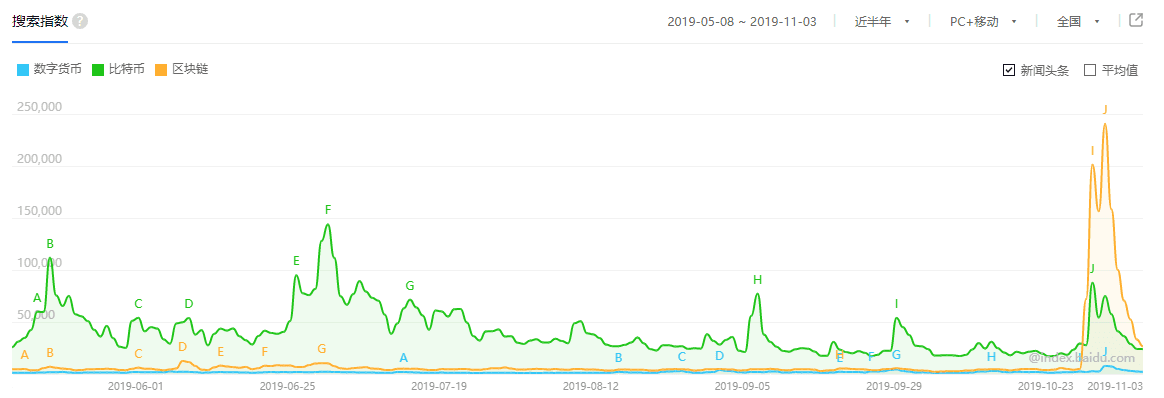
如何使用Python自动找出这180天里的突变点呢?由于这里涉及到了对时间序列的突变点的检测,我们可以使用一种叫 Pettitt突变点检测 算法。
1.获取数据
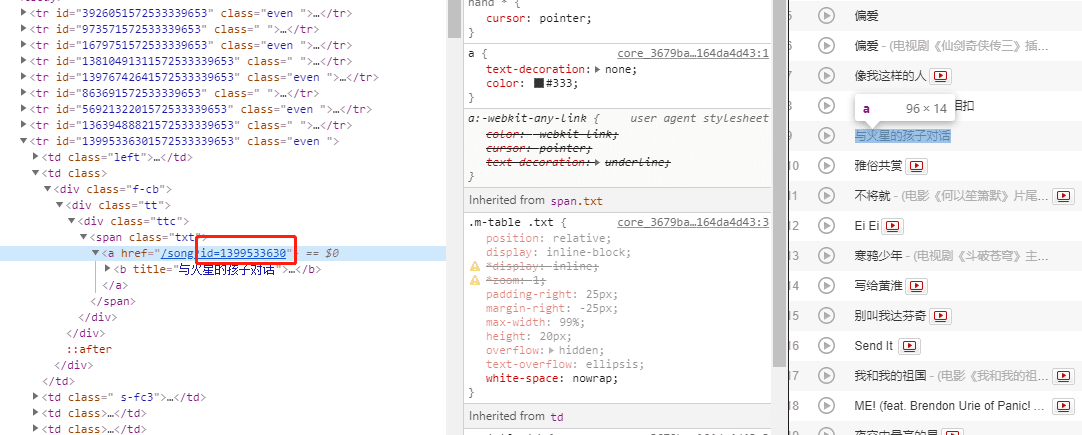
通过开发者工具找到数据接口,结果发现其接口返回来的数据进行了加密:

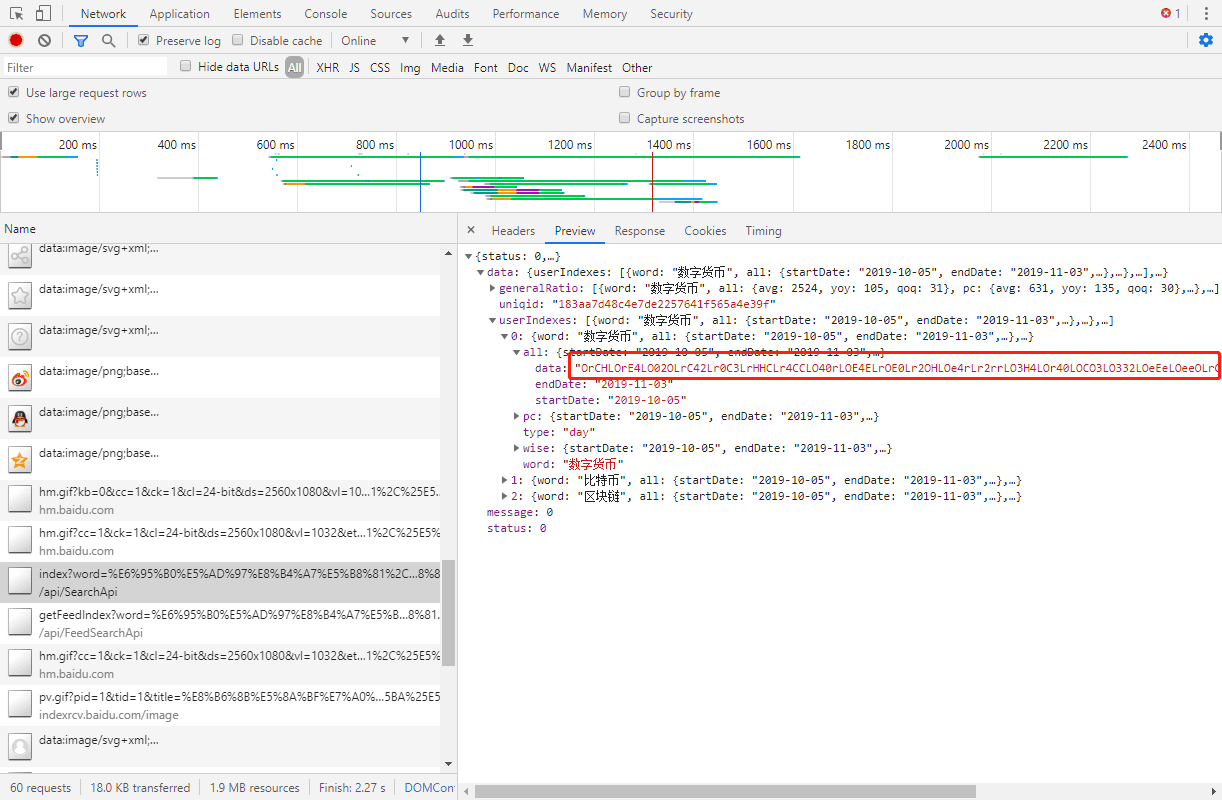
看起来就很像字符串替换,如果要从头开始解密的话需要做一些对比工作(把源数据和该加密数据放一起进行比较)或者直接看前端源代码 。由于这里不是今天要讲的重点内容,我直接使用了他人的开源项目: 百度指数爬虫 。你可以通过关注文章最下方的公众号(Python实用宝典),回复 百度指数突变点 获得本文所有的源代码。
将爬取到的数据,按照关键词存放到数组中,你可以很轻易地修改我的代码增加/减少关键词。如下:
from get_index import BaiduIndex
if __name__ == "__main__":
keywords = ['区块链']
results = {'区块链':[]}
baidu_index = BaiduIndex(keywords, '2019-05-04', '2019-11-04')
for index in baidu_index.get_index():
if index['type'] == 'all':
results[index['keyword']].append(index['index'])
print(results)

2.突变点算法
Pettitt突变点检测 算法是用R语言写的,实现其实很简单。作者并没有说为什么这么做,而是给了几个数学公式,我们只需要跟着做即可。


代码如下:
def pettitt(data):
data = np.array(data)
n = data.shape[0]
k = range(n)
dataT = pd.Series(data)
r = dataT.rank()
Uk = [2*np.sum(r[0:x])-x*(n + 1) for x in k]
Uabs = list(np.abs(Uk))
U = np.max(Uabs)
K = Uabs.index(U)
p = 2 * np.exp((-6 * (U**2))/(n**3 + n**2))
if p <= 0.5:
# 显著
result = 'yes'
else:
# 不显著
result = 'no'
return K, result 我们只需要将数据放入该函数,就能得到这段数据的突变点(一个),由于它只能找出一段数据里的一个突变点,而我们需要获得的是多个突变点,因此还得设置一个移动窗口,获得每个窗口中的突变位置。
3.设置窗口获得每个窗口的突变位置
将数据设为30天一个窗口,检测每个窗口中的突变值:
length = len(results['区块链'])
locations = []
for i in range(0, length, 1):
pos, result = pettitt(results['区块链'][i:i+29])
if result == 'yes':
locations.append(pos+i)
print(set(locations)) 结果如下:


这样看实在是不好看出什么,用matplotlib可视化一下:
print(results)
plt.plot(range(len(results['区块链'])), [int(i) for i in results['区块链']])
for i in locations:
plt.plot(i,int(results['区块链'][i]),'ks')
my_y_ticks = np.arange(0, 250000, 50000)
#显示范围为0至25000,每5000显示一刻度
plt.yticks(my_y_ticks)
plt.show()结果:

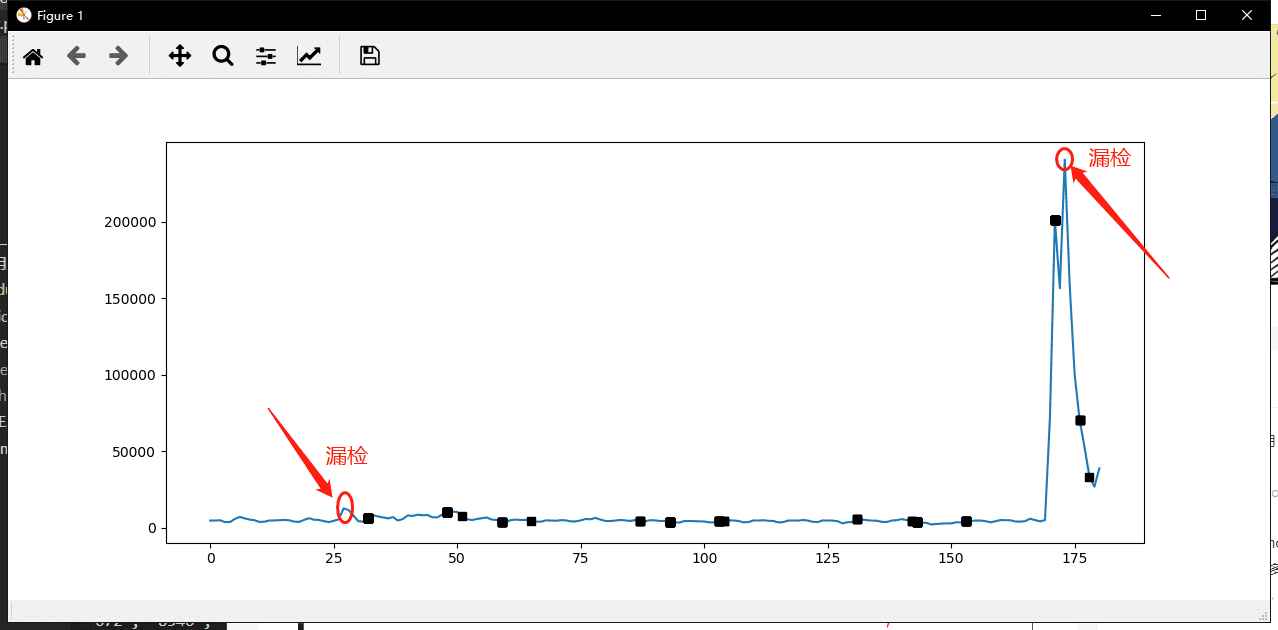
说实话,不太满意这个结果,有两个比较明显的两个突变点竟然没找出来。除开这两个突变点不说,整体上看,这个检测方法的效果还可以。
文章到此就结束啦, 你可以通过关注文章下方的公众号(Python实用宝典),回复 百度指数突变点 获得本文所有的源代码。
如果你喜欢今天的Python 教程,请持续关注Python实用宝典,如果对你有帮助,麻烦在下面点一个赞/在看哦![]()

Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典