Python之所以这么流行,是因为它不仅能够应用于科技领域,还能用来做许多其他学科的研究工具 ,最常见的便是绘制地图 。
今天我们用matplot工具 包之一的:mpl_toolkits来绘制世界地图 ,这是一个简单的可视化地图 工具 ,你如果希望绘制更加复杂的地图 ,可以考虑使用Google Maps API,不过这不在我们今天的讨论范围之内。
1.安装
如果你还没有安装Python,请见这篇文章:超详细Python安装指南
为了能够顺利开展本项目,你需要先安装以下依赖,在cmd或Terminal中输入以下命令:
pip install numpy
pip install matplotlib
为了使用 mpl_toolkits, 单纯安装matplotlib是不够的,我们还需要单独安装basemap,如果你已经安装了Anaconda,那这一步就非常好办,输入以下命令安装即可:
conda install basemap
如果没有的话,就稍微麻烦一点:
1.安装geos: pip install geos htt p://www.lfd.uci.edu/~gohlke/pythonlibs/#basemap pip install basemap‑1.2.1‑cp37‑cp37m‑win_amd64.whl
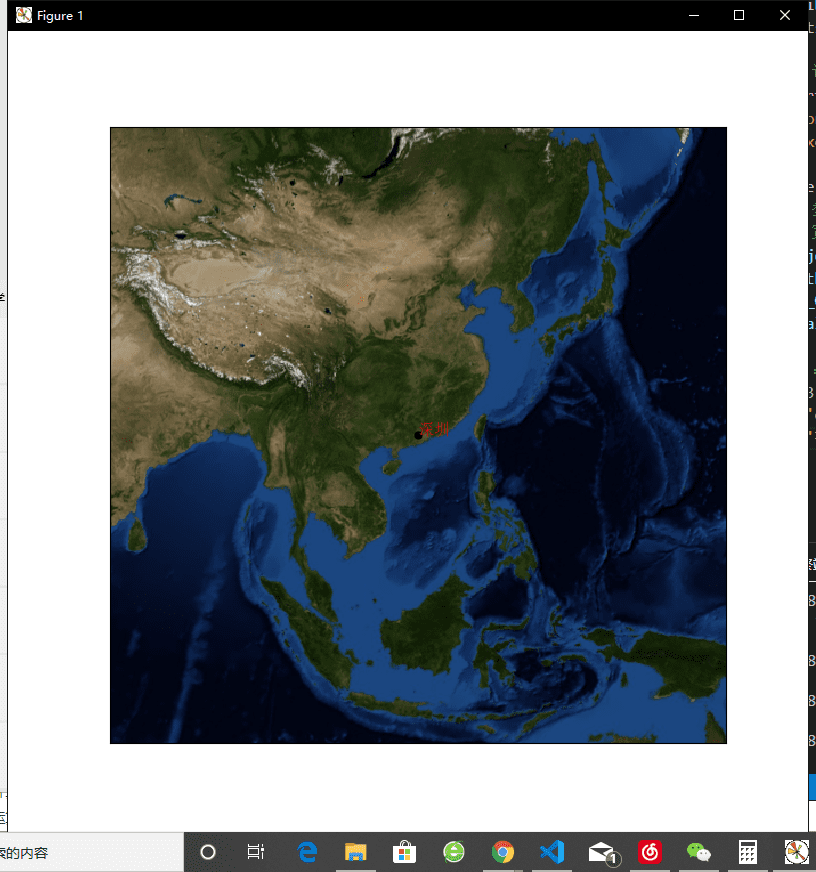
让我们开始绘制一个地球,中心指向中国:
# 导入需要的包
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
# 初始化图形
plt.figure(figsize=(8, 8))
# 底图:圆形, lat_0:纬度;lon_o: 经度, (113,29)是武汉
m = Basemap(projection='ortho', resolution=None, lat_0=29, lon_0=113)
# 底色
m.bluemarble(scale=0.5)
# 显示
plt.show() 这里的重点在于Basemap,指定好你想要放置的中心。
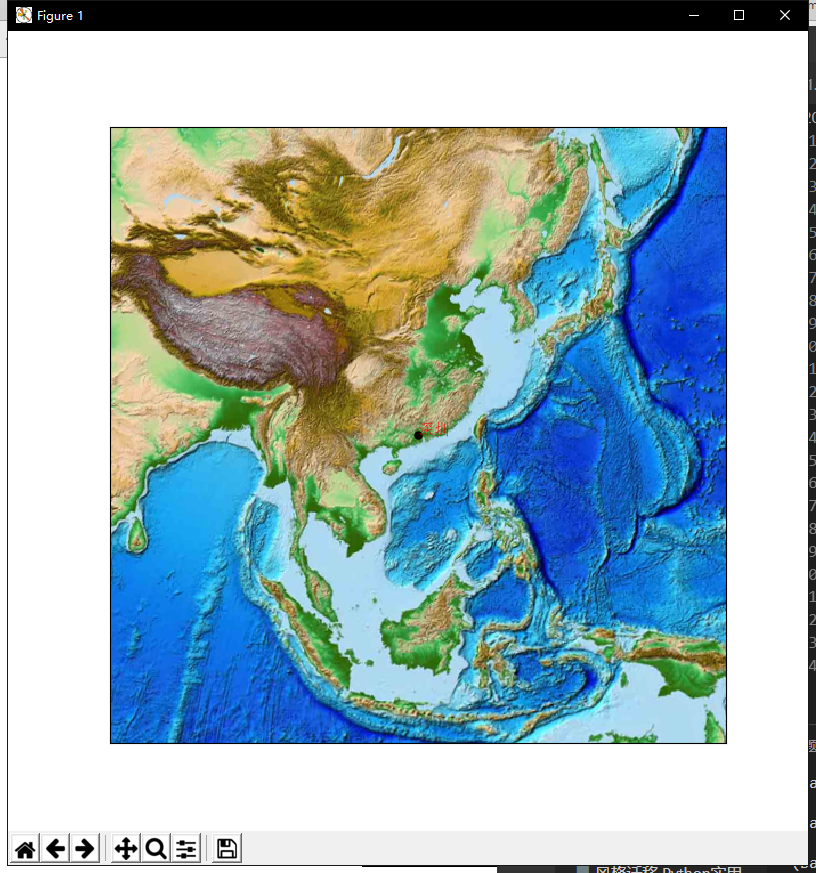
效果还不错哦,不仅如此,它其实不单单只是一张图像 ,它还是一个功能齐全的matplot画布。这也就意味着,你能够在上面画线!让我们放大地图 ,进入中国区域,然后标记出深圳的位置:
# 导入需要的包
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
# 以下三行是为了让matplot能显示中文
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong']
mpl.rcParams['axes.unicode_minus'] = False
fig = plt.figure(figsize=(8, 8))
# 注意几个新增的参数, width和height是用来控制放大尺度的
# 分别代表投影的宽度和高度(8E6代表 8x10^6米)
m = Basemap(projection='lcc', resolution=None,
width=8E6, height=8E6,
lat_0=23, lon_0=113,)
m.bluemarble(scale=0.5)
# 这里的经纬度是:(经度, 纬度)
x, y = m(113, 23)
plt.plot(x, y, 'ok', markersize=5)
plt.text(x, y, '深圳', fontsize=12, color="red")
plt.show() 不要用蓝底图了,看得不是很清晰,我们换成浮雕型:
可以很明显地看到山区、丘陵等地理样貌。你还可以根据你的需要,针对某几个城市做连线或者绘制某些经纬度之间的区域。别忘了,这可是matplotlib可编辑的画布。
接下来,我们将上述的世界地图 展开成带经纬线的平面图形。
# 导入需要的包
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
from itertools import chain
def draw_map(m, scale=0.2):
# 绘制带阴影的浮雕图像
m.shadedrelief(scale=scale)
# 根据经纬度切割,每13度一条线
lats = m.drawparallels(np.linspace(-90, 90, 13))
lons = m.drawmeridians(np.linspace(-180, 180, 13))
# 集合所有线条
lat_lines = chain(*(tup[1][0] for tup in lats.items()))
lon_lines = chain(*(tup[1][0] for tup in lons.items()))
all_lines = chain(lat_lines, lon_lines)
# 循环画线
for line in all_lines:
line.set(linestyle='-', alpha=0.3, color='w')
fig = plt.figure(figsize=(8, 6), edgecolor='w')
m = Basemap(projection='cyl', resolution=None,
llcrnrlat=-90, urcrnrlat=90,
llcrnrlon=-180, urcrnrlon=180,)
draw_map(m)
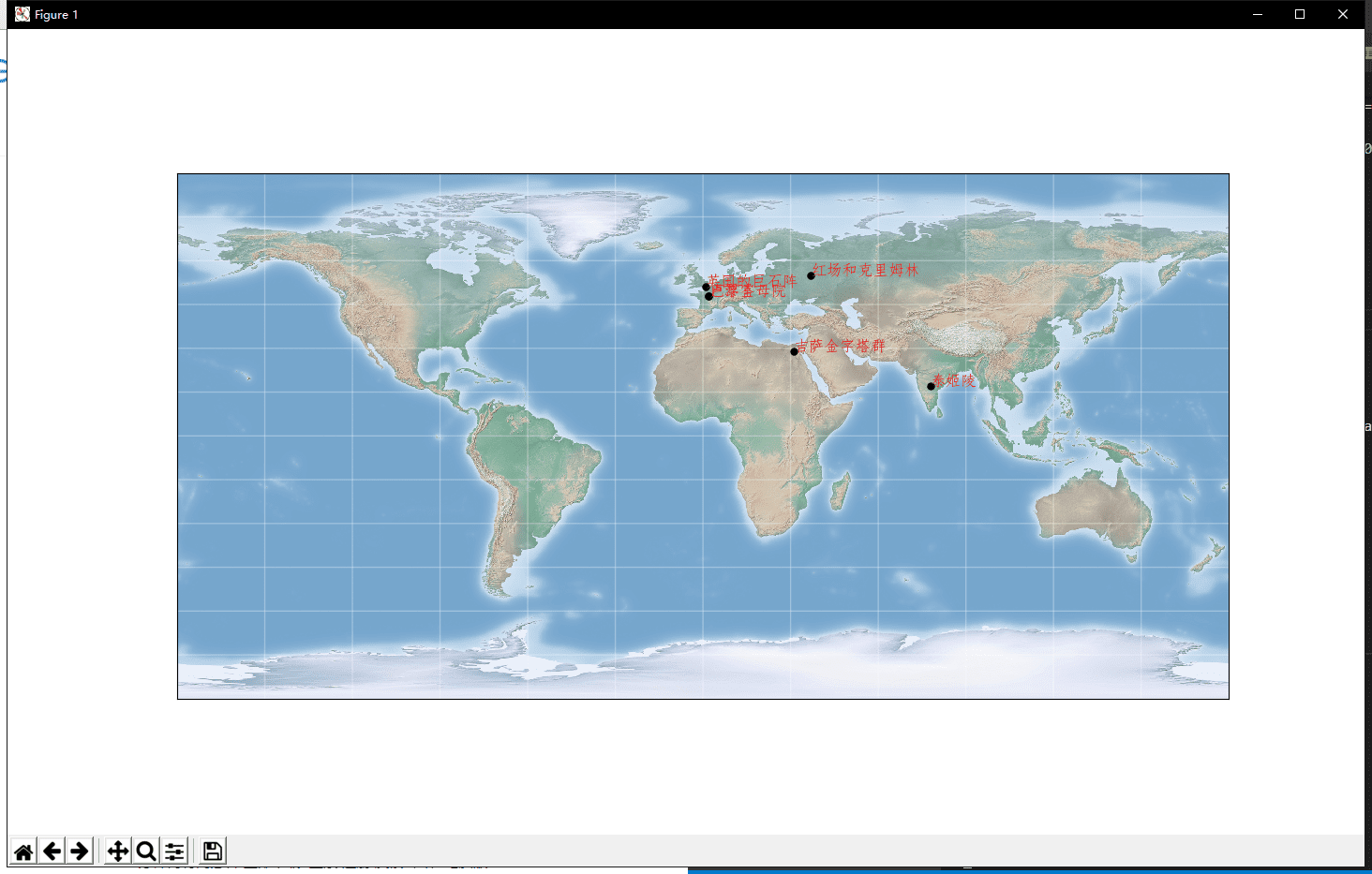
plt.show() 嗯,有点那个味了哈。都可以自己去打印出来给小孩子学习地理了。但是他如果想学习地理,好像整个世界有点大?我们先让他学习世界著名景点的位置吧?
# 导入需要的包
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
from itertools import chain
# 以下三行是为了让matplot能显示中文
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong']
mpl.rcParams['axes.unicode_minus'] = False
def draw_point(m, x, y, name):
# 这里的经纬度是:(经度, 纬度)
x, y = m(x, y)
plt.plot(x, y, 'ok', markersize=5)
plt.text(x, y, name, fontsize=12, color="red")
def draw_map(m, scale=0.2):
# 绘制带阴影的浮雕图像
m.shadedrelief(scale=scale)
# 根据经纬度切割,每13度一条线
lats = m.drawparallels(np.linspace(-90, 90, 13))
lons = m.drawmeridians(np.linspace(-180, 180, 13))
# 集合所有线条
lat_lines = chain(*(tup[1][0] for tup in lats.items()))
lon_lines = chain(*(tup[1][0] for tup in lons.items()))
all_lines = chain(lat_lines, lon_lines)
# 循环画线
for line in all_lines:
line.set(linestyle='-', alpha=0.3, color='w')
fig = plt.figure(figsize=(8, 6), edgecolor='w')
m = Basemap(projection='cyl', resolution=None,
llcrnrlat=-90, urcrnrlat=90,
llcrnrlon=-180, urcrnrlon=180,)
locations = {
'泰姬陵': (17, 78),
'吉萨金字塔群': (29, 31),
'英国的巨石阵': (51, 1),
'巴黎圣母院': (48, 2),
'卢浮宫': (48, 2),
'红场和克里姆林': (55, 37),
# ...
}
draw_map(m)
for loc in locations:
print(locations[loc])
draw_point(m, locations[loc][1], locations[loc][0], loc)
plt.show() 这样,你只需要往locations里类似地加入某个地点的经纬度,就能在地图 上展示出来了,你还能自定义地画两个地点之间的连线,或者是重点放大某个区域,总而言之,你想干的,基本上基于Matplotlib都可以做得到。
我们的文章到此就结束啦,如果你希望我们今天的Python 教程 ,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦
Python实用宝典 (pythondict.com )