很多玩股票的朋友都希望能通过计算机来自动买入卖出股票,这样的作法在美股中很常见,但在A股由于监管的问题,从前我们的做法是通过Easytrader来实现股票的自动买入和卖出,但是这种做法会让交易时延达到1秒左右,而现在,通过QMT我们能直接将这1秒的延迟直接消除。
通过QMT的交易接口,我们能实现毫秒级的交易时延,比Easytrader速度快不少。这非常重要,要知道对于交易热门的股票,差1秒,买入价差可能就差5档。
本文将教大家如何使用QMT进行基础的简单买入卖出和撤单的功能,在本文的最后会介绍仅需3万门槛且起步仅0.5元的QMT开通通道。
1.下载并使用QMT程序
QMT程序可以在我们公众号后台回复 QMT 下载。
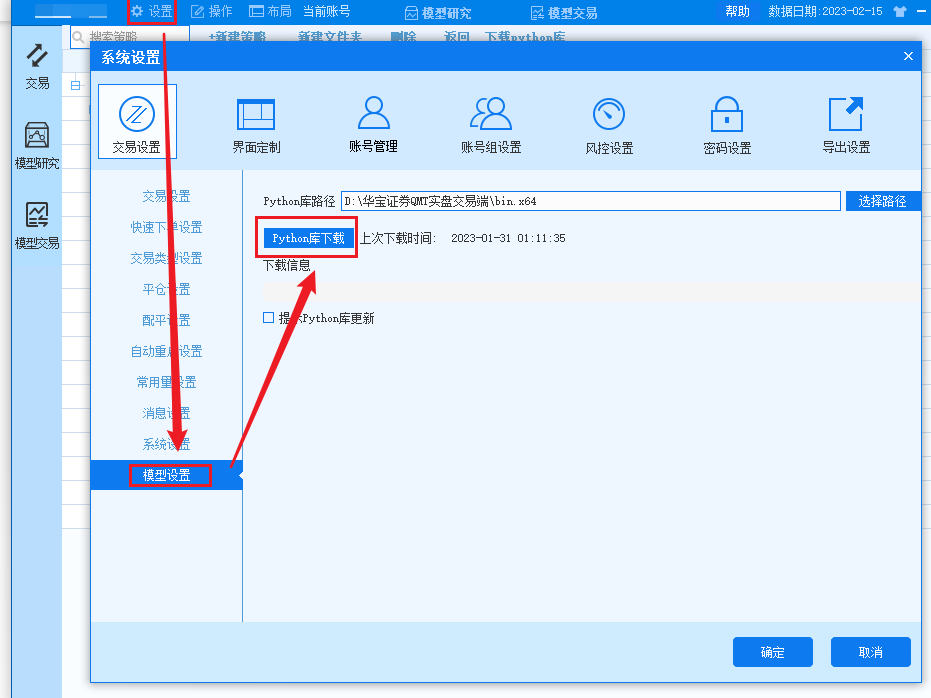
下载登陆后,请先安装Python,在设置->模型设置中,点击Python库下载即可:

然后,要实现自动交易的功能,我们必须在模型研究中,新建一个策略:

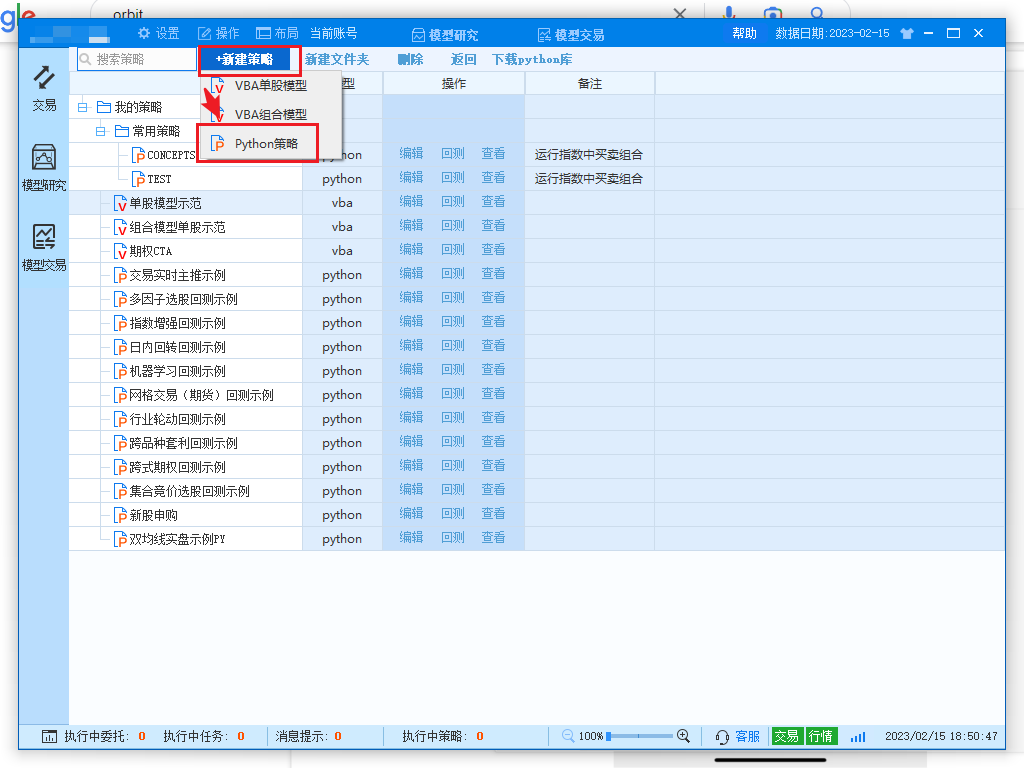
然后就会弹出一个策略的编辑器,在这里会编辑我们的买入卖出策略:
2.QMT基本函数介绍
QMT的基本执行结构是:
# 公众号:二七阿尔量化
def init(ContextInfo):
ContextInfo.accID = '你的账号ID'
def handlebar(ContextInfo):
# 处理K线
pass
下面会一步一步地讲解如何基于这个基本结构制作我们的根据信号买入卖出策略。
定时器
定时器是我们实现毫秒级策略的基础。在QMT中,执行是按照K线来的,比如分钟K线,日线等K线类型,新的一根bar到来后,就进入handle_bar函数被用户处理。但是这样按K线执行的逻辑有一个严重的问题,那就是无法执行秒级、毫秒级的策略。
如果你需要执行毫秒级的策略,就需要用到定时器了:
# 公众号:二七阿尔量化
ContextInfo.run_time("buy_logic", "100nMilliSecond", "2019-10-14 13:20:00")
这行代码的意思便是从2019-10-14 13:20:00开始,每隔100毫秒执行一次 buy_logic 函数。
只需要把这行代码放在 init 函数下,便会启动定时器。
买入卖出
首先介绍如何在QMT中实现自动买入卖出。QMT的买入卖出函数都是 passorder,通过传参实现不同的操作,比如:
passorder(23, 1102, account_id, "002587", 11, 6.80, 55000, "concepts_main", 1, "", ContextInfo)
看不懂不要紧,我们先往下看。
对于股票交易,它的参数列表如下:
passorder(opType, orderType, accountid, orderCode, prType, modelprice, volume, strategyName, quickTrade, ContextInfo)
opType: 我们上述例子中 opType 为 23,意思为 股票买入,或沪港通、深港通股票买入。对于股票的交易,它只有两种选项:
23: 股票买入,或沪港通、深港通股票买入 24: 股票卖出,或沪港通、深港通股票卖出
orderType: 这个参数是能让你指定 按股买入/按金额买入/按总资产比例买入/按可用比例买入某只股票,非常好用:
1101: 单股、单账号、普通、股/手方式下单(ETF申赎只能用此参数) 1102: 单股、单账号、普通、金额(元)方式下单(只支持股票) 1113: 单股、单账号、总资产、比例[0~1]方式下单 1123: 单股、单账号、可用、比例[0~1]方式下单
account_id: 用户ID,即你的股票账户名。
orderCode: 股票代码,不要添加任何后缀。
prType: 下单选价类型,可以选择以下委托方式
0:卖5价 1:卖4价 2:卖3价 3:卖2价 4:卖1价 5:最新价 6:买1价 7:买2价(组合不支持) 8:买3价(组合不支持) 9:买4价(组合不支持) 10:买5价(组合不支持) 11:(指定价)模型价(只对单股情况支持,对组合交易不支持) 12:涨跌停价 13:挂单价 14:对手价 26:限价即时全部成交否则撤单[上交所|深交所][期权] 27:市价即成剩撤[上交所][期权] 28:市价即全成否则撤[上交所][期权] 29:市价剩转限价[上交所][期权] 42:最优五档即时成交剩余撤销申报[上交所][股票] 43:最优五档即时成交剩转限价申报[上交所][股票] 44:对手方最优价格委托[深交所][股票][期权] 45:本方最优价格委托[深交所][股票][期权] 46:即时成交剩余撤销委托[深交所][股票][期权] 47:最优五档即时成交剩余撤销委托[深交所][股票][期权] 48:全额成交或撤销委托[深交所][股票][期权]
请注意,在今天全面注册制后,正常交易存在价格笼子(挂单最多只能在当前最新价上浮动2%),所以除了在集合竞价中使用涨跌停价(12),其他情况都不要使用。
modelprice: 指定买入价格,只有当prType是模型价时price有效;其它情况无效。
volume: 决定买入的量,根据orderType值最后一位确定volume的单位:
# 当orderType最后一位为: 1:股/手 2:金额(元) 3:比例
strategyName: 策略名称,按你喜好来定即可
quickTrade: 是否立马触发下单,0 否,1 是
ContextInfo: QMT的上下文,必须传递,保持变量不变即可。
然后我们再回过头来看这行代码:
# 公众号: 二七阿尔量化 passorder(23, 1102, account_id, "002587", 11, 6.80, 55000, "concepts_main", 1, "", ContextInfo)
它的意思是,用户(参数2) 以指定金额的方式(参数1) 买入(参数0) 股票002587(参数3), 按照指定价(参数4) 6.80 元的价格(参数5), 希望可以成交 55000 元(参数6).
现在,不看我的答案的情况下,尝试理解下面这行卖出代码:
# 公众号: 二七阿尔量化 passorder(24, 1123, account_id, "002587", 12, 0, 1, "concepts_main", 1, "", ContextInfo)
答案是用户(参数2) 以可用比例的方式(参数1) 卖出(参数0) 股票002587(参数3), 按照涨跌停价(参数4) (参数5随意), 希望可以 100% (参数6) 成交。
获取仓位
仓位的获取也很简单,只需要传递account_id,第二个参数指定 “STOCK”(股票), 第三个参数指定为”POSITION”(仓位)即可:
# 公众号: 二七阿尔量化 positions = get_trade_detail_data(account_id, "STOCK", "POSITION")
获取委托
委托列表和仓位列表的获取方式都是通过get_trade_detail_data函数,只不过第三个参数改为”ORDER”
# 公众号: 二七阿尔量化 get_trade_detail_data(account_id, "STOCK", "ORDER"):
3.QMT买入、卖出、撤单并行运行
如果你希望一个线程检测是否买入某只股票、另一个线程检测是否需要撤单,还有一个线程进行卖出操作,那么你可以这么做:
# encoding:gbk
# 公众号: 二七阿尔量化
import time
import datetime
account_id = ""
def init(ContextInfo):
ContextInfo.accID = account_id
ContextInfo.max_buy = 3
ContextInfo.run_time("buy_logic", "100nMilliSecond", "2019-10-14 13:20:00", 'SZ')
ContextInfo.run_time("cancel_logic", "1000nMilliSecond", "2019-10-14 13:20:00", 'SZ')
ContextInfo.run_time("sell_logic", "300nMilliSecond", "2019-10-14 13:20:00", 'SZ')
def handlebar(ContextInfo):
pass
def buy_logic(ContextInfo):
"""
你的买入逻辑
"""
pass
def cancel_logic(ContextInfo):
"""
你的撤单逻辑
"""
pass
def sell_logic(ContextInfo):
"""
你的卖出逻辑
"""
pass
这三个run_time的意思是分别按每100毫秒执行买入逻辑、每1秒执行撤单逻辑,每300毫秒执行卖出逻辑。
只需要一个程序就能完成这三件事,用过Easytrader的同学一下就会明白这比Easytrader好用多了。
我们有一个相对完整的根据信号买入卖出的代码,在开户入金完成后,公众号后台回复:QMT代码 联系我获取代码。
4.运行QMT自动买入卖出程序
填充完你的各种逻辑后,保存程序,点击模型交易

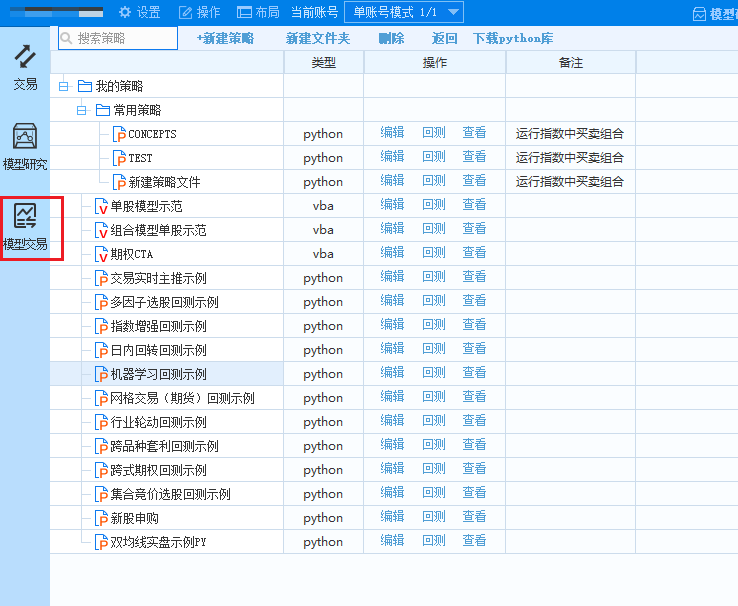
选择左上角的新建策略交易,找到你刚刚保存的策略:

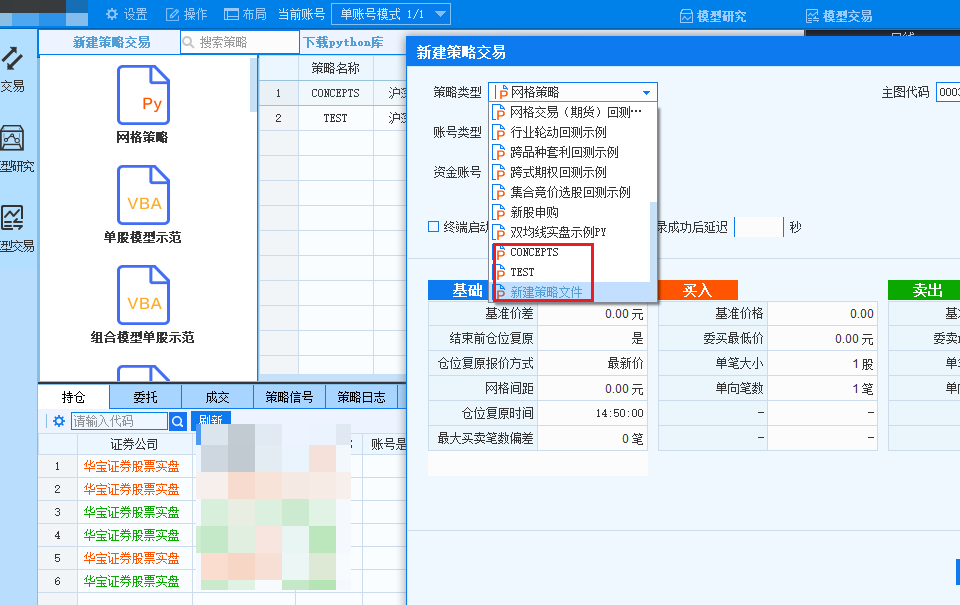
选择好账号类型和资金账号,确定后便可以准备开始运行策略,点击运行模式可以切换实盘/模拟盘。点击操作里的三角形便可以启动策略。

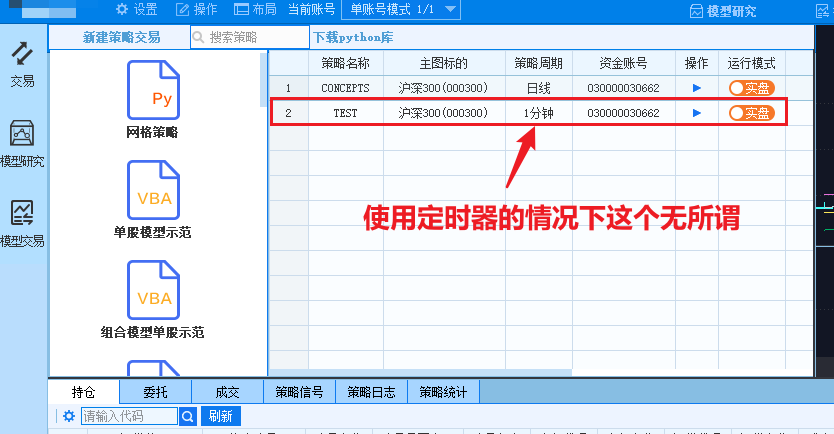
如果你是按本文定时器的方法使用QMT,你不需要在意策略周期。
本文对QMT的基本介绍结束,根据我这半个月的使用经历,我认为QMT对于我们量化交易而言是非常值得使用的,平均成交时间会比Easytrader方法快1秒左右。此外也不需要开启多个Easytrader进程去按键精灵般点点点,基本不会出现报错的情况。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典