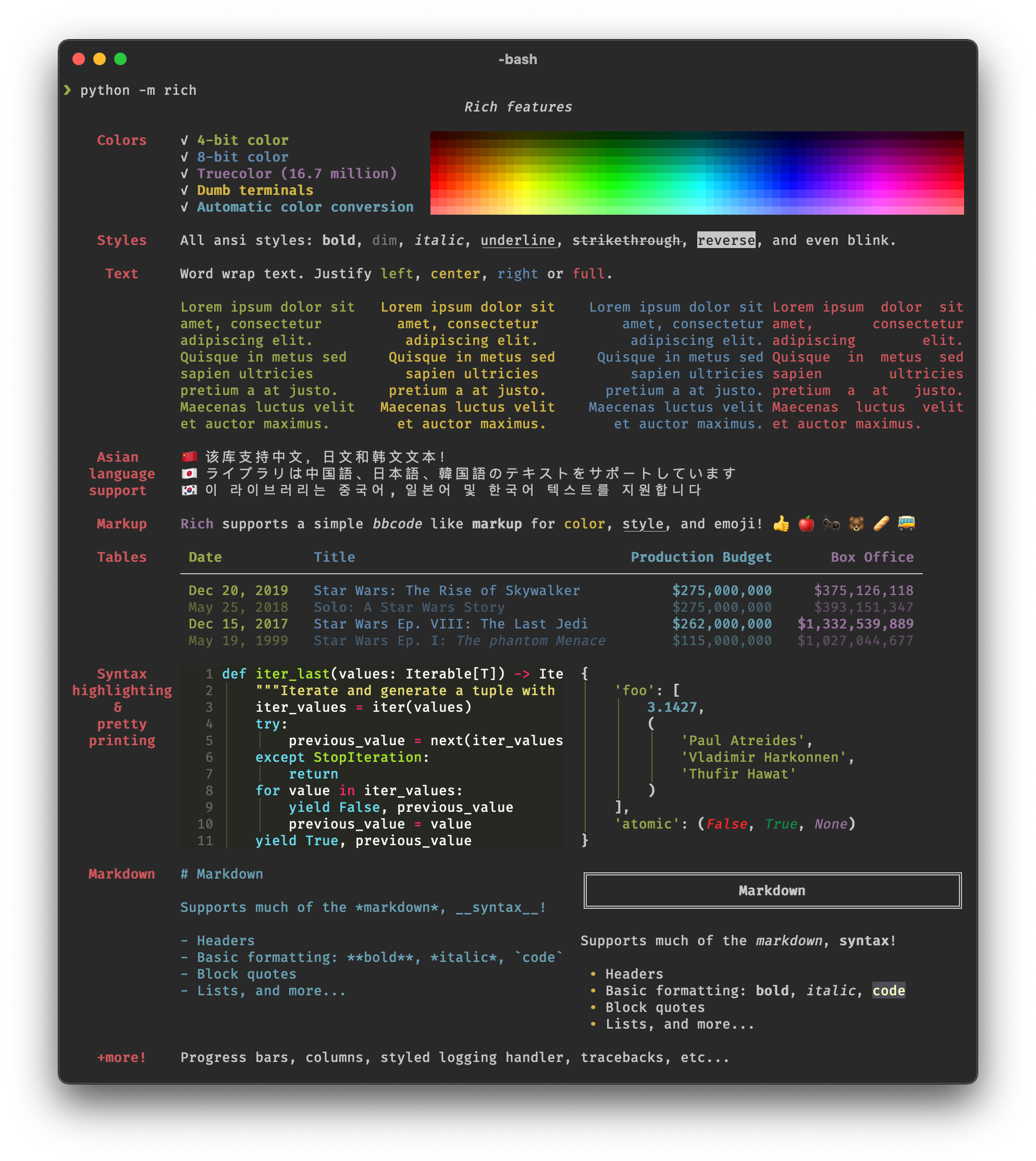
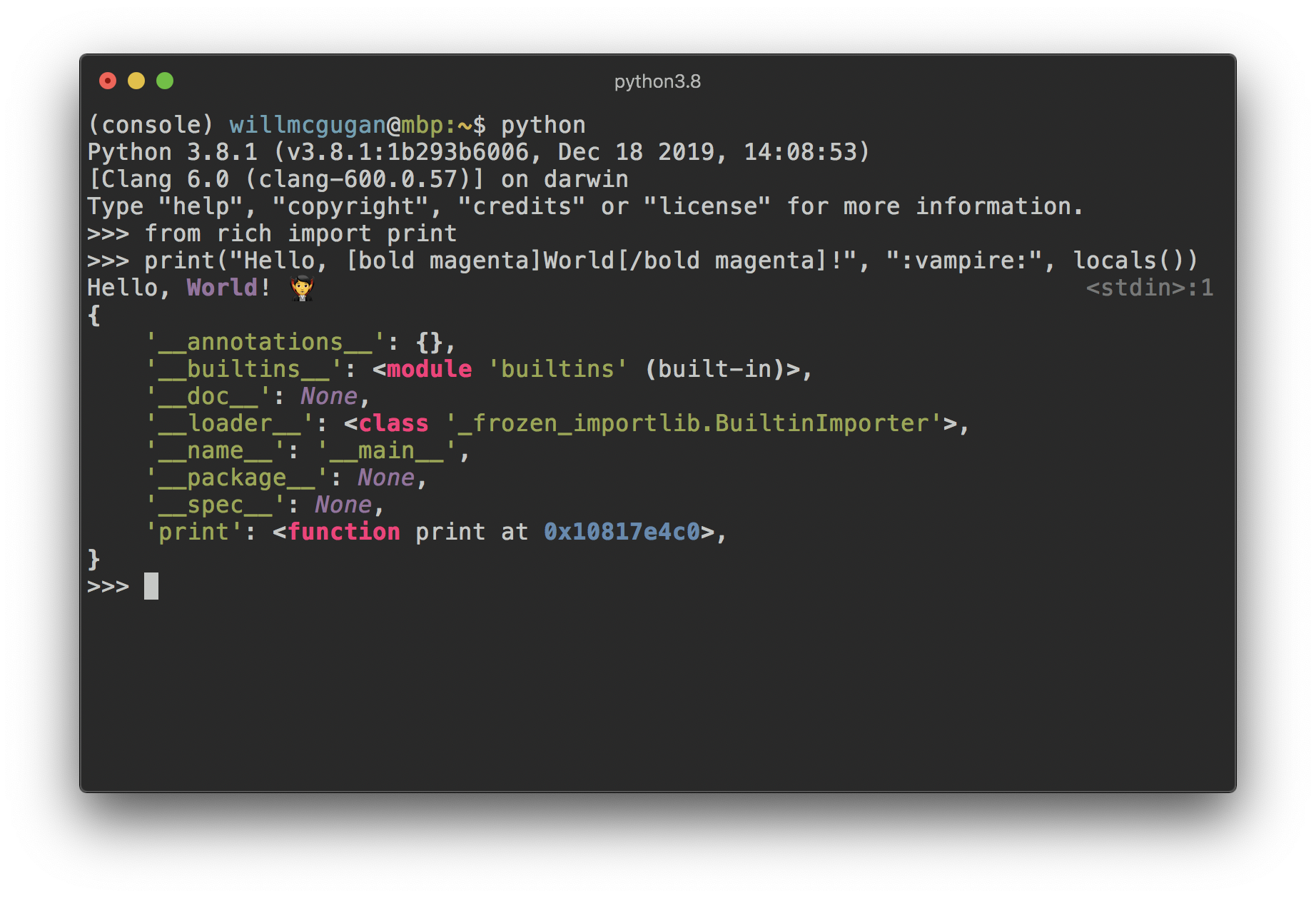
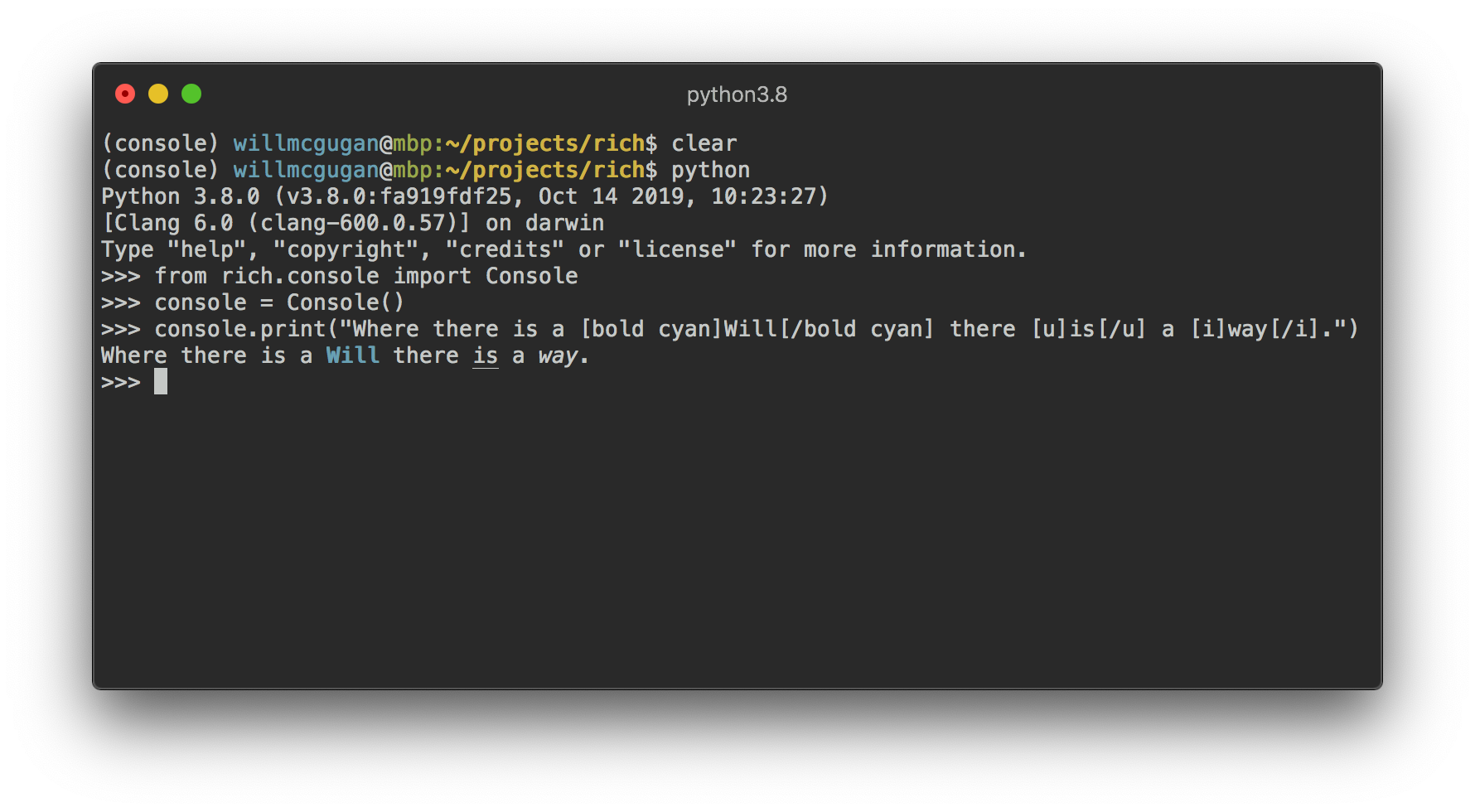
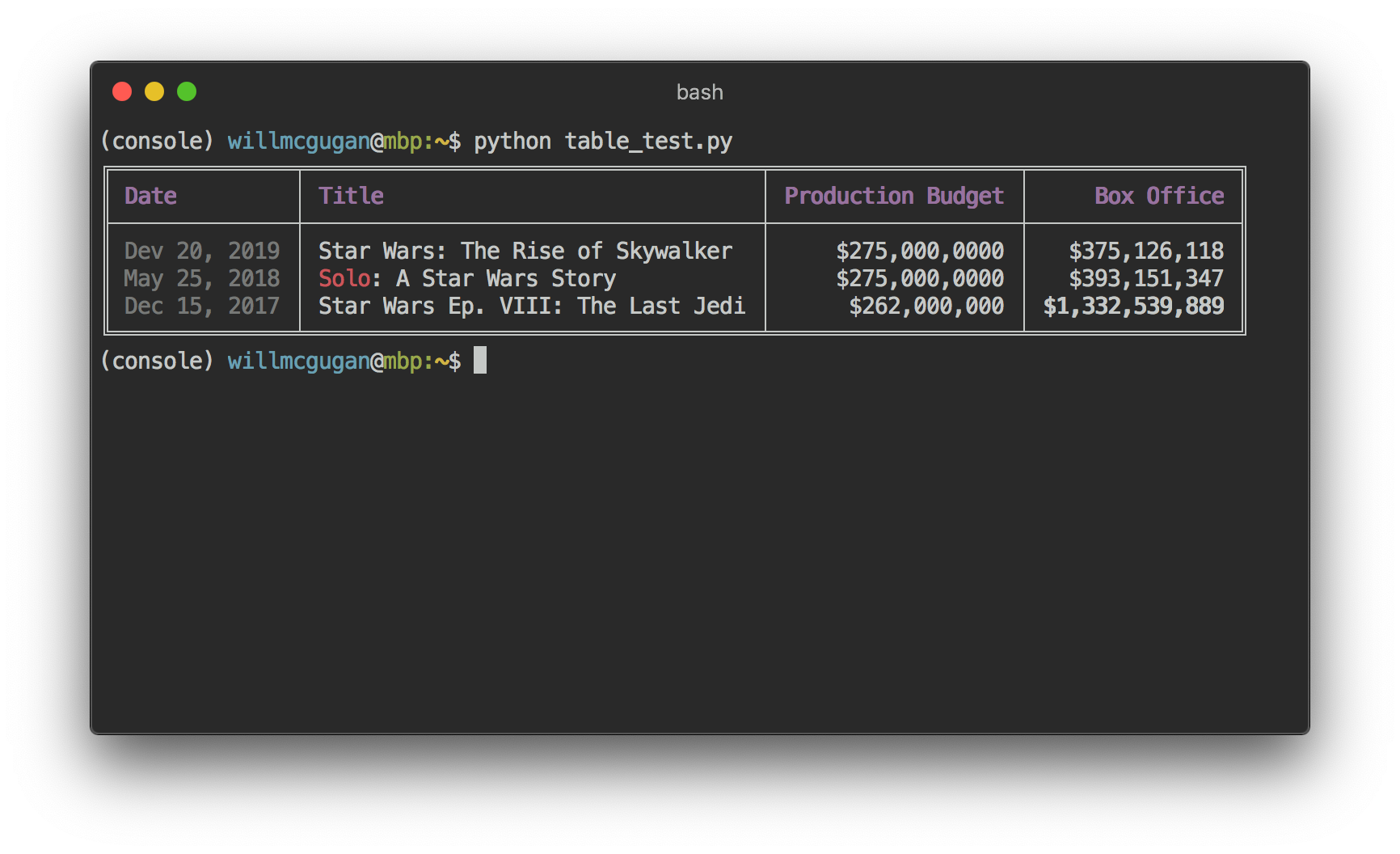
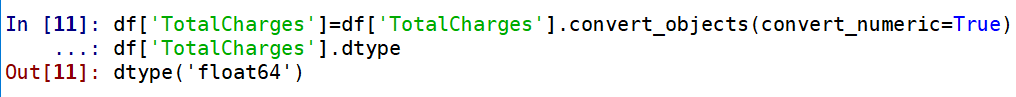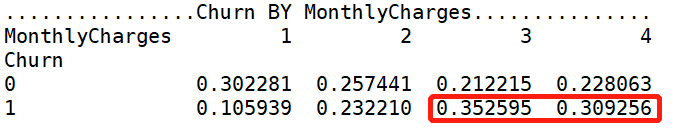from rich.console import Console
from rich.markdown import Markdown
console = Console()
with open("README.md") as readme:
markdown = Markdown(readme.read())
console.print(markdown)
from rich.console import Console
from rich.syntax import Syntax
my_code = '''
def iter_first_last(values: Iterable[T]) -> Iterable[Tuple[bool, bool, T]]:
"""Iterate and generate a tuple with a flag for first and last value."""
iter_values = iter(values)
try:
previous_value = next(iter_values)
except StopIteration:
return
first = True
for value in iter_values:
yield first, False, previous_value
first = False
previous_value = value
yield first, True, previous_value
'''
syntax = Syntax(my_code, "python", theme="monokai", line_numbers=True)
console = Console()
console.print(syntax)
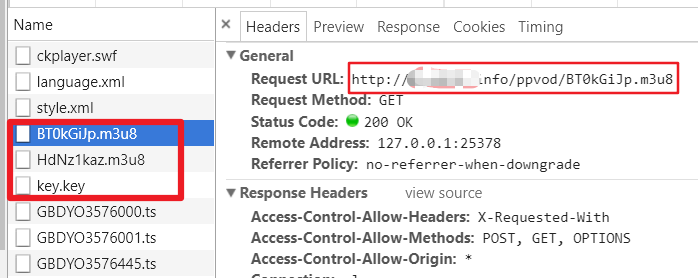
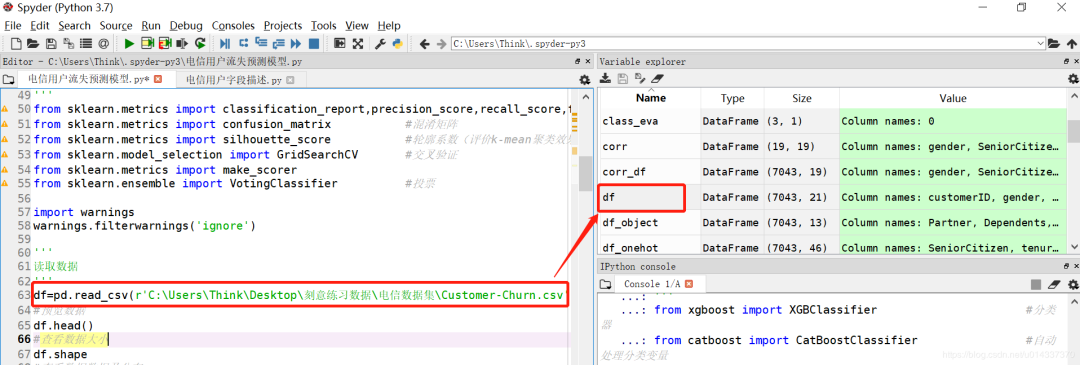
import os
filePath = "你的ts视频存放路径"
file_list = sorted(os.listdir(filePath))
with open("你的ts视频存放路径/file_list.txt","w+") as f:
for file in file_list:
f.write("file '{}'\n".format(file))
注意,这个 file_list.txt 需要和你的 ts 视频存放在同一个目录下,然后 cd 进入此目录,并执行上面提到过的 ffmpeg 合并转换命令:
>>> def create_generator():
... mylist = range(3)
... for i in mylist:
... yield i*i
...
>>> mygenerator = create_generator() # create a generator
>>> print(mygenerator) # mygenerator is an object!
<generator object create_generator at 0xb7555c34>
>>> for i in mygenerator:
... print(i)
0
1
4
第一次 for 调用从您的函数创建的生成器对象时,它将从头开始运行您的函数中的代码,直到命中yield,然后它将返回循环的第一个值。然后,每个后续调用将运行您在函数中编写的循环的另一次迭代并返回下一个值。这将一直持续到生成器被认为是空的为止。
4. 控制生成器耗尽的一个例子
>>> class Bank(): # Let's create a bank, building ATMs
... crisis = False
... def create_atm(self):
... while not self.crisis:
... yield "$100"
>>> hsbc = Bank() # When everything's ok the ATM gives you as much as you want
>>> corner_street_atm = hsbc.create_atm()
>>> print(corner_street_atm.next())
$100
>>> print(corner_street_atm.next())
$100
>>> print([corner_street_atm.next() for cash in range(5)])
['$100', '$100', '$100', '$100', '$100']
>>> hsbc.crisis = True # Crisis is coming, no more money!
>>> print(corner_street_atm.next())
<type 'exceptions.StopIteration'>
>>> wall_street_atm = hsbc.create_atm() # It's even true for new ATMs
>>> print(wall_street_atm.next())
<type 'exceptions.StopIteration'>
>>> hsbc.crisis = False # The trouble is, even post-crisis the ATM remains empty
>>> print(corner_street_atm.next())
<type 'exceptions.StopIteration'>
>>> brand_new_atm = hsbc.create_atm() # Build a new one to get back in business
>>> for cash in brand_new_atm:
... print cash
$100
$100
$100
$100
$100
$100
$100
$100
$100
...
import matplotlib.pyplot as plt import seaborn as sns sns.set(style='darkgrid',font_scale=1.3) plt.rcParams['font.family']='SimHei' plt.rcParams['axes.unicode_minus']=False
6.1.3 特征工程
import sklearn from sklearn import preprocessing #数据预处理模块 from sklearn.preprocessing import LabelEncoder #编码转换 from sklearn.preprocessing import StandardScaler #归一化 from sklearn.model_selection import StratifiedShuffleSplit #分层抽样 from sklearn.model_selection import train_test_split #数据分区 from sklearn.decomposition import PCA #主成分分析 (降维)
6.1.4 分类算法
from sklearn.ensemble import RandomForestClassifier #随机森林 from sklearn.svm import SVC,LinearSVC #支持向量机 from sklearn.linear_model import LogisticRegression #逻辑回归 from sklearn.neighbors import KNeighborsClassifier #KNN算法 from sklearn.cluster import KMeans #K-Means 聚类算法 from sklearn.naive_bayes import GaussianNB #朴素贝叶斯 from sklearn.tree import DecisionTreeClassifier #决策树
6.1.5 分类算法–集成学习
import xgboost as xgb from xgboost import XGBClassifier from catboost import CatBoostClassifier from sklearn.ensemble import AdaBoostClassifier from sklearn.ensemble import GradientBoostingClassifier
6.1.6 模型评估
from sklearn.metrics import classification_report,precision_score,recall_score,f1_score #分类报告 from sklearn.metrics import confusion_matrix #混淆矩阵 from sklearn.metrics import silhouette_score #轮廓系数(评价k-mean聚类效果) from sklearn.model_selection import GridSearchCV #交叉验证 from sklearn.metrics import make_scorer from sklearn.ensemble import VotingClassifier #投票
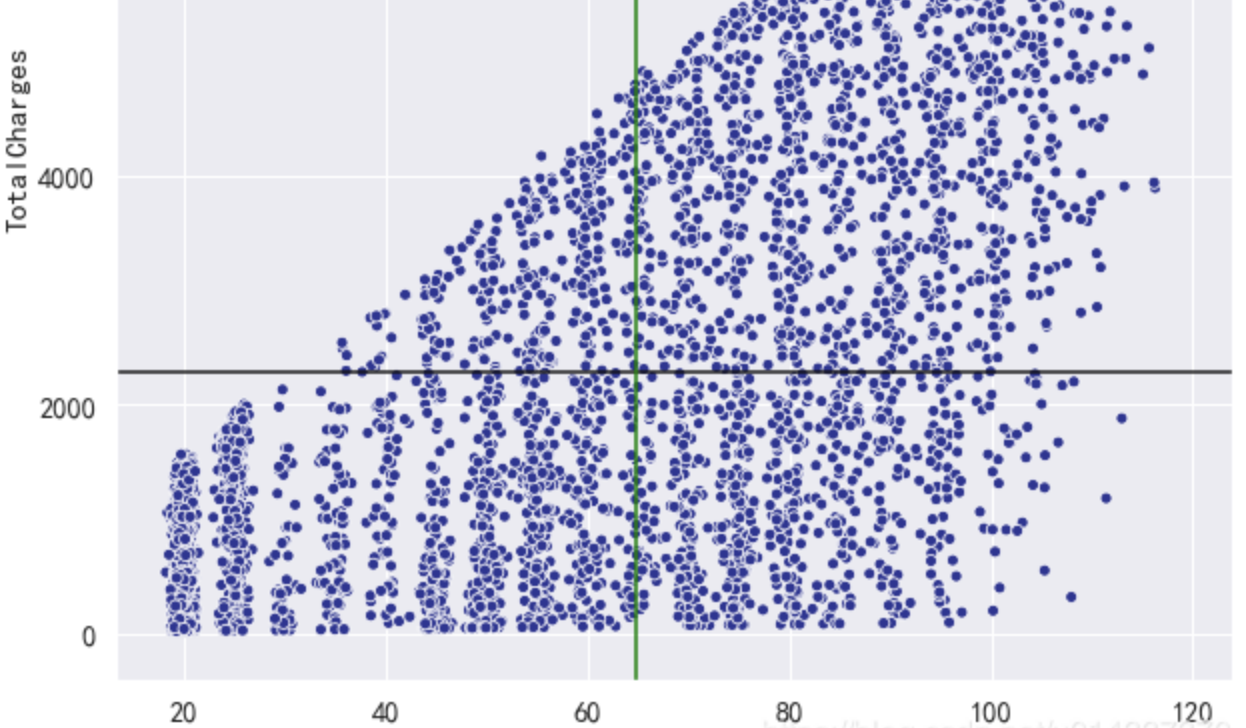
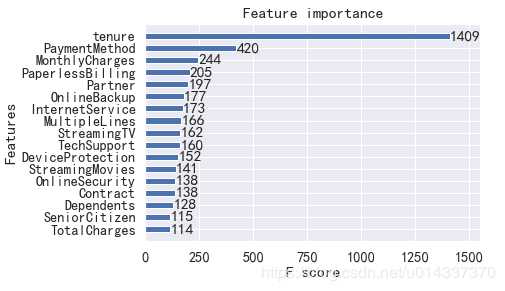
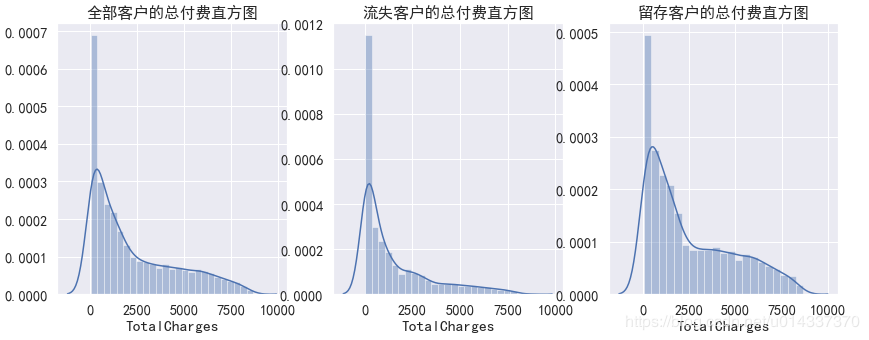
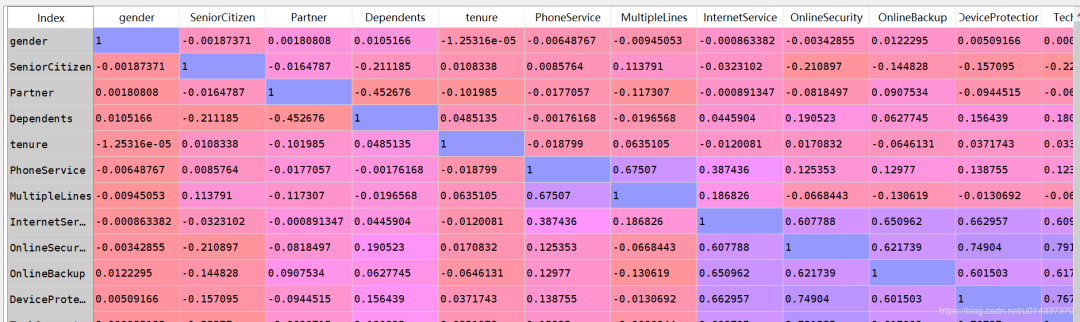
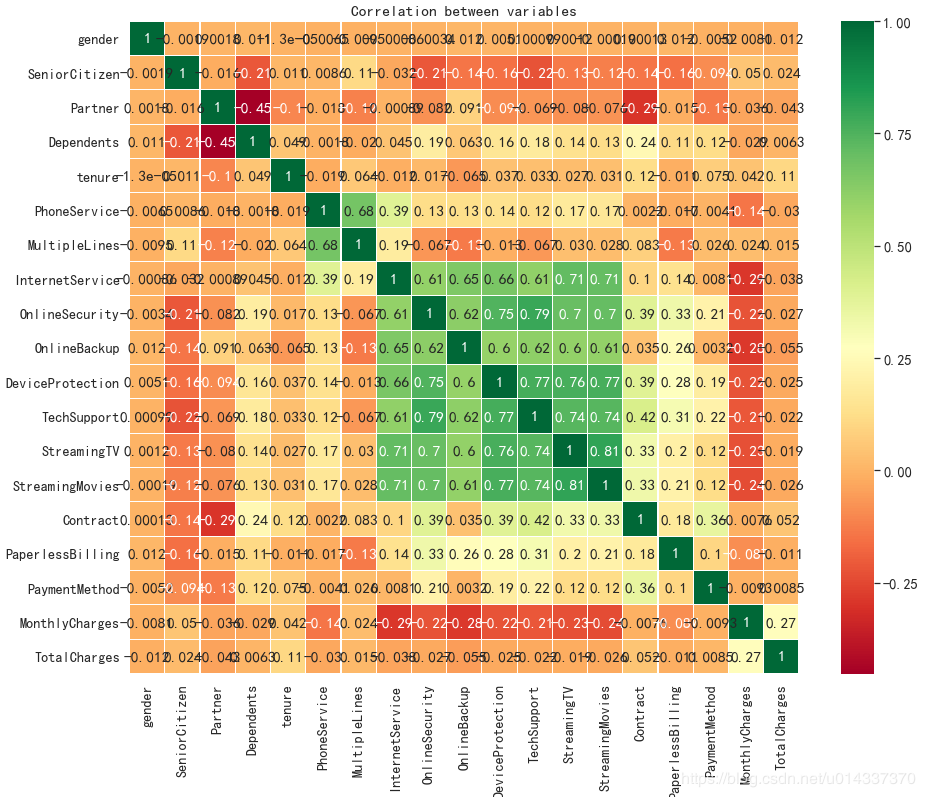
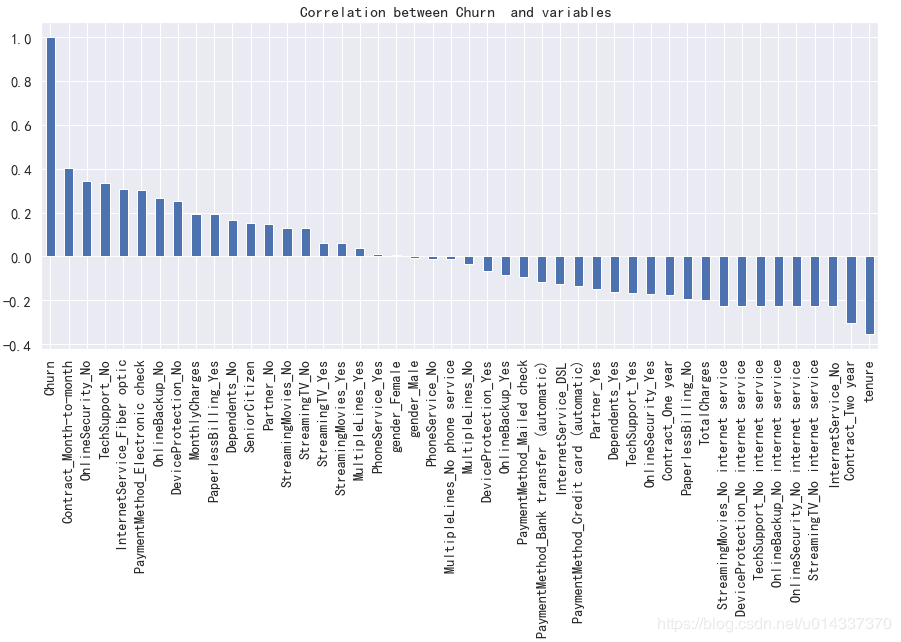
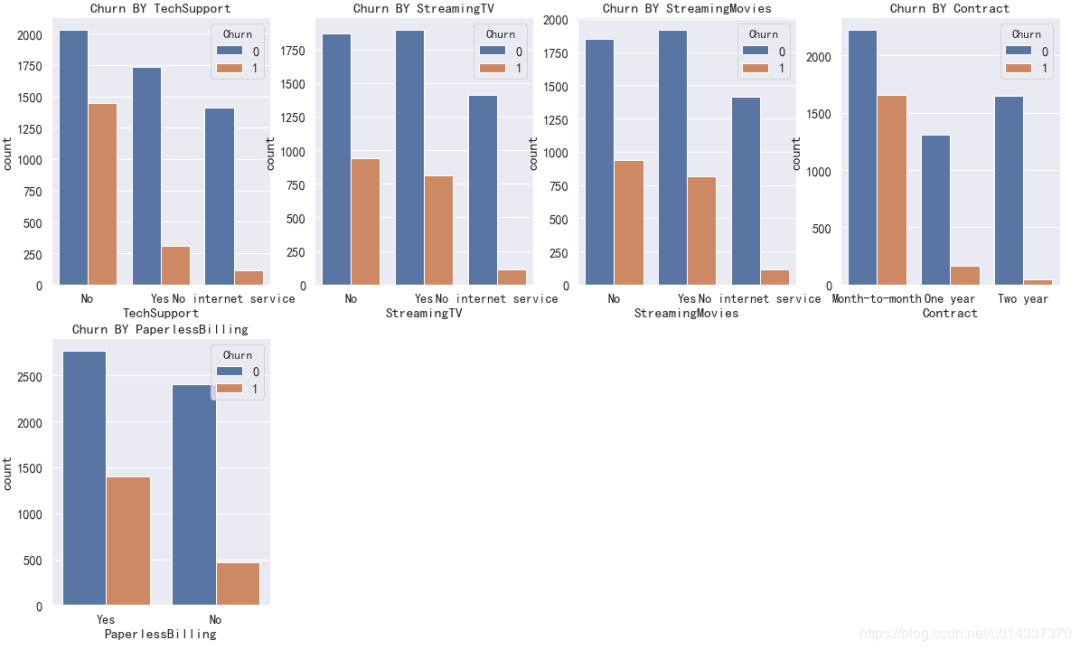
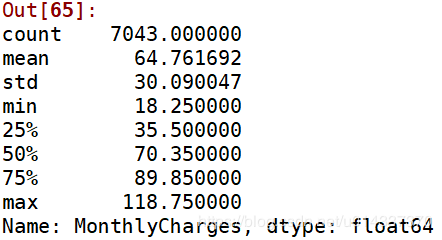
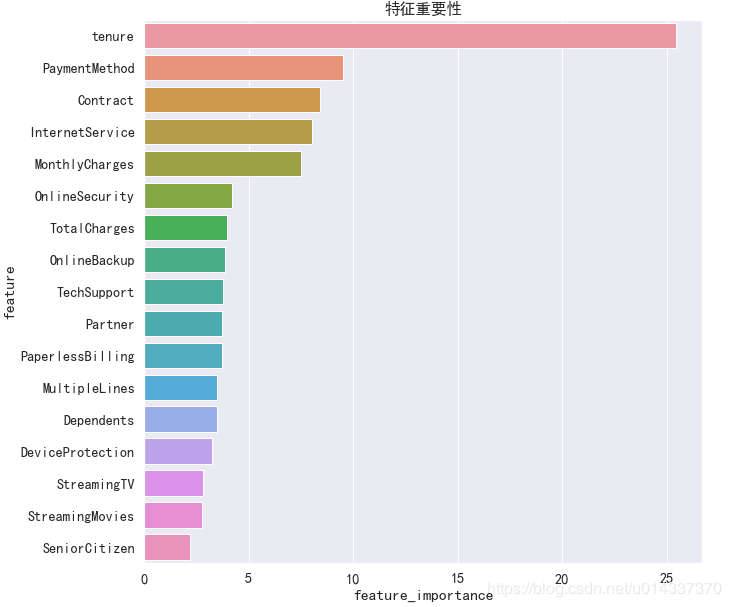
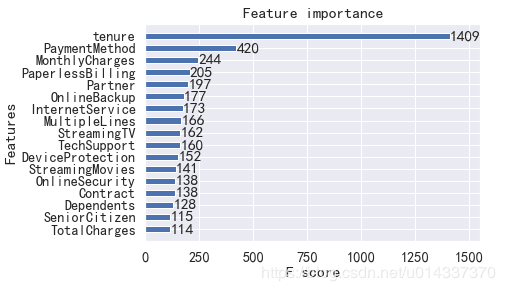
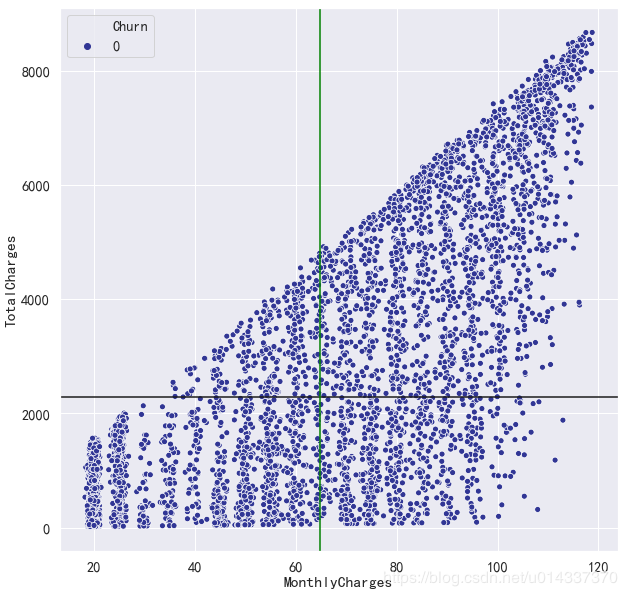
plt.figure(figsize=(15,6)) df_onehot.corr()['Churn'].sort_values(ascending=False).plot(kind='bar') plt.title('Correlation between Churn and variables ')
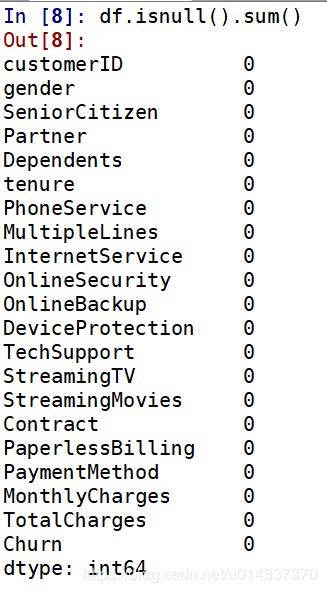
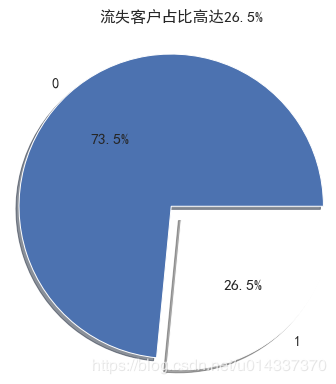
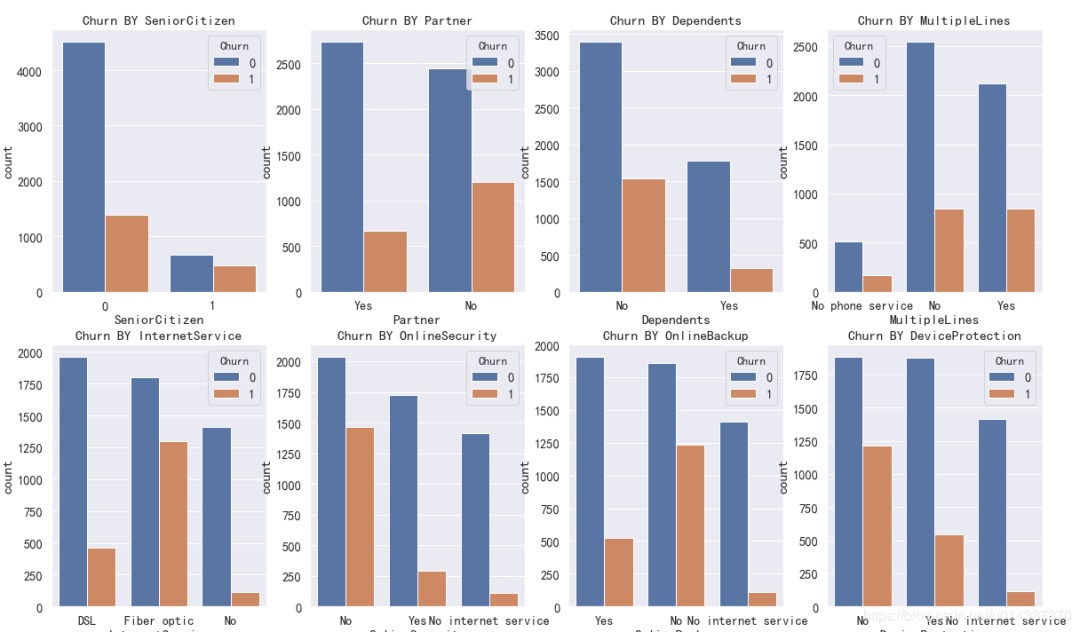
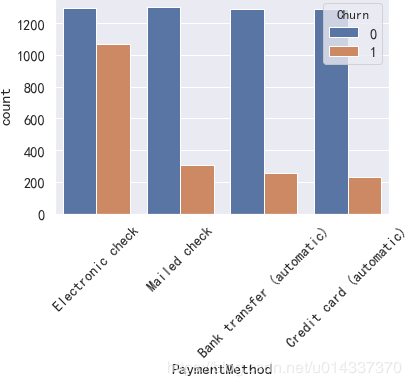
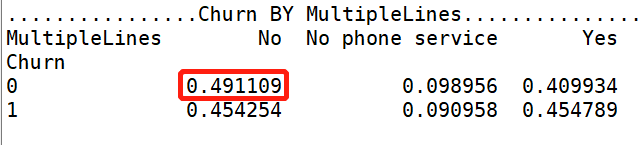
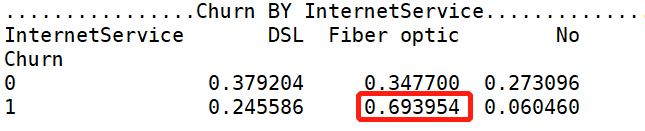
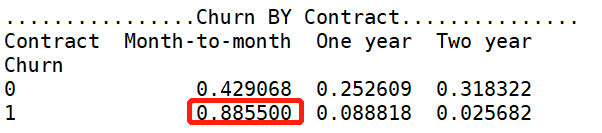
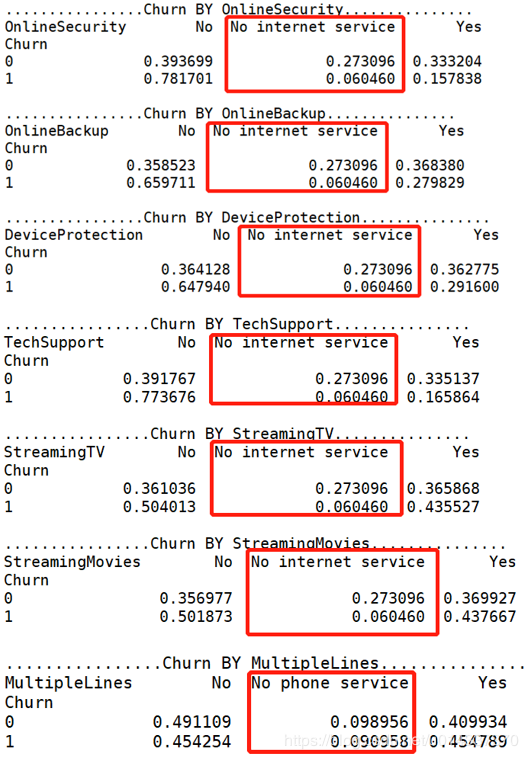
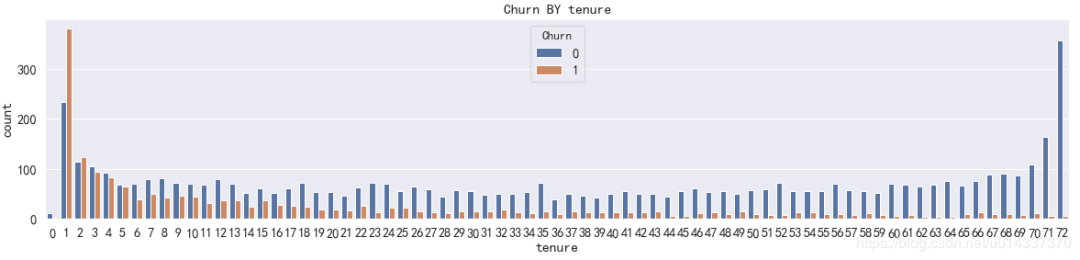
print('ka_var列表中的维度与Churn交叉分析结果如下:','\n') for i in kf_var: print('................Churn BY {}...............'.format(i)) print(pd.crosstab(df['Churn'],df[i],normalize=0),'\n') #交叉分析,同行百分比
#自定义齐性检验 & 方差分析 函数 defANOVA(x): li_index=list(df['Churn'].value_counts().keys()) args=[] for i in li_index: args.append(df[df['Churn']==i][x]) w,p=stats.levene(*args) #齐性检验 if p<0.05: print('警告:Churn BY {}的P值为{:.2f},小于0.05,表明齐性检验不通过,不可作方差分析'.format(x,p),'\n') else: f,p_value=stats.f_oneway(*args) #方差分析 print('Churn BY {} 的f值是{},p_value值是{}'.format(x,f,p_value),'\n') if p_value<0.05: print('Churn BY {}的均值有显著性差异,可进行均值比较'.format(x),'\n') else: print('Churn BY {}的均值无显著性差异,不可进行均值比较'.format(x),'\n')
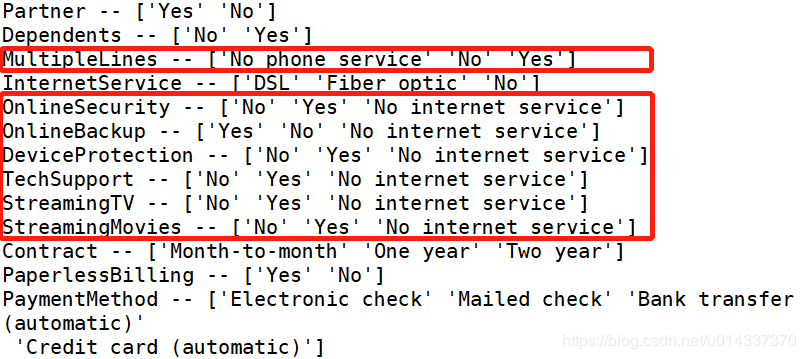
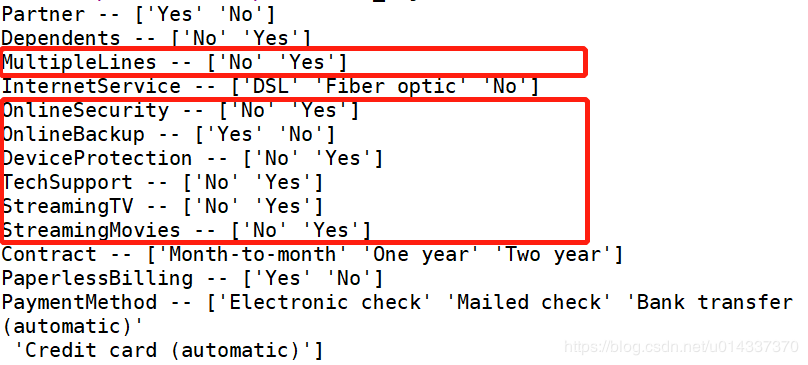
deflabelencode(x): churn_var[x] = LabelEncoder().fit_transform(churn_var[x]) for i in range(0,len(df_object.columns)): labelencode(df_object.columns[i]) print(list(map(Label,df_object.columns)))
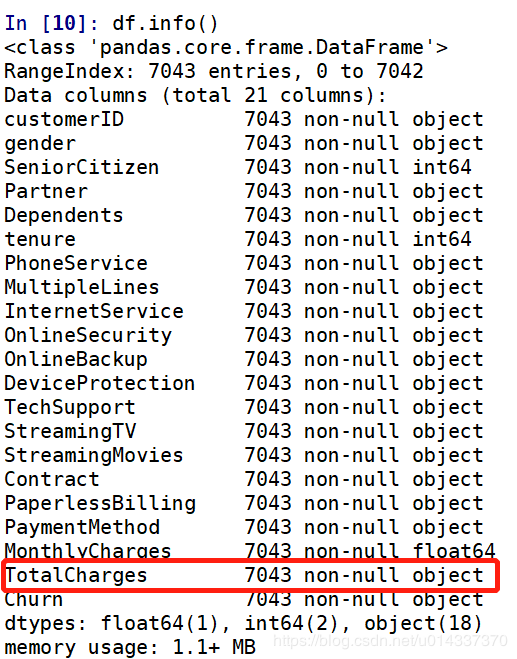
Churn by MonthlyCharges 的卡方临界值是0.00,小于0.05,表明MonthlyCharges组间有显著性差异,可进行【交叉分析】
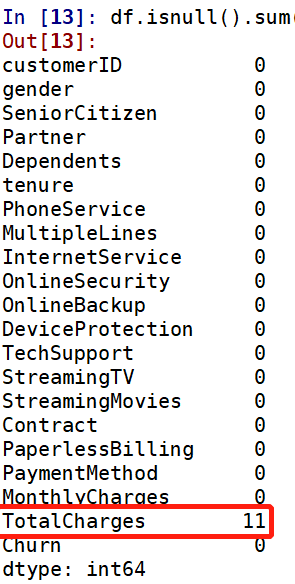
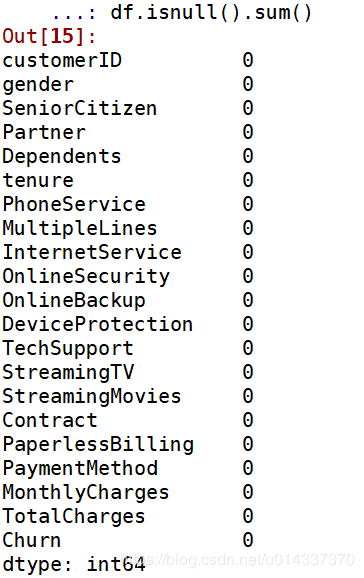
Churn by TotalCharges 的卡方临界值是0.00,小于0.05,表明TotalCharges组间有显著性差异,可进行【交叉分析】
交叉分析
for i in ['MonthlyCharges','TotalCharges']: print('................Churn BY {}...............'.format(i)) print(pd.crosstab(df['Churn'],df[i],normalize=0),'\n')
%%cython import numpy as np cimport numpy as cnp ctypedef cnp.int_t DTYPE_t
cpdef cnp.ndarray[DTYPE_t] _transform(cnp.ndarray[DTYPE_t] arr): cdef: int i = 0 int n = arr.shape[0] int x cnp.ndarray[DTYPE_t] new_arr = np.empty_like(arr)
while i < n: x = arr[i] if x % 2: new_arr[i] = x + 1 else: new_arr[i] = x - 1 i += 1 return new_arr
%%cython import cython import numpy as np cimport numpy as cnp ctypedef cnp.int_t DTYPE_t
@cython.boundscheck(False) @cython.wraparound(False) cpdef cnp.ndarray[DTYPE_t] _transform(cnp.ndarray[DTYPE_t] arr): cdef: int i = 0 int n = arr.shape[0] int x cnp.ndarray[DTYPE_t] new_arr = np.empty_like(arr)
while i < n: x = arr[i] if x % 2: new_arr[i] = x + 1 else: new_arr[i] = x - 1 i += 1 return new_arr
%load_ext Cython
%%cython
def f_plain(x):
return x * (x - 1)
def integrate_f_plain(a, b, N):
s = 0
dx = (b - a) / N
for i in range(N):
s += f_plain(a + i * dx)
return s * dx
6.46 s ± 41.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
看来直接加头,效率提升不大。
方法2,使用c type
%%cython
cdef double f_typed(double x) except? -2:
return x * (x - 1)
cpdef double integrate_f_typed(double a, double b, int N):
cdef int i
cdef double s, dx
s = 0
dx = (b - a) / N
for i in range(N):
s += f_typed(a + i * dx)
return s * dx
345 ms ± 529 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
import numba
@numba.jitdef f_plain(x):
return x * (x - 1)
@numba.jitdef integrate_f_numba(a, b, N):
s = 0
dx = (b - a) / N
for i in range(N):
s += f_plain(a + i * dx)
return s * dx
@numba.jitdef apply_integrate_f_numba(col_a, col_b, col_N):
n = len(col_N)
result = np.empty(n, dtype='float64')
assert len(col_a) == len(col_b) == n
for i in range(n):
result[i] = integrate_f_numba(col_a[i], col_b[i], col_N[i])
return result
def compute_numba(df):
result = apply_integrate_f_numba(df['a'].to_numpy(),
df['b'].to_numpy(),
df['N'].to_numpy())
return pd.Series(result, index=df.index, name='result')
%timeit compute_numba(df)
6.44 ms ± 440 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
我们看到,使用numba,需要做的代码改动较小,效率提升幅度却很大!
3.4 进阶 并行化处理
并行化读取数据
在基础篇讲分块读取时,简单提了一下并行化处理,这里详细说下代码。
第一种思路,分块读取,多进程处理。
import pandas as pd
from multiprocessing import Pool
def process(df):
"""
数据处理
"""
pass
# initialise the iterator object
iterator = pd.read_csv('train.csv', chunksize=200000, compression='gzip',
skipinitialspace=True, encoding='utf-8')
# depends on how many cores you want to utilise
max_processors = 4# Reserve 4 cores for our script
pool = Pool(processes=max_processors)
f_list = []
for df in iterator:
# 异步处理每个分块
f = pool.apply_async(process, [df])
f_list.append(f)
if len(f_list) >= max_processors:
for f in f_list:
f.get()
del f_list[:]
from multiprocessing import Pool
import pandas as pd
import os
def read_func(file_path):
df = pd.read_csv(file_path, header=None)
return df
def read_file():
file_list=["train_split%02d"%i for i in range(66)]
p = Pool(4)
res = p.map(read_func, file_list)
p.close()
p.join()
df = pd.concat(res, axis=0, ignore_index=True)
return df
df = read_file()
import csv import os import random import re import time
import dateutil.parser as dparser from random import choice from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.chrome.options import Options
import csv import os import random import re import time import threading
import dateutil.parser as dparser from random import choice from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.chrome.options import Options
import csv import os import random import re import time
import dateutil.parser as dparser from random import choice from multiprocessing import Pool from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.chrome.options import Options
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
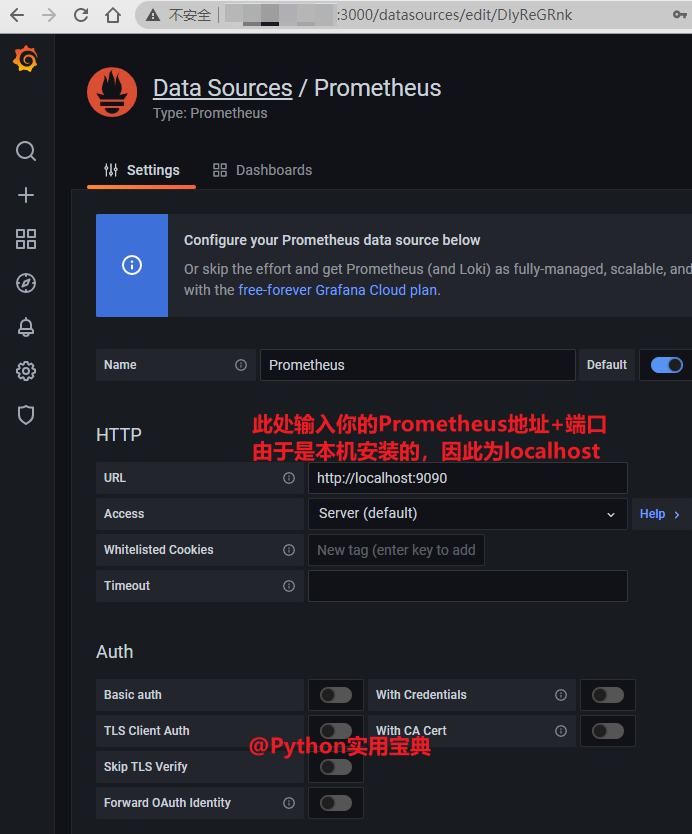
- targets: ['localhost:9090']
# 主要是新增了node_exporter的job,如果有多个node_exporter,在targets数组后面加即可
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100']
#(CentOS) vim /data/prometheus/conf/prometheus.yaml
vim /data/prometheus/conf/prometheus.yml # ubuntu
配置如下:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# 主要是新增了node_exporter的job,如果有多个node_exporter,在targets数组后面加即可
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100']
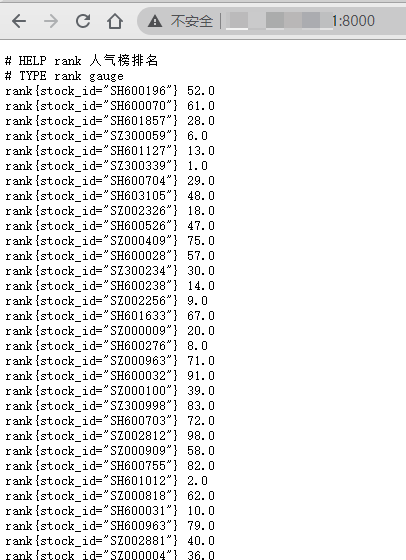
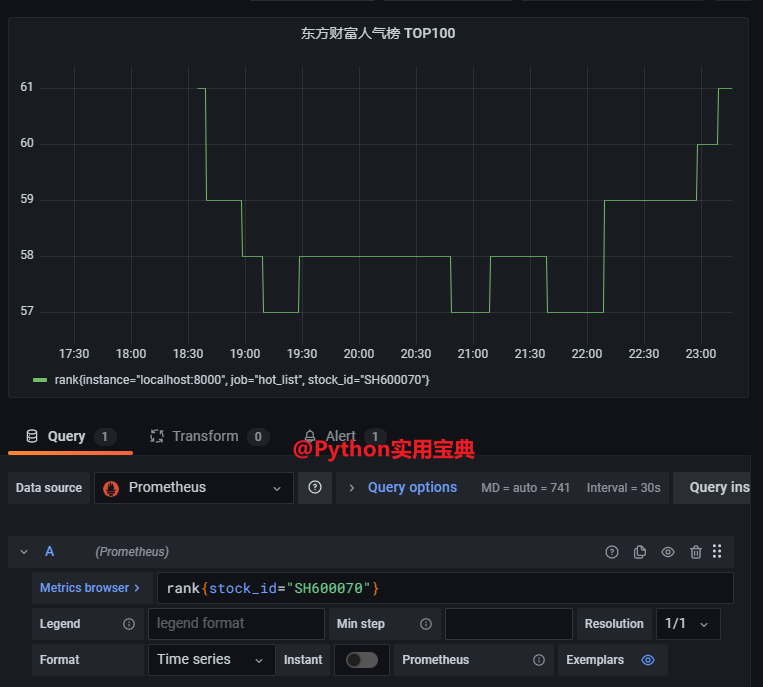
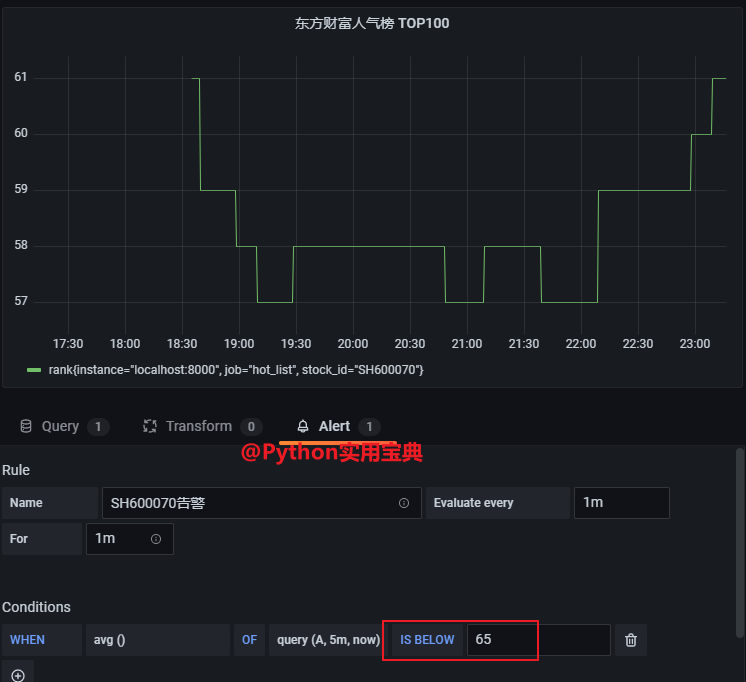
# 新增我们的Python股票采集脚本
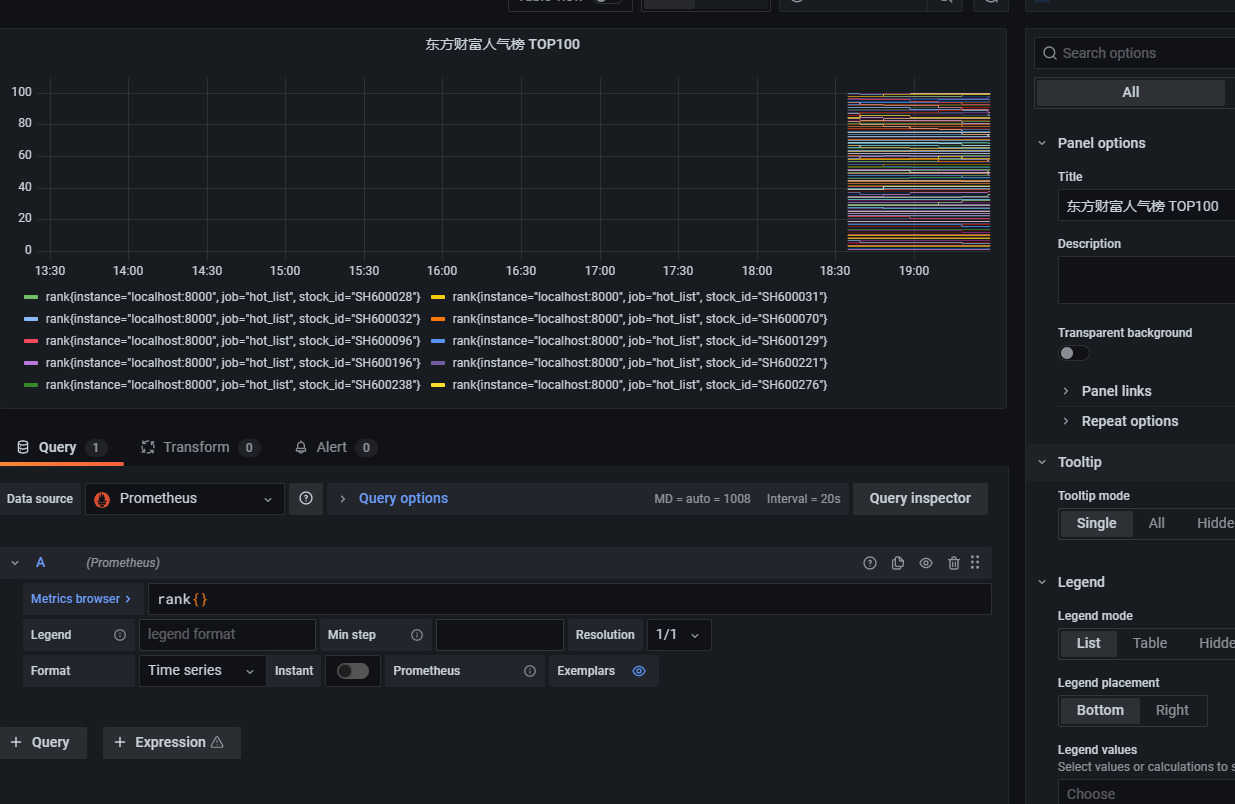
- job_name: 'hot_list'
static_configs:
- targets: ['localhost:8000']